3.3 Microsoft s Extensible Storage Engine (ESE)
3.3 Microsoft’s Extensible Storage Engine (ESE)
Microsoft designed Exchange Server to be a highly reliable messaging server platform that would provide continuous operation, high transactional throughput, rapid recovery, and the full operational and functional capability of a relational database system. There were philosophical concepts kept in mind during the design phases of the Exchange Server database technology. One key thought kept at the forefront of designers’ minds was: What if the database crashes? Exchange Server had to be able to recover quickly and completely. Also, the database had to provide for 7 24 operation and the ability to perform backup operations without shutting down the services. In later versions of Exchange Server, the designers also sought to make the Exchange database engine as self-tuning as possible—eliminating previous issues related to static memory allocation and design rigidity. Finally, the designers understood that the most critical component of performance for Exchange Server would be I/O operations and the efficiency of how they were performed by the database engine.
These philosophies and design points lead Exchange Server developers to select Microsoft’s Joint Engine Technology (JET) as the database engine technology on which to base Exchange Server. JET was an outgrowth of technology that Microsoft had used in other products such as Microsoft Access and Foxpro/Foxbase (formerly owned by Borland). JET had two variants—JET “Red” and JET “Blue,” which Microsoft at one point had planned on converging into a single technology (the evolution of ESE is shown in Table 3.4). JET Red is the variant that has evolved into the current Access product, and it is used in various other places on the client side such as Microsoft Office. JET Red is a single user database engine that was designed to run standalone on an end user’s workstation (as in the case of Microsoft Access). JET Red is not well suited for multiuser access and is not relevant to our discussion. On the other hand, JET Blue was used to develop the Exchange Server data-base technology. Since JET Blue was a multiuser variant, it was much better suited to an environment such as Exchange Server. Although Exchange Server’s database engine was based on JET Blue, it has greatly evolved over the last several years and is hardly recognizable when compared to its original form. In fact, in Exchange Server 5.5, Microsoft renamed the JET variant that Exchange used to Extensible Storage Engine (ESE) because ESE represented significant new technology (a major rewrite) compared to previous JET versions. This was also done for marketing reasons since customers and competitors often cited JET technology as a weakness and shortcoming of Exchange Server. By severing ties to JET, Microsoft had hoped to establish Exchange Server’s database engine in a class by itself. This was only successful to a certain degree since ESE’s roots are still mired in the negative connotations of JET and Microsoft Access. Nevertheless, the marketing aspects and issues are not pertinent to our cause. Realistically, JET/ESE technology in Exchange Server has evolved so far from its original form that any arguments over what to call the technology are a waste of valuable brain cells.
| JET/ESE Variant | Description and Purpose |
|---|---|
| JET NT (JET*.DLL) JET Exchange (EDB.DLL) | Original Exchange database engine variant that was not only used in Exchange 4.0 and 5.0, but also in certain NT services such as WINS (Windows Internet Naming Service). |
| ESE97 (ESE.DLL) | Shipped with Exchange 5.5, providing major performance and reliability improvements over previous versions. |
| ESENT (ESENT.DLL) | Available with Windows 2000 as the Active Directory core database engine. ESENT for Windows 2000 is based on ESE97. Future ESENT versions are based on ESE98. |
| ESE98 (ESE.DLL) | Available since Exchange 2000, further refining and enhancing Exchange database technology. ESE98 is further enhanced in Exchange 2003. |
3.3.1 Industry-standard core technology
Whether you refer to the underlying database technology for Exchange Server as JET or ESE, an understanding of this technology is an important foundation for our discussion of disaster recovery and reliability later in this book. The ESE supports two core database files for Exchange 2000—the property store and the streaming store. The property store (EDB file) is based on a fundamental relational database structure used throughout the years in the computer industry called Balanced Tree database structure, or B-Tree for short. The B-Tree structure is not something that Microsoft invented, but a fundamental structural data design conceived years before in the halls of computer science academia.
B-Tree database structure
B-Tree technology is based on the concept of a data tree. A tree is a data structure that consists of a set of data nodes that branch out at the top from a root node. If you think about this, it is more like an upside-down tree (computer scientists always seems to build trees upside down—not the way God intended them …). The root node is the parent node of all nodes in the tree, and all nodes have only one parent. Also, nodes can have from zero to n child nodes under them. Another type of node in this structure is a leaf node. A leaf node is a node that has no children (no nodes beneath it) where data is typically stored. Within a data tree structure there can also be subtrees, which consist of the structure that exists below a certain node— thus, its subtree. The last important structure in a tree is the pointer. One way to implement data trees that allow for quick navigation of the tree is to place a field in each node called the pointer. The pointer is a field containing information that can be used to locate a related record. Often, most nodes have pointers to both their parent and all child nodes. Figure 3.7 illustrates the concept of data tree structures used in database technology for data storage and organization.
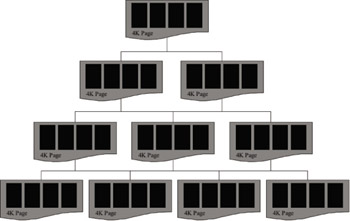
Figure 3.7: Basic B-Tree database structure.
Data trees are viewed and manipulated in terms of several properties. First is the degree of a tree. This is also called the branching factor or fan-out by database design gurus. The branching factor is the maximum number of children allowed for each parent node. In general, trees with a large branching factor are broader and shallower structures. Trees with small branching factors have the opposite effect on their structure. For Exchange, ESE will allow each page to store over 200 page pointers per 4-KB page, providing for a very high fan-out (Exchange databases have B-Tree structures with a degree of less than 4, which translates to high performance access). This ensures (in theory) that any piece of data in a large database can be accessed with no more than four disk I/Os (three pointer pages to navigate through, plus the data page itself ). When a database engine accesses tree structures, tree depth has the greatest impact on performance. The breadth of a tree has less of an effect on the speed at which data in trees is accessed. Tree depth is the number of levels between the root node and a leaf node (lowest level) of a data tree structure. When the depth of a tree is uniform across the entire tree structure (i.e., the distance is the same from the root node to each leaf node), the tree structure is referred to as a Balanced Tree, or B-Tree. In a B-Tree structure, all leaves are the same distance from the root. This ensures consistent and predictable performance access across the entire structure.
There are several varieties of B-Tree technology; the standard B-Tree and the B+Tree are seen as the most common. The B+Tree variant (shown in Figure 3.8) has all of the characteristics of an ordinary B-Tree but differs from the standard B-Tree in that it also allows horizontal relationships to other nodes in the structure that are at the same level. Each data page in the B+Tree has page pointers to its previous and adjacent pages. Although there is some overhead incurred with this design during certain database operations like insert, split, merge, and index creation, the extra pointers allow for faster navigation through the tree structure.
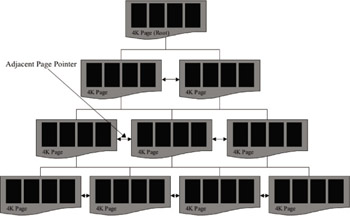
Figure 3.8: Exchange Extensible Storage Engine B-Tree structure.
Microsoft Exchange Server’s ESE uses the standard B+Tree implementation (with some modifications to get some extra features). Keep in mind that the structures I describe here are standard technologies defined and refined by computer scientists and software engineers over many years. The particular implementation that Microsoft uses for Exchange Server is based on these technologies, but may vary based on designers’ goals at Microsoft as Exchange has been developed and evolved. Applied to Microsoft Exchange Server, B-Tree technology is the best fit for the complex, semistructured data requirements of a messaging and collaborative application server. This is a key point since I continually hear speculation from different sources wondering when Microsoft will migrate Exchange Server to SQL Server database technology. The flaw in this speculation is that SQL Server today is not as well suited to storing semistructured data. Microsoft SQL Server’s data-storage strengths lie in structured data storage in which indexes are more static and the data changes less frequently. Applied to Exchange Server, the SQL Server technology would not fair well in an environment where data changes continuously and indexes and data views must be created and recreated dynamically. In recent times, the weaknesses of SQL Server and the legitimacy of these arguments have diminished. In fact, the next version of Exchange Server due sometime in 2005 or 2006 will be built on the on the next generation of SQL Server code-named Yukon. Microsoft still has a lot of work to do, however, to provide the same abstraction layer that is built on top of ESE today on top of Yukon in the future.

Figure 3.9: Exchange ESE page structure.
To return to our discussion of ESE technology used by Exchange Server, let’s dig deeper into how this technology is used to store messaging data. ESE stores all Exchange Server data in a B-Tree structure. An individual table within the Exchange Server information store is simply a collection of B-Trees. The B-Trees are indexed to provide fast and efficient access to data on disk by minimizing the number of disk I/Os required to access the database. An Exchange Server ESE B-Tree database is organized into 4-KB pages. These pages contain either data or pointers to other pages in the database. For faster access, Exchange Server caches these 4-KB database pages in memory. The structure of the ESE page is illustrated in Figure 3.9.
Each 4-KB page comprises a header portion and a data portion. The content of the page header includes a 4-byte checksum, a 4-byte page number, flags, and a timestamp (known as DBTime). We will discuss the importance of the header information to ensuring the integrity of the Exchange Server databases later in this chapter. Exchange Server arranges the B-Tree structures in the database in a fashion that provides for shallow B-Tree structures. This is achieved with a high-fan-out design that ensures that the B-Tree structure is purposely broad and shallow. With the goal of achieving a fan-out greater than 200 (meaning 200 pages across), a shallow B-Tree structure less than four levels deep can usually be achieved. Again, this helps reduce disk I/O by increasing cache hits for pages in the ESE page cache and makes page access as efficient as possible. Dynamic buffer allocation (discussed later in this chapter) performs this wonder by caching most of the internal nodes of the B-Tree, thereby greatly enhancing access to any page in the database.
B-Tree indexes
Another key structure for the ESE is the index. Indexes allow users to quickly access and view database records using whatever key they desire. ESE allows the creation and deletion of indexes dynamically. The combination of these key database structures provides Exchange Server with high performance access to user data while minimizing disk I/O requirements. When you need to have flexibility of access and views of your data while not sacrificing performance, you utilize indexes. In B-Tree technology, an index is just another B-Tree that maps a primary key for viewing the data in a particular way. A secondary index simply maps a secondary key onto a primary key. Indexes are useful for the semistructured data environment of messaging and collaborative applications since they can be dynamically created and deleted, and it is also possible to hide records from indexes (as in the case of the Deleted Items folder). For example, if you modify your folder view in the Exchange client (typically Outlook), Outlook uses MAPI to request that the database engine build a new index (a secondary index) of your data in the information store. This is why there is typically some delay as the new index is created. When unutilized, secondary indexes (which are B-Tree structures themselves) are maintained for 7 days and then are aged out of the database. One of ESE’s strengths is that it allows these indexes to be created without taking the database off-line (other database engines require that indexes be created while the data is off-line). ESE uses the version store (discussed later) to keep track of database transactions that modify tables during the index creation. When the index creation is complete, ESE updates the table.
Long-Value B-Trees
In certain cases, a column in a table may be too large to fit into a single 4-KB database page. One example of this is a message with a body longer than 4 KB (held in the PR_BODY column of the message table). Exchange Server provides for this case through the use of a Long-Value (LV) B-Tree. Long-Value B-Trees take these large data segments, break them into 4-KB chunks (approximately, since there is overhead for the page header), and store them as a special long-value data type. If data needs to be stored in an ESE page that is to too large (i.e., greater than 4 KB) to fit into a single BTree data page, ESE breaks the data into pieces of almost 4 KB (allowing room for headers and overhead) and stores the data in a separate Long-Value B-Tree. In the data B-Tree, there will be a pointer (the Long Value Identifier, or LID) to the Long-Value B-Tree. Using a LID and offset that can be accessed on a tablewide basis allows for efficient access to these chunks. ESE saves space by allowing multiple database records to share the same long value (the single-instance storage benefit) such as a message body for a message sent to multiple recipients. ESE accomplishes this by storing a reference count for each long-value record. Once the reference count reaches zero, the long value can be deleted. Long values are an important and powerful feature of ESE. As such, tools like ESEUTIL will inspect and fix long value references (using the /p repair option) and will also detect long-values that have been dereferenced (called orphaned) but not deleted (using the /x integrity/repair option). ESEUTIL will not remove orphaned long values from the database. However, since Exchange 2000, orphaned long values will be deleted during online database maintenance.
3.3.2 The database engine at work
The Exchange server relies on an embedded database engine that lays out the structure of the disk for Exchange and manages memory (see Figure 3.10). The database engine technology used in Exchange is also used under the covers by other services in the Windows operating system, such as Active Directory. In the case of Active Directory, ESE is implemented in the Local Security Authentication Subsystem (LSASS) utilizing the ESENT.DLL (ESENT uses 8-KB pages, however). The Exchange Server database engine caches the disk in memory by swapping 4-KB chunks of data, called pages, in and out of memory dynamically. It updates the pages in memory and takes care of writing new or updated pages back to the disk. This means that when requests come into the system, the database engine can buffer data in memory so it does not constantly have to go to disk. This makes the system more efficient because writing to memory is cheaper (or faster) than writing to disk. When users make requests, the database engine starts loading the requests into memory and marks the pages as dirty (a dirty page is a page in memory that has been written with data). These dirty pages are then later written to the information store databases on disk.
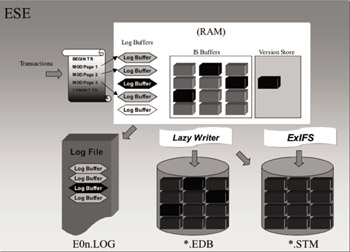
Figure 3.10: The Exchange database engine at work.
Dynamic buffer allocation
Prior to Exchange Server 5.5, the buffer cache that the database engine used to hold its pages (called the information store buffer pool) was of a fixed size. If Exchange Server was thrashing and needed more memory, the administrator had to install more memory on the system and then run the Exchange Server Performance Optimizer to retune the system. To make matters worse, previous versions could only use a maximum of about 20,000 of these buffers or about 80 MB (20,000 buffers 4 KB). With Exchange Server 5.5, however, the development team made some design changes to the way the database engine uses memory. They built dynamic buffer allocation into the database engine so that the database engine dynamically grows or shrinks depending on how much memory is available and whether there is pressure from other services running on the system. If memory is not being used by other services in the system, ESE will take up as much memory as it needs (by default Exchange 2000 limits this to a maximum of 900 MB of RAM). When other services need memory, the Exchange database engine will give up some of its memory by flushing pages to disk and shrinking the size of its buffer. The number of information store buffers that Exchange Server allocates is the single highest memory consumer on an Exchange Server (unless someone has a bad memory leak). Exchange Server 5.5 and Exchange 2000 Server continually monitor the system and the size of the buffer pool. You can easily view the size of ESE’s buffer pool in Windows Performance Monitor by looking at the Database object and monitoring the cache size counter for the Information Store Instance.
Dynamic Buffer Allocation (DBA) had several key design goals. Chief among these was to maximize performance for Exchange Server. Next was to maximize memory utilization on the system. Designers could see no reason to leave memory on the system underutilized and chose to have the store process allocate as much as possible to the information store buffer pool. Another goal kept in mind was to balance the needs of Exchange Server with those of Windows Server. Memory that is not needed should not be used, and finally, when memory is released, it should be released quickly. The Exchange Server database engine very efficiently utilizes the DBA feature to dynamically tune the information store buffer pool. This is most beneficial when the Exchange Server is also running other services such as Microsoft SQL Server. When first available in Exchange Server 5.5, DBA was a bit alarming to some Exchange administrators. This was due to the fact that the STORE process immediately allocated all available memory on the server. In contrast, previous versions of Exchange Server would leave substantial amounts of memory unused. This created quite a stir, and it appeared to some as though Exchange Server 5.5 had sprung a memory leak. System manager education eventually overcame this misconception. Today, for Exchange Server 5.5 and Exchange 2000/2003 Server, the manifestations of DBA have become accepted and are a welcome (to most Exchange administrators) mode of operation for Microsoft Exchange Server. DBA makes optimal use of server resources while maximizing performance. (For more information on tuning Exchange Server memory for optimal database engine performance, see Microsoft knowledge base article Q815372.)
Although caching data in memory is the fastest and most efficient way to process data, it means that while Exchange Server is running, the information on disk is never completely consistent. The latest version of the database is in memory, and since many changes in memory have not made it to disk yet, the database and memory are out of sync. If there are any dirty pages in memory that have not been flushed and written to disk yet, the databases are flagged as inconsistent. Therefore, while Exchange Server is running normally, the databases are technically inconsistent. The only time that Exchange databases are truly in a consistent state is when all the dirty pages in memory are flushed to disk following a graceful shutdown or a dismount of the database in which no errors occurred. Based on this, you can see that, if something goes wrong, the database must be recovered. If you lose the contents of memory because of a server outage before the data is written to disk, you are left with an inconsistent database. To protect against this problem, Exchange Server provides a way to recover from this situation. This is where transaction logging comes in. I will discuss transaction logging more in later sections.
3.3.3 Database 101: Transaction reliability counts!
While the performance features of the Exchange Server database engine are key to the server, scalability, reliability, and recoverability are of paramount concern. Exchange Server is often referred to as a transaction-based e-mail system and the information store as a transactional database. So what does that mean anyway? A transaction is defined as a set of changes, such as inserts, deletes, and updates, to a database in which the system obeys the following absolutes known as the ACID properties:
-
Atomic: Either all the operations in a particular transaction occur or none of them occur.
-
Consistent: The database is transformed from one correct state to another.
-
Isolated: Changes in one transaction do not effect other items that are outside the scope of the transaction, and changes are not visible until committed.
-
Durable: Committed transactions are preserved in the database even if the system crashes.
The database engine commits a transaction only when it can guarantee that the data is durable, meaning that it is protected from crashes or other failures. The database engine will only successfully commit data when there is confidence that transactions have been flushed from memory to the transaction log file on disk. For example, to move an e-mail message from one folder, such as Inbox, to another folder called Important, Exchange Server must perform the following logical operations (at the physical database level, the process is much more complex):
-
Delete the e-mail message from Inbox.
-
Insert the e-mail message into Important.
-
Update the information about each folder to correctly reflect the number of items in each folder and the number of unread items.
Because these operations are done within the boundary of a single transaction, Exchange will perform all or none of these operations. As a result, it does not matter in which order Exchange Server performs the operations. The message can be deleted safely from Inbox first because the system knows that the delete will only be committed if the message is also inserted into Important. Because of transaction-based system qualities, even if the system crashes, it is guaranteed that Exchange Server will never lose an email message while performing any operations on it. In addition, Exchange Server will never end up with two copies of an e-mail message that was moved. Hopefully, your bank uses similar technology when making changes to your checking account.
The version store
The version store is a component of the ESE transaction process that gives Exchange the ability to track and manage multiple concurrent transactions to the same database page. In essence, the version store holds operations that are outstanding from a database transaction that has not completed. This provides the isolation and consistency ACID attributes that ensure consistent transactions to the database. The version store exists only in memory (refer to Figure 3.10) and is a list of page modifications. When a transaction starts, the original page is stored in the version store cache in memory. This allows concurrent session threads to read the contents of the original page, even though a current transaction has not committed. In fact, the transaction may never commit, which is why it is important to have saved the original page contents (providing for a rollback). If a transaction needs to be rolled back, the version store contains a list of all operations performed, and ESE simply needs to undo these operations in order for the rollback to be complete. The version store also protects against page write conflicts by detecting when two sessions attempt to modify the same page. In this case, the version store will reject the second modification. ESE’s version store guarantees that sessions (i.e., users) will see a consistent view of the database and that reads to the database are repeatable. When a session begins a transaction, it always sees the same view—regardless of whether the records in view are being modified by other sessions. The version store is able to discern which view of a record a session should see. The version store is key to ESE’s ability to meet the requirements of the ACID properties for transaction-based systems.
How transaction logging works
Most administrators will agree that the database files are an important aspect of data recovery. However, transaction log files are equally important because they reflect server operations up to the second. With Exchange Server, the database files are written to disk as server I/O bandwidth allows via a checkpointing mechanism that flushes dirty database buffers (pages) to disk. The transaction log files contain information that the database files do not. As a result, the transaction logs are critical to recovery of your Exchange Server. Without them, the Exchange Server databases will be inconsistent and, most likely, unusable. ESE technology uses what is called write-ahead logging. Write-ahead logging is a valuable tool since system failures are bound to occur. Failures in hardware such as disk drive failure, system errors, or power failures are a given. Transaction logging allows the Exchange Server database to remain consistent despite crashes. With write-ahead logging, transactions and data are written to the log files on disk first, before they are written to the database files. Since the information store buffer pool also has database pages cached in memory, these pages are updated in memory, but are not immediately written to disk. Since transactions are appended to the log files sequentially, transaction log I/O is very fast and imposes minimal overhead.
Exchange uses transaction log files to keep track of the information in memory that has not yet made its way to the database on disk. Transaction log files are a sequence of files whose purpose is to keep a secure copy on disk of volatile data in memory so that the system can recover in the event of a failure. If your system crashes and the database is undamaged, as long as you have the log files, you can recover data up to the last committed transaction before the failure. As a best practice, log files should be placed on a dedicated disk or array so that they are not affected by any problems or failures that corrupt the database. Transaction log files also make writing data fast since appending operations and data sequentially in a log file takes less I/O bandwidth than writing randomly to a database file. When a change is made to the database, the database engine updates the data in memory and synchronously writes a record of the transaction to the log file. This record allows the database engine to recreate the transaction in the event of failure. Then the database engine writes the data to the database on disk. To save disk I/O, the database engine does not write pages to disk during every transaction, but instead batches them into larger I/O operations. With Exchange 5.5 this batched checkpoint operation resulted in an I/O pattern that was rather “spike-like” in nature. For Exchange 2000/2003, algorithms have been implemented that smooth out the checkpointing operations, resulting in a more even I/O pattern. Logically, you can think of the data as moving from memory to the log file to the database on disk, but what actually happens is that data moves from memory to the database on disk (refer to Figure 3.10). The log files are optimized for high-speed writes, so during normal operations, the database engine never actually reads the log files. It only reads the log files if the information store service stops abnormally or crashes and the database engine needs to recover from the failure by replaying the log files.
The transaction logs are generated and accessed in sequential order and are stored as generations. Each transaction log file in a sequence can contain up to 5 MB of data (all log files are 5 MB regardless of whether they are full or not). When the log file is full, the store creates a new one and transitions to the new log file by creating an interim file called EDBTMP.LOG, saving the current E0n. LOG to the next generational sequence and renaming EDBTMP.LOG to E0n. LOG. To track transaction log files, ESE associates each log file with a generation number. For example, when Exchange Server starts for the first time, it creates a log file called E00.log for the first storage group (EDB.LOG in previous versions) with a generation number of 1. Additional storage groups’ default transaction logs are enumerated E01.LOG, E02.LOG, and so forth. When that log file is full and the database engine rolls over to a new log file, the new log file becomes E00.log with a generation number of 2 (or the next in sequence), and the old E00.log file is renamed E00nnnnn. log. This sequence number is in hexadecimal format. This continues until the next sequence of log files starts. If you shut down the server and lose all of the log files, when you restart the information store, the database engine will create a new sequence of log files starting with a generation number of 1.
Since log files can have the same name, the database engine stamps the header in each file in the sequence with a unique signature so it can distinguish between different series of log files. Also within each log file are the hard-coded paths of the database files with which the log is associated, along with other information such as timestamps and generation information. Figure 3.11 shows a dump of the header of a transaction log file using the ESEUTIL utility with the /ML parameter (ESEUTIL /ML).
It is important to point out here that transaction logging of streaming store data (*.STM file) follows a different model. Transactions for STM data are actually logged in a write-behind fashion versus the write-ahead logging used by the database engine for the property store (*.EDB file) data.
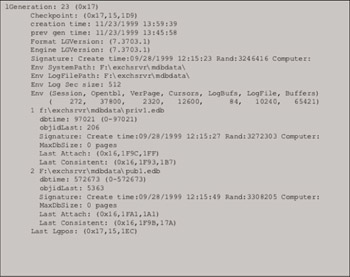
Figure 3.11: Exchange transaction log file header format.
This is because ESE is not directly responsible for managing the STM files; access to these files is managed by the Exchange Installable File System (ExIFS). I will discuss ExIFS more later in the section entitled “ How Exchange stores incoming data.” Data from Internet clients destined for the STM file is written directly to the file by the ExIFS subsystem. This data is then read back through ESE, which references the content with properties and stores these properties along with STM page checksums in the property store (*.EDB file). This is why STM file operations do not require transaction rollback capabilities. In fact, if you enable circular logging (discussed later) for a storage group, no logging occurs at all for STM file operations.
Inside exchange transaction logs
If you were to dig deeper into the inside of a transaction log file, you would also find the most important parts of the log files—log records. Log records contain transactional information and commands like BeginTransaction, Insert, Delete, Replace, Commit, and Rollback. Records of low-level physical modifications to the database are also stored. Figure 3.12 illustrates the format of log records contained within a transaction log file. At a high level, delivering one piece of mail seems to be a rather simple operation.
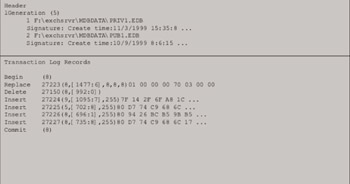
Figure 3.12: Example ESE transaction log file contents.
However, under the covers, it is a complex operation that involves many low-level operations to the database. Also, since a typical Exchange server under load is handling hundreds or thousands of operations from multiple users simultaneously, the operations performed by these transactions are interleaved within the transaction log file. When an Exchange Server database page is modified, the following operations occur:
-
The timestamp on the database page is updated.
-
A new log record is created in memory that includes the timestamp.
-
The page is modified.
-
When modification operations are complete, a commit occurs.
-
Once a commit operation occurs, all log records are flushed to the disk.
-
The database page on disk is updated once the transaction log records have been flushed to disk via the checkpoint process and sufficient I/O bandwidth is available.
The implications of physical logging of every transaction applied to the database are that the database must be in the correct state in order for recovery operations to work. What would happen if something were to go wrong in the database-recovery scenario? What if log files were missing or if the wrong version of the database were restored? What would be the effect of a corrupt log file? For example, what if a log record performed a delete operation, but the data had never been inserted? In another scenario, what if the most current log file generation (E00.LOG) was accidentally deleted? Some recent transactions in a previous log file that had already been flushed to the database could possibly have been undone in the current log file. If E00.LOG were deleted, these rollback operations would never be executed. Thus, the Exchange Server database could potentially become corrupt. This emphasizes the importance of proper database maintenance and not interfering with or second-guessing Exchange Server’s transactional integrity mechanisms.
Logging file record checksumming
We know that the transaction logs protect the database from permanent corruption by allowing transactions to be replayed in the event of a failure. In addition, the database itself has an integrity checksum on every 4-KB page. So what protects the logs? In Exchange 2000/2003, each record in a log file has a checksum. The LRCK (log record checksum) can cover a range of data both before and after its position in the log file. ESE creates the checksum by XORing every 4 bytes in the range (backwards and forwards), all fields in the LRCK, and the generation number of the log file. The generation number of the log file is included when calculating the checksum so that when circular logging is enabled, ESE will reuse an old log file and will not interpret the old records as valid. Each checksum is verified during backup and recovery. If a checksum fails during one of these operations, the operation will stop, logging an event in the application event log with an event ID of 463, indicating the failed checksum record location. During recovery, if an LRCK fails to match the data it covers, it can be for one of two reasons, either a torn write (a partially completed write) at the end of the current log file (E0n.LOG) or data damage (corruption) somewhere else in the log file sequence. ESE handles these two situations differently.
Torn write —Before ESE can act on a failed LRCK, it must first work out where the data damage is. To enable ESE to do this, each log file is filled before use with a data pattern known as the log-file fill pattern. If ESE is replaying transactions in E0n.log, ESE looks for the recognizable fill pattern beyond the LRCK range. If the fill pattern is the only data found beyond the point of the failed LRCK range to the end of the log file, then ESE can safely make the decision that the invalid data was caused by a torn write at the end of the log file sequence and that there are no log records beyond this point. ESE will log an event ID 461 to indicate that it has hit this condition.
Data damage —If, however, ESE either is not replaying transactions from E00.log or finds data other than the recognizable log-file fill pattern in E00.log beyond the failed LRCK data range, there must be more records in this log file. In this case, data that the disk subsystem had confirmed to be successfully written to disk is now no longer matching its checksum. ESE will log an event ID 464 or 465 to indicate this condition.
The log file checksums can be manually verified using ESEUTIL/ML; this performs a quick (i.e., less than a second) integrity check verifying each checksum. This additional level of integrity checking further enhances an already robust system in the Exchange database engine for ensuring that user data is intact. No other messaging server product that I am aware of provides the levels of integrity checking of Exchange 2000/2003.
Reserved log files
Finally, within each storage group or ESE instance, reserve transaction logs are also maintained. These files (named RES1.LOG and RES2.LOG) are needed in the event that disk space on the volume holding transaction logs runs out. While these files rarely get used, they provide an important safeguard against the potential condition that results when disk space on the transaction logging volume is not monitored and runs out. These reserved log files are kept in the default directory where the other log files for a storage group are stored. If the database engine is in the process of renaming the current E00.LOG to the next log generation and there is not enough disk space to create a new E00.LOG (NTFS returns an out-of-disk-space error message to ESE), the reserve log files are then used and are renamed to the current generation number. This fail-safe measure is only activated in the event of an emergency. Once Exchange Server is aware that there is no disk space available to create new log files, the storage group instance must be shut down. When this happens, ESE will flush any transactions in memory that have not yet been committed to the database (dirty buffers) to a log entry in RES1.LOG or ES2.LOG. The reserve log files provide a location for transactions that may be “in flight” during this premature shutdown to be written. Once this flush operation is complete, the storage group can be safely taken off-line, and administrative action must occur (e.g., increase disk space). Also, in this event, the ESE instance will shut down and record this event in the system event log. On an extremely busy server with large amounts of memory, it could be possible that not all outstanding transactions can be safely stored within the confines of RES1.LOG and RES2.LOG. Remember that each log file is only 5 MB in size. While this possibility exists, it is quite remote in nature since, by design, Exchange attempts to minimize the number of outstanding transactions in memory. However, this possibility should serve as a good example of the importance to overall server health of proactive monitoring of available disk space and other measures.
The checkpoint file
Since not all transaction log files are needed to recover a database, database systems provide a method to quickly determine which log files are required. This mechanism is the checkpoint file. The checkpoint file tells ESE which log files are needed to recover from a crash and recover a database to a consistent state. The checkpoint file simply keeps track of the data contained in the log files that has not yet been written to the database file on disk. The database engine maintains a checkpoint file called E0n. CHK for each log file sequence (per storage group in Exchange 2000/2003). The checkpoint file is a pointer in the log sequence that maintains the status between memory and the database files on disk. It indicates the point in the log file from which the database engine needs to start the recovery if there has been a failure. In fact, the checkpoint file is essential for efficient recovery because, if it did not exist, the information store would have to attempt recovery by starting from the beginning of the oldest log file it found on disk and then checking every page in every log file to determine whether it had already been written to the database. The database engine can recover without the checkpoint file, but it will take much longer because all transaction logs must be scanned to search for transactions that have not been written to the database. This process, of course, is very time-consuming, especially if all you want to do is make the database consistent.
Circular logging
Exchange supports a feature called circular logging. The circular logging feature is left over from the days when server disk space was at a premium. Back in the early days of Exchange, there was some concern about running out of disk space and less concern about recovering data. As a result, to maintain a fixed size for log files and to prevent the buildup of log files, circular logging was enabled by default. This means that once five log file generations have been written, the first file in the sequence is reused. The database engine deletes it and creates a new log file in the sequence. By doing this, only enough data is on disk to make the database consistent in the event of a crash. This still provides ESE with the ability to perform a soft recovery, but it makes hard recovery (restore from backup) impossible (I will provide more detail on hard versus soft recovery for Exchange in the next chapter). If you are concerned about protecting your data, the first thing you should do is turn circular logging off on your Exchange server. For Exchange 2000/2003, circular logging is disabled by default (but administrators should always check this setting). While circular logging reduces the need for disk space, it eliminates your ability to recover all changes since your last backup if your information store is corrupted due to a hardware failure. This is because circular logging only maintains enough log files to ensure transactional integrity when recovering from nonhardware failures. Circular logging negates the advantages of using a transaction-based system and sacrifices the ability to recover if something goes wrong with the system and the contents of memory are lost. As a result, it is not recommended for most deployments.
Circular logging works in much the same way as normal logging except that the checkpoint file is no longer just an optimization feature; it is essential for keeping track of the information that has been flushed to disk.
During circular logging, as the checkpoint file advances to the next log file, old files are reused in the next generation. When this happens, you lose the ability to use the log files on disk in conjunction with your backup media to restore to the most recently committed transaction. When (and only when) circular logging is enabled for Exchange 2000/2003, writes to the streaming store (*.STM files) are not transaction logged. This saves disk I/O to the transaction logs when transactions are committed. One exception to this is during backup operations when writes to the streaming store are always logged. If you are concerned about log files consuming your disk resources, there is a better way to clean up your log files—simply perform regular online backups. Backups automatically remove transaction log files when they are no longer needed.
3.3.4 How Exchange 2000 stores incoming data
Exchange 2000 now supports the ability for content to be stored in the database based on the type of native format of the client. In previous versions of Exchange Server, all incoming content was stored in Microsoft Rich Text Format (RTF) and was viewed as MAPI properties in the database (*.EDB file). In versions of Exchange prior to Exchange 2000, when non-MAPI clients sent or retrieved data from the Exchange information store, content was converted to a useable native form (such as MIME). This resulted in an increased processing load for Exchange servers as they performed this conversion process (called IMAIL, which still exists in Exchange 2000/2003). Exchange 2000/2003 now provides a native content store for Internet Protocol clients using the MIME (Multipart Internet Mail Extension) format. This store is the streaming store, or STM file. As discussed earlier in this chapter, the streaming store has no B-Tree overhead and is simply a flat data structure consisting of 4-KB pages grouped into 16 page runs that are ideal for storing MIME content and Binary Large Objects (BLOBs). In order for all types of clients to have access to data in the Exchange databases (EDB + STM file pair), Exchange 2000/2003 supports a feature known as property promotion. Property promotion allows data held in the streaming file to have some of its key properties (such as sender, date sent, date received, subject, and so forth) promoted to the properties store, allowing folder and index views of the data stored in the streaming file. Property promotion is based on where the data came from and where it is stored. Table 3.5 documents how Exchange 2000/2003 carries out property promotion. In general, the rule is that the last writer determines how and where the data is stored.
| Content Source | Promotion Rules |
|---|---|
| MAPI client or application | Content stored in properties store (EDB). If a non-MAPI client asks for this message, Exchange will perform a conversion from MAPI to Internet format. The conversion is not persisted (moved to the streaming store). |
| Internet client (POP3, IMAP, SMTP) | Level 1 conversion: Content is stored in the streaming store (STM), and certain headers are promoted as properties to the EDB file. Level 2 conversion: If a MAPI client requests a property of the message (such as subject), Exchange will promote all of the header information into the property store. Level 3 conversion: If the MAPI client requests the attachment data, a near-duplicate message is created in the property store. If the MAPI client modifies the message, the streaming store version is discarded. |
Exchange installable file system
Exchange 2000/2003 features the much-touted Exchange Installable File System (ExIFS), which turns an Exchange server into a potential file repository for most any application. ExIFS provides direct access to the STM file at a file system level. This enables Win32 applications and Server Message Block (SMB) applications to directly access the Exchange information store by exposing item- and folder-level information store objects as a simple file or share. For maximum benefit of ExIFS, it is combined in Exchange Server 2000/2003 with other information store features such as document property promotion, full-text indexing, or Web client (HTTP) support. When used in conjunction with these features, Exchange becomes a file server with capabilities beyond even those available with Windows Server and NTFS. For example, a browser-based client could query the Exchange information store for object properties or perform full-text searches much more easily than was possible with earlier versions of Exchange Server. On every Exchange 2000 server, the M: drive (by default) is automatically mapped with a share name of Exchange. Users can access the Exchange information remotely over the network by simply mapping a drive. (However, this feature has been disabled by default in Exchange Server 2003.) ExIFS provides access to two hierarchical levels of the Exchange information store—Public Folders and Mailbox.
Public Folder items can be listed using the standard DIR command or view and can be manipulated with Windows Explorer and other standard interfaces and commands (just don’t try to use Windows Explorer to set permissions on messages, folders, post items, or attachments!). The Mailbox level is provided by the MBX folder. This is the root for all mailboxes on the Exchange 2000/ 2003 server. Mailbox folder names are not viewable by default, but with proper access, users can view these as well. This powerful feature also requires the utmost in management and security attention. To summarize, the ExIFS is a method of providing complete file system semantics for the Exchange information store objects. ExIFS is implemented as a kernel-mode device driver (ExIFS.SYS) for high performance and reflects Win32 file system calls to the Exchange Store (via ExWin32.DLL), thereby exposing Win32 file system APIs (i.e., CreateFileEx, ReadFileEx, and so forth), as well as file-system functions exported from Kernel32.DLL for both third-party developers and Microsoft software such as IIS. Via ExIFS, the contents of the Exchange databases are exposed as ordinary NTFS file objects.
The information store and exifs work together to store messaging data
Figure 3.13 shows the relationship between the Exchange Store process (a subcomponent of which is ESE), the ExIFS, and IIS. In previous versions of Exchange, incoming messaging data from services such as SMTP or NNTP was transferred using the NTFS file system as an intermediate step (in Exchange 5.5, this was done by transferring files in the IMSDATAIN directory to the MTS-IN folders). For Exchange 2000, more focus was given to Internet protocols, and therefore ExIFS was leveraged to allow IIS to view the streaming store as a collection of smaller “virtual files.” Since IIS hosts all Internet protocols (in the form of virtual servers) for Exchange 2000/2003, a protocol server such as SMTP will communicate via the Exchange/ IIS Epoxy layer (a shared memory message-passing construct), obtain file handles (provided by ExIFS) to these virtual files, and write incoming Internet content directly into the streaming store (STM file). Likewise, outgoing messages can be read directly from the STM file by IIS. A message then becomes a list of pages and properties (some of which are promoted to the property store). IIS is able simply to allocate pages from the virtual files (contained in the streaming store) via communication with the store process (which manages the database engine) and the ExIFS. Accessing the streaming store via ExIFS allows IIS to use standard Win32 file handlers to access content stored in Exchange 2000/2003 databases. ESE maintains a list of pages in the streaming store that are available for use by IIS. The ExIFS driver queries this list, known as a scatter-gather list, when it needs to write information to the streaming store. When an IFS client (such as IIS) needs to write to the streaming store, ESE will allocate chunks of sixteen 4-KB pages (64 KB). This enables data to be streamed from the STM file in kernel mode (ExIFS is a kernel-mode driver) in large I/Os of 32 to 320 KB. The combination of ESE and ExIFS allows Exchange 2000/2003 to provide a high-performance storage mechanism for both native Internet content and MAPI content that is also completely transaction based.
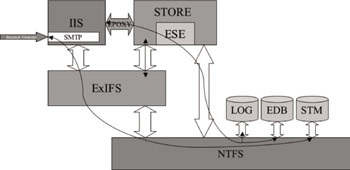
Figure 3.13: Interactions between ESE, ExIFS, and IIS when storing Exchange data.
3.3.5 Content indexing
The Exchange 2000/2003 information store supports the management and creation of indexes for common key fields such as subject or message body for fast searches and lookups. Previous versions of Exchange would search through every document in every folder in order to support a full-text search capability. This would drastically increase search times as databases grew larger. With the content indexing feature in Exchange 2000/2003, every word in the database is indexed, making fast searches a reality regardless of the database size. Both the message content and attachment text can now be searched. In addition, advanced searches are now possible for content in both the EDB and STM stores using the property promotion feature of the information store. Searches can be performed on any document property, such as author. Content indexing could be a very important feature as future document management and workflow applications for Microsoft and third-party vendors leverage the Exchange Server information store. Exchange administrators should understand how content indexing works in Exchange and the impact it will have on disaster recovery, server performance, and migration between Exchange versions and service packs.
3.3.6 Is single-instance storage sacrificed?
Since its very first versions, Exchange Server has supported the single-instance storage feature. With single-instance storage, a message sent to multiple mailboxes is only stored once per database. While this feature is significant in reducing overall storage requirements on the server, it is difficult to realize this benefit in larger deployments and receive any practical benefits. In order to achieve a high degree of single-instance storage (called a single instance storage ratio), you must attempt to allocate users by workgroup and provide a high degree of concentration in your user population. The idea is that the locality of users will achieve high single instance storage since messages, in theory, will be grouped by workgroup or other factors such as geography. In practice, we see that real-world deployments have trouble achieving the desired result since workgroups and organizations are highly dispersed. Exchange 2000/2003 still supports single-instance storage as well. However, based on our previous discussions of multiple storage groups and databases, you can see that a high degree of single instance storage will be an even more challenging goal to achieve with Exchange 2000/2003. As long as messages are sent to users who reside on the same database, single instance storage is attainable. If not, the message (or any data, for that matter) is copied once to each database where recipients reside. If the databases are in different storage groups, then the additional overhead of multiple transaction logging is also added. To illustrate this, let’s look at the example in Figure 3.14. Suppose a single storage group is deployed on a server. The storage group has four private and one public information stores (databases) configured. A single 1-MB message is sent to 40 people configured as follows: 10 people are hosted by each of the 4 private information stores configured. In this configuration, the total amount of information store space required is 4 MB—1 MB on each private information store. An additional 1 MB is also used because the message is also stored in the transaction log for that storage group. Without single-instance storage, the message would have to be replicated to each individual user’s mailbox, resulting in 40 copies of the 1-MB message—a total of 40 MB of information store space would be required.
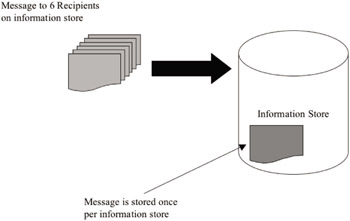
Figure 3.14: Exchange single instance storage illustrated.
3.3.7 Evolving Exchange Server storage to the next generation
It has been a long time coming and many have doubted it for years. However, it is true—Microsoft has made the strategic decision to evolve Exchange Server beyond the confines of ESE. Microsoft has recently announced at long-term direction for Exchange Server to migrate to the SQL Server platform. This will occur down the road, a few years after Microsoft completes work on the next generation of SQL Server— codenamed Yukon. Yukon represents a huge investment in a unified storage solution for Windows. As such, the Exchange team is aiming to leverage this investment and build the next generation of Exchange Server ( codenamed Kodiak) on the SQL Server Yukon platform. This will require a huge effort by Microsoft as Exchange developers must essentially reinvent the Exchange store layer on top of SQL Server versus JET/ESE. Already, Microsoft developers and program managers are hard at work designing the next generation of Exchange Server.
3.3.8 Storage and the Exchange database are key
I have taken the (perhaps indecent) liberty in this chapter of significantly digressing into the roots and technologies around Exchange Server’s database technology. I wanted not only to focus on Exchange 2000/2003 features and functionality, but also to highlight how the technology in Exchange has evolved within the industry and at Microsoft to provide the high-performance, reliable, recoverable, scalable, and manageable semistructured storage engine that we now see in Exchange 2000/2003 Server. It is also important to understand the significance of the Balanced-Tree database technology upon which the Exchange database property store is based. This is proven technology, used for years, which Microsoft (believe it or not) did not invent. Hopefully, I have also illustrated how important new developments in Exchange 2000/2003, such as storage groups and multiple databases will free us from the bondage of the monolithic store in previous versions of Exchange Server. The new features in the Exchange information store technology, such as the streaming store, multiple public folder trees, ExIFS, and the removal of the Internet protocols allowing front-end/ backend architectures for Exchange 2000/2003 to be deployed, will be important to our later discussions on building reliable systems. Along with all of these new capabilities and powerful features in Exchange 2000/2003 come greater management complexities. Exchange administrators to master these new features in order to deploy them properly. Key foundational knowledge must be imparted in order to conduct further discussions about high availability and disaster recovery for Exchange. A thorough understanding of the new technologies provided since Exchange 2000 as well as the issues that have limited us in previous version will help us build Exchange deployments that truly meet mission-critical standards.
EAN: 2147483647
Pages: 91