2.2 Hardware configurations
|
| < Day Day Up > |
|
2.2 Hardware configurations
In this section, we discuss the different types of hardware cluster, concentrating on disk clustering rather than network or IP load balancing scenarios. We also examine the differences between a hardware cluster and a hot standby system.
2.2.1 Types of hardware cluster
There are many types of hardware clustering configurations, but here we concentrate on four different configurations: two-node cluster, multi-node cluster, grid computing, and disk mirroring (these terms may vary, depending on the hardware manufacturer).
Two-node cluster
A two-node cluster is probably the most common form of hardware cluster configuration; it consists of two nodes which are able to access a disk system that is externally attached to the two nodes, as shown in Figure 2-4 on page 44. The external drive system can be attached over the LAN or SAN network (SSA Disk system), or even by local SCSI cables.
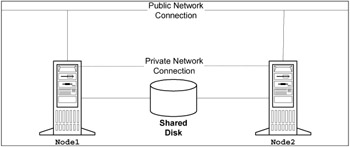
Figure 2-4: Two-node cluster
This type of cluster is used when configuring only a couple of applications in a high availability cluster. This type of configuration can accommodate either Active/Passive or Active/Active, depending on the operating system and cluster software that is used.
Multi-node cluster
In a multi-node cluster, we have between two and a number of nodes that can access the same disk system, which is externally attached to this group of nodes, as shown in Figure 2-5 on page 45. The external disk system can be over the LAN or SAN.
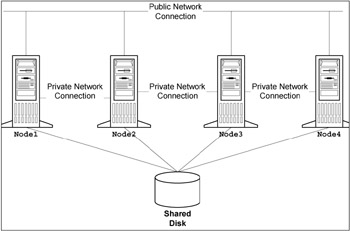
Figure 2-5: Multi-node cluster
This type of configuration can be used for extra fault tolerance where, if Node1 were to fail, then all work would move onto Node2-but if Node2 were to fail as well, then all work would then move on to the next node, and so on.
It also can support many applications running simultaneously across all nodes configured in this cluster. The number of nodes that this configuration can support depends on the hardware and software manufacturers.
Grid computing
Even though grid computing is not necessarily considered a cluster, it acts like one, so we will explain the concepts involved. Grid computing is based on the concept that the IT infrastructure can be managed as a collection of distributed computing resources available over a network that appear to an end user or application as one large virtual computing system.
A grid can span locations, organizations, machine architectures, and software boundaries to provide unlimited power, collaboration, and information access to everyone connected to the grid. Grid computing enables you to deliver computing power to applications and users that need it on demand, which is only when they need it for meeting business objectives.
Disk mirroring
Disk mirroring is more commonly used in a hot standby mode, but it is also used in some clustering scenarios, especially when mirroring two systems across large distances; this will depend on the software and or hardware capabilities.
Disk mirroring functionality can be performed by software in some applications and in some clustering software packages, but it can also be performed at the hardware level where you have a local disk on each side of a cluster and any changes made to one side is automatically sent across to the other side, thus keeping the two sides in synchronization.
2.2.2 Hot standby system
This terminology is used for a system that is connected to the network and fully configured, with all the applications loaded but not enabled. It is normally an identical system for which it is on standby for, and this is both hardware and software.
One hot standby system can be on standby for several live systems which can include application servers which have a Fault Tolerant Agent, IBM Tivoli Workload Scheduler Master Domain Manager or a Domain Manager.
The advantage over a hardware cluster is that one server can be configured for several systems, which cut the cost dramatically.
The disadvantages over a hardware cluster are as follows:
-
It is not an automatic switchover and can take several minuets or even hours to bring up the standby server.
-
The work that was running on the live server has no visibility on the standby server, so an operator would have to know where to restart the standby server.
-
The standby server has a different name, so the IBM Tivoli Workload Scheduler jobs would not run on this system as defined in the database. Therefore, the IBM Tivoli Workload Scheduler administrator would have to submit the rest of the jobs by hand or create a script to do this work.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 92