| The DOM object representation is in the form of a tree structure, in which each node of the tree represents a component of the XML document. For example, consider the XML document (CarParts.xml) that describes car parts shown in Listing 5.1. Listing 5.1 The CarParts.xml File<?xml version='1.0' encoding='us-ascii'?> <!-- XML file that describes car parts --> <!DOCTYPE carparts SYSTEM "CarParts.dtd" ]> <CarParts> <engine> Engine 1 </engine> <carbody> CarBody 1 </carbody> <wheel> Wheels 1 </wheel> </carstereo> </CarParts> A graphical representation of the DOM for CarParts.xml is displayed in Figure 5.1. 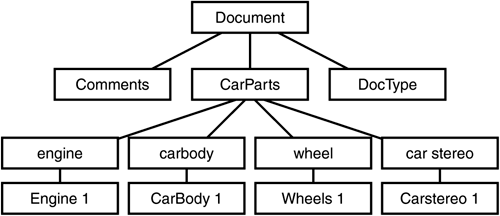
In the DOM, each entry in the XML file is a node. For each unique constituent element of an XML file, there is a node type. So, a DOM representation of an XML file will contain zero or one doctype nodes, one document element node, and zero or more processing instruction nodes, comment nodes, element nodes, and so on. The document element node is the root of the element tree of the XML document. All other elements of the XML document come under this node. Note that in a DOM structure, data for elements exist as text nodes. For example, in the preceding XML file, the data (Carstereo1) for the carstereo element will be stored in a text node under the carstereo element node. Similarly, the attributes of an element are also nodes, called the attribute nodes. However, the attribute nodes are not part of the document tree. This is because for efficiency reasons the attributes are treated as properties of elements, rather than individual nodes. Table 5.1 shows the node types as defined in the DOM specification along with the node name, value, attribute, and type information. Table 5.1. Node Types | Attr | Name of the attribute | Value of the attribute | null | 2 | | CDATASection | #cdata-section | Contents of the CDATA section | null | 4 | | Comment | #comment | Content of the comment | null | 8 | | Document | #document | null | null | 9 | | DocumentFragment | | null | #documentfragment null | 11 | | DocumentType | Document type name | null | null | 10 | | Element | Tag name | null | NamedNodeMap | 1 | | Entity | Entity name | null | null | 6 | | EntityReference | Name of entity reference | null | null | 5 | | Notation | Notation name | null | null | 12 | | ProcessingInstruction | Target | Entire content excluding the target | null | 7 | | Text | #text | Content of the text node | null | | This is very different from the approach the SAX parser takes. As you recall from the discussions in the earlier chapter, the SAX parser is event-based. The SAX parser throws callback methods whenever an XML component, such as the start of an element, is found in the document. This approach makes it very useful for applications that do serial processing of XML, such as Web applications that use XML data for creating HTML documents. Because there is no in-memory representation of the data, a SAX parser is very light on the resources. However, because it's event-based, an application based on SAX cannot modify the XML data or randomly access parts of an XML document. For example, an application based on the SAX parser cannot add its own element tags or modify the content of an element. Also, it is difficult to use SAX if you have to write application code that depends on the relationship between entities in an XML document. The creation of the in-memory representation of the XML document makes it possible for applications to randomly access any part of the document and modify it. However, because it loads the entire XML document in the memory, DOM is very resource-heavy and might have performance issues with large documents. So, when you have to build applications that modify XML data, or traverse the document multiple times in any order, DOM is the API of choice. |
