The Nature of Web Log Data
Measurement industries have sprung up around each mass medium. Traditional mass media's asymmetric and indirect information flow, though, makes measurement difficult. For example, to measure television viewers , diaries or electronic meters track what station is on at what time. Connecting this information to purchases requires expensive and customized experimentation. The Internet, in contrast, is both interactive and digital. The former property implies that information also flows from the consumer to the marketer and the latter implies easily recording such information. Web site software automatically records these same visits and transactions.
A growing number of authors have written, in glowing terms, about using data from interactive media (Ansari & Mela, 2003; Burton & Walther, 2001; Cutler, 1990; Dr ze & Zufryden, 1997; Garofalakis, Kappos, & Makris, 2002; Hofacker & Murphy, 1998, 2000; Johnson, 2001; Murphy et al., 2001; Novak & Hoffman, 1997). Using actual visitors to a site optimizes external validity and the high degree of control afforded by a computermediated environment guarantees a high level of internal validity. Furthermore, the use of behavioral data avoids the errors and biases of self-reporting (Alba & Hutchinson, 2000; Blair & Burton, 1987; Lee, Hu, & Toh, 2000; Nisbett & Wilson, 1977).
Variables Captured by the Server
When someone requests a Web page, the Web server records information about the computer that requested the page and the files for that page. See Figure 11-1 and the Passive Observation of Log Data section, for a sample log file entry. The information logged includes:
-
Internet Protocol (IP) address of the requesting computer
-
domain name of the requesting computer
-
date and time of the request
-
requested URL, or address of the Web page
-
return code or status of the request
-
bytes returned, or the total amount of data sent to the requesting computer
-
referring URL, or previous page that the requesting computer visited
-
browser version that the requesting computer used
Which variables appear, and their sequence in the log file, depends on how the Web master configures the server, and whether the site uses Microsoft's Internet Information Server or the open source and freely available Apache server from Apache.org. Regardless, an important field is the return code or status of the request. Generally , the researcher should keep and analyze only those requests with a return code beginning with '2', meaning that the server successfully sent the file to the visitor.
A good overview of Web log data appears in the book by Stout (1997). The following section highlights measurement issues for interpreting such data, from the marketing practitioner's and academic's points of view. Such issues include using a local cache, identifying individual visitors, and identifying search engine robots and other automated Web page retrieval agents .
Technical Issues
-
Local Cache. Caching is a clever technique to reduce Internet traffic and help Web pages load faster. The first time a visitor requests a page, the Web server sends that page to the visitor's hard drive. If a visitor requests the same page, the Web browser - such as Internet Explorer or Netscape Navigator - first looks for that page on the computer hard drive. Thus, the Web log data show only the first request for a page by a particular visitor and not subsequent requests, which stem from the cache when the visitor hits the browser's 'back arrow.'
-
Identifying Visitors. As the fields captured in Web log data reflect, the online marketer learns more about the visitor's computer than about the visitor. Nevertheless, the IP address and the domain name associated with that IP address help identify individual visitors. Due to various technical and practical reasons however, multiple individuals may use the same IP address.
An example is the student in an Internet caf using the computer next to the window to access a particular site. Later, another person sits at the same computer and accesses the same site. Furthermore, some Internet Service Providers (ISPs) allocate IP addresses dynamically. Each dial up request from a visitor using a modem, even broadband users with DSL or cable modems, may have a different IP address. In any case, the same individual may revisit a particular site using a different computer in the Internet caf , or using a different IP address from their ISP. The upshot is that one cannot simply map IP addresses and individuals, except within relatively short spans of time. Even this, though, can be tricky.
Proxy servers add to the difficulty of mapping individuals and IP addresses. Internet Service Providers such as America Online (AOL) or large universities centralize the retrieval of Web pages for their users via proxy servers. If an AOL user requests a particular page, the AOL proxy server stores that page for a period of time for use by others with AOL. This speeds up AOL's network traffic, but complicates analyzing log data.
Novak and Hoffman (1997) defined a visitor as a series of logged records from the same domain name or IP address with no more than a 30-minute gap between consecutive Web log records. Reducing this gap to 20 minutes and using only the first three fields of the IP address - i.e., 199.168.1 instead of 199.168.1.292 - helps address identifying visitors and the problem of proxy servers.
Cookies, however controversial and intrusive , help track user visits to a site over days, weeks or months by eliminating the ambiguities discussed above. A cookie is an identifying file that the Web site's server places on the user's hard drive. In the typical case, a CGI Script, that is a computer program that interfaces with the Web server, writes a line such as:
Set-Cookie: Customer=18174
Using this simple mechanism, the server can recognize when the same computer returns by re-reading the cookie that it set previously. Again, server log data track computers, not people. Furthermore, cookies alone cannot extract information such as user e-mail addresses - one can only read the variables previously written by the CGI script. Requiring visitors to log in to a particular site can also identify visitors, but this process goes beyond the simple use of log file data.
-
Robots and Web Crawlers. Another subtlety in the use of Web log data comes from robots. These automated agents that retrieve and inspect Web pages might traverse a Web site, indexing the pages for a search engine. Each robot generally has a unique 'Browser Version' that identifies it. Similar to cleaning survey data or other data, filtering these unwanted Web crawlers from the log data is necessary prior to statistical analysis. According to well-accepted protocols, robots request a file called robots.txt before traversing a site. Visitors that request that file are inhuman. Collecting such identifying characteristics helps filters robots from the log data (Hofacker & Murphy, 1998, 2000; Murphy, 1999; Murphy & Hofacker, 2003; Murphy et al., 2001).
Modeling Issues
This section reviews possible criterion variables to use with log data, and models appropriate to each type of data.
-
Click-Through. When the focus is on click-throughs for particular links, the data resemble choice data, and in particular, retail scanner data (Hoffman & Novak, 1996). As such, it is natural to use a Logit model (Guadagni & Little, 1983). When one tracks individual visitors and the data are disaggregate, each observation is one visitor's data with a 1 (clicked) or 0 (not clicked) for the link(s) in question, one can use Maximum Likelihood. Alternatively, when not tracking individual visitors and analyzing aggregated choice probabilities, one can use either Maximum Likelihood or Weighted Least Squares.
-
Site Depth. Figure 11-2 shows the frequency that visitors to a hospitality business' communication site view one page, two pages, and so forth. In 1997, Dr ze and Zufryden suggested that such data exhibit a Poisson distribution. The next year, Huberman (1998) proposed the inverse Gaussian distribution based on economic considerations, and obtained a good empirical fit with that distribution. More recently, Bucklin and Sismeiro (2003) suggested that the Type II Tobit model is better as it allows for covariates.
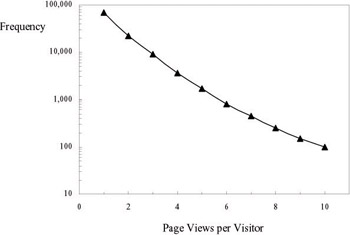
Figure 11-2: Frequency distribution of site depths for a regional hospitality site -
Time on Site. One measures the time on site by calculating the difference between the visitor's first and last page request. This calculation, though, places a lower bound on the visitor's time 'at' the site. Web servers usually do not maintain state. The visitor neither logs in nor logs off the site. The server simply reacts to individual page requests and has no way of recording if the visitor subsequently requested pages from another site, or stared at the last requested page for 20 minutes before turning to another activity.
In other words, such data are subject to right censoring. As such, both Site Depth and Time on Site are amenable to modeling using the above mentioned Type II Tobit model (Bucklin & Sismeiro, 2003). Figure 11-3 shows that like other measures of time, the number of people accessing the site for 'n' minutes drops off rapidly .
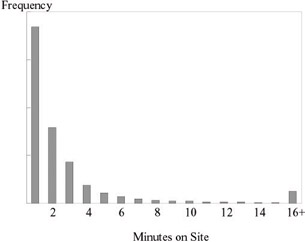
Figure 11-3: Distribution of time on site for a regional hospitality site
EAN: 2147483647
Pages: 164