| Versions of NDS prior to NDS 8 relied on a flat-file data store known as Record Manager (RECMAN), which has no real indexing. Anyone with some database experience knows that indexes are essential for efficient and fast database searches. To address this shortcoming, NDS and eDirectory switched away from using a flat-file structure for the data store and now use Flexible Adaptive Information Manager (FLAIM) instead; FLAIM is far more scalable than RECMAN. As a result, NDS 8 and higher allow significantly more information to be held on a single server, without requiring you to partition DS. In addition, database indexes have been introduced to increase performance of any client (including LDAP) accessing the database, especially during attribute value searching. eDirectory supports the following four types of indexes: -
Operational ” Operational indexes are required for the proper operation of eDirectory (much like the operational schema definitions) and cannot be modified, suspended , or deleted by administrators. Examples of operational indexes include GUID and Obituary . -
System ” System indexes are required for the proper operation of eDirectory at the database level and cannot be modified, suspended, or deleted by administrators. Examples of system indexes include Member and Reference . -
Auto Added ” Auto Added indexes are predefined indexes that are added to the database by eDirectory during the database creation phase. Auto Added indexes are indexes for attributes that are frequently used in queries by applications that access eDirectory. CN is an example of an Auto-added index. In eDirectory 8.7 and above, if any object in the tree has an attribute that has more than 25 values, an Auto Added index for the attribute will be automatically added by the system. -
User Defined ” User Defined indexes are indexes that have been manually created by the system administrator and are generally used in conjunction with predicate stats for performance-tuning purposes. These indexes can be created, suspended, and deleted as needed. TIP Due to the underlying structure of the eDirectory database, System indexes have faster access times than User indexes. User-added indexes still increase the performance of LDAP queries, for instance, if the attribute does not meet the criteria to be automatically added. You can use predicate stats (discussed later in this chapter, in the "What Attribute Needs to Be Indexed?" section) to determine which attribute can benefit from a User index.
The indexes are defined on a server-by-server basis and are stored in the indexDefinition attribute (syntax type SYN_CI_LIST ) of the NCP Server object (see Figure 16.3). Each index on a server applies to the data stored on that server only. Index definitions are not replicated to other servers, but by using ConsoleOne or iManager, you can easily copy an index definition from one server to another server. Figure 16.3. Default eDirectory indexes. 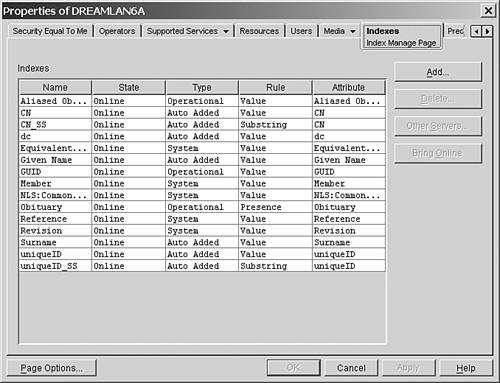
Each index is based on one of three types of index matching rules that determine how the index will be matched: -
Presence ” An index based on the Presence rule simply provides a Boolean value of True or False , depending on whether the desired attribute exists. A Presence index optimizes queries with criteria that only involve the presence of an attribute. An example of this type of query is to find all entries with a Login Script attribute. -
Value ” An index based on the Value rule provides an ordered list of objects based on the value of the specified attributes. A Value index helps with queries in which the criteria involve the entire value or the first part of the value. For example, a Value index helps on both a query to find all entries with a Surname attribute value that is equal to Jensen and a query to find all entries with a Surname attribute value that begins with Jen . -
Substring ” A Substring index allows for complex searches on characters within the attribute data. A Substring index can be used to optimize queries with criteria that are a subset of a String value. For example, a query to find all entries with a Surname attribute value that contains der would benefit from this index. The query in this example would return matches for (among others) Derington , Anderson , and Lauder . Given the large number of possible combinations of attribute data, Substring indexes are costly to create and can require large amounts of resources to keep updated. Therefore, you should keep Substring indexes to a minimum. Indexes based on the Substring rule are by far the most costly index type in eDirectory. TIP If your LDAP search performance doesn't improve after adding a Presence index, you should try using a Value index instead for the same attribute. LDAP will use this index when doing a Presence search.
REAL WORLD: Inside the indexDefinition Attribute The indexDefinition attribute on the NCP Server object is defined using the SYN_CI_LIST syntax. It is a multivalued attribute. Each value of the attribute holds the following information fields: -
Index Version ” This field is reserved for future use and has a value of 0. -
User-defined Index Name ” This field is used to identify the index on the Index tab of ConsoleOne. You can define any name that best describes the index (for example, " Group membership" or "Zip code value"). The index name should not contain the $ character because it is used as the delimiter between the data fields within the attribute value. If you use the $ character in the name, you must escape it when working with the indexes via LDAP . -
Index State ” Possible field values are (Suspended), 1 (Bringing Online), 2 (Online), and 3 (Pending Creation). When an index is in the Suspended state, it is not used in queries and is not updated. The Bringing Online state indicates that an index is in the process of being created. The Online state means that the index is up and working. A Pending Creation state means that the index has been defined and is waiting for the background process to begin its operation. When you're defining an index using LDAP , you should set this field to 2 . The background process automatically changes the state when index building has begun. -
Index Rule ” Possible field values are (Value Matching), 1 (Presence Matching), and 2 (Substring Matching). -
Index Type ” This field indicates whether the index is User-Defined ( ), Auto Added ( 1 ) ”that is, added on attribute creation ”Operational ( 2 ) ”that is, required for operation ”or a System index ( 3 ). When you're defining an index using LDAP , this value should always be set to ; ConsoleOne automatically sets this field to . -
Index Value State ” eDirectory uses this field to identify the source of the index. Possible values are (Uninitialized), 1 (Added from Server), 2 (Added from Local DIB ), 3 (Deleted from Local DIB ), and 4 (Modified from Local DIB ). Indexes that are predefined or that were added or modified using ConsoleOne are identified with the 2 , 3 , or 4 values. An index created using LDAP should have this field set to 1. -
Attribute Name ” This field contains the name of the DS attribute that is being indexed. In many cases, attributes have both a DS name and an LDAP name mapped to it. You should be sure to use the DS name for the attribute. When you create an index by using ConsoleOne or iManager, this is not an issue because you select from the list of known DS attribute names . When you create an index by using LDAP , however, you should make sure to use the appropriate DS attribute name, not the LDAP mapped attribute name. You should be careful to escape any characters that need to be escaped. |
When a new index is defined or the state of an existing index is changed, the operation does not happen immediately. A background process that runs every 30 minutes checks the index definition values against the current index status and then starts any necessary processes. As a result, indexes are built in the background while the directory is still working. When the index is completed, its status changes to Online automatically, and at that point, the users should notice the performance improvement. Managing eDirectory Indexes You manage eDirectory indexes by using ConsoleOne or iManager. Because these indexes are associated with the server, in ConsoleOne you access them through the Indexes tab on the Properties page of the NCP Server object. When using iManager, you select eDirectory Maintenance, Index Management, server . Figure 16.4 shows the Create Index dialog box from ConsoleOne. From the Indexes tab in ConsoleOne, you can also change an index's state between Suspend and Online, delete a User Defined index, or copy an index definition to another server. At the time of this writing, you can use NDS iMonitor only to view the indexes and their states (by selecting Agent Summary, clicking the server name in the Navigator frame, and selecting indexDefinition from the list of attributes), as shown in Figure 16.5. Figure 16.4. Adding an eDirectory index. 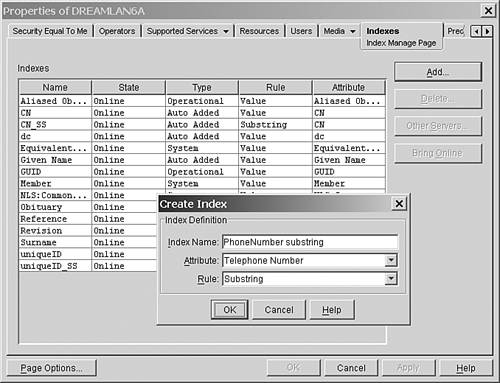
Figure 16.5. eDirectory index status. 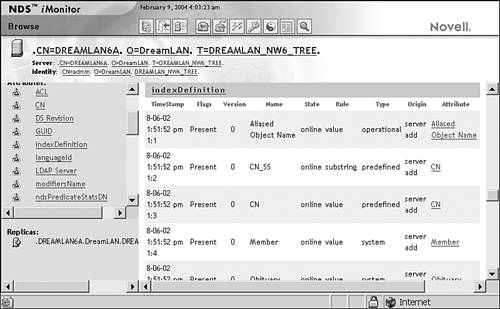
NOTE You can also manage the eDirectory indexes by using iManager. In addition, Novell provides a command-line utility called ndsindex for managing eDirectory indexes. In Windows, it is found in \Novell\NDS , and in Unix, it is in /usr/ldaptools/bin . In NetWare, the utility is NINDEX.NLM , and it is shipped with NetWare 6.5 and later; you can also get a copy of it by downloading the LDAP NDK from Novell DeveloperNet, installing Service Pack 3 for NetWare 6.0, or installing eDirectory 8.7.3.
Other than by using ConsoleOne and iManager, you can define and manage eDirectory indexes via LDAP. The advantage of using LDAP is that an application can define indexes during the installation process. Index definitions can be part of the same LDIF file that applies the required schema extension for the application. The LDIF file shown in Figure 16.6 creates a Substring index (called PhoneNumber substring ) for the Telephone Number attribute. Figure 16.6. An LDIF file to add a substring index. 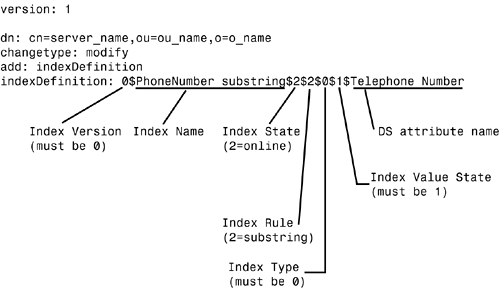
WARNING Keep in mind the following requirements when creating an eDirectory index via LDAP : -
If a $ character is present in the field value, it must be escaped. (To make things easiest , it is best not to use the $ character at all.) -
The Index State field (the third field) value must be set to 2 . -
The Index Value State field (the sixth field) value must be set to 1 . -
The Attribute Name field (the seventh field) value must specify the DS attribute name, not the LDAP mapped name.
NOTE You can either use ICE (from within ConsoleOne or from a command line) or the ldapmodify .exe utility included with eDirectory to process an LDIF file.
You can also use LDAP to programmatically change the state of a defined index. You should first query the NCP Server object's indexDefinition attribute to determine the current Index State value before modifying it. Then you set the Index State field to either to suspend it or 2 to start bringing it online. You should never change the state to either Bringing Online ( 1 ) or Pending Creation ( 3 ). A background process does this automatically. The following LDIF commands change the state of the PhoneNumber substring index from Online to Suspended: version: 1 dn: cn= server_name ,ou= ou_name ,o= o_name changetype: modify delete: indexDefinition indexDefinition: 0$PhoneNumber Substring version: 1 dn: cn= server_name ,ou= ou_name ,o= o_name changetype: modify delete: indexDefinition indexDefinition: 0$PhoneNumber Substring$2$2$0$1$ Telephone Number add: indexDefinition indexDefinition: 0$PhoneNumber Substring$0$2$0$1$ Telephone Number $ Telephone Number add: indexDefinition indexDefinition: 0$PhoneNumber Substring version: 1 dn: cn= server_name ,ou= ou_name ,o= o_name changetype: modify delete: indexDefinition indexDefinition: 0$PhoneNumber Substring$2$2$0$1$ Telephone Number add: indexDefinition indexDefinition: 0$PhoneNumber Substring$0$2$0$1$ Telephone Number version: 1 dn: cn= server_name ,ou= ou_name ,o= o_name changetype: modify delete: indexDefinition indexDefinition: 0$PhoneNumber Substring$2$2$0$1$ Telephone Number add: indexDefinition indexDefinition: 0$PhoneNumber Substring$0$2$0$1$ Telephone Number $ Telephone Number
What Attribute Needs to Be Indexed? Although appropriate indexes can significantly improve performance, you should be aware of the cost associated with each index added to the directory. To start with, each addition, deletion, or modification of an entry in the directory causes all indexes affected by the change to be updated. Substring indexes are the most costly (that is, CPU intensive ) to create and update, and Presence indexes are the least costly. The more indexes that exist on a server, the longer the time it takes to perform add, delete, or modify operations. Consequently, indexes should be used judiciously. A secondary side-effect of adding indexes is that each index requires some storage to contain it. Thus, each index adds to the size of the server's DIB. TIP Because each object addition or modification requires touching the defined indexes, having all the indexes active may slow down bulk-addition or bulk-modification of data in the directory. To achieve additional speed during bulk operations, you might first want to suspend some or all of the User Defined indexes, especially the Substring ones. After the operation is completed, you can then bring the indexes online. The indexes will (re-)build in the background and become effective when updating is complete.
So, which attributes should you index? To help make that determination, eDirectory provides the capability to capture search predicate statistics data. Predicate statistics data, often called predicate stats data, is a server-specific history of the objects people search for. You can use predicate stats to identify the most frequently searched for objects and then create indexes to improve the speed of future information access. NOTE eDirectory 8.7.3 ships with the following set of predefined indexes that provide basic query functionality: Aliased Object Name ldapClasssList CN Member Dc Obituary Equivalent to Me Reference extensionInfo Revision Given Name Surname GUID uniqueID ldapAttributeList You can look up the index definitions by using ConsoleOne, iManager, or NDS iMonitor, as discussed earlier in this chapter, in the "Managing eDirectory Indexes" section. eDirectory internally defines a number of Operational and System indexes (for instance, an index for combined class ID and RDN [ ClassID_RDN_IX ] and an index for combined parent ID and creation time stamp [ ParentID+CTS_IX ]). They are not documented, but you can see them referenced in DSTrace (see the "Is Your Query Really Using the Indexes?" section, later in this chapter).
When eDirectory is installed, a special Predicate Stats object is created. The name of the object is the server name, with -PS appended (for example, NETWARE65-PS or WIN2K-NDS-PS ). You can create as many objects of this type as you feel necessary, but typically a single object will suffice. TIP Although only one Predicate Stats object can be linked with a server at any one time, you can keep multiple Predicate Stats objects for testing of multiple scenarios, for instance.
At the time of this writing, only ConsoleOne can be used to view and manage the predicate stats collected by an NCP Server object. Figure 16.7 shows an example of the ConsoleOne Predicate Data tab. Figure 16.7. eDirectory predicate stats data. 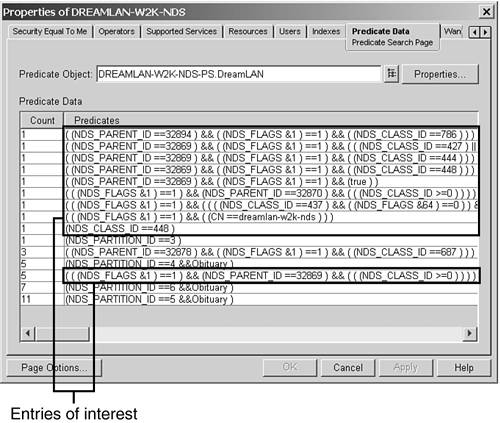
The Predicate Stats object itself has no configuration option. All its settings are handled through the Predicate Data tab of the NCP Server object. The following steps describe how to configure the Predicate Stats object and its functionality: - In ConsoleOne, right-click the NCP Server object and select Properties from the context menu.
- Select the Predicate Data tab.
- Select the Predicate Stats object, using the Browser button if necessary.
- Click the Properties button to specify the appropriate configuration for the object.
- Set the update interval, which is the number of seconds to wait before refreshing the data display and writing data to disk. (This updates the ndsPredicateTimeout attribute on the Predicate Stats object.)
TIP If the data display does not refresh, you can exit the Properties dialog box and open it again. - Click the Advanced button for additional configuration options:
-
Enable ” This option specifies whether the collection process should run in the background or should be turned off. If you turn off data collection (by unchecking the check box), the most recently collected data will either be released from memory (that is, lost) or, if you've selected Write to Disk, it will be moved to disk. (This updates the ndsPredicateState attribute on the Predicate Stats object.) -
Display Value Text ” This option determines whether the data display will be abbreviated or complete. The abbreviated display provides enough information to determine which predicates are good candidates for indexes. For instance, with Display Value Text selected, the predicate stats data displays one entry for the search surname=Smith and another entry for surname=Jones . However, if the option is not selected, the prior two queries will be displayed as two instances of the surname== predicate. (This updates the ndsPredicateUseValues attribute on the Predicate Stats object.) -
Write to Disk ” This option determines storage location of predicate data, either always in memory or moving from memory to disk ”saved to the ndsPredicate attribute of the Predicate Stats object ”as specified in Update Interval. (This updates the ndsPredicateFlush attribute on the Predicate Stats object.) - Click OK to update the Predicate Stats object configuration.
For testing purposes, you can shorten the refresh Update Interval setting and perform a few find operations by using ConsoleOne. This will generate some data to populate the Predicate Data tab display. You can change the settings of the Predicate Stats object via its Other Edit tab instead of going through the NCP Server object's Predicate Data tab. WARNING The in-memory buffer has no upper limit, so if most predicates are unique, it is possible to use up all of a server's available memory.
WARNING The predicate statistics functionality is not intended to be run all the time that the directory is in operation. Collecting these statistics affects performance of the server, and lengthy accumulation of statistics can result in large databases.
In order to view the predicate statistics from ConsoleOne, the Write to Disk setting must be selected. Each time the internal table is flushed to the ndsPredicate attribute of the selected Predicate Stats object, the values in the table are compared to the predicates held by the object. If the values are the same, the count is simply updated to reflect the new instance of that predicate. If the internal table holds new predicates, they are added as values to the object. TIP If ConsoleOne refuses to display any statistics after you have properly configured the Predicate Stats object, you can turn on DSTrace on the server to see whether it is reporting any -649 (Insufficient Buffer) errors when trying to load the predicate statistics table. If it is, then this is the reason you are unable to view the statistics ”the server is low on memory.
If you decide to change the statistics display mode by toggling the Display Value Text check box, it is recommended that you first turn statistics collection off, clear out all the old statistics values, change the display mode setting, and then turn statistics collection back on. TIP You may have noticed that the Predicate Data tab does not have an option to clear the data from the Predicate Stats object. To clear the old values, you can delete the ndsPredicate attribute from the Predicate Stats object.
Entries in the Predicate Data tab list are sorted by the number of times they have been used. The list may be a little difficult to read because it shows internal search information as well as user query information. TIP Sometimes the full predicate does not fit in the display window. To expand it, you can use a mouse to drag the right column width marker farther to the right. You can then use the horizontal scrollbar to see more of the predicate information.
Figure 16.8 shows a number of entries that may be helpful in determining what attribute may warrant an index. The following three entries are examples of what to look for when deciding what indexes may be required: (((NDS_FLAG&1)==1)&&((((NDS_CLASS_ID==437)&&((NDS_FLAGS&64)==0)... (((NDS_FLAG&1)==1)&&((CN==dreamlan-w2k-nds))) (((NDS_FLAG&1)==1)&&(NDS_PARENT_ID==32869)&&(((NDS_CLASS_ID>=0))))
Figure 16.8. The entry ID of the User class schema definition. 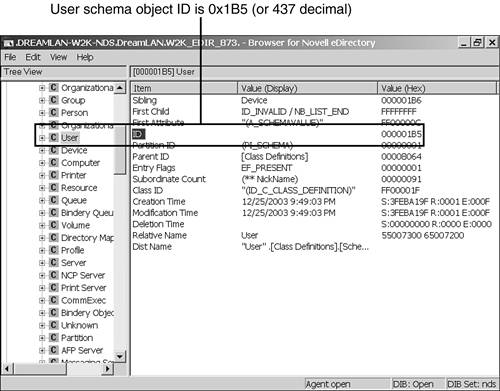
The first sample entry shows that the query used the filter NDS_CLASS_ID==437 . This indicates that a search was performed on an object class whose (schema) entry ID value is 437 decimal (1B5 in hex). To find out what object class has an ID of 437, you need to use DSBrowse to perform a find based on the ID. Figure 16.8 shows that the User class schema definition has an entry ID of 1B5. TIP When you have the class ID, it is very easy to locate the classname. In DSBROWSE.NLM , you select Object Search, enter the class ID (in hex) into the ID field under Object Information, and press F10 to start the search. For DSBrowse in Windows, you switch to the DIB Browser view. Then you right-click [Schema Root] under Entries, Go to Record ID. Next, you enter the class ID in the Record Number field, select Entry for the Record type, and click OK to start the search.
WARNING Bear in mind that entry IDs are server specific. Therefore, on a different server, the schema entry ID for the User class will have a different value.
If you are seeing a high count value (meaning many searches using that filter) for NDS_CLASS_ID==437 , you should check to see whether the same predicate search includes any attribute names, such as "search in all User objects whose Department attribute value is Sales ." If the answer is yes, the specified attribute names are potential candidates for indexing. Otherwise, creating an index for just the Object Class attribute may be useful; refer to the "General Guidelines for Using Indexes" section, later in this chapter, for more information. The second predicate data entry example shows that the search was for a particular CN , an NCP Server object ( dreamlan-w2k-nds ). In more than 80% of the searches, specific object names ( CN ) are used. For example, "Show me all values in the ACL attribute for user Chelsea ." When you have many objects in the tree, indexing CN is an excellent idea ”and that's why CN is one of the predefined indexes. The other 20% of searches would include queries such as "Show me all the objects that have a Location value of New York City ," where the CN index is not used. The third example shows that the filter NDS_PARENT_ID==32869 was used. This indicates that the search is either looking for a DS container (whose parent container's entry ID is 32869 decimal or 0x8065 hexadecimal), objects in this container, or objects in this container and its subordinate containers. However, the parent ID here refers to the entry ID of the partition root object of the partition where the search is targeted . Using DSBrowse or NDS iMonitor, you can determine the name of the container based on the entry ID, thus the partition in question. Although this information does not help you to decide what attribute needs to be indexed, it does suggest whether you should put a replica of that partition on this server. NOTE The LDAP server discussion in Chapter 2, "eDirectory Basics," mentions that there would be network traffic implications, depending on whether the LDAP server is configured for chaining or referral. If your predicate stats show that there are many queries ” unfortunately , you can't tell whether the searches are made via LDAP ”on this server for objects in a partition that it is not hosting, you need to consider either placing a replica on it to reduce tree-walking or reconfigure the application to query a different server that does hold a replica of interest.
The following are a few points to keep in mind when working with predicate stats: -
Do not leave the predicate statistics function running all the time. Collecting predicate stats affects performance of the server, and lengthy accumulation of statistics can result in a large DIB. -
Each object addition or modification requires that the defined indexes be updated. Therefore, having all the indexes active may slow down bulk-addition or bulk-modification of data in the directory. You may first want to suspend all the User Defined indexes. After the operation is completed, you can bring them back online. The indexes will (re-)build in the background and become effective when updating is complete. -
Because Predicate Stats objects are replicated, you might want to define a partition that exists only on the server being tuned and store the objects there so they are not unnecessarily replicated to other servers. -
Not all entries reported in the predicate stats are useful. Many of them are results of background processes running, and you should not let them distract you. You should focus mainly on the entries that include attributes. -
Reading and interpreting predicate stats is not straightforward. Before you start using predicate stats in earnest, you should run a few sample queries and examine the resulting predicates. Knowing what the "questions" were makes it easier to understand the data. General Guidelines for Using Indexes When the server receives a search request, the query is evaluated and broken into a combination of mini-terms. Each of these mini-terms (or tokens , as they are called in text string parsing parlance) becomes a search predicate. One index is selected as being optimal for each predicate. The indexed attribute is used to create the initial result pool for that predicate, and then the other predicate criteria are applied to form the final set. Result sets from the different predicates are then merged to form the final result set. The complete rules for how an index is selected are complex and generally uninteresting to most people. The following are some simple guidelines to consider when working with eDirectory indexes: -
The search predicates that show up in the statistics screen do not necessarily represent the database's optimization of the query. These values are only to be used as indicators of the attributes that are most commonly referenced. -
Although it is possible, and often tempting, to create an index on the Object Class attribute, the effectiveness of the index depends very much on the type of data you are using. For example, if your tree has two million users and five printers defined, an Object Class index makes sense when you are searching for printers but would not gain you any performance benefit if you were searching for users. -
If the number of objects matching a search filter approaches a high percentage of the number of objects in the tree, query performance may be better if no index is used. -
Substring indexes are the most costly type of index to maintain, so the presence of several Substring indexes can severely affect add, delete, and modify performance. You should use Substring indexes sparingly. -
Value indexes on large string or octet string attributes may not provide the desired performance improvement. eDirectory truncates indexed string values at 32 bytes and indexed octet string values at 49 bytes. When a query includes a value that is larger than the truncation value (say, a string that is 40 bytes long), the index can only be used to generate a possible result set. Each object in the possible set must then be read and evaluated to make sure it fits the criteria. -
Although indexes enhance search performance, each additional index adds to the update time for a new object; this is especially true for Substring indexes. Therefore, for massive bulk-loading operations, you should consider suspending User Defined indexes, especially the Substring indexes, during the operation. -
Defining an index for each attribute within a query rarely provides performance benefits. Complex search filters are broken down to predicates during the filter evaluation, and eDirectory uses only one index per predicate. The DSA selects one optimal index per complex search and then applies the other filter criteria to the results pulled from the index. Therefore, if you see a predicate searching for four attributes, there is no need to create four indexes ”unless they are also used by other predicates. -
Queries containing ! in the expression do not use indexes. The reason for this is that objects where the attribute is not defined are also returned in the result set. -
Queries that contain a greater-than-or-equal-to specification ( >= ) use an index, but queries containing less-than -or-equal-to ( <= ) do not. As is the case with ! queries, a <= query assumes that all objects that don't contain the attribute match the query. -
If a query includes multiple predicates on the same indexed attribute that are concatenated together, query performance is generally better if the more specific predicate is given before the less specific predicate because eDirectory uses the index attribute on the first predicate only. For example, if you are trying to find users who belongs to both the GW Support group and Support group, this search filter: ((groupMembership=="GW Support")&& (groupMembership=="Support"))
performs better than the following query: ((groupMembership=="Support")&& (groupMembership=="GW Support"))
because the first filter has the more specific predicate, GW Support , listed first. Is Your Query Really Using the Indexes? Indexes are not miracle solutions to all query-based performance bottlenecks. They can greatly help improve search speeds if the applications can take advantage of them, such as by formulating and structuring the search filters to the way eDirectory works. But how can you find out after creating all the necessary indexes whether the still-not-so-speedy search response time is due to the applications or a system bottleneck somewhere else? DSTrace provides much information to many eDirectory internal processes, and it can help you again in this situation. By setting the Record Manager filter for tracing, you can see which index was picked for a particular query. NOTE As discussed in the "Server Tools" section in Chapter 7, "Diagnostic and Repair Tools," there are two implementations of DSTrace on NetWare servers: the built-in SET DSTRACE command and the DSTRACE NLM command. In order to view the RECMAN information, you need to use the NLM implementation. On Windows servers, the RECMAN filter in DSTrace is called Storage Manager (StrMan) instead.
The following example shows a ConsoleOne query that is looking for the x121Address attribute by doing a find for the attribute. Notice that the boldfaced message indicates that no index was used to perform the query: [02/10/2004 06:24:07.96] StrMan : Iter #c31e00 query ((Flags&1)==1) && ((((x121Address9A$.Flags&8)==8) && x121Address9A$.Flags&8))) [02/10/2004 06:24:07.96] StrMan : Iter #c31e00 NO INDEX USED [02/10/2004 06:24:07.96] StrMan : Iter #c31e00 first ( ID_INVALID)
NOTE The ID_INVALID message indicates that the search found no matching objects. Otherwise, an entry ID (EID) value will be displayed.
The following example is a ConsoleOne query for a list of NCP Server objects in the tree. Notice that the highlighted message indicates that the ClassID_RDN_IX index, an internal eDirectory index, was used to perform the query: [02/10/2004 06:23:03.89] StrMan : Iter #6d74ee0 query ((Flags&1)==1) && (((ClassID==448) && ((Flags&64)==0))) [02/10/2004 06:23:03.89] StrMan : Iter #6d74ee0 index = ClassID_RDN_IX [02/10/2004 06:23:03.89] StrMan : Iter #6d74ee0 first ( eid=32871)
Using the information provided by DSTrace along with the predicate stats provides you with some good tools for pinpointing possible bottlenecks in search performance. |