Correctly Using Exception Handlers
A lot of computer scientists warn us not to use exception handlers as general error handling. I disagree. Why not? They work, and they work well. And the last thing you want to do is manually propagate an error out of a function call stack that’s eight levels deep. The exception mechanism already does this for you!
My goal here is not to teach you how to use exceptions; plenty of good programming books offer that information. Instead, what I’m doing here is giving you tips on how to use exceptions most effectively with the end goal of creating good software that handles error situations appropriately by:
-
Not dying
-
Not issuing angry messages directed at the user
-
Not leaving resources open and causing memory leaks
Now in theory, the final bullet item shouldn’t be a problem if your program is shutting down. (But experts argue over how much the popular operating systems—most notably, Windows— really do clean up after a program shuts down.) However, where you run into trouble is if you handle an error situation appropriately and therefore your program doesn’t shut down. But what if the error keeps happening, and each time you’re allocating more and more resources? Then your user’s computer could eventually run into a low-resource situation.
In the following sections are some tips that will help you make exceptions work for you.
Handle All Exceptions
Please make sure you handle all your exceptions. This includes exceptions generated by any third-party library you might be linked to. If I forget to handle an exception, here’s the error I see using gcc:
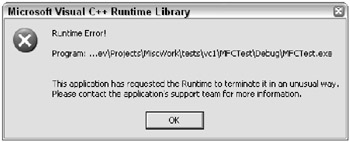
This application has requested the Runtime to terminate it in an unusual way. Please contact the application's support team for more information.
The bold emphasis in this error is my own. Wouldn’t your support team love to get a phone call like this:
Angry customer: “Hey, dude, your software shut down and it told me to contact you.”
Support team member: “Tell me exactly what happened.”
Angry customer: “I dunno, I was just using it and the program died, and I saw this message that says I need to call you.”
Support team member: “What were you doing when it died?”
Angry customer: “What, you sound like you’re blaming me for this problem?”
Support team member: “Uh, no, uh, I just need to know what situation was taking place when the software died.”
Angry customer: “I already told you! I was using it!”
Support team member: “Okay, let’s try a different approach. What do you see on the screen?”
Angry customer: “Nothing!”
Support team member: “So your screen is blank?”
Angry customer: “No, you idiot! I see a message…”
You can see where this is headed. And you can also imagine the bug report you’ll receive, and you can see having to fill in the “cannot reproduce” check box in the bug report after you’ve messed with it. And then a week later another customer calls with the same problem. And then another, and another, and soon the VP of Engineering is coming down on you and the other programmers to find the problem and fix it. But how do you find the problem if you can’t reproduce it? And worse, imagine this thought that will keep you up in the middle of the night: Where is that message coming from?
| Warning | If you’re a Windows programmer, don’t think that you’re immune to mysterious messages. I placed the same code that caused gcc’s runtime library to dump the preceding message inside a nice, unsuspecting MFC application. Figure 9.1 shows the error I received inside a message box. |
Remember, if you’re just not sure what exceptions could be called, use the catchall exception handler of an ellipsis, ..., in C++.
Clean Up Resources Appropriately
One common mistake in exceptions is that people forget to clean up their resources. Cleaning up can be tricky at times, so you’ll want to spend some time to make sure you get it right. The general idea is to put cleanup code inside your exception handler.
But think about this scenario: You have a function that opens a file, and then the function opens another file. But during the second file opening, an exception occurs. Inside your exception handler, you have code that closes both files. The problem is the second file’s handle is not valid, since the file never opened. Oops!
One way to code around this problem is by wrapping exception blocks around exception blocks. I’m not particularly fond of that approach, however, as it makes for code that’s hard to read. Instead, a simple solution is to initialize your file pointers to 0 (or NULL) and then inside the exception handler, first check to see if each file pointer is 0. If the file pointer is not 0, then close the file. Otherwise, skip it.
Unfortunately, this causes another coding problem that I’m not fond of: duplicate code. You want to clean up your resources if an exception occurs but also if an exception doesn’t occur. The following complete program (which I used gcc to compile) demonstrates a simple solution to this problem:
#include <iostream> #include <string> using namespace std; class SomeException { public: string filename; SomeException(string afilename) : filename(afilename) {} }; class FileInfo { public: string filename; FileInfo(string afilename) : filename(afilename) { cout << "Opening " << filename << endl; } void Close() { cout << "Closing " << filename << endl; } void Process() { cout << "Processing" << endl; } }; FileInfo *MyFileOpener(string filename) { // Force a demo exception if (filename == "another.dat") { cout << "Forcing exception..." << endl; throw new SomeException(filename); }
cout << "Opening " << filename << endl; return new FileInfo(filename); } void FileStuff() { FileInfo *file1 = 0; FileInfo *file2 = 0; try { file1 = MyFileOpener("testfile.dat"); file2 = MyFileOpener("another.dat"); file1->Process(); file2->Process(); } catch (SomeException *e) { cerr << "LOG FILE: Unable to open " << e->filename << endl; } // Clean up! if (file1 != NULL) file1->Close(); if (file2 != NULL) file2->Close(); } int main() { FileStuff(); } I’m assuming you’re fluent in C++, so I won’t walk you through this code line by line; instead, I’ll make some general comments about the code. (However, I would like to point out—in case you’re not aware—that the 1998 ANSI standard of C++ now supports initialization of object members by following the constructor name with a colon, then the member name, then the initial value for the member; you can see I do this in both the SomeException and FileInfo classes.)
As you can see, this code includes a class that simulates the opening, processing, and closing of a file. (I like to create my own classes for such work to help with encapsulation; a real program would actually open the files, of course, rather than just print out a silly message as this sample does.) To simulate an exception, I’ve hard-coded a test for whether the filename is a certain value, and if it is, I throw the exception. This, of course, occurs inside the routine that is supposed to create a new instance of the FileInfo class. Thus, when this line runs
file1 = MyFileOpener("testfile.dat"); I will get an exception, causing file1 to remain at its initial value of 0. I next catch this exception and write it to an error log. But thanks to the beauty of the exception-handling system, the code will continue running after the exception handler. Thus, whether I get the exception or not, I can clean up. I do so by checking the value of file1 and file2 before calling each object’s Close method.
| Tip | Some languages (notably Java and Borland’s Object Pascal) have a construct (called finally in Java and Object Pascal) that gets called whether the exception occurs or not. This is a great place to put your cleanup code. The idea is that you put your throwable code inside a try block. Then you put cleanup code in the finally block. |
What about Exceptions in Constructors and Destructors in C++?
If you use exceptions in constructors and destructors, you need to be extremely careful to get it all right. And part of the problem here isn’t just what you do but rather what the experts all say. The experts disagree on how and whether to use exceptions in constructors and destructors:
-
Should an exception throw an exception? And if so, what’s the best way to handle it?
-
Should a destructor throw an exception? And if so, what’s the best way to handle it?
I know that if I take sides on this issue, I’m going to get letters from people telling me I’m wrong, no matter what I say. But let me point out some things:
-
Not all compilers handle exceptions thrown inside constructors the same way.
-
I’ve heard from people that some compilers might allocate the object itself without deallocating the object if you throw an exception inside the constructor. (But see my point following this list!)
-
None of the compilers call a destructor in response to an exception handler.
| Note | Regarding the second point: I ran a test and found that the gcc does indeed deallocate the object by calling delete if you throw an exception inside the constructor. The compiler does not, however, call your destructor in such a case. I then tested this out in Visual C++ 6.0 and Visual C++.NET, and both of these compilers also deallocated the memory. Apparently doomsayers abound. |
Now just to get you thinking here, let’s say you allocate some resources inside your constructor, and toward the end of the constructor something causes an exception. Suddenly you’re back out of the constructor and inside your exception handler. How do you clean up the resources? The object doesn’t exist (or does it?) and so you can’t call the object’s destructor!
I think everybody would agree with me that this is a mess. Therefore, I suggest clients do either of the following:
-
Don’t allow exceptions to be thrown inside constructors. Instead, include in the class a member variable that holds a status, and check the status after the constructor.
-
Don’t do anything inside the constructor. Instead, have a separate Init member function (or some similar name) that you can call; this Init function can throw an exception, and then you’re free to call the destructor yourself.
-
Put a try/catch block inside the constructor to catch any problems, and then do the cleanup inside the catch block. Then, inside your catch block, rethrow the exception, allowing the code that created the instance to catch the exception.
Regarding the final point, you don’t have to actually rethrow the same exception. Instead, you can make your own exception class called something like ConstructorFailed, for example. And as for cleaning up your resources inside the constructor, you can manually call the destructor function, if you want, simply by calling ~MyClass() but not by calling delete. (Yes, theoretically you can call delete this inside your constructor, but come on, do you really think that’s clean programming style?)
Here’s kind of a silly little program that throws an exception inside the constructor, catches it, does some cleanup, and rethrows the exception. (Now really, you would probably catch an exception that was generated by a function call made by the constructor, as opposed to just throwing the exception as I did here.) You can see in this code how I called the destructor function without deleting the instance. (The gcc compiler required that I use this-> before the destructor name.)
#include <iostream> using namespace std; class MyException { }; class Failable { public: int x; Failable() { try { x = 10; throw (new MyException()); } catch (MyException *e){ this->~Failable(); throw (e); } } ~Failable() { cout << "Cleaning up..." << endl; x = 0; } }; int main() { try { Failable x; } catch (...) { cout << "Oops..." << endl; } } Incidentally, if you’re wondering how I tested whether the compilers deallocate the object if you throw an exception inside a constructor, here’s how. I included these two member functions in the preceding class declaration:
void * operator new(size_t s) { cout << "new..." << endl; return malloc(s); }; void operator delete(void * mem) { cout << "delete..." << endl; free(mem); }; When I ran the program, I saw the messages “new...” and “delete...” appear on the screen, meaning the C++ runtime did indeed clean up everything on gcc, Visual C++, and Visual C++.NET.
But what about destructors? Can and should you have exceptions inside destructors? The answer is yes you can; as for whether you should, it depends on your particular situation. Generally I try to avoid exceptions inside a destructor, because you do have one big problem: On most compilers (including gcc) if you throw an exception in the destructor, the C++ runtime library will not finish deallocating the memory for your object. (You can test this by overloading the new and delete operators as in the preceding new and delete samples, creating an instance on the stack, and then throwing an exception inside the destructor.)
Therefore, I usually recommend the following:
-
Do not throw exceptions inside a destructor.
-
If your destructor calls functions that could throw an exception, wrap the call inside a try /catch block, and handle the exception right inside the destructor. In addition to assuring that your object’s memory will be deallocated, you can also be assured of continuing with your own cleanup code inside the destructor.
Specifying Exceptions in Function Headers in C++
Be careful if you use the throw keyword inside a function header like so:
void b() throw (ExceptionA) { C++ gurus encourage us to use this construct because it provides good documentation for what exceptions the function can throw, and it doesn’t allow any additional exceptions to propagate out of the function. Well, if you’re not careful, you can end up with a problem if your function calls other functions that throw other exceptions. Look at this code:
class ExceptionA { }; class ExceptionB { }; void a() { throw new ExceptionB; } void b() throw (ExceptionA) { a(); } Look closely at what this code does; if you call function b, then b will call function a, which in turn throws an exception that b refuses to propagate. The C++ standard says that in such a situation the C++ runtime library can terminate the application.
Not a good situation. Here’s how you prevent this, regardless of your compiler: Handle all exceptions! In this case, using the throw keyword in the function header is actually a good thing when used properly, because it prevents your function b from being the evil function that threw an exception others weren’t prepared to handle. The key in making this all work, however, is in making sure your function handles any exceptions it receives. The solution is to put an exception handler inside b and include the ellipsis exception handler, like so:
void b() throw (ExceptionA) { try { a(); } catch (ExceptionA e) { throw e; } catch (...) { // Handle the exceptions yourself! HandleSomething(); } } This code rethrows the ExceptionA exceptions that it receives and handles all others. The end result is that your users won’t see a horrible message.
Oh, and by the way, what do you do if you’re using a third-party library that you purchased, and you call a function in the library that has a throw keyword in its function header, and that function doesn’t handle some exception it receives from another function within the same library? You get to call the third-party’s support team and give them a hard time! Because try as you might, you cannot coerce the function into passing the exception outside it. Changing the header file won’t work; you need to change the original source, which is typically a bad idea when dealing with third-party libraries. If you change just the header file, and you’re linking to an object file, the gcc linker will be fine, but you won’t change the behavior of the function. So you’re stuck. Call the support team (and tell them about this really great book you’re reading about usability!).
EAN: 2147483647
Pages: 114