Backing Up and Restoring a Database
| As you're probably aware by now, this book is not intended to be a how-to book for database administrators. The bibliography in the companion content lists several excellent books that can teach you the mechanics of making database backups and restoring and can offer best practices for setting up a backup-and-restore plan for your organization. Nevertheless, there are some important issues relating to backup and restore processes that can help you understand why one backup plan might be better suited to your needs than another. Most of these issues involve the role the transaction log plays in backup and restore operations, so I'll discuss the main ones in this section. Types of BackupsNo matter how much fault tolerance you have implemented on your database system, it is no replacement for regular backups. Backups can provide a solution to accidental or malicious data modifications, programming errors, and natural disasters (if you store backups in a remote location). If you opt for the fastest possible speed for data file access at the cost of fault tolerance, backups provide insurance in case your data files are damaged. The degree to which you can restore the lost data depends on the type of backup. SQL Server 2005 has four main types of backups (and a couple of variations on those types):
Note
A full backup can be made while your SQL Server instance is in use. This is considered a "fuzzy" backupthat is, it is not an exact image of the state of the database at any particular point in time. The backup threads just copy extents, and if other processes need to make changes to those extents while the backup is in progress, they can do so. To maintain consistency for either full, differential, or file backups, SQL Server records the current log sequence number (LSN) at the time the backup starts and again at the time the backup ends. This allows the backup to also capture the relevant parts of the log. The relevant part starts with the oldest open transaction at the time of the first recorded LSN and ends with the second recorded LSN. As mentioned previously, what gets recorded with a log backup depends on the recovery model you are using. So before I talk about log backup in detail, I'll tell you about recovery models. Recovery ModelsAs I told you in Chapter 4 when I discussed database options, the RECOVERY option has three possible values: FULL, BULK_LOGGED, or SIMPLE. The value you choose determines the speed and size of your transaction log backups as well as the degree to which you are at risk of losing committed transactions in case of media failure. FULL Recovery ModelThe FULL recovery model provides the least risk of losing work in the case of a damaged data file. If a database is in this mode, all operations are fully logged, which means that in addition to logging every row added with the INSERT operation, removed with the DELETE operation, or changed with the UPDATE operation, SQL Server also writes to the transaction log in its entirety every row inserted using a bcp or BULK INSERT operation. If you experience a media failure for a database file and need to recover a database that was in FULL recovery mode and you've been making regular transaction log backups preceded by a full database backup, you can restore to any specified point in time up to the time of the last log backup. In addition, if your log file is available after the failure of a data file, you can restore up to the last transaction committed before the failure. SQL Server 2005 also supports a feature called log marks, which allows you to place reference points in the transaction log. If your database is in FULL recovery mode, you can choose to recover to one of these log marks. I'll talk a bit more about log marks in Chapter 8. In FULL recovery mode, SQL Server also fully logs CREATE INDEX operations. When you restore from a transaction log backup that includes index creations, the recovery operation is much faster because the index does not have to be rebuiltall the index pages have been captured as part of the database backup. Prior to SQL Server 2000, SQL Server logged only the fact that an index had been built, so when you restored from a log backup, the entire index would have to be built all over again! So, FULL recovery mode sounds great, right? As always, there are tradeoffs. The biggest tradeoff is that the size of your transaction log files can be enormous, so it can take much longer to make log backups than with any previous release of SQL Server. BULK_LOGGED Recovery ModelThe BULK_LOGGED recovery model allows you to completely restore a database in case of media failure and also gives you the best performance and least log space usage for certain bulk operations. These bulk operations include BULK INSERT, bcp, CREATE INDEX, SELECT INTO, WRITETEXT, and UPDATETEXT. In FULL recovery mode, these operations are fully logged, but in BULK_LOGGED recovery mode, they are only minimally logged. When you execute one of these bulk operations, SQL Server logs only the fact that the operation occurred and information about space allocations. However, the operation is fully recoverable because SQL Server keeps track of what extents were actually modified by the bulk operation. Every data file in a SQL Server 2005 database has at least one special page called a BCM (Bulk Change Map) page, which is managed much like the GAM and SGAM pages that I discussed in Chapter 2 and the DCM pages that I mentioned earlier. Each bit on a BCM page represents an extent, and if the bit is 1, it means that this extent has been changed by a minimally logged bulk operation since the last full database backup. A BCM page is located at the eighth page of every data file and every 511,230 pages thereafter. All the bits on a BCM page are reset to 0 every time a log backup occurs. Because of the ability to minimally log bulk operations, the operations themselves can be carried out much faster than in FULL recovery mode. Setting the bits in the appropriate BCM page requires a little overhead, but compared with the cost of logging each individual change to a data or index row, the cost of flipping bits is an order of less magnitude. If your database is in BULK_LOGGED mode and you have not actually performed any bulk operations, you can restore your database to any point in time or to a named log mark because the log will contain a full sequential record of all changes to your database. The tradeoff comes during the backing up of the log. In addition to copying the contents of the transaction log to the backup media, SQL Server scans the BCM pages and backs up all the modified extents along with the transaction log itself. The log file itself stays small, but the backup of the log can be many times larger. So the log backup takes more time and might take up a lot more space than in FULL recovery mode. The time it takes to restore a log backup made in BULK_LOGGED recovery mode is similar to the time it takes to restore a log backup made in FULL recovery mode. The operations don't have to be redone; all the information necessary to recover all data and index structures is available in the log backup. SIMPLE Recovery ModelThe SIMPLE recovery model offers the simplest backup-and-restore strategy. Your transaction log is truncated whenever a checkpoint occurs, which happens at regular, frequent intervals. Therefore, the only types of backups that can be made are those that don't require log backups. These types of backups are full database backups, differential backups, partial full and differential backups, and filegroup backups for read-only filegroups. You get an error if you try to back up the log while in SIMPLE recovery mode. Because the log is not needed for backup purposes, sections of it can be reused as soon as all the transactions it contains are committed or rolled back, and the transactions are no longer needed for recovery from server or transaction failure. In fact, as soon as you change you database to SIMPLE recovery model, the log will be truncated. Keep in mind that SIMPLE logging does not mean no logging. What's "simple" is your backup strategy because you'll never need to worry about log backups. However, all operations are logged in SIMPLE mode, even though the individual log records are not as big as they are in FULL mode. A log for a database in SIMPLE mode might not grow as much as a database in FULL mode because the bulk operations discussed under BULK_LOGGED recovery model will also be minimally logged in SIMPLE mode. This does not mean you don't have to worry about the size of the log in SIMPLE mode. As in any recovery mode, log records for active transactions cannot be truncated and neither can log records for any transaction that started after the oldest open transaction. So, if you have large or long-running transactions, you still might need lots of log space. Migrating from SQL Server 7.0Microsoft introduced these recovery models in SQL Server 2000 and intended them to replace the select into/bulkcopy and trunc. log on chkpt. database options. SQL Server 7.0 and earlier versions required that the select into/bulkcopy option be set in order for you to perform a SELECT INTO or bulk copy operation. The trunc. log on chkpt. option forced your transaction log to be truncated every time a checkpoint occurred in the database. This option was recommended only for test or development systems, not for production servers. You can still set these options by using the sp_dboption procedure but not by using the ALTER DATABASE command. However, in SQL Server 2000 and SQL Server 2005, changing either of these options using sp_dboption also changes your recovery model, and changing your recovery model changes the value of one or both of these options, as you'll see below. The recommended method for changing your database recovery mode is to use the ALTER DATABASE command: ALTER DATABASE <database_name> SET RECOVERY [FULL | BULK_LOGGED | SIMPLE] To see what mode your database is in, you can inspect the sys.databases view. For example, this query returns the recovery mode and the state of the AdventureWorks database: SELECT name, database_id, suser_sname(owner_sid) as owner , state_desc, recovery_model_desc FROM sys.databases WHERE name = 'AdventureWorks' As I just mentioned, you can change the recovery mode by changing the database options. For example, if your database is in FULL recovery mode and you change the select into/bulkcopy option to true, your database recovery mode changes to BULK_LOGGED. Conversely, if you force the database back into FULL mode by using ALTER DATABASE, the value of the select into/bulkcopy option changes. If you're using SQL Server 2005 Standard Edition or Enterprise Edition, the model database starts in FULL recovery mode, so all your new databases will also be in FULL mode. You can change the mode of the model database or any other user database by using the ALTER DATABASE command. To make best use of your transaction log, you can switch between the FULL and BULK_LOGGED modes without worrying about your backup scripts failing. Prior to SQL Server 2000, once you performed a SELECT INTO or a bulk copy, you could no longer back up your transaction log. So if you had automatic log backup scripts scheduled to run at regular intervals, these would break and generate an error. This can no longer happen. You can run SELECT INTO or bulk copy in any recovery mode, and you can back up the log in either FULL or BULK_LOGGED mode. You might want to switch between FULL and BULK_LOGGED modes if you usually operate in FULL mode but occasionally need to perform a bulk operation quickly. You can change to BULK_LOGGED and pay the price later when you back up the log; the backup will simply take longer and be larger. You can't easily switch to and from SIMPLE mode. Switching into SIMPLE mode is no problem, but when you switch back to FULL or BULK_LOGGED, you need to plan your backup strategy and be aware that there are no log backups up to that point. So when you use the ALTER DATABASE command to change from SIMPLE to FULL or BULK_LOGGED, you should first make a complete database backup in order for the change in behavior to be complete. Remember that in SIMPLE recovery mode, your transaction log will be truncated at regular intervals. This recovery mode isn't recommended for production databases, where you need maximum transaction recoverability. The only time that SIMPLE mode is really useful is in test and development situations or for small databases that are primarily read-only. I suggest that you use FULL or BULK_LOGGED for your production databases and switch between those modes whenever you need to. Choosing a Backup TypeIf you're responsible for creating the backup plan for your data, you'll need to choose not only a recovery mode but also the kind of backup to make. I mentioned the three main types: full, differential, and log. In fact, you can use all three types together. To accomplish any type of full restore of a database, you must occasionally make a full database backup. In addition, you must choose between a differential backup and a log backup. Here are characteristics of these last two types that can help you decide between them: A differential backup:
A log backup:
Restoring a DatabaseHow often you make each type of backup determines two things: how fast you can restore a database and how much control you have over which transactions are restored. Consider the schedule in Figure 5-5, which shows a database fully backed up on Sunday. The log is backed up daily, and a differential backup is made on Tuesday and Thursday. A drive failure occurs on Friday. If the failure does not include the log files or if you have mirrored them using RAID 1, you should back up the tail of the log with the NO_TRUNCATE option. Figure 5-5. Combined use of log and differential backups reduces total restore time.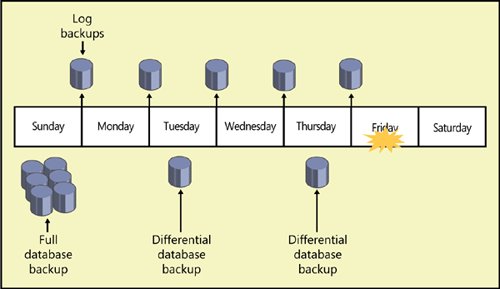 Warning
To restore this database after a failure, you must start by restoring the full backup made on Sunday. This does two things: it copies all the data, log, and index pages from the backup media to the database files, and it applies all the transactions in the log. You must determine whether incomplete transactions are rolled back. You can opt to recover the database by using the WITH RECOVERY option of the RESTORE command. This rolls back any incomplete transactions and opens the database for use. No further restoring can be done. If you choose not to roll back incomplete transactions by specifying the WITH NORECOVERY option, the database will be left in an inconsistent state and will not be usable. If you choose WITH NORECOVERY, you can then apply the next backup. In the scenario depicted in Figure 5-5, you would restore the differential backup made on Thursday, which would copy all the changed extents back into the data files. The differential backup also contains the log records spanning the time the differential backup was being made, so you have to decide whether to recover the database. Complete transactions are always rolled forward, but you determine whether incomplete transactions are rolled back. After the last differential backup is restored, you must restore, in sequence, all the log backups made after the last differential backup was made. This includes the tail of the log backed up after the failure if you were able to make this last backup. Note
Backing Up and Restoring Files and FilegroupsSQL Server 2005 allows you to back up individual files or filegroups. This can be useful in environments with extremely large databases. You can choose to back up just one file or filegroup each day, so the entire database does not have to be backed up as often. This also can be useful when you have an isolated media failure on a single drive, and you think that restoring the entire database would take too long. Here are some details to keep in mind about backing up and restoring files and filegroups:
For example, suppose you back up Filegroup FG1 at 10 A.M. on Monday. The database is still in use, and changes happen to data in FG1 and transactions are processed that change data in both FG1 and other filegroups. You back up the log again at 4 P.M. More transactions are processed that change data in both FG1 and other filegroups. At 6 P.M., a media failure occurs and you lose one or more of the files that make up FG1. To restore, you must first back up the tail of the log containing all changes that occurred between 4 P.M. and 6 P.M. The tail of the log is backed up using the special WITH NO_TRUNCATE option, but you can also use the NORECOVERY option. When backing up the tail of the log WITH NORECOVERY, the database is put into the RESTORING state and can prevent an accidental background change from interfering with the restore sequence. You can then restore FG1 using the RESTORE DATABASE command, specifying just filegroup FG1. Your database will not be in a consistent state because the restored FG1 will have changes only through 10 A.M., and the rest of the database will have changes through 6 P.M. However, SQL Server knows when the last change was made to the database because each page in a database stores the LSN of the last log record that changed that page. When restoring a filegroup, SQL Server makes a note of the maximum LSN in the database. You must restore log backups until the log reaches at least the maximum LSN in the database, and you will not reach that point until you apply the 6 P.M. log backup. Partial BackupsA partial backup can be based either on a full or a differential backup, but a partial backup does not contain all of the filegroups. Partial backups contain all the data in the primary filegroup and all of the read-write filegroups. In addition, you can specify that any read-only files also be backed up. If the entire database is marked as read-only, a partial backup will contain only the primary filegroup. Partial backups are particularly useful for VLDBs using the SIMPLE recovery model because they allow you to back up only specific filegroups, even without having log backups. Page RestoreSQL Server 2005 also allows you to restore individual pages. When SQL Server detects a damaged page, it marks it as suspect and stores information about the page in the suspect_pages table in the msdb database. Damaged pages can be detected when activities such as the following take place:
Several types of errors can require a page to be marked as suspect and entered into the suspect_pages table. These can include checksum and torn page errors, as well as internal consistency problems such as a bad page ID in the page header. The column event_type in the suspect_pages table indicates the reason for the status of the page, which usually reflects the reason the page has been entered into the suspect_pages table. SQL Server Books Online lists the following possible values for the event_type column:
Some of the errors recorded in the suspect_pages table might be transient errors such as an I/O error that occurs because a cable has been disconnected. Rows can be deleted from the suspect_pages table by someone with the appropriate permissions, such as someone in the sysadmin server role. In addition, not all errors that cause a page to be inserted in the suspect_pages table require that the page be restored. A problem that occurs in cached data, such as in a nonclustered index, might be resolved by rebuilding the index. If a sysadmin drops a nonclustered index and rebuilds it, the corrupt data, although fixed, will not be indicated as fixed in the suspect_pages table. Page restore is specifically intended to replace pages that have been marked as suspect because of an invalid checksum or a torn write. Although multiple database pages can be restored at once, you aren't expected to be replacing a large number of individual pages. If you do have many damaged pages, you should probably consider a full file or database restore. In addition, you should probably try to determine the cause of the errors; if you discover pending device failure, you should do your full file or database restore to a new location. Log restores must be done after the page restores to bring the new pages up-to-date with the rest of the database. Just like with file restore, the log backups are applied to the database files containing a page that is being recovered. In an online page restore, the database is online for the duration of the restore, and only the data being restored is offline. Note that not all damaged pages can be restored with the database online. Note
Books Online lists the following basic steps for a page restore:
Partial RestoreSQL Server 2005 lets you do a partial restore of a database in emergency situations. Although the description and the syntax look similar to file and filegroup backup and restore, there is a big difference. With file and filegroup restore, you start with a complete database and replace one or more files or filegroups with previously backed up versions. With a partial database restore, you don't start with a full database. You restore individual filegroups, which must include the primary filegroup containing all the system tables, to a new location. Any filegroups you don't restore are treated as OFFLINE when you attempt to reference data stored on them. You can then restore log backups or differential backups to bring the data in those filegroups to a later point in time. This allows you the option of recovering the data from a subset of tables after an accidental deletion or modification of table data. You can use the partially restored database to extract the data from the lost tables and copy it back into your original database. Restoring with StandbyIn normal recovery operations, you have the choice of either running recovery to roll back incomplete transactions or not running recovery. If you run recovery, no further log backups can be restored and the database is fully usable. If you don't run recovery, the database is inconsistent and SQL Server won't let you use it at all. You have to choose one or the other because of the way log backups are made. For example, in SQL Server 2005, log backups do not overlapeach log backup starts where the previous one ended. Consider a transaction that makes hundreds of updates to a single table. If you back up the log during the update and also after it, the first log backup will have the beginning of the transaction and some of the updates, and the second log backup will have the remainder of the updates and the commit. Suppose you then need to restore these log backups after restoring the full database. If, after restoring the first log backup, you run recovery, the first part of the transaction will be rolled back. If you then try to restore the second log backup, it will start in the middle of a transaction and SQL Server won't know what the beginning of the transaction did. You certainly can't recover transactions from this point because their operations might depend on this update that you've partially lost. SQL Server therefore will not allow any more restoring to be done. The alternative is to not run recovery to roll back the first part of the transaction and instead to leave the transaction incomplete. SQL Server will know that the database is inconsistent and will not allow any users into the database until you finally run recovery on it. What if you want to combine the two approaches? It would be nice to be able to restore one log backup and look at the data before restoring more log backups, particularly if you're trying to do a point-in-time recovery, but you won't know what the right point is. SQL Server provides an option called STANDBY that allows you to recover the database and still restore more log backups. If you restore a log backup and specify WITH STANDBY = '<some filename>', SQL Server will roll back incomplete transactions but keep track of the rolled-back work in the specified file, which is known as a standby file. The next restore operation will read the contents of the standby file and redo the operations that were rolled back, and then it will restore the next log. If that restore also specifies WITH STANDBY, incomplete transactions will again be rolled back, but a record of those rolled back transactions will be saved. Keep in mind that you can't modify any data if you've restored WITH STANDBY (SQL Server will generate an error message if you try), but you can read the data and continue to restore more logs. The final log must be restored WITH RECOVERY (and no standby file will be kept) to make the database fully usable. |
EAN: 2147483647
Pages: 115