Section 6.8. Unicode
6.8. UnicodeUnicode string support, introduced to Python in version 1.6, is used to convert between multiple double-byte character formats and encodings, and includes as much functionality as possible to manage these strings. With the addition of string methods (see Section 6.6), Python strings and regular expressions are fully featured to handle a wide variety of applications requiring Unicode string storage, access, and manipulation. We will do our best here to give an overview of Unicode support in Python. But first, let us take a look at some basic terminology and then ask ourselves, just what is Unicode? 6.8.1. Terminology
6.8.2. What Is Unicode?Unicode is the miracle and the mystery that makes it possible for computers to support virtually any language on the planet. Before Unicode, there was ASCII, and ASCII was simple. Every English character was stored in the computer as a seven bit number between 32 and 126. When a user entered the letter A into a text file, the computer would write the letter A to disk as the number 65. Then when the computer opened that file it would translate that number 65 back into an A when it displayed the file contents on the screen. ASCII files were compact and easy to read. A program could just read in each byte from a file and convert the numeric value of the byte into the corresponding letter. But ASCII only had enough numbers to represent 95 printable characters. Later software manufacturers extended ASCII to 8 bits, which provided an additional 128 characters, but 223 characters still fell far short of the thousands required to support all non-European languages. Unicode overcomes the limitations of ASCII by using one or more bytes to represent each character. Using this system, Unicode can currently represent over 90,000 characters. 6.8.3. How Do You Use Unicode?In the early days, Python could only handle 8-bit ASCII. Strings were simple data types. To manipulate a string, a user had to create a string and then pass it to one of the functions in the string module. Then in 2000, we saw the releases of Python 1.6 (and 2.0), the first time Unicode was supported in Python. In order to make Unicode strings and ASCII strings look as similar as possible, Python strings were changed from being simple data types to real objects. ASCII strings became StringTypes and Unicode strings became UnicodeTypes. Both behave very similarly. Both have string methods that correspond to functions in the string module. The string module was not updated and remained ASCII only. It is now deprecated and should never be used in any Unicode-compliant code. It remains in Python just to keep legacy code from breaking. Handling Unicode strings in Python is not that different from handling ordinary ASCII strings. Python calls hard-coded strings string literals. By default all string literals are treated as ASCII. This can be changed by adding the prefix u to a string literal. This tells Python that the text inside of the string should be treated as Unicode. >>> "Hello World" # ASCII string >>> u"Hello World" # Unicode string The built-in functions str() and chr() were not updated to handle Unicode. They only work with regular ASCII strings. If a Unicode string is passed to str() it will silently convert the Unicode string to ASCII. If the Unicode string contains any characters that are not supported by ASCII, str() will raise an exception. Likewise, chr() can only work with numbers 0 to 255. If you pass it a numeric value (of a Unicode character, for example) outside of that range, it will raise an exception. New BIFs unicode() and unichr() were added that act just like str() and chr() but work with Unicode strings. The function unicode() can convert any Python data type to a Unicode string and any object to a Unicode representation if that object has an __unicode__() method. For a review of these functions, see Sections 6.1.3 and 6.5.3. 6.8.4. What Are Codecs?The acronym codec stands for COder/DECoder. It is a specification for encoding text as byte values and decoding those byte values into text. Unlike ASCII, which used only one byte to encode a character into a number, Unicode uses multiple bytes. Plus Unicode supports several different ways of encoding characters into bytes. Four of the best-known encodings that these codecs can convert are: ASCII, ISO 8859-1/Latin-1, UTF-8, and UTF-16. The most popular is UTF-8, which uses one byte to encode all the characters in ASCII. This makes it easier for a programmer who has to deal with both ASCII and Unicode text since the numeric values of the ASCII characters are identical in Unicode. For other characters, UTF-8 may use one or four bytes to represent a letter, three (mainly) for CJK/East Asian characters, and four for some rare, special use, or historic characters. This makes it more difficult for programmers who have to read and write the raw Unicode data since they cannot just read in a fixed number of bytes for each character. Luckily for us, Python hides all of the details of reading and writing the raw Unicode data for us, so we don't have to worry about the complexities of reading multibyte characters in text streams. All the other codecs are much less popular than UTF-8. In fact, I would say most Python programmers will never have to deal with them, save perhaps UTF-16. UTF-16 is probably the next most popular codec. It is simpler to read and write its raw data since it encodes every character as a single 16-bit word represented by two bytes. Because of this, the ordering of the two bytes matters. The regular UTF-16 code requires a Byte Order Mark (BOM), or you have to specifically use UTF-16-LE or UTF-16-BE to denote explicit little endian and big endian ordering. UTF-16 is technically also variable-length like UTF-8 is, but this is uncommon usage. (People generally do not know this or simply do not even care about the rarely used code points in other planes outside the Basic Multilingual Plane (BMP). However, its format is not a superset of ASCII and makes it backward-incompatible with ASCII. Therefore, few programs implement it since most need to support legacy ASCII text. 6.8.5. Encoding and DecodingUnicode support for multiple codecs means additional hassle for the developer. Each time you write a string to a file, you have to specify the codec (also called an "encoding") that should be used to translate its Unicode characters to bytes. Python minimizes this hassle for us by providing a Unicode string method called encode() that reads the characters in the string and outputs the right bytes for the codec we specify. So every time we write a Unicode string to disk we have to "encode" its characters as a series of bytes using a particular codec. Then the next time we read the bytes from that file, we have to "decode" the bytes into a series of Unicode characters that are stored in a Unicode string object. Simple ExampleThe script below creates a Unicode string, encodes it as some bytes using the UTF-8 codec, and saves it to a file. Then it reads the bytes back in from disk and decodes them into a Unicode string. Finally, it prints the Unicode string so we can see that the program worked correctly. Line-by-Line ExplanationLines 17The usual setup plus a doc string and some constants for the codec we are using and the name of the file we are going to store the string in. Lines 919Here we create a Unicode string literal, encode it with our codec, and write it out to disk (lines 9-13). Next, we read the data back in from the file, decode it, and display it to the screen, suppressing the print statement's NEWLINE because we are using the one saved with the string (lines 15-19). Example 6.2. Simple Unicode String Example (uniFile.py)
When we run the program we get the following output: $ unicode_example.py Hello World We also find a file called unicode.txt on the file system that contains the same string the program printed out. $ cat unicode.txt Hello World! Simple Web ExampleWe show a similar and simple example of using Unicode with CGI in the Web Programming chapter (Chapter 20). 6.8.6. Using Unicode in Real LifeExamples like this make it look deceptively easy to handle Unicode in your code, and it is pretty easy, as long as you follow these simple rules:
These rules will prevent 90 percent of the bugs that can occur when handling Unicode text. The problem is that the other 10 percent of the bugs are beyond your control. The greatest strength of Python is the huge library of modules that exist for it. They allow Python programmers to write a program in ten lines of code that might require a hundred lines of code in another language. But the quality of Unicode support within these modules varies widely from module to module. Most of the modules in the standard Python library are Unicode compliant. The biggest exception is the pickle module. Pickling only works with ASCII strings. If you pass it a Unicode string to unpickle, it will raise an exception. You have to convert your string to ASCII first. It is best to avoid using text-based pickles. Fortunately, the binary format is now the default and it is better to stick with it. This is especially true if you are storing your pickles in a database. It is much better to save them as a BLOB than to save them as a TEXT or VARCHAR field and then have your pickles get corrupted when someone changes your column type to Unicode. If your program uses a bunch of third-party modules, then you will probably run into a number of frustrations as you try to get all of the programs to speak Unicode to each other. Unicode tends to be an all-or-nothing proposition. Each module in your system (and all systems your program interfaces with) has to use Unicode and the same Unicode codec. If any one of these systems does not speak Unicode, you may not be able to read and save strings properly. As an example, suppose you are building a database-enabled Web application that reads and writes Unicode. In order to support Unicode you need the following pieces to all support Unicode:
The database server is often the easiest part. You just have to make sure that all of your tables use the UTF-8 encoding. The database adapter can be trickier. Some database adapters support Unicode, some do not. MySQLdb, for instance, does not default to Unicode mode. You have to use a special keyword argument use_unicode in the connect() method to get Unicode strings in the result sets of your queries. Enabling Unicode is very simple to do in mod_python. Just set the text-encoding field to "utf-8" on the request object and mod_python handles the rest. Zope and other more complex systems may require more work. 6.8.7. Real-Life Lessons LearnedMistake #1: You have a large application to write under significant time pressure. Foreign language support was a requirement, but no specifics are made available by the product manager. You put off Unicode-compliance until the project is mostly complete ... it is not going to be that much effort to add Unicode support anyway, right? Result #1: Failure to anticipate the foreign-language needs of end-users as well as integration of Unicode support with the other foreign language-oriented applications that they used. The retrofit of the entire system would be extremely tedious and time-consuming. Mistake #2: Using the string module everywhere including calling str() and chr() in many places throughout the code. Result #2: Convert to string methods followed by global search-and-replace of str() and chr() with unicode() and unichr(). The latter breaks all pickling. The pickling format has to be changed to binary. This in turn breaks the database schema, which needs to be completely redone. Mistake #3: Not confirming that all auxiliary systems support Unicode fully. Result #3: Having to patch those other systems, some of which may not be under your source control. Fixing Unicode bugs everywhere leads to code instability and the distinct possibility of introducing new bugs. Summary: Enabling full Unicode and foreign-language compliance of your application is a project on its own. It needs to be well thought out and planned carefully. All software and systems involved must be "checked off," including the list of Python standard library and/or third-party external modules that are to be used. You may even have to bring onboard an entire team with internationalization (or "I18N") experience. 6.8.8. Unicode Support in Pythonunicode() Built-in FunctionThe Unicode factory function should operate in a manner similar to that of the Unicode string operator ( u / U ). It takes a string and returns a Unicode string. decode()/encode() Built-in MethodsThe decode() and encode() built-in methods take a string and return an equivalent decoded/encoded string. decode() and encode() work for both regular and Unicode strings. decode() was added to Python in 2.2. Unicode TypeA Unicode string object is subclassed from basestring and an instance is created by using the unicode() factory function, or by placing a u or U in front of the quotes of a string. Raw strings are also supported. Prepend a ur or UR to your string literal. Unicode OrdinalsThe standard ord() built-in function should work the same way. It was enhanced recently to support Unicode objects. The unichr() built-in function returns a Unicode object for a character (provided it is a 32-bit value); otherwise, a ValueError exception is raised. CoercionMixed-mode string operations require standard strings to be converted to Unicode objects. ExceptionsUnicodeError is defined in the exceptions module as a subclass of ValueError. All exceptions related to Unicode encoding/decoding should be subclasses of UnicodeError. See also the string encode() method. Standard EncodingsTable 6.9 presents an extremely short list of the more common encodings used in Python. For a more complete listing, please see the Python Documentation. Here is an online link:
RE Engine Unicode-AwareThe regular expression engine should be Unicode aware. See the re Code Module sidebar in Section 6.9.
String Format OperatorFor Python format strings: %s performs str(u) for Unicode objects embedded in Python strings, so the output will be u.encode(<default encoding>). If the format string is a Unicode object, all parameters are coerced to Unicode first and then put together and formatted according to the format string. Numbers are first converted to strings and then to Unicode. Python strings are interpreted as Unicode strings using the <default encoding>. Unicode objects are taken as is. All other string formatters should work accordingly. Here is an example: u"%s %s" % (u"abc", "abc") |
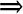 uabc abc"
uabc abc"EAN: 2147483647
Pages: 334