Oracle 10g Data Pump Enhancements
| Starting with 10g, Oracle now provides new infrastructure support for high-speed data movement in and out of the database. The foundation for this support is referred to as Oracle Data Pump. This chapter details the new features of Oracle Data Pump and how to effectively utilize its capabilities and features to dramatically increase data movement performance compared to previous releases of the Oracle database. Oracle 10g Data Pump ConceptsData Pump is a new feature offered with Oracle Database 10g that enables high-speed data and metadata movement for the Oracle database. The primary goal of Data Pump is to provide a dramatic increase in performance and manageability compared to the original export and import utilities as well as to add high-speed data load and unload capabilities for existing tables. Oracle 10g Data Pump provides this new technology by extracting data at the block level into platform-independent flat files using an efficient proprietary format via the new PL/SQL package DBMS_DATAPUMP. The DBMS_DATAPUMP PL/SQL package serves as the core application program interface (API) for high-speed data and metadata movement within the Oracle server. Oracle Data Pump is also the cornerstone for other key 10g database features such as transportable tablespace, logical standby database, and Oracle streams.
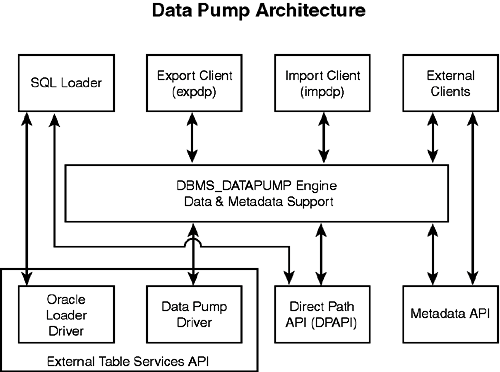
Oracle 10g Data Pump is available in all versions of the database, but parallelism with a degree greater than one is available only in the Enterprise Edition. Data Pump has the same look and feel as the original export (EXP) and import (IMP) utilities, however is completely different. Dump files created by the new Data Pump technology are not compatible with the dump files created by EXP. Therefore, dump files created by the EXP utility cannot be used with Data Pump. Data Pump ArchitectureThe diagram in Figure 19.1 details the major components for 10g Data Pump. Figure 19.1. Oracle 10g Data Pump architecture overview.
In basic terms, the Data Pump architecture consists of the following:
As noted, 10g Data Pump offers two access methods to table data: Direct Path API (DPAPI) and External Table Services API. Because both methods support the same external data representation, data that is unloaded with one method can be loaded by using the other method. When invoked, Data Pump will automatically select the most appropriate access method for each operation. By default, Data Pump will use the Direct Path API (DPAPI) when a table's structure allows it and when maximum performance is desired. If, however, any of the following conditions exist with your operation, Data Pump will automatically use external table support rather than direct path API support:
Because Data Pump is server based, all Data Pump operations, regardless of where the command is started, are handled in the database server. Because Data Pump is server based and not client based, dump-file sets and log files are written on the server specified by server-based directory paths. When using Data Pump, the following order of precedence is employed to define directory structure paths and to locate the necessary dump files for the operation:
If none of the previous three conditions returns a directory object and you are a privileged user (that is, a user who has been granted EXP_FULL_DATABASE and IMP_FULL_DATABASE roles), then Data Pump will attempt to use the value for the server-based DATA_PUMP_DIR environment variable. It's important to note that Data Pump does not create the DATA_PUMP_DIR directory object; it only attempts to use its value when a privileged user has not provided a valid directory object using any methods previously described. This default directory object must first be created by a DBA with 10g Release 1.
In Oracle 10g Release 1, there is no default DATA_PUMP_DIR, so you must specify a valid directory object for your operation using one of the valid methods. If you do not specify a valid directory object for your operation, your operation will fail. Oracle 10g Data Pump offers support for command-line and GUI interfaces as well as API support via DBMS_DATAPUMP. Command-line support is offered by the new expdp and impdp utilities found in the $ORACLE_HOME/bin directory. GUI support is offered by the new Web-based Enterprise Manager, a.k.a. Database Control. Database Control provides an interface to create and manage Data Pump import and export jobs within the EM environment. Starting with 10g Release 2, you can use the EM GUI interface to monitor all Data Pump jobs including those created by the expdp and impdp command-line utilities or by using the DBMS_DATAPUMP package. Data Pump Process FlowOnce a Data Pump process has been initiated from an import, export, or external client connection, a shadow process is created on the server to act in its behalf. The Data Pump client will also make a call to DBMS_DATAPUMP.OPEN to establish the specifics of the operation. When the call is established on the server, a new service called the Master Control Process (MCP) is started and returns a handle identifying the specific session's access to the Data Pump operation. Along with the creation of the MCP, two queues are established. The first queue, the Status queue, is used to send status and error messages to any client connection that is interested in this operation. Basically, this queue is populated by the MCP, is consumed by any client queries, and carries the name KUPC$S_<job_timestamp_identifier>. The second queue, the Command and Control queue, is used as management control for the worker processes that are established by the MCP. The Command and Control queue is also used by the client's shadow process executing dynamic commands to the MCP via DBMS_DATAPUMP and carries the name KUPC$C_<job_timestamp_identifier>. After the queues are created, the client establishes the session parameters to DBMS_DATAPUMP using various methods such as SET_PARAMETER and ADD_FILE. Data Pump uses Advanced Queuing (AQ) to facilitate the communication between these two queues and the various Data Pump processes.
A Data Pump operation executes in the schema of the job creator with that user's rights and privileges. After all the parameters are set, the client calls DBMS_DATAPUMP.START_JOB to start the actual Data Pump job. If requested, the MCP will create any necessary parallel streams via the worker processes. After the worker processes have initialized and instructed the MCP to perform the specific action, the MCP will detail another worker process to extract the necessary database object metadata via DBMS_METADATA. Depending on whether your operation performs an export, all metadata is written to a new dump file set in XML format. If your operation is an import, the target dump file will be processed. During a data dump operation, a master table is created and maintained in the schema of the user initiating the Data Pump operation. The master table is used by the Data Pump process to track the health of the Data Pump job as well as to control the ability of both import and export operations to restart. At any point in time during the operation, the client process can detach from the job without having to abort the job. Basically, when metadata is retrieved from the Data Pump job, location and size information about each object is written to the master table. When the entire Data Pump operation is complete, the master table is loaded in its entirety into the dump-file set. While the master table serves as a recorder for export operations, an import operation will actually read, load, and process the master table from the dump-file set to complete the operation. If the operation is killed or if the MCP process is terminated, the master table will be dropped from the requester's schema.
During a Data Pump operation, more than one client process may be attached to a job to monitor its progress. Data Pump Export and Import UtilitiesData Pump export (expdp) and Data Pump import (impdp) are the new high-speed export and import utilities offered with Oracle 10g. These essentially replace the previous version of export (EXP) and import (IMP). While Data Pump export unloads data and metadata into a set of operation system files called dump-file sets, Data Pump import is used to load data and metadata from these files into any 10g target database. Data Pump export can be used to export data and metadata from both local and remote databases directly to a local dump-file set. Data Pump import can also be used to load data into a target system directly from a remote source system without any configuration files needed. These types of remote operations are known as network-mode operations and can be processed over predefined database link connections. Although the new Data Pump export and import clients do offer the same benefits as their predecessors, several new features are also introduced with their addition:
The Data Pump export and import clients provide three separate modes for user interaction: command line, parameter file, and interactive command mode. The command-line interface can be used to specify most of the Data Pump parameters directly on the command line. With the parameter-file interface, you can list all necessary command-line parameters in a parameter file called PARFILE. Interactive command interface stops logging to a terminal session and allows you to perform various commands while the operation continues to run in the background. To start interactive command mode, you will need to perform one of the following tasks:
The Data Pump import and export clients also provide five different modes that can define the scope of the operation. For Data Pump export, the following modes can be used for unloading different portions of the database:
For Data Pump import, the specified mode actually applies to the source of the operation: either a dump-file set or a remote database if the NETWORK_LINK parameter is used. When the import source is a local dump-file set, specifying a mode is actually optional. If no mode is specified, the import operation attempts to load the entire dump-file set in the mode in which the export operation was executed. For Data Pump import, the following modes can be used for loading data and metadata from either a valid dump-file set or a remote database:
Following is an example of how one would use the Data Pump feature to run a full export of a user's schema and then use the import feature to import the data:
You can also use 10g Enterprise Manager (EM) Database Control to perform Data Pump export and import operations. 10g EM offers both the Data Pump Export wizard and Data Pump Import wizard to provide the necessary GUI for Data Pump responsibilities and tasks. To access the Data Pump Export wizard, click the Export to Files link in the Utilities section of the Maintenance tab. When the Data Pump Export wizard launches, the Export: Export Type page is displayed. It offers you three choices for your export operation: Database, Schemas, or Tables, as shown in Figure 19.2. Figure 19.2. Choosing the export type from the Data Pump Export wizard. After you choose your selection, enter the necessary host credentials for the user name and password to process the export request, and click Next. If you selected Schemas or Tables, then the next page will be the Export: Select Users page, followed by the Export: Options page. If you chose Database as your export operation, you'll skip the Select Users page and land directly on the Export: Options page, shown in Figure 19.3. Here, you can set thread options, estimate disk space, specify optional files for the export operation, as well as use advanced options such as content exclusion or inclusion, flashback, and even predicate options for your export operation. Make your selections and click Next. Figure 19.3. Listing of the export options from the Data Pump Export wizard. You will see the Export: Files page, shown in Figure 19.4. Here you can set the path, name, and maximum size for the Data Pump export files. You can also add multiple files to meet your needs. Make your selections and click Next. Figure 19.4. Specifying additional export files from the Data Pump Export wizard. Next up is the Export: Schedule page, shown in Figure 19.5. Here you can schedule to run your export job immediately or at a later time, depending on your business needs. Usually you will want to schedule long-running jobs during off peak hours. Make your selections and click Next. Figure 19.5. Specifying any scheduling options for your export job.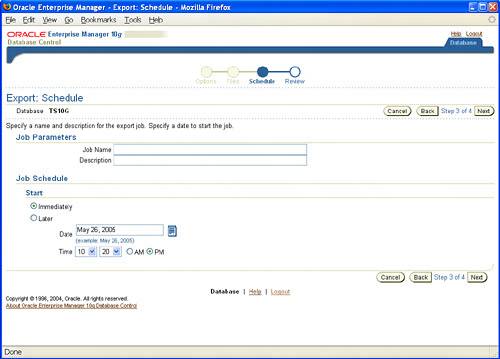 The Export: Review page is displayed, as shown in Figure 19.6. Here you will see the PL/SQL command-line interface code for the Data Pump operation, which was generated by your selections in the preceding screens. You can copy this code into a text editor to save it as a script, as well as click the Submit Job button to start the export operation. Figure 19.6. Data Pump Export wizard Summary page.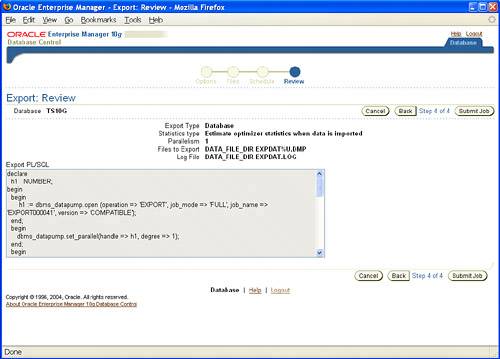 The Data Pump Import wizard has the same look and feel as the Data Pump Export wizard. To access the Data Pump Import wizard, click the Import from Files link or the Import from Database link in the Utilities section of the Maintenance tab. The first screen of the Data Pump Import wizard, shown in Figure 19.7, prompts you to choose your import method: entire files, schemas, or tables. You also need to select the correct directory object and file name so EM can process the file for the import operation. Figure 19.7. Specifying the import type and import files from the Data Pump Import wizard. After the file is processed, the import operation displays the valid options for processing. In the example shown in Figure 19.8, the entire file was processed and only one schema was available for the import operation. Figure 19.8. Listing of valid schemas from target import file. If needed, you can re-map schemas, tablespaces, or data files from the import file. Use the screen shown in Figure 19.9 to designate whether to import each user's schema into the same schema or to import into a different schema, import each object into the same or different tablespace, or change the data-file names of specific tablespaces. The remap keyword is the same as the original import/export keywords fromuser and touser. Figure 19.9. Import re-mapping options from the Data Pump Import wizard. Next is the Import: Options screen, as shown in Figure 19.10. Here you can select a nondefault log file as well as parallelism and other advanced options. When you click Next, you will see the Import: Scheduling page. Its features are the same as the Data Pump Export wizard's Scheduling page. Here you can schedule to run your import job immediately or at another time. Figure 19.10. The Import: Options screen. The last page is the Import: Review page, as shown in Figure 19.11. Here you can review the PL/SQL command lineinterface code for the import operation that was generated by the selections made from this wizard. You can copy this code into a text editor to save as a script as well as click the Submit Job button to start the import operation. Figure 19.11. Data Pump Import wizard Summary page.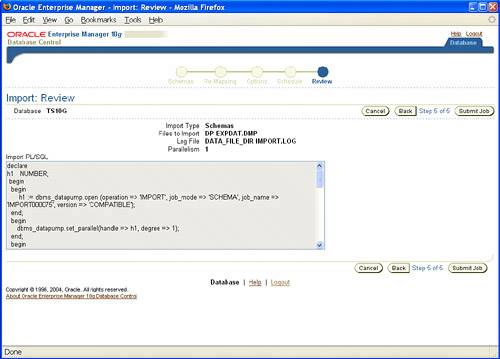 Along with export and import support, Data Pump also provides DDL transformation support. When using impdp to import data from a dump-file set, you can use the REMAP_SCHEMA parameter to provide the same support as the fromuser/touser capability from the original IMP and EXP utilities. You can also move objects from one tablespace to another using the REMAP_TABLESPACE parameter as well as move data files across platforms using the REMAP_DATAFILE parameter. Diagnosing Data Pump Issues with trACEOracle 10g Data Pump also provides the capability to diagnose and troubleshoot any issue or abnormal behavior with the Data Pump operation. The undocumented parameter trACE can be used to trace specific Data Pump components to assist in any troubleshoot needed. You can enable tracing when you initially create your Data Pump job or by temporarily stopping your current job and then restarting the job with the trACE parameter defined. To invoke tracing, the TRACE parameter is initialized by a pre-defined hex value that will detail what specific subcomponent you wish to trace. All Data Pump components such as MCP, worker processes, fixed views, and even the underlying API are eligible for tracing. Following are a few of the possible combinations for Data Pump component tracing:
The majority of errors from Data Pump can be diagnosed by using 480300 MCP + worker process tracing only. Before tracing any other component, start with this trace value first. Along with these values, you can also specify tracing for the Data Pump API calls. This must be set at the system level with event 39089, but you must restart your instance for this to take effect: SQL> alter system set event='39089 trace name context forever, level 0x300' scope=spfile; Following is an example showing how to invoke tracing with the Data Pump export utility (expdp):
The default location for the Data Pump MCP and worker process dump files is the directory specified by BACKGROUND_DUMP_DEST. The Data Pump component trace files will be written to the directory specified by USER_DUMP_DEST. If one of these directories is not specified in your instance, Oracle will send the trace files to $ORACLE_HOME/rdbms/log. Along with tracing, you can also use the SQLFILE parameter to test the validity of your Data Pump import operation (impdp) before actually modifying your database. With SQLFILE, all the SQL DDL that impdp would have executed is written to a file for review. The output file is written to the directory object specified in the DIRECTORY parameter. An example of this feature is listed here: $ impdp stroupe/asu directory=DP dumpfile=DUMP.dmp logfile=IMP_LOG.log SQLFILE=IMP_SQL_TEST.sql You can even expand this feature to generate the XML code from the export file by specifying trACE=2: $ impdp stroupe/asu directory=DP dumpfile=DUMP.dmp logfile=IMP_LOG.log SQLFILE=IMP_SQL_TEST.sql TRACE=2 Managing Data Pump JobsOracle Data Pump maintains several DBA and USER views to allow users to monitor the overall progress and health of Data Pump jobs running within the server. Data Pump users should use this to also investigate and/or troubleshoot issues that may arise from using Oracle Data Pump in their environment. Following is a short summary of a few views available to Data Pump users in Oracle 10g:
There are other DATAPUMP-type views in Oracle 10g, such as DATAPUMP_REMAP_OBJECTS, DATAPUMP_DDL_TRANSFORM_PARAMS, and DATAPUMP_OBJECT_CONNECT. These serve only as static parameter settings for the Data Pump feature. |
EAN: 2147483647
Pages: 214