Types
In programming, we use the term ‘type’ to describe a particular kind of value. For example, C++ and Java programmers will be familiar with types such as int, float, and double. For each type, the compiler knows the following information:
-
How much memory to allocate when we create a value of this type
-
What operations are allowed to be performed using this value
The concept of types is fundamental to strongly typed programming languages, including all .NET languages. In a strongly typed language, the type of value stored in each variable is known at compile time, so the compiler can predict how we intend to use each variable, and can therefore tell us when we are going wrong.
A type is a contract. A variable of a particular type guarantees contractually that it will contain all the data you would expect a value of the given type to have, and it can be processed in all the ways we would expect a value of that type to be processed. We sometimes call the contract of a type its interface.
| C++ Note: | Having been used to defining the interfaces of your C++ classes in header files, you will already be aware that C# has no header files. The definition of C# types is included in the compiled assembly as metadata. You should also remember that the C# compiler does not worry about the order of type declarations in your source code. |
To a computer all data is just chains of ones and zeroes. When we have a variable in our program, ultimately that variable is simply holding a binary number of some kind. So, when we ask the computer to display that variable on the screen, perform a calculation on it, or retrieve one of the variable's properties, the computer needs to know what type the variable contains in order to know how to interpret its value, and thus respond to our request. For example, an integer and a single-precision floating-point number can both be stored in four bytes of binary data. Take the following four bytes, for example:
00110110 11011011 10001010 01110100
If the value were interpreted as an integer, it would represent the number 920,357,492. Interpreted as a single-precision floating-point value, it has the approximate value of 6.5428267E-6. So, if a variable contains this binary number, and we ask .NET to add one to it, the result is going to depend not only on what value is in the variable, but also on the variable type.
A type describes the purpose of any string of ones and zeroes in memory. It enables us to compare values of two integers and see if one is greater than another, retrieve a string representing a value, or modify the value in a particular way.
The .NET Type System
The .NET Framework includes a large selection of types that assists software development in the .NET languages. All types we define and use in our own code must conform to the .NET Framework standards to ensure that they operate correctly in the runtime environment. There are two important specifications that define these standards, the Common Type System (CTS) and the Common Language Specification (CLS).
The Common Type System (CTS)
The Common Type System shows compiler writers how to declare and use types used in the .NET runtime. It defines rules that all .NET languages must follow in order to produce compiled code that can run within the Common Language Runtime (CLR). The CTS provides an object-oriented framework within which individual .NET languages operate. The existence of this common framework is crucial for ensuring type-safety and security at run-time, and also facilitating cross-language integration. In essence, the Common Type System is the backbone of the .NET Framework.
Figure 1 shows how the Common Type System is organized:
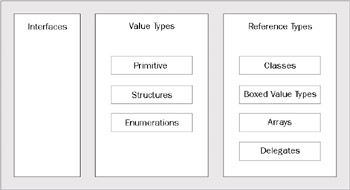
Figure 1
The diagram shows how the Common Type System makes a clear distinction between value types and reference types, which are discussed below. It also allows us to define pure interfaces; an interface is a simple definition of a contract, which is then implemented by another type (or types) – it separates out the definition of a contract from the implementation of that contract. All of the other types combine the above two things.
| C++ Note: | Interfaces are akin to pure abstract classes. Unlike in C++, a C# class may only inherit from a single base class. However, a C# class may additionally inherit from multiple interfaces. |
| Java Note: | Like Java, C# supports single inheritance of classes but multiple inheritance of interfaces. Unlike Java-however, C# allows explicit implementation of interfaces, which avoids problems with naming conflicts. We'll see this in action later. |
The Common Language Specification (CLS)
While the CTS defines how types are created and managed within the runtime, the Common Language Specification is more concerned with language interoperability. The CLS describes a minimum set of features that must be supported by any compiler targeting the .NET runtime. While we're primarily C# developers, it is important to understand the significance of .NET's language independence.
The CLS makes it extremely easy to use several different programming languages in the same application. Whenever we compile source code written in a CLS-compliant language, it is compiled into a standard .NET Framework byte code format called Microsoft Intermediate Language (MSIL). The CLS ensures that certain types and language constructs are all compiled to the same MSIL equivalents whatever the language used. This means we can easily mix-and-match C#, Visual Basic .NET, Managed Extensions for C++, Visual J#, or JScript .NET within the same application, provided we only use CLS compliant types in any public interfaces declared in our code. To ensure this, the C# compiler can be instructed to check the code and issue warnings if we break any rules.
The use of an intermediate byte code format will be familiar to Java developers. Just as Java is typically compiled to byte code before being run in a managed environment (the Java Virtual Machine), so are C# and other .NET languages compiled to MSIL before being run by the .NET Common Language Runtime (CLR). One difference is that Java optionally allows the byte code to be interpreted at run time rather than compiled to native code, while MSIL is always compiled, either by the Just In Time compiler (JIT), or as a pre-JITted assembly loaded from the Global Assembly Cache (GAC). The other important difference is that the language-neutral nature of MSIL was designed into the .NET Framework from day one. As mentioned earlier, the CLS effectively specifies a set of rules that define how different languages should compile to MSIL and this facilitates language interoperability.
We need to make an important distinction here. We have a tendency to assume that the C# language is so closely tied to the .NET runtime that CLS compliance is an inherent property of the language. Actually C# is a type-safe, feature-rich, object-oriented language in its own right, and it's perfectly capable of writing code which is not CLS-compliant. It has primitive types that are not part of the CTS, for example. In this book, while we will predominantly be talking about the .NET type system, we will also talk about the way the C# compiler targets the .NET runtime when it compiles your source code. We'll see, for example, how some of C#'s non-CLS features are exposed to other CLS-compliant languages.
It is also worth pointing out here that language interoperability is not just a gimmick. The CTS and .NET runtime together support many more features than the subset defined by the CLS. Different languages expose different, larger subsets of these features, though at times they overlap. So it is possible that a particular language may be more suitable for certain parts of an application. As all languages share the common ground defined by the CLS, we have a guaranteed interface between these languages.
Apart from .NET languages, there are also a number of CLS-compliant languages from third-party vendors, such as COBOL (Fujitsu), Perl and Python (ActiveState), and Smalltalk (Quasar Knowledge Systems).
Before we look at the details of value types and reference types, it's useful to know that all the types in .NET are completely self-describing. This includes things such as enumerations and interfaces. A compiled .NET assembly (an .exe or a .dll) includes metadata, in which all the details of the types defined and used by the assembly are given. For those types defined in the assembly, we can use reflection to interrogate their definition. This is useful during development, where we don't need header files or type libraries to identify what properties and methods an object exposes. It is also crucial at run time, where the CLR uses this information to dynamically resolve method calls during JIT compilation. This information is stored in a compiled .NET assembly and is used extensively by the CLR. We'll cover metadata in more detail in Chapter 8.
Value Types and Reference Types
Value types often represent entities that are essentially numerical in nature, such as the date and time, colors, screen coordinates, and so on. Such entities can be represented by a simple binary number of a fixed length – the only complication is in interpreting the meaning of the number. Value types are typically small and exhibit quite simple behaviors, perhaps just providing an interface for reading and writing the underlying value.
Value Types and the Stack
An example of a simple value type is an eight-byte long integer that can be used to represent a very large range of dates and times. This number can be interpreted as an offset of a number of time intervals from a fixed point in time. .NET has a 64 bit DateTime type that does just that – it represents the number of ticks (units of 100 nanoseconds, or 10−7 seconds) since 00:00:00 on the first of January, 1 A.D (C.E.), at a particular point in time. Such values represent different instances in time quite effectively. The type, then, provides functionality allowing us to extract the year, the month, the day, the hour, minute, second, and so on, from the simple binary value, in a form that we can make use of.
Since this value type actually consists of very little data, it is easy to pass DateTime information around in a program. If we create a variable aDate to hold a DateTime, it will need eight bytes of storage exactly. If we create another variable bDate to hold a DateTime, it too will take eight bytes of storage. If we now write bDate = aDate;, the eight bytes of data in aDate can be quickly copied and placed into bDate.
When used as local variables or member fields, value types are allocated on the stack. This is an efficient (but limited size) area of memory used strictly for storing local variables (variables declared inside method bodies). The effect of the above actions may be shown schematically as follows. First, we declare two DateTime value types representing different dates:
DateTime aDate = new DateTime(1994, 08, 28); // 28th August 1994 DateTime bDate = new DateTime(1996, 07, 23); // 23rd July 1996
Then, we copy one date to the other:
aDate = bDate; // copy date
The effect on the running thread's stack is shown in the following diagram. On the left is the situation immediately before the copy, and on the right is the situation after the copy.
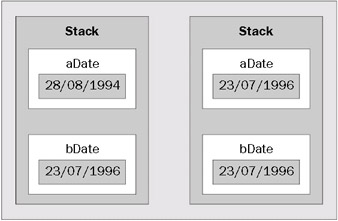
Figure 2
Value types exhibit copy-by-value semantics; when we copy one value type object to another, the compiler performs a byte-by-byte copy of our object. Value types are useful when we don't care how many copies of an object we create; all we care about is the value. When we pass a value type object into a method, the compiler creates a local copy of the object. When the method returns, the memory that the local copy of the value type object was using is automatically reclaimed. This means there are some important limitations to the kinds of uses to which we can put value types.
Reference Types and the Managed Heap
Since value types have fixed data size, they can be copied quickly and be processed faster then more complex types, such as arrays. We'll cover arrays in more detail towards the end of the chapter, but for now, we just need to appreciate that an array is not of a limited, fixed size. When we create a variable myArray to hold an array of integers, it is not clear how many bytes of storage it will need – it's going to depend on the size of the array we put into it. But, when .NET creates a variable, it needs to know how much space to allocate for it. .NET resolves this issue using a fixed size piece of data called a reference. The reference value is always the same number of bytes, and refers to a location in the part of the system memory called the managed heap.
The managed heap is a much larger area of memory than the stack but is slower to access. This is similar to a C runtime heap except that we only use it to allocate memory; we never specifically free memory from the managed heap. The CLR handles all of this housekeeping automatically (hence the term managed).
If we create an array of eight integers (which will require 32 bytes of space to store the array's members), it is created by allocating 32 bytes of the managed heap. When we place that array into the myArray variable, the location of the array on the managed heap (a reference to the array) is placed into the variable itself. The myArray variable that contains this reference is (like all local variables) held on the stack. The memory pointed to by the reference is on the managed heap.
If we then create another variable myArray2 to hold an array of integers, and then write myArray2 = myArray;, the value of that reference is copied into myArray2 so that it points to exactly the same array of integers that myArray did. Arrays, like all classes, are reference types.
We can see this happening schematically. First, we define two array variables, initializing one of them to refer to a new instance on the managed heap:
int[] myArray = new int[8]; int[] myArray2;
Then, we'll assign one array to the other. Remember, this only copies the reference:
MyArray2 = myArray;
The result of these operations is shown in the following diagram. On the left, we have the running thread's stack and the managed heap immediately before the above assignment; on the right the situation is shown after the assignment. Note that the reference variables myArray and myArray2 now both refer to the same array instance:
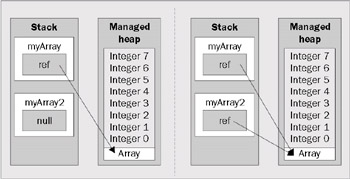
Figure 3
So, reference types represent entities that have a unique identity – they exist in one place on the managed heap, and are referenced from variables using this identity. When we defined an integer array and created an instance of this, the CLR allocated memory for the object and returned us a reference to this new object. When we copied the array into another variable, we just copied the reference. We still only have a single Array instance, but there are now two variables referring to it. Reference types exhibit copy-by-reference semantics. Likewise, when we pass a reference type into a method, the method receives a copy of the reference to our object, not a copy of its value.
Value Types and the Managed Heap
In a lot of .NET literature, you'll find the generalization ‘value types are stored on the stack’. This is misleading. For example, an array is a reference type, so it is stored on the managed heap. But if we declare an array containing value-type entities, these values will be stored inline within the array, so they will actually be stored – as value types – on the managed heap. When we retrieve one of these values from the array, we don't get a reference to the location of the value on the heap, we get a copy of the value from the heap available for local use. The relevant distinction between value and reference types is that reference types are stored in a unique location on the managed heap; value types are stored wherever they are used.
Understanding .NET Memory Usage
Right now, Java developers will be thinking that value types are similar to primitive data types, while reference types are like classes and are heap allocated; C++ developers may be thinking of value types in terms of structs and reference types in terms of reference variables or pointers to dynamically-allocated memory. This is partly true in each case, but there are some important points to consider.
Where reference types are concerned, C++ developers will need to get used to not thinking in terms of pointers. Although this is more-or-less what happens behind the scenes, the CLR moves objects around on the managed heap and adjusts references on the fly while the application is running. Since we don't notice this at run time and it's not obvious from the source code, it confuses matters if you mentally try to translate between C# and C++ as you write. For example, in C# the syntax for accessing a value type is no different from that for accessing a reference type. In C++ you might have the following
SomeClass *pClassOnHeap = new SomeClass(); pClassOnHeap->DoSomething(); delete pClassOnHeap;
However, in C#, the ‘->’ syntax is only used in unsafe code blocks for backward compatibility. In normal situations, the ‘.’ should be used to access the type's methods as follows
SomeClass pClassOnHeap = new SomeClass(); pClassOnHeap.DoSomething(); pClassOnHeap = null;
Note also that we do not explicitly delete the heap-allocated variable when we have finished with it. We just nullify the reference and leave the rest to the garbage collector. Once the garbage collector determines that the object is no longer accessible through a reference stored anywhere else, it will become eligible for disposal. This will be familiar to Java and Visual Basic developers but may look like sloppy code to a C++ developer. This is discussed in more detail in Chapter 5 where we'll be looking at the object lifecycle.
Initializing Variables
When a variable of any type is created, it must be initialized with a value before being accessed. If we forget to put a value into a local variable and then try to use that variable in a calculation, the C# compiler will give an error. This is very different from C++ where it is the programmer's responsibility to check for this problem, and from Visual Basic where local variables are automatically initialized to suitable default values.
The only case in which the C# compiler will initialize variables on your behalf is for variables declared as fields in a class or struct. This simple compile-time check can save hours of debugging as it prevents you inadvertently retrieving junk values from memory left over from other programs.
Everything is an Object
It is important to remember here that any type within the .NET environment, whether a value or reference type, is an object. This means that every type will inherit explicitly, implicitly, or indirectly from System.Object. This is similar to the situation in Java, where there is a single rooted class hierarchy, with every class inheriting in some manner from java.lang.Object – except that in .NET it also applies to non-reference types. We'll explore some of the consequences of this throughout the book.
EAN: 2147483647
Pages: 90