Resource Planning
| A major part of the "hard" work of making your application-development efforts successful is ensuring that you've properly planned the environment in which the application is going to live. The importance of resource planning really can't be understated. To use a simple, but familiar, example, imagine that you went to work and that there was no desk for you to use, no lights for you to turn on, and no computer for you to bang out code. You'd find it pretty hard to work, wouldn't you? Similarly, for your application to function properly, it has to have a properly designed and thought-out working environment. In many cases, achieving success with a project implementation depends as much (if not more) on resource planning as it does on coding. How involved you are in the initial stages of project planning likely determines the amount of input that you personally have on the type and amount of hardware used. Nonetheless, being as familiar as you can with the "best-case scenarios" makes you an invaluable advisor should you find yourself in that role. The following section attempts to familiarize you with various processes you can use to properly plan and utilize your resources while tailoring them to suit your specific applications and make the most of your fiscal resources. Environment ConsiderationsObviously, there are many times when you are tasked with application building in situations in which the architecture and environment have already been decided for you. In those cases, the best you can do as a developer is to make sure you write solid code, adhere to best practice standards, and make yourself aware of the subtleties of each specific OS/database combination where that code might be run. Still, if you're lucky, there are times when your advice as the expert is sought in making the decisions about the platforms with which the application will live. Developers often approach these situations with a "go with what you know attitude." Although there's nothing wrong with that attitude on the surface, you'll find yourself of much more value to the client or customer if you can identify pros and cons of each platform based on the client's specific situation. As you read on, you should gain a better understanding of how you can approach this "needs analysis" and determine the best choices for any given situation. OSsWe're hesitant to even begin writing this section because we can hear the screams of each devoted faction ringing in our ears. Again, in many cases, you might play no role in this decision. Still, if you were asked to make a recommendation (and I'm sure you hold your own strong opinions), it would help if you were able to make that recommendation using logical analysis of the situation instead of just your personal devotion to one choice or the other. When dealing with applications that make use of ColdFusion Server, you have three major choices in the world of OSs. Currently, versions of ColdFusion Server are available for Windows, Solaris, and Linux. Table 3.2 briefly outlines each choice and its benefits and drawbacks.
Of course, Table 3.1 makes some broad generalizations regarding the different OS choices, and it's very brief in its discussion of the benefits and drawbacks of each choice. The intent, however, is to get you to think along those same lines as you attempt to identify the best choice for your customer (even if the customer is you!). If you're a Linux guru already, you've eliminated one of the items I've listed in the drawbacks column. Similarly, if you already have Solaris machines that cannot be retooled to run Windows, you're on your way to a choice there as well. The key is to identify all the benefits and drawbacks of each choice, evaluate where you are and where you need to go, and then make the most informed decision possible. The differences in stability and performance between the three versions are all pretty negligible, and the choice usually comes down to the hardware and technical resources that you or the customers have in-house. Choosing a DatabaseJust as you must decide which OS you want to use for your ColdFusion Servers, you also must decide where your data is going to be stored. Just as with the OS discussion, there are many cases (especially when dealing with legacy applications) where the data is already in a database, thus eliminating the need for you to make this choice. There are still situations, however, where the application you are building is gathering or creating the data. In those cases, it becomes necessary to decide which database you're going to use and how you want to implement it. In general, there are two types of database systems: desktop database tools and server databases. Table 3.3 illustrates the differences between the two.
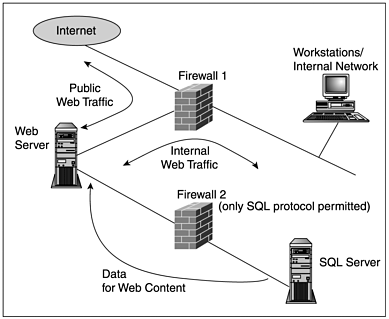
If you're serious about application performance, and you want your site to be highly available under all types of traffic load, you should ensure that you're not using a file-based database. Desktop databases were never really meant to be web-connected, and it shows. Aside from being less reliable than their server counterparts, desktop databases are much, much slower and less secure. Because a large part of any ColdFusion application's processing time is spent waiting for result sets to return from the database, this can have a huge performance impact on your application as a whole. You need to take a close look at the resources that are available to manage the data after it's there; in addition, make sure that you're not trying to leverage an Oracle database administrator (DBA) for Sybase work, or vice-versa. Believe it or not, the subtleties between different database management systems are often more complex than those between OSs. This makes it all the more critical to know who is available to manage the data after it's in the database. Contrary to popular opinions, designing table layouts in SQL or Oracle doesn't make you a DBA. As you're application begins to become more heavily trafficked, you inevitably discover that you have to do some tweaking at the database level to keep things running smoothly. At this point, the DBMS you've chosen and the folks you have around you to help you support it become extremely important to you so choose carefully. Assessing the Needs of Your ApplicationWhat a wonderful world it would be if we were able to peer into our crystal balls and determine, well in advance, just what type of resource configuration our applications would require to function at their very best. As it is, however, we are forced to try to deliver our best estimates. During the discovery phase of any section of a project, the first thing you usually want to do is a needs analysis. Determining an appropriate application-environment configuration is no different. Based on the requirements you've already received, as well as how you believe that the application should work in its finished state, you should be able to determine roughly how you need to configure your environment to suit your application. Of course, to determine the actual hardware requirements of the application servers themselves, you'll want to conduct systematic load testing of the finished code. This is an absolutely necessary step and one that is covered in great detail in Chapter 26, "Performance Optimization and Scalability Planning." For now, we deal with planning the environment as a whole to suit your application. First and foremost, you need to determine the overall architecture that you plan to implement. Depending on the needs of your application, this is where you should begin to investigate DMZs, firewalls, Network Address Translation (NAT) and Secure Socket Layer (SSL) hardware/software combinations, and so on. Ideally, you want to expose as little of your infrastructure as possible to the outside world. The most traditional method of accomplishing this is by placing your public servers (such as the web server) on a protected subnetwork that has no access to your internal network. In this way, you can keep the public portion of your network accessible, without introducing undue security risks. Further, you might want to make use of a firewall of some sort to restrict traffic between all computers on your network in accordance with the security policies that you or your network administrators have defined. The firewall can become an integral part of your overall design; it acts as the traffic cop, pushing traffic meant for your public servers to your predefined subnetwork and keeping unwanted intrusion from your internal systems. Figure 3.8 demonstrates this design. Figure 3.8. Example architecture. After you've determined the overall design of the environment in which your application will live, you should address (as much as is within your power as the developer) the security of the public servers themselves. Depending on the combination of OSs and web server software you have chosen, the actual methods for securing these servers differ. Still, the key things that you want to check are as follows:
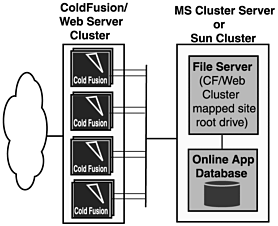
Of course, this is by no means a complete list, but it should help you begin to look in the right direction in thinking about securing your servers. If security is a major concern for you and your organization, there are many consultancies now offering full security audits of your architecture. Another part of your initial security strategy should be checking vendor sites to make sure that you've installed and configured all necessary security patches. Most vendors maintain sites explicitly designed to keep their customers updated with recent security releases. After you've decided which software products you're going to use, it's a good idea to visit the vendor sites for these products and sign up for the various security alert mailing lists that are offered. These mailings typically update you as new security issues are discovered, and they tell you the actions that you need to take to protect your configuration. Depending on the type of application that you are designing, there might be other pieces of your configuration that you need to snap in; but in almost every case, you have to start by defining a configuration and security model. After you've done the work up front, you can move on to the actual design and implementation of your application with a good understanding of the policies and limitations behind the scenes. Planning Ahead for ScalabilityWhen you're designing your architecture, leave yourself a path to upgrade should your application suddenly get bombarded by traffic that is much higher than you expected. When you are initially designing the architecture, you are forced to make a best-guess estimate of the amount of traffic your site will actually receive. Although this is fine as a starting point, you might find that as you gain a larger user base, you need to reevaluate how your environment is designed and expand your architecture to better suit the needs of your growing user base. One of the easiest ways to do this is through clustering and load balancing. Clustering and load balancing enable you to have multiple servers in your environment that serve exactly the same purpose as their twins, thus splitting the work between two or more partners. In a typical architecture, there are three places that you can cluster: at the web server, at the application server, and at the database server. Unless you've implemented a three-tiered architecture with your application server physically separated from your web server, you likely will be performing clustering at the web/application server or at the database server. To cluster, you need to identify where your traffic bottlenecks exist. By performing analysis on your traffic patterns and monitoring the resource usage on your application and database machines, you should be able to determine where you get the most bang for your buck. Obviously, if your analysis shows you that your ColdFusion Servers are spending the vast majority of their time in an idle state and your database server is nearly never idle, you should consider clustering your database to spread the load. Conversely, if the database is idle nearly 100 percent of the time and your ColdFusion Server's resources are strained, you should cluster at the ColdFusion layer. Depending on the database that you've chosen, you should be able to find a wealth of information on your clustering options at the vendor site. If you've determined that you need to cluster at the application-server layer, the first step in analyzing your traffic pattern is to define how many servers are necessary to service all your concurrent requests during peak load times. Clustering ColdFusion Servers in this sense refer to having a group of web/application servers work together to service the entire site. When clustering in this way, each member of the cluster typically hosts a complete copy of the entire site so that any incoming request can be answered by any node on the cluster. Alternatively, you might choose to centralize all web content in a single location, giving all cluster members access to this content. The content is made available on a separate physical machine on the network, typically referred to as a content or file server. The main problem with this type of configuration is that although your application servers are still clustered, the content server represents a single point of failure in that if it becomes unavailable, none of the clustered application/web servers can service any incoming requests. One way to solve this problem is by partnering the content server and the database server, and then making each one the other's failover. In other words, although the database server's primary function in this setup is to handle incoming database requests, it would also contain copies of the content so that if the content server were to fail, the cluster nodes could look to the database server for the content. Subsequently, should the database server go offline, the content server will have a complete copy of the database that can come online to answer database requests in the event of a failure. This type of setup eliminates the need for redundant hardware, but continues to ensure high availability of all components in the cluster. Figure 3.9 demonstrates this model. Figure 3.9. High-availability model. Load balancing is the next major key in scalability planning. After you've decided to cluster your application servers, you need to come up with a plan for the distribution of incoming traffic between each member of the cluster. There are many ways that you can do this, but by far the most popular choice today is through the introduction of a hardware layer. This hardware layer, typically called a load balancer, sits on the network in front of all your web-application servers. When any requests come in for your site, the load balancer answers these requests by deciding to which server on the cluster it wants to direct this traffic. The way in which it makes that decision can be controlled by the way in which you configure the load balancer itself. Typically, if your site is located at www.somesite.com, www.somesite.com resolves to the Internet Protocol (IP) address of your load balancer. After traffic hits the load balancer, the load balancer can decide to which member of the server cluster it should translate that request. This can also give you an additional layer of security because, in this model, the load balancer itself really is the only piece of hardware that needs to have a public Internet address. After traffic has been sent there, it can usually translate the request to a private network address of a machine on the cluster for response. After you've decided that you are going to need to cluster and implement some sort of load-balancing strategy, the next step is defining how many cluster members you actually need to handle the amount of traffic you are experiencing during peak times. There are many different strategies and methodologies available for determining this number. We will present one that we've used successfully in the past. First, it helps to have a general understanding of how cluster size is determined. Generally, there are a few standard factors that you need to consider:
After all items have been considered, testing is required to determine the exact number of cluster members necessary to meet the expectations that you have defined. As with any other methodology, there are many testing methods available. The one we've used successfully in the past is outlined here:
Again, you might find that you have a better way to determine your cluster needs. There is nothing wrong with developing your own methodology for determining these needs just make sure that whatever method you use, you have some quantifiable way to measure the improvement in performance as you add members to the cluster. SummaryIn this section, we examined how to define the environment in which our application runs, as well as how to determine the specific needs of our application from an architectural standpoint. We also talked about how to expand our environment for scalability after we determine the need. To successfully build a web application with any technology and not just ColdFusion, you have to make sure that you are properly planning and using your resources. Making proper use of the resources you have means that you're keeping track of what they're doing and how they are doing it. This keeps everything running smoothly. The job of monitoring all components of your setup is an ongoing task throughout the life of your application, and it's a necessary step in making sure that you can identify and deal with any potential problems early on. In addition to the number of servers you have available to you and the way that your network is architected, you also need to examine the type of hardware that you have to make sure that it's up-to-date and appropriate for the task. You really can't over-plan your resources. It's better to have too much hardware available to you than to come up short after it's too late. There's an old adage that the prepared companies determine the maximum amount of hardware they need for peak load and then double it just to be safe. Although that's unrealistic to expect, the core message is true. It's better to be prepared for the worst than it is to get left wishing you had. Depending on how involved you are in the predevelopment stages of the project, you might find that most or all architecture and environment planning work has been done for you. Nevertheless, as a developer, it's important that you keep yourself well-versed in the different ways in which an application environment is planned and deployed so that you can offer expert advice based on your experiences when you are inevitably called upon to do so. After you've completed the planning of your architecture and hardware, you then can begin thinking about how you're actually going to build the core application. Just as the architecture and hardware layer requires proper planning to ensure success, so too does the application-building process. In the next section, we dive right into one of the first steps of this planning by beginning a discussion of the various development methodologies that are available for you to use when designing your application. |
EAN: 2147483647
Pages: 579
- Data Mining for Business Process Reengineering
- Intrinsic and Contextual Data Quality: The Effect of Media and Personal Involvement
- Healthcare Information: From Administrative to Practice Databases
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare