| One of the challenges of multiprocessor systems is synchronizing access between the processors. In the early days of UNIX, it could be assumed that there was only one processor and only one kernel, and once that kernel started running, it had absolute control of the system. If the kernel had a critical sequence of instructions, it could turn off interrupts and execute that code without the risk of anything interrupting the flow. With multiprocessor systems, even with interrupts off, it is possible that two processors could try to access the same data at the same time. For an example of why this is a problem, consider the following code, which stores a value into a circular buffer, increments the index into the buffer, then wraps the index back to the beginning if it is past the end: buffer[index++] = new_data; if (index == BUFFER_SIZE) { index = 0; }
This looks pretty reasonable until you consider the case where two processors execute the same code at the same time. Let's say your buffer has 200 entries, so BUFFER_SIZE is 200. You've got 199 entries in the buffer, so index is at 199. Processor A stores the new data at buffer[199] and increments index to 200. Now processor B stores its new data at buffer[200] (off the end of the buffer) and increments the index to 201. Next, processor A gets to the test and checks to see if index is equal to 200. It's not, it's 201, so it keeps on going. Processor B does the same. Now you've got your index pointing past the end of the buffer and it's never going to come back. It'll just keep on writing over memory until something breaks. In order to prevent this kind of data contention, we have two general classes of locks: spinlocks and semaphores. In general, spinlocks are used for short waits, and they protect against access by another processor. Semaphores can be used for longer waits, and they protect against access by another thread on any processor. Here are some of the other key differences between the two: Spinlocks may be held for only a short time. If any spinlock is held for more than 60 seconds, the system will panic. Semaphores can be held indefinitely. If the system tries to get a spinlock and finds it already locked, it will busy wait. It will do no other work until the spinlock is free. If it tries to get a semaphore and finds it locked, it can put the current process to sleep and switch to another process. A process can sleep while holding a semaphore. Processes that are holding spinlocks are not allowed to sleep.
Let's look into the details of spinlocks first. Spinlocks Listing 12.3 is the structure that represents a spinlock. Listing 12.3. Spinlock structure struct lock { volatile uintptr_t sl_lock; volatile uintptr_t sl_owner; char *sl_name_ptr; volatile uint16_t sl_flag; volatile uint16_t sl_next_cpu; uint32_t sl_arena_alloc_flag; };
This structure is also typdefed to lock_t; you'll see lock_t used more commonly than struct lock. The first word in the structure, sl_lock, is the one that indicates whether or not the lock is currently locked. If sl_lock is zero, then the spinlock is locked. If it is nonzero, it is not locked. When it is not locked, this field should contain the per-processor data pointer (PPDP) of the processor that had it last. (Remember that the PPDP is also the address of the mpinfo structure for that processor.) The second field, sl_owner, does the opposite of sl_lock. When the spinlock is locked, this field contains the PPDP of the owner. When it is unlocked, it contains zero. sl_name_ptr is a pointer to a character string containing the name of the spinlock. Each spinlock is given a name when it is allocated. Prior to HP-UX release 11.11, this pointer had to be left-shifted two bits before it was used. Starting with 11.11, the pointer can be used as is. You might wonder why we use zero to indicate locked. It seems more logical that a zero would be unlocked and nonzero would be locked. The answer comes from the PA-RISC architecture. In order to implement any kind of locking mechanism, the hardware must provide an atomic operation for testing a value and setting the value. By atomic, we mean that it is a single operation the test and the set must both happen. The instruction can't be interrupted partway through. Many hardware architectures implement a Test and Set instruction. On PA-RISC this operation is done with the Load and Clear Word (LDCW) instruction. The instruction is given a register and an address. The instruction first loads the contents of memory from the given address into the given register. It then clears the value in memory sets it to zero. When the instruction completes, the memory location will always be zero. The register will be whatever value was in memory before the instruction was executed. We use this instruction to set the value in sl_lock in the spinlock structure. After the instruction executes, the spinlock will be locked. We then examine the register we passed to the LDCW instruction. If that register is zero, it means that the spinlock was already locked by some other processor. If it is nonzero, then it was previously unlocked, and now is locked by us. So what do we do if we try to lock a spinlock and find it is already locked? We spin, of course. More specifically, we call wait_for_lock(), which does some accounting, then sits in a tight loop waiting for the lock to free up. When it finds the lock free, it tries to grab it. If it succeeds, then wait_for_lock() returns and the processor continues. If, when we try to grab the lock, we find that we can't, that means some other processor beat us to it. We continue to spin. During this spin we also keep a timer. If we find after 60 seconds that we're still waiting for the lock, then the system will panic with a Spinlock deadlock message. Sixty seconds is far too long for a spinlock to be held. If we're not able to get it within 60 seconds, something is broken. Notice that once we find the lock free, there's a chance we still can't get it because another processor got there first. On a very busy system this can cause problems on a popular spinlock. To avoid this, the system uses a method of handing the spinlock from one processor to another. Rather than just freeing a spinlock, a processor can check to see if another processor is waiting for it. If so, it can assign it to that other processor. This is where the other two fields, sl_flag and sl_next_cpu, are used. sl_flag is set to one if there is another processor waiting for the spinlock. So when we try to lock a spinlock and find it already locked, one of the things that wait_for_lock() does is set sl_flag to one. The spinunlock() code checks this flag when unlocking the spinlock. If the flag is one, indicating that someone is waiting, rather than just releasing the spinlock, the code donates it to the next processor. Arbitration Picking who to donate the spinlock to involves two more pieces of the puzzle: the sl_arb array and the sl_next_cpu member. sl_arb is a global array of pointers to spinlocks, one for each processor in the system. When a processor starts to wait for a spinlock, in addition to setting sl_flag to one, it sets its own sl_arb array entry to point to the spinlock it is waiting for. Now, when the spinunlock code is ready to donate a lock to another processor, it can look through sl_arb for an entry that points to the spinlock that's being released. When it finds one, that processor is the one that gets the lock next. The sl_next_cpu member is used to decide where in the sl_arb array to start looking. Each time the lock is donated to a processor, that processor's index is put into sl_next_cpu. The next time we go through the process of looking for someone to donate to, we start at sl_next_cpu+1. This way, we proceed round-robin through the list of waiting processors. The one that got it last time is the last one to get it this time. Prearbitration There is one more shortcoming to the spin and arbitrate method we've discussed so far. With a heavily used spinlock, many processors can be continuously looking at the same memory. This causes contention between the caches on those processors the caches need to be continually flushed and updated to verify correctness. To avoid this contention, one more step was added to the process of acquiring a lock: prearbitration. Similar to the sl_arg array, there is a global array called pre_arbitration, with one entry per processor. Each entry in this array is of type struct pre_arbitration. In this structure is a pointer to a lock and a sequence number. Now when we try to get a lock and find it locked, we first call the preArbitration() routine. This routine looks through the pre_arbitration array for another processor that is already pointing to the lock we want that is, another processor that's already waiting for this lock. If we find none, then the routine returns and we fall through to the usual spinlock code, spinning on the lock and waiting for it to be released. However, if we do find one or more processors already waiting for the lock, we find the one that is last in line based on the sequence number. Then we set our own pa_lock field to indicate which lock we're waiting for, and then we spin, watching the processor that is in line before us. We're looking at the pa_lock field of that processor's pre_arbitration structure, waiting for it to change to zero. When we see the pa_lock field for the guy in front of us go to zero, we know that he has now acquired the lock and we're next in line. We exit pre_arbitration() and continue to spin on the spinlock as we would without arbitration. Each of the pre_arbitration structures is aligned and sized such that it will be on its own cache line. That means that there is only one processor spinning on that cache line and it doesn't have to be updated on the other processors. The whole process sounds complicated, but it's really not as bad as it sounds. Figure 12-2 shows a flowchart of the process for acquiring a spinlock. Figure 12-2. Flowchart of Spinlock Acquisition 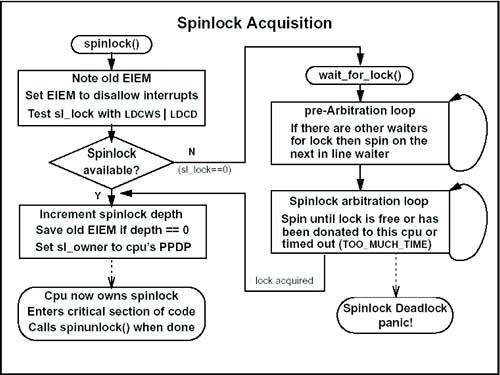
Compared to acquiring the lock, releasing it is a pretty simple operation. First, we check for the lock's sl_flag to see if anyone is waiting for it. If no one is waiting, we simply set sl_owner to zero and sl_lock to our PPDP. Then we restore the interrupt mask from before we had the lock, decrement the spinlock depth, and we're done. If we find there is someone waiting for the lock, the process is still not much more complicated. We look through the sl_arb array to find out who is waiting for it. Then we set sl_owner to the PPDP of the processor that is waiting, leaving sl_lock at zero. The lock remains locked, but now the next processor in line is the owner of it. Recall that in wait_for_lock() the processor is looking for either sl_lock to become nonzero or for sl_owner to match its own PPDP. When it sees sl_owner change to its own PPDP, it knows that it now owns the lock and can continue. Exploring the system: To display the io_tree_lock: q4> load struct lock from io_tree_lock q4> print -tx
|
Semaphores Now that we've covered spinlocks, let's have a look at the other synchronization primitive offered by the kernel: semaphores. Semaphores in the HP-UX kernel can be roughly divided into two types: mutual exclusion semaphores, or mutexes, and synchronization semaphores. Mutual exclusion semaphores are further divided into alpha semaphores and beta semaphores. The key difference between an alpha semaphore and a beta semaphore is that alpha semaphores are used to protect data structures, which must be consistent when a context switch occurs. It is assumed that a structure is inconsistent while the lock is held. That's the idea of the lock to prevent access while the structure is inconsistent. For that reason, a process can't sleep while an alpha semaphore is held. Over time, the alpha semaphores have been replaced with beta semaphores such that only one remains now: the file system semaphore, filesys_sema. Alpha semaphores are now officially deprecated, so there will be no new alpha semaphores created. The filesys_sema is the last. There are several differences between mutual exclusion semaphores and synchronization semaphores. Table 12-2 lists the key differences. Table 12.2. Comparison of Semaphore TypesMutual Exclusion Semaphores | Synchronization Semaphores |
|---|
Lock and unlock operations are always done by the same thread. | Lock and unlock are normally done by different threads. When the first thread locks the semaphore, it blocks. When another thread unlocks the semaphore, it allows the first to proceed. | Semaphores are initialized to one. The first lock will succeed, all following locks will block. | Semaphores are initialized to zero so that the first lock will block. | Semaphores have only two states: locked or unlocked. For this reason, these are also called binary semaphores. | Semaphores can take any value. For this reason, these are also called counting semaphores. |
Alpha Semaphores The actual implementation of alpha semaphores is fairly straightforward. The tricky part dealing with contention between processors is handled using a spinlock. Alpha semaphores are represented by a struct sema data type, also called a sema_t. The first field in a struct sema is a pointer to a spinlock, sa_lock. This protects the semaphore structure from concurrent access. Any time the semaphore structure is modified, the code first grabs the sa_lock spinlock, then modifies the semaphore, then releases the spinlock. In addition to the sa_lock field, there are two other fields sa_count and sa_owner which implement the core of the semaphore's functionality. sa_count is one if the semaphore is unlocked and zero if it is locked. sa_owner is a pointer to the thread that owns the semaphore if it is locked. Because there is only one alpha semaphore in the system, there are a few alpha semaphore routines that are no longer used. For example, pxsema() and vxsema() are used to release one semaphore and acquire another in the same operation. Since there's only one semaphore, there's never a need to do this. The following are the more useful semaphore functions: initsema() initialize a semaphore. psema() acquires a semaphore. vsema() releases a semaphore. owns_sema() checks that a thread owns the semaphore. sema_add() adds a semaphore to a thread's list of semaphores. sema_delete()removes a semaphore from a thread's list.
Most of these routines are very simple. initsema() initializes the fields in the semaphore, setting the sa_count to one and allocating a spinlock structure for sa_lock. sema_add() and sema_delete() are actually more complicated than they need to be. They maintain a linked list of semaphores owned by a thread. The kthread structure has a field, kt_sema, which points to a list of owned semaphores. Within the semaphore, the sa_next and sa_prev pointers continue the list. However, since there is only one alpha semaphore, this list will either be empty or contain one entry, the filesys_sema. The owns_sema() routine simply checks to see if the sa_owner field is equal to the current thread. Acquiring a semaphore with the psema() routine can be complicated. The first step is to lock the spinlock associated with the semaphore. Next, we check sa_count. If it is one, indicating it is free, then we set it to zero, set sa_owner to the current thread, and release the spinlock. The complicated part comes in if we find that the semaphore is already owned. Because a semaphore can be held for a long time, we don't want to just spin waiting for it we want to be able to context-switch and let the processor do other work. On the other hand, changing context is an expensive process. If the wait is going to be a short one, we'd rather not do the context switch. To balance out these requirements, when we try to get a semaphore and find it locked, the first thing we do is a short spin wait. The routine psema_spin_1() is called to spin for up to 50,000 clock cycles trying to get the lock. If we fail to get the lock after 50,000 cycles, we then call psema_switch_1() to give up the processor and let another process take over. When we return from psema_switch_1 (when it's our turn on the processor again), we go into another section of spinning, this time by calling psema_spin_n(). The difference between psema_spin_1() and psema_spin_n() is that psema_spin_n() uses an arbitration mechanism to determine how long to spin and who should get the semaphore next. The semaphore has a field, sa_turn, which says which SPU is next in line in the waiters list. Each time we get ready to spin on the semaphore, we first look at the sa_missers[] array in the semaphore. This array keeps track, in priority order, of the SPUs that are waiting for the semaphore. The earlier entries in sa_missers have been waiting longer and thus have a higher priority for getting the semaphore. If the current SPU isn't in the sa_missers[] array it gets added at the end of the list. Now we look at the sa_turn member in the semaphore and find out whose turn is next. We find that SPU in the sa_missers array, and if it is farther down the list than we are, we set sa_turn to our own SPU, indicating that we're next in line. This sa_turn field has two effects. First, when we're spinning, waiting for the semaphore, we spin longer if it's our turn. If sa_turn equals our SPU, then we'll spin for 50,000 cycles waiting for the semaphore. If not, we spin only 5,000 cycles. Second, once we find the semaphore is free, we acquire it only if sa_turn points to our SPU or it is the value SA_NONE. We go through this cycle of "find out whose turn it is, then spin" nine times before we context-switch. We continue doing this until we get our turn at the semaphore. Figure 12-3 shows the flowchart of the process of acquiring an alpha semaphore. Figure 12-3. Flowchart of Alpha Semaphore Acquisition 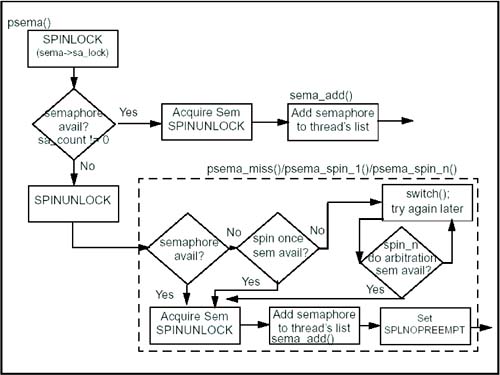
As in the spinlock case, releasing the semaphore is trivial. We call sema_delete() to remove the semaphore from the thread's list, then we set sa_count to one, indicating the semaphore is free. An interesting construct is seen in the semaphore code and in fact is used in a lot of code that uses spinlocks. In order to avoid contention for the spinlock, the semaphore code grabs the spinlock only when it has to that is, when it is going to make a change to the semaphore. The spinlock isn't needed when reading the contents of the semaphore, only when modifying it. However, if the code reads the semaphore and finds that it needs to change it as in the case when it finds it free and is now going to lock it then the spinlock has to be acquired in order to make the change. But there's one more test that has to be done: now that you've got the spinlock, you have to make sure that the structure didn't change since you last looked at it. This leads to code that looks like this: if (sema->sa_count == 1) { SPINLOCK(sema->sa_lock); if (sema->sa_count == 1) { sema->count = 0; sema->owner = u.u_kthreadp; } SPINUNLOCK(sema->sa_lock); }
We check the semaphore; if it's free, we grab the spinlock. Then we check to see if it's still free, and only then can we lock the semaphore for ourselves. Exploring the system: To examine the file system semaphore: q4> load struct sema from filesys_sema q4> print -tx
|
Beta Semaphores Most of the functions on beta semaphores are similar to those for alpha semaphores. One concept that is different is the idea of disowning a semaphore. There are a few cases when a semaphore must be acquired and held until an I/O operation completes. When the I/O completes later and an interrupt is generated, the "current thread" is whichever one is running when the interrupt occurs. Before the I/O starts, the system disowns the semaphore, leaving it locked but without an owner. Then, when the I/O completes later, the system can unlock the semaphore even though it is in a different thread context. Internally, there are several differences between the alpha and beta semaphores. The beta semaphore structure itself has three fields: b_lock, owner, and order. b_lock is a bitmask value. The lowest order bit is on if the semaphore is currently locked, and the second bit is on if someone is waiting for the semaphore. The owner field will be zero if the semaphore is not locked, negative one if the semaphore is locked but disowned, or it will point to the thread which owns the semaphore. The order field is used to ensure that if a thread acquires several semaphores, it does so in the correct order. To prevent a deadlock situation, all semaphores have an order. Every time a semaphore is acquired, the system checks all other semaphores already held by that thread. The order of the new semaphore must not be less than the order of any semaphore already held. This check of a semaphore order takes some extra time and really shouldn't be necessary. Semaphore should never be violated if there are no bugs in the system. Because of this, this feature is actually turned off in most kernels. When a new kernel is under development, semaphore order checking is turned on. When the kernel is ready for release, the kernel is rebuilt in "performance mode" with this check turned off to eliminate the overhead. Another difference between the alpha and beta semaphore implementations is the lack of a spinlock and information about waiters in the b_sema structure. This information is kept in a separate structure, the beta semaphore hash. The system maintains a single table of information about beta semaphores, called b_sema_htbl. This table is an array of struct bh_sema. Each bh_sema structure has a pointer to a spinlock and forward and backward pointers to a doubly linked list of threads. Entries in this array are accessed by running the address of the semaphore through a hashing algorithm to get an index into the array. The spinlock entry from this beta semaphore hashtable is used just as the spinlock is on an alpha semaphore. Before modifying the semaphore, the code must acquire the spinlock. The spinlock is released immediately after the semaphore is updated. The thread pointers make up a list of threads that are waiting for the semaphore. The bh_sema->fp points to the first waiting thread, and the remaining threads are linked using the kthread->kt_wait_list pointer. bh_sema->rp points to the tail of the list, and kthread->kt_rwait_list is the reverse pointer within the thread structure. When a thread tries to acquire a beta semaphore and finds it locked, it sets the second bit in b_lock by ORing b_lock with SEM_WAIT. It then inserts its thread pointer onto the end of the list of waiters. When the semaphore becomes available, the b_vsema() routine checks to see if the SEM_WANT flag is set. If so, it goes to the list of waiters and gets the first entry off the list. It then checks the kt_beta_misses value from the thread structure of the first waiter. This value indicates the number of times the thread tried to get the semaphore, found it locked, and went to sleep. If this value is less than 10, then the semaphore is simply freed. If the value is 10, indicating that the thread has slept at least 10 times waiting for the semaphore, the semaphore is donated to the thread. Exploring the system: To display the pid_sema beta semaphore: q4> load struct b_sema from &pid_sema q4> print x b_lock order owner
To display the beta semaphore hashtable entry for pid_sema: q4> idx = (((&pid_sema) >> 6) & (64-1)) q4> load bh_smea_t from &bsema_htbl skip idx q4> print x beta_spinlock fp bp
|
Synchronization Semaphores Where mutual exclusion semaphores are generally used to protect data structures from simultaneous access, synchronization semaphores are used to synchronize events. The implementation and usage are almost the same as for the mutual exclusion semaphores. The data structure for a synchronization semaphore is struct sync, or sync_t. A struct sync has many of the same fields as the other semaphores. s_lock is a pointer to a spinlock to protect the semaphore during modification, count is the current value of the semaphore, wait_list is a pointer to a list of threads waiting for the semaphore, and order is the locking order. The two main operations on a synchronization semaphore are psync() and vsync(). psync() corresponds to the lock operation on a mutual exclusion semaphore. The psync operation first decrements the count field in the semaphore. If the result is less than zero, the process blocks. If the result is greater than or equal to zero, the process continues. The vsync() operation is the inverse. It increments the value in the count field. The count field can be thought of as the number of psync() calls that can be done before blocking. Because the count field can take on values other than just one or zero, you can also think of a synchronization semaphore as keeping track of how many of a particular resource are available. In this case, the psync() call corresponds to using a resource, and vsync() corresponds to freeing one up. There is an additional call, cvsync(), which is a conditional vsync(). It performs the vsync operation only if there is a thread waiting for the semaphore. An example of how this might be used is if you have a thread that uses a resource, such as memory, and another that frees up that resource. If the first thread finds it is low on memory, it can call psync() to wait until more is available. The thread that is freeing memory can call cvsync() once it has made more memory available. This technique is used by the scheduler to suspend itself when memory is critical and to wait for the statdaemon to reactivate it when memory becomes available. |