What About the Role of IP Sprayers Such as IBM's Network Dispatcher? Network Dispatcher is a TCP connection router that supports failover and load sharing across several TCP servers. Network Dispatcher was "rebranded" under the WebSphere umbrella and is now part of the WebSphere Edge Server. Load sharing in Network Dispatcher is supported by a user -level manager process that monitors the load on the servers and controls the connection allocation algorithm in the kernel extension. At many Internet sites, the workload required of various services has grown to the point where a single system is often unable to cope. Offering the same service under a number of different node names is a solution that has been used by a number of sites ”for example, by Netscape for its file transfers. Round- robin DNS can also be used for much the same purpose and allows the servers to publish a single name by which the service is known. Neither of these approaches spreads the load evenly as the number of servers providing the service increases . In the Netscape approach, clients manually pick from a list of names providing the service. In all probability, the names at the top of the list, or with some other feature, will be chosen. Whatever attribute is chosen , it is unlikely to be related to the current load on the servers. The list can be manipulated to put lightly loaded nodes in a place where they are most likely to be picked, but this cannot necessarily be done on a timely basis. Round-robin DNS eliminates psychology as an issue but replaces it with IP address caching. Once a particular client or proxy has received an IP address for a service, that IP address may be cached for hours, or even days. Intermediate name servers and gateways also frequently cache IP addresses and usually ignore any time-to-live limits suggested by DNS. With either method, control over the number of requests per server is limited, which causes the load to be unevenly spread. Network Dispatcher is one solution to the problems of keeping the load evenly spread or balanced on a group of servers. Network Dispatcher is integrated with the TCP/IP stack of a single system. It acts as a dispatcher of connections from clients who know a single IP address for a service, to a set of servers that actually perform the work. Unlike other approaches, only the packets going from the clients to the server pass through Network Dispatcher; packets from the server to client may go by other routes, which need not include Network Dispatcher. This reduces the load on Network Dispatcher, allowing it to potentially stand in front of a larger number of servers. Network Dispatcher has been used to spread the load as part of several large-scale Web server complexes ”for example, the 1996 and 2000 Summer Olympic Games, Deep Blue vs. Kasperov, and the 1998 Winter Olympic Games Web sites. These systems handled millions of requests per day, going to dozens of servers at a time. Network Dispatcher has also been successfully used with many different types of Web servers. The Weighted Round Robin (WRR) connection allocation algorithm is efficient and maintains the following conditions: All servers with the same weight will receive a new connection before any server with a lesser weight receives a new connection. Servers with higher weights get more connections than servers with lower weights, and servers with equal weights get an equal distribution of new connections. Finally, an eligible server will be returned on each invocation of the allocation function or an indication that there are no eligible servers. The service time and resources consumed by each type of TCP connection request varies depending on several factors. These factors include request-specific parameters (type of service, content) and currently available resources (CPU, bandwidth). For example, some requests may perform computationally intensive searches, while others perform trivial computation. A na ve distribution of TCP connections among the back-end servers can (and often does) produce a skewed allocation of the cluster resources. For example, a simple round-robin allocation may result in many requests being queued up on servers that are currently serving "heavy'' requests. Obviously, such an allocation policy can cause underutilization of the cluster resources, as some servers may stay relatively idle while others are overloaded. This condition, in turn , will also produce longer observed delays for the remote clients. Load-balancing and load-sharing are two main strategies for improving performance and resource utilization. Load-balancing strives to equalize the servers' workload, while load-sharing attempts to smooth out transient peak overload periods on some nodes. Load-balancing strategies typically consume many more resources than load-sharing, and the cost of these resources often outweigh their potential benefits. IBM found this to be the case in allocating TCP connections for HTTP requests; therefore, the first Network Dispatchers implemented a load-sharing allocation policy. Network Dispatcher can be configured with multiple network interfaces and can be optionally co-located with a server. Packets from Network Dispatcher to the servers can follow a separate network path than the response packets from the servers to the clients. This enables better use of network bandwidth. For example, the 2000 Olympic Web site had a Network Dispatcher node on the public network, a separate token-ring network between Network Dispatcher and the servers, and the servers attached to the public network via ATM. This takes advantage of the fact that Web responses are generally much larger than the corresponding requests. Network Dispatcher has explored two approaches for providing high availability: integrating Network Dispatcher with an existing recovery infrastructure and providing HA for smaller stand alone sites. The high-availability infrastructure consists of a set of daemons running on all nodes, exchanging heartbeat messages, and automatically initiating a recovery program via a recovery driver when a specific failure event (software or hardware) occurs. The recovery infrastructure described here is available as a product called High Availability Cluster Multi-Processing for AIX (HACMP) on the IBM SP-2, where multiple heartbeats on distinct networks are used to tolerate network adapter failures. The Web recovery programs have been prototyped and demonstrated on the SP-2 using HACMP with multiple Network Dispatcher nodes co-located with servers. Figure 14-5 illustrates a scalable Web server with a set of Network Dispatchers routing requests from multiple clients to a set of server nodes. While a single Network Dispatcher node can handle the routing requirements of a large site, multiple Network Dispatchers may be configured for high availability and nondisruptive service. Recovery programs consist of multiple steps, and each step, which can be a single command or a complex recovery script, can execute on a different node of the system. Recovery steps can be forced to execute in sequence via barrier commands that are used for synchronization. Figure 14-5. HACMP WAS cluster for an e-commerce application. 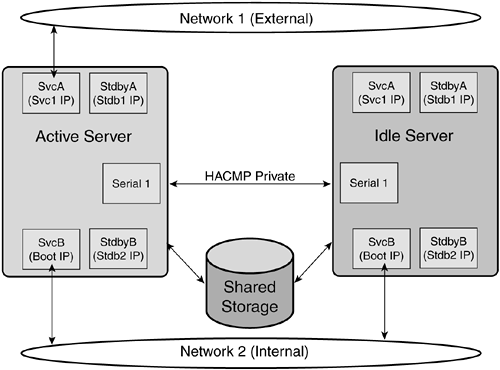
Figure 14-4. High availability in a scalable Web server using Network Dispatchers. 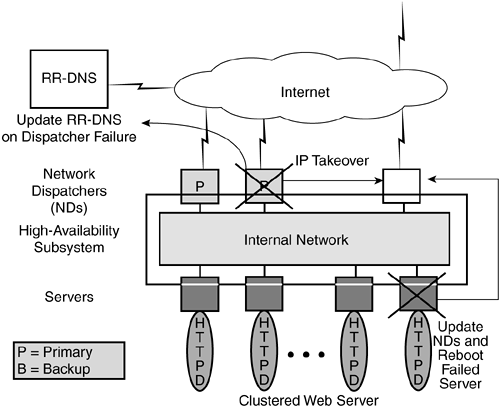
If there is no recovery infrastructure, then Network Dispatcher would be a single point of failure. To address this issue, Network Dispatcher has been augmented with primary backup function. Two Network Dispatchers, ND1 and ND2, with the same LAN connectivity can be configured to serve the same set of servers: One is designated as primary (ND1), and the second as backup (ND2). When the backup Network Dispatcher initializes, it requests replication of the primary Network Dispatcher's state. After the primary has replicated its state to the backup, it runs a cache consistency protocol with the backup. All changes made to the state of the primary are replicated to the backup. If the primary fails, the backup takes over the address of the primary using a gratuitous ARP. Many Internet sites rely on DNS-based techniques to share load across several servers (e.g., NCSA). These techniques typically include modifications to the DNS BIND code. There are several drawbacks to all DNS-based solutions. All DNS variations may disclose up to 32 IP addresses for each DNS name, due to UDP packet size constraints. Knowledge of these IP addresses may create problems for clients (e.g., unnecessary reload of HTML pages in cache) and also for network gateways (e.g., for filtering rules in IP routers). Any caching of IP addresses resolved via DNS creates skews in the distribution of requests. DNS-based solutions are very slow (or unable) to detect server failures and additions of new servers. Furthermore, while the server host may be running properly, the specific server software (e.g., httpd) may have failed. In a pathological case, a load-balancing DNS tool may see that a server is under-loaded (because the httpd daemon failed), and give it even higher priority. Several packet-forwarding hardware products have been introduced (e.g., Cisco's LocalDirector). These devices translate (rewrite) the TCP/IP headers and recompute the checksums of all packets flowing between clients and servers in both directions. This is similar to Network Address Translation (NAT), adding the choice of the selected server. Notice that this device quickly becomes the main network bottleneck. |