Recipe 4.1 Regular Expression Syntax
ProblemYou need to learn the syntax of JDK 1.4 regular expressions. SolutionConsult Table 4-2 for a list of the regular expression characters. DiscussionThese pattern characters let you specify regexes of considerable power. In building patterns, you can use any combination of ordinary text and the metacharacters, or special characters, in Table 4-2. These can all be used in any combination that makes sense. For example, a+ means any number of occurrences of the letter a, from one up to a million or a gazillion. The pattern Mrs?\. matches Mr. or Mrs.. And .* means "any character, any number of times," and is similar in meaning to most command-line interpreters' meaning of the * alone. The pattern \d+ means any number of numeric digits. \d{2,3} means a two- or three-digit number.
Regexes match anyplace possible in the string. Patterns followed by a greedy multiplier (the only type that existed in traditional Unix regexes) consume (match) as much as possible without compromising any subexpressions which follow; patterns followed by a possessive multiplier match as much as possible without regard to following subexpressions; patterns followed by a reluctant multiplier consume as few characters as possible to still get a match. Also, unlike regex packages in some other languages, the JDK 1.4 package was designed to handle Unicode characters from the beginning. And the standard Java escape sequence \unnnn is used to specify a Unicode character in the pattern. We use methods of java.lang.Character to determine Unicode character properties, such as whether a given character is a space. To help you learn how regexes work, I provide a little program called REDemo .[2] In the online directory javasrc/RE, you should be able to type either ant REDemo, or javac REDemo followed by java REDemo, to get the program running.
In the uppermost text box (see Figure 4-1), type the regex pattern you want to test. Note that as you type each character, the regex is checked for syntax; if the syntax is OK, you see a checkmark beside it. You can then select Match, Find, or Find All. Match means that the entire string must match the regex, while Find means the regex must be found somewhere in the string (Find All counts the number of occurrences that are found). Below that, you type a string that the regex is to match against. Experiment to your heart's content. When you have the regex the way you want it, you can paste it into your Java program. You'll need to escape (backslash) any characters that are treated specially by both the Java compiler and the JDK 1.4 regex package, such as the backslash itself, double quotes, and others (see the sidebar Remeber This!).
In Figure 4-1, I typed qu into the REDemo program's Pattern box, which is a syntactically valid regex pattern: any ordinary characters stand as regexes for themselves, so this looks for the letter q followed by u. In the top version, I typed only a q into the string, which is not matched. In the second, I have typed quack and the q of a second quack. Since I have selected Find All, the count shows one match. As soon as I type the second u, the count is updated to two, as shown in the third version. Figure 4-1. REDemo with simple examples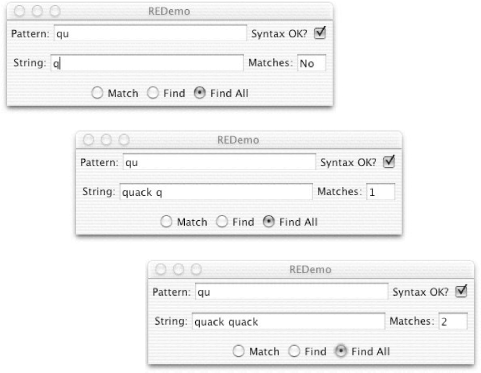 Regexes can do far more than just character matching. For example, the two-character regex ^T would match beginning of line (^) immediately followed by a capital T i.e., any line beginning with a capital T. It doesn't matter whether the line begins with Tiny trumpets, Titanic tubas, or Triumphant slide trombones, as long as the capital T is present in the first position. But here we're not very far ahead. Have we really invested all this effort in regex technology just to be able to do what we could already do with the java.lang.String method startsWith( ) ? Hmmm, I can hear some of you getting a bit restless. Stay in your seats! What if you wanted to match not only a letter T in the first position, but also a vowel (a, e, i, o, or u) immediately after it, followed by any number of letters in a word, followed by an exclamation point? Surely you could do this in Java by checking startsWith("T") and charAt(1) == 'a' || charAt(1) == 'e', and so on? Yes, but by the time you did that, you'd have written a lot of very highly specialized code that you couldn't use in any other application. With regular expressions, you can just give the pattern ^T[aeiou]\w*!. That is, ^ and T as before, followed by a character class listing the vowels, followed by any number of word characters (\w*), followed by the exclamation point. "But wait, there's more!" as my late, great boss Yuri Rubinsky used to say. What if you want to be able to change the pattern you're looking for at runtime? Remember all that Java code you just wrote to match T in column 1, plus a vowel, some word characters, and an exclamation point? Well, it's time to throw it out. Because this morning we need to match Q, followed by a letter other than u, followed by a number of digits, followed by a period. While some of you start writing a new function to do that, the rest of us will just saunter over to the RegEx Bar & Grille, order a ^Q[^u]\d+\.. from the bartender, and be on our way. OK, the [^u] means "match any one character that is not the character u." The \d+ means one or more numeric digits. The + is a multiplier or quantifier meaning one or more occurrences of what it follows, and \d is any one numeric digit. So \d+ means a number with one, two, or more digits. Finally, the \.? Well, . by itself is a metacharacter. Most single metacharacters are switched off by preceding them with an escape character. Not the ESC key on your keyboard, of course. The regex "escape" character is the backslash. Preceding a metacharacter like . with escape turns off its special meaning. Preceding a few selected alphabetic characters (e.g., n, r, t, s, w) with escape turns them into metacharacters. Figure 4-2 shows the ^Q[^u]\d+\.. regex in action. In the first frame, I have typed part of the regex as ^Q[^u and, since there is an unclosed square bracket, the Syntax OK flag is turned off; when I complete the regex, it will be turned back on. In the second frame, I have finished the regex and typed the string as QA577 (which you should expect to match the ^Q[^u]\d+, but not the period since I haven't typed it). In the third frame, I've typed the period so the Matches flag is set to Yes. Figure 4-2. REDemo with ^Q[^u]\d+\. example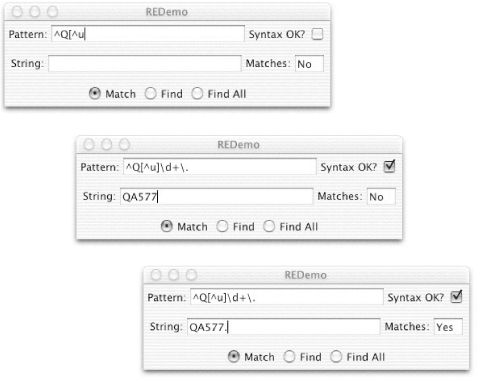 One good way to think of regular expressions is as a "little language" for matching patterns of characters in text contained in strings. Give yourself extra points if you've already recognized this as the design pattern known as Interpreter. A regular expression API is an interpreter for matching regular expressions. So now you should have at least a basic grasp of how regexes work in practice. The rest of this chapter gives more examples and explains some of the more powerful topics, such as capture groups. As for how regexes work in theory and there is a lot of theoretical details and differences among regex flavors the interested reader is referred to the book Mastering Regular Expressions. Meanwhile, let's start learning how to write Java programs that use regular expressions. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: 2147483647
Pages: 409