A Brief Theory of XML
|
An XML document is a plain text file. As such, you can use any text editor of your choice to write, view, and edit it. When you see an XML document for the first time, you will immediately notice that some words are enclosed in brackets: < … >. The words in brackets are called tags. If you know Hypertext Markup Language (HTML), then XML will remind you of it. However, unlike HTML, no predefined tags make up an XML document. Every tag is tailor-made—in other words, you create your own!
| Note | This section does not offer you a complete reference of XML. XML is a broad topic that requires a thick book to describe it thoroughly. However, what is presented in this chapter should give you sufficient background knowledge to work through the project. |
The main use of XML is to store a data structure. Consider, for example, a table containing product information as given in Table 2-1.
| PRODUCTID | NAME | DESCRIPTION | PRICE | SUPPLIERID |
|---|---|---|---|---|
| 1 | ChocChic | Mint chocolate, 100gr | 1.50 | 1 |
| 2 | Chocnuts | Chocolate with peanuts, 200gr | 2.95 | 2 |
As you can see, Table 2-1 contains two records. If this data is to be written in XML, you will get the XML document shown in Listing 2-1.
Listing 2-1: An XML Document
<?xml version="1.0" standalone="yes" encoding="UTF-8"?> <products> <product> <product_id>1</product_id> <name>ChocChic</name> <description>Mint chocolate, 100g</description> <price>1.50</price> <supplier_id>1</supplier_id> </product> <product> <product_id>2</product_id> <name>Chocnuts</name> <description>Chocolate with peanuts, 200gr</description> <price>2.95</price> <supplier_id>2</supplier_id> </product> </products>
You might ask the following question: If relational databases work so well, why do you need XML at all? There are a number of answers:
-
XML uses a standard and open format from the W3C (http://www.w3c.org), making data exchange easy. Compare this with proprietary data formats of relational databases that make exchanging data a complex process.
-
XML can represent hierarchical data.
-
You must comply with rules when writing XML. These rules make it possible to check the data integrity of an XML document.
-
The same rules make it possible to validate XML documents.
-
XML is extensible. You create your custom tags to accommodate any type of data you have.
| Note | You can find the XML recommendation version 1.0 (the latest version) at http://www.w3.org/TR/REC-xml. |
Because there are rules in writing XML and because it is based on an open standard, there is no ambiguity in interpreting an XML document, even when trying to understand an XML document you have never seen before. For instance, you can describe the XML document shown in Listing 2-1 as follows:
-
The first line specifies it is an XML document compliant to version 1.0 of XML, it is a stand-alone document (meaning it does not refer to any external entity), and it uses UTF-8 encoding.
-
The second line begins the data, which is represented as a collection of elements. The first element in the XML document is <products>, which is self-explanatory. Clearly this XML document is a collection of products. The first element, which is always the topmost element in hierarchical data, is called the root. So, <products> is the root in Listing 2-1.
-
An element can consist of other elements, which are called the child elements of that element. As mentioned, XML is suitable for hierarchical data. Therefore, elements with child elements that in turn have their own child elements are common in XML. For example, the <product> element is the child element of the <products> element. The <product> element has the child elements <product_id>, <name>, <description>, <price>, and <supplier_id>.
-
An element in an XML document can contain attributes, which are similar to attributes of an HTML tag. For example, the following is a <product> element to which an in_stock attribute has been added:
<product in_stock="yes">
| Note | Element names and values, as well as attribute names and values, are case sensitive. |
In determining whether data integrity has been maintained in an XML document, an XML writer should know two rules: well-formedness and validity. A valid XML document is always well-formed, but a well-formed document is not always valid.
A well-formed XML document follows the syntax rules governed by the World Wide Web Consortium (W3C) in the XML 1.0 Specification. Well-formedness means the following:
-
An XML document must contain at least one element, the root element.
-
There can be only one root element. All other elements are nested inside the root element.
-
Each element must nest inside an enclosing element. For example, Listing 2-2 is not well-formed because the closing </name> element appears after the <description> opening tag.
Listing 2-2: An XML Document, Not Well-Formed
<product> <name> ChocChic <description> chocolate with mint 100g </name> </description> </product>
A valid XML document is one that follows a set of grammatical rules. You can check the validity of an XML document against two sets of rules: Document Type Definitions (DTDs) and schemas. A valid XML document must have a DTD or a schema associated with it, against which the correctness and well-formedness of the XML document can be verified.
We now discuss how to write a well-formed XML document. Afterward, we look at the two rules that can guarantee the validity of the XML document.
Writing Well-Formed XML Documents
What does it take to write a well-formed XML document? The short answer is that the document must meet all the well-formedness constraints specified in the W3C's XML 1.0 recommendation. This translates into the following rule: An XML document has three parts—a prolog, an element, and a miscellaneous part. The following sections describe these parts.
Prolog
The prolog starts an XML document. It contains an XML declaration, miscellaneous part, and DTD. All the parts in the prolog are optional. Therefore, an XML document can still be well-formed even if the prolog is empty. However, an XML document with an empty prolog is not valid.
The XML declaration part of the prolog contains the version information, optional encoding declaration, and optional stand-alone document declaration. These prolog examples contain only the XML declaration part:
<?xml version="1.0"?> <?xml version="1.0" encoding="UTF-8"?> <?xml version="1.0" standalone="yes"?> <?xml version="1.0" encoding="UTF-8" standalone="yes"?>
The only valid version number for an XML document is currently 1.0. The encoding declaration is the language encoding for the document. The default value for the encoding declaration is UTF-8. A value of "yes" for the stand-alone declaration means the XML document does not refer to any external document; "no" means the opposite.
The miscellaneous part of the prolog contains a comment or a processing instruction.
| Note | An XML comment starts with <! - and ends with - >. |
A processing instruction is an instruction to the XML processor and it is processor dependant. As such, you do not specify it in the XML 1.0 recommendation. A common processing instruction includes the <?xml-stylesheet?> instruction, which connects a style sheet with the XML document.
The "Writing Valid XML Documents" section discusses the DTD part of a prolog.
Element
An XML element begins with a start tag and ends with an end tag. A start tag begins with < and ends with >. An end tag starts with </ and ends with >. Empty elements are an exception, however. In addition to the normal syntax, an empty element can consist of only one tag.
For example, the following is an XML element:
<productId>1</productId>
And the following is an empty element:
<productId/>
A tag name, such as productId in the previous examples, starts with a letter, an underscore, or a colon. Following the first character are letters, digits, underscores, hyphens, periods, and colons. A tag name can contain no whitespace.
An element can have attributes, which are name-value pairs containing additional data for the element. You separate the name and the value in an attribute with an equal sign. Attribute names follow the same rule as tag names. You must enclose attribute values in quotation marks, either double quotes or single quotes. Using double quotes is more common, but you can use single quotes if the value itself contains double quotes. In a case where the attribute value contains both single quotes and double quotes, you can use ' to represent a single quote and " to represent a double quote.
| Note | In addition to ' and ", you can use & for the ampersand (&) character, < for the left-bracket (<) character, and > for the right-bracket (>) character. |
For example, the following element whose tag name is product has an attribute called in_stock. The attribute has the value of 6:
<product in_stock="6"> <name>ChicChoc</name> </product>
Confusion often arises whether to write data related to an element as an attribute or a child element. In the case of the previous example, you can rewrite the elements as follows:
<product> <in_stock>6</in_stock> <name>ChicChoc</name> </product>
Whether to use an attribute or a child element is entirely up to you. However, the general rule of thumb says that you should not have more than 10 attributes in one element.
Miscellaneous
This part can contain comments or processing instructions.
Writing Valid XML Documents
As mentioned, well-formedness alone is not enough to guarantee the data integrity of an XML document. For data integrity, you also have to make sure that an XML document is valid. For example, an XML document that contains the data structure for some products may define that the root element is <products> and there are five child elements under it: <name>, <description>, <product_id>, <price>, and <supplier_id>. If a document has a <products> element as its root, but the <supplier_id> element is missing, the document is not valid, even though it may be well-formed.
For validity, you can check the XML document against two rules: DTDs and schemas. Specifications for DTDs were published earlier than those of schemas, but schemas are more powerful than DTDs. However, both are still widely in use today. We look at both in turn.
Document Type Definition
You can define DTDs in the XML document itself or in an external file—or in both. The following sections first cover DTD basics in an internal DTD and then cover documents that have external DTDs. The last subsection talks about entities and attributes.
| Note | You can find the formal rules for DTDs in the XML 1.0 at http://www.w3.org/TR/REC-xml. |
DTD Basics
To start with, you use <!DOCTYPE> to write a DTD, which always appears in the XML document prolog. There are a few syntaxes for <!DOCTYPE>; this chapter uses the following:
<!DOCTYPE rootName [DTD]>
where rootName is the name of the root in the document and [DTD] is the part that defines all elements—in other words, the root itself and all other elements nesting inside the root. Each element is defined by <!ELEMENT>. Because an XML document must have a root, the DTD must have at least one element that defines the root itself. For example, the following is an XML document with an internal DTD. The DTD dictates that the document must have a root called products, and <products> can have no elements nested inside it:
<?xml version="1.0" standalone="yes"?> <!DOCTYPE products [ <!ELEMENT products (#PCDATA)> ]> <products/>
Note that the XML declaration in the prolog contains the standalone attribute with the value of "yes". This means that this XML document does not refer to any external document. Note also that the DTD defines the <!ELEMENT> for products. #PCDATA stands for parsed character data and indicates text that does not contain markup.
You can also declare that an element must be empty using the EMPTY keyword. An empty element cannot have a value or a child element, but it can have attributes. For example, the following is the previous XML document with a DTD that states that the root element (product) must be empty:
<?xml version="1.0" standalone="yes"?> <!DOCTYPE products [ <!ELEMENT products EMPTY> ]> <products></products>
An XML document with only the root and no other elements is not of much use. The <!ELEMENT> in a DTD allows you to define another element. For instance, the following is a DTD that states that the XML document must have <products> as its root and <products> must have a <product> element. The DTD next states that the <product> element must have the <name> and <product_id> elements:
<!DOCTYPE products [ <!ELEMENT products (product)> <!ELEMENT product (name,product_id)> <!ELEMENT name (#PCDATA)> <!ELEMENT product_id (#PCDATA)> ]>
Listing 2-3 shows a valid XML document that uses the previous DTD.
Listing 2-3: A Valid XML Document with an Internal DTD
<?xml version="1.0" standalone="yes"?> <!DOCTYPE products [ <!ELEMENT products (product)> <!ELEMENT product (name,product_id)> <!ELEMENT name (#PCDATA)> <!ELEMENT product_id (#PCDATA)> ]> <products> <product> <name>ChicChoc</name> <product_id>10</product_id> </product> </products>
In declaring child elements, you can use the following operators that have special meanings. Here x denotes a child element:
-
x*: Zero or more instances of x
-
x+: One or more instances of x
-
x?: Zero or one instance of x
-
x, y: x followed by y
-
x | y: x or y
For example, if you want to say in the previous DTD that <products> can have zero or more <product> elements and <product> can have an optional <name> but must have a <product_id>, use this modified DTD:
<!DOCTYPE products [ <!ELEMENT products (product)*> <!ELEMENT product (name?,product_id)> <!ELEMENT name (#PCDATA)> <!ELEMENT product_id (#PCDATA)> ]>
External DTDs
Using an external DTD is useful because you can share the DTD with many XML documents. Also, for a long DTD, it makes the XML document that uses it tidier.
There are two kinds of external DTDs: private and public. Private DTDs are to be used privately by certain people or applications in a group. You specify an external private DTD using the SYSTEM keyword in the <!DOCTYPE>. On the other hand, a public external DTD can be used by anyone, thus making it public. To make an external DTD public, use the PUBLIC keyword in the <!DOCTYPE>.
Practically the only differences between using an external DTD from an internal DTD are that with external DTDs you have a separate file for the DTD and this DTD file is referenced from inside the XML document. Listing 2-4 shows an XML document that uses a private DTD called products.dtd. Because the products.dtd file is referenced without any information about its path, it must reside in the same directory as the XML document.
Listing 2-4: A Valid XML Document with a Private External DTD
. <?xml version="1.0" standalone="no"?> <!DOCTYPE products SYSTEM "products.dtd"> <products> <product> <name>ChocChic</name> <product_id>12</product_id> </product> <product> <name>Waftel Chocolate</name> <product_id>15</product_id> </product> </products>
And, the following is the products.dtd file, which is an external DTD to the previous XML document:
<!ELEMENT products (product)+> <!ELEMENT product (name, product_id)> <!ELEMENT name (#PCDATA)> <!ELEMENT product_id (#PCDATA)>
You can also reference a private external DTD using its Uniform Resource Locator (URL). In this case, you just specify a URL after the SYSTEM keyword:
<!DOCTYPE products SYSTEM "http://www.brainysoftware.com/dtd/products.dtd">
A public external DTD is quite similar, except that you must define a Formal Public Identifier (FPI) after the PUBLIC keyword in the <!DOCTYPE> element. The FPI has four fields, each of which is separated from each other using double forward slashes (//). The first field in an FPI indicates the formality of the DTD. For a DTD that you define yourself, you use a minus (−) sign. If the DTD has been approved by a nonstandard body, you use a plus (+) sign. For a formal standard, use the reference to the standard itself. The second field in an FPI is the name of the organization that maintains the DTD. The third field indicates the type of document being described, and the fourth field specifies the language that the DTD uses. For example, EN stands for English.
This is an example of a <!DOCTYPE> that references an external public DTD:
<!DOCTYPE products PUBLIC "-//bs//Exports//EN"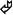 "http://brainysoftware.com/products.dtd">
"http://brainysoftware.com/products.dtd">
Entities
In a DTD, you can define entities. You will probably ask then, what is an entity? To explain it to a programmer like yourself, it is best to draw an analogy between an entity in an XML document and a constant in a computer program. You declare a constant (using the keyword Const in Visual Basic) and assign it a value so that you can reference the value through the constant from within your code. Likewise, you define an entity in a DTD so that you can use it from anywhere in the XML document. You define an entity using the following syntax:
<!ENTITY name definition>
When the XML document is parsed, the entity will be replaced by the value of the entity. To use the entity, you precede the entity name with the ampersand (&) and add a semicolon (;) after the name. For example, to refer to an entity called myEntity, you write &myEntity;.
As an example, Listing 2-5 shows an XML document in which an entity named company is declared in its DTD. The value of the entity is Cooper Wilson and Co.
Listing 2-5: An XML Document with an Entity
<?xml version="1.0" standalone="yes"?> <!DOCTYPE products [ <!ELEMENT products (manufacturer, (product)*)> <!ELEMENT manufacturer (#PCDATA)> <!ELEMENT product (name, product_id)> <!ELEMENT name (#PCDATA)> <!ELEMENT product_id (#PCDATA)> <!ENTITY company "Cooper Wilson and Co."> ]> <products> <manufacturer>&company;</manufacturer> <product> <name>ChocChic</name> <product_id>12</product_id> </product> <product> <name>Waftel Chocolate</name> <product_id>15</product_id> </product> </products>
When a parser, such as Internet Explorer, reads this XML document, it replaces the entity with its value, like in Listing 2-6.
Listing 2-6: An XML Document with an Entity's Value
<?xml version="1.0" standalone="yes" ?> <!DOCTYPE products (View Source for full doctype...)> <products> <manufacturer>Cooper Wilson and Co.</manufacturer> <product> <name>ChocChic</name> <product_id>12</product_id> </product> <product> <name>Waftel Chocolate</name> <product_id>15</product_id> </product> </products>
You can use five predefined entities in your XML document without declaring them in the DTD: ', ", &, <, and >.
Attributes
You specify attributes that an element has using the following syntax:
<!ATTLIST elementName attributeName_1 type_1 defaultValue_1 attributeName_2 type_2 defaultValue_2 . . . attributeName_n type_n defaultValue_n>
For example, to define that the <product> element must have the id attribute, you write the code shown in Listing 2-7.
Listing 2-7: An XML Document with Elements and Attributes
<?xml version="1.0" standalone="yes"?> <!DOCTYPE products [ <!ELEMENT products (product)*> <!ELEMENT manufacturer (#PCDATA)> <!ELEMENT product (name, product_id)> <!ELEMENT name (#PCDATA)> <!ELEMENT product_id (#PCDATA)> <!ATTLIST product supplier_id CDATA #IMPLIED> ]> <products> <product supplier_> <name>ChocChic</name> <product_id>12</product_id> </product> <product supplier_> <name>Waftel Chocolate</name> <product_id>15</product_id> </product> </products>
The default value #IMPLIED means that the attribute is optional.
Schemas
Like DTDs, schemas validate XML documents. However, schemas are more powerful. Schemas provide the following advantages over DTDs:
-
Additional data types are available using a schema.
-
Schemas support custom data types.
-
A schema uses XML syntax.
-
A schema supports object-oriented concepts such as polymorphism and inheritance.
| Note | Schemas are basically XML documents. By convention a schema has an .xsd extension. The term instance document is often used to describe an XML document that conforms to a particular schema. A schema does not have to reside in a file, though. It may be a stream of bytes, a field in a database record, or a collection of XML Infoset "information items." |
In discussing schemas, it is convenient to refer to elements as simple types and complex types. Elements that contain subelements or carry attributes are complex types, whereas elements that contain numbers (and strings, dates, and so on) but do not contain any subelements are simple types. Some elements have attributes; attributes always have simple types.
The W3C recommendation defines schemas in a three-part document at the following locations:
-
http://www.w3.org/TR/xmlschema-0/
-
http://www.w3.org/TR/xmlschema-1/
-
http://www.w3.org/TR/xmlschema-2/
Each of the elements in the schema has a prefix xsd:, which is associated with the XML Schema namespace through the declaration xmlns:xsd="http://www.w3.org/2001/XMLSchema" that appears in the schema element. By convention, the prefix xsd: denotes the XML Schema namespace, although you can use any prefix. The same prefix, and hence the same association, also appears on the names of built-in simple types—for example, xsd:string. The purpose of the association is to identify the elements and simple types as belonging to the vocabulary of the XML Schema language rather than the vocabulary of the schema author. For clarity, I just mention the names of elements and simple types and omit the prefix.
| Note | Like DTDs, schemas can appear inside an XML document or as external documents. The schemaLocation and xsi:schemaLocation attributes specify the location of an external schema referenced by an XML document. However, the project in this chapter does not support external schemas; therefore, I do not discuss them in detail. Interested readers should read the document at http://www.w3.org/TR/xmlschema-0/. |
In XML Schema, there is a basic difference between the complex types that allow elements in their content and can carry attributes and the simple types that cannot have element content and cannot carry attributes. There is also a major distinction between definitions that create new types (both simple and complex) and declarations that enable elements and attributes with specific names and types (both simple and complex) to appear in document instances. In this section, we focus on defining complex types and declaring the elements and attributes that appear within them.
You define new complex types using the complexType element; such definitions typically contain a set of element declarations, element references, and attribute declarations. The declarations are not themselves types, but rather an association between a name and the constraints that govern the appearance of that name in documents governed by the associated schema. You declare elements using the element element, and you declare attributes using the attribute element. Listing 2-8 is an example of an XML document that uses an inline schema.
Listing 2-8: Using an Inline Schema
<xs:schema xmlns:xs='http://www.w3.org/2001/XMLSchema' xmlns='xsdBook' targetNamespace='xsdBook' > <xs:element name='Book'> <xs:complexType> <xs:sequence> <xs:element name='Title' type='xs:string' maxOccurs='1'/> <xs:element name='Author' type='xs:string' maxOccurs='1'/> </xs:sequence> <xs:attribute name='Edition' type='xs:string' use='optional'/> </xs:complexType> </xs:element> </xs:schema> <hc:Book Edition='1' xmlns:hc='xsdBook'> <Title>Dogs are from Mars, Cats are from Venus</Title> <Author>T. Sakhira</Author> </hc:Book>
Related XML Resources
To conclude the discussion of XML basics, the following are links to useful documents to help you work with XML and understand it better:
-
http://www.w3c.org/xml: The official Web site of XML
-
http://www.w3c.org/TR/REC-xml/: The W3C XML 1.0 recommendation
-
http://www.w3c.org/DOM/: The W3C Document Object Model
-
http://www.w3.org/TR/REC-xml/: The formal rules for DTDs in XML 1.0
-
http://www.w3.org/TR/xmlschema-0/: XML Schema Part 0: Primer
-
http://www.w3.org/TR/xmlschema-1/: XML Schema Part 1: Structures
-
http://www.w3.org/TR/xmlschema-2/: XML Schema Part 2: Datatypes
-
http://www.xml.com/: A site dedicated to providing XML resources, discussions, and so on
-
http://msdn.microsoft.com/xml/tutorial/default.asp: Microsoft's XML tutorial
Now that you have a good background of XML theory, it's time to learn how to program XML in the .NET Framework.
|
EAN: 2147483647
Pages: 82