What Is XML?
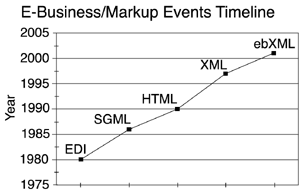
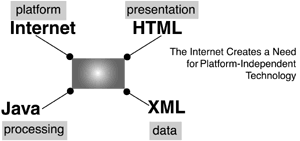
| XML makes possible the entire idea of using the World Wide Web and the Internet for exchanging business messages. XML is a generic markup language, which means that it provides instructions that only define the message or document content, not how that content is displayed or printed. For example, the instructions can say, "This block of text contains a business shipping address." By focusing on the content and detailing the precise business context, XML makes it possible for systems in remote locations to exchange and interpret such documents without human intervention. This ability to automatically send, retrieve, interpret, transform, and process the data in electronic messages is of course critical to the conduct of electronic business itself. The World Wide Web Consortium ( W3C ) developed XML in 1996 “97, and officially released version 1.0 in February 1998.[1] While XML is widely recognized as a technology and the W3C is a highly respected organization, drawing its membership from both major software vendors and academic institutions, the W3C chooses to call its fully approved technical documents recommendations rather than standards, to avoid anti-competitive lawsuits in the U.S. Recommendations represent a consensus within the W3C as well as the approval of the W3C director, now Tim Berners-Lee. As recommendations, documents such as the XML specifications demonstrate stability and are considered ready for widespread implementation and business use.[2] Markup: Seeing Is BelievingThe World Wide Web emerged as a common communications medium once the Hypertext Markup Language (HTML) became available in the early 1990s.[3] HTML is also a recommendation of the W3C (the latest version is 4.01, December 1999), and now there is also an XHTML recommendation (February 2001). HTML provides a good example of a markup language in wide use, and makes a convincing case study for the importance of consistent standards. You can see HTML markup by opening any web page with Internet Explorer or Netscape Communicator. Using the top-level menu in the browser, select View, Source (Internet Explorer) or View, Page Source (Netscape). What you see displayed is the internal HTML syntax that the browser uses to render the page content you see onscreen. The familiar web page with its human-readable text and images are exposed as machine-readable computer markup code. Notice that the code contains a lot of instructions in angle brackets, such as <HTML> , <BODY> , <HEAD> , <TITLE> , <TABLE> , and so on. (See Listing 4.1 for an example.) Enclosing the syntax text within angle brackets creates a tag or element. Close to the top of the web page's HTML markup source is the tag <HTML> . This tag tells the web browser that the page is coded in HTML; the web browser responds by displaying the information as directed by the rest of the tags on the page. At the bottom of the page is a similar tag, </HTML> . The slash after the opening angle bracket in the tag tells the browser that it has reached the end of the HTML page. The <HTML> tag is called an open tag, and the </HTML> tag is a close tag. The markup also contains other tag pairs: <HEAD> and </HEAD> , <TITLE> and </TITLE> , <BODY> and </BODY> . These tags define parts and functions of the HTML document. Listing 4.1 Sample of HTML Markup<HTML> <HEAD> <TITLE>Dynamiks Research Center News Homepage<TITLE> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <meta name="keywords" content="press releases, wind tunnels, aerospace".> </HEAD> <BODY bgcolor="#FFFFFF"> <TABLE width="100%" border="0" cellpadding="0" cellspacing="0"> </TABLE> </BODY> </HTML> The power of HTML is that it's very simple to use, as the HTML software excuses most obvious mistakes by human editors ”unclosed tags, orphaned tags, mistyped tags ”by always displaying something, not just a blank page.This leads to very complex HTML software, but ease of use for content creators . HTML has a fixed set of markup tags and most HTML software readily understands such commonly used tags. Because HTML is a standard more or less recognized by the browser manufacturers,[4] millions of people and companies worldwide have found new and innovative ways of communicating over the web ”and in many cases doing good business ”without worrying about too many technical details. XML takes a different approach, first by allowing its users to create their own tags (hence the extensible part of its name). As a result, XML is highly suited to describing your own particular business data in messages and exchanging those messages with trading partners . Listing 4.2 shows the XML markup of a customer's telephone number, using the XML vocabulary from version 3.0 of the xCBL syntax:[5] Listing 4.2 Sample XML Content for a Supplier Mailing Address<?xml version="1.0" encoding="UTF-8"?> <Supplier> <NameAddress> <Name1>ABC Wholesale</Name1> <Address1>1222 Industrial Park Way </Address1> <City>South San Francisco</City> <StateOrProvince>California</StateOrProvince> <PostalCode codetype="ZIP">96045</PostalCode> <Country>US</Country> </NameAddress> </Supplier> XML elements use start and end tags as in HTML. However, the elements also contain attributes such as codetype within the <PostalCode> tag. Attributes act as qualifiers of the elements, providing more definition or direction to the trading partners exchanging the messages. Attributes are familiar in HTML too, such as the <FONT typeface="italic">I said hello!</FONT> instruction, where italic qualifies the style of presentation font for the text. Similarly, in the case of the XML postal code number shown in Listing 4.2, the attribute tells us that this is a U.S. style numeric-based ZIP code. HTML uses a fixed set of tags for display of text, not for the definition of data. Listing 4.3 shows the same information as in Listing 4.2, but coded in HTML. You may notice another characteristic of XML from this example ”its readability. XML doesn't restrict tag writers to specific string lengths; tags can be labeled to confer hierarchy, context, and meaning. Listing 4.3 HTML Content for a Supplier Mailing Address<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML> <HEAD> <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=iso-8859-1"> <META NAME="Author" CONTENT="Alan Kotok"> <META NAME="GENERATOR" CONTENT="Mozilla/4.06 [en]C-gatewaynet (Win95; I) [Netscape]"> </HEAD> <BODY> <ADDRESS> Supplier name and address:</ADDRESS> <ADDRESS> Name: ABC Wholesale</ADDRESS> <ADDRESS> Address: 1222 Industrial Park Way</ADDRESS> <ADDRESS> City: South San Francisco</ADDRESS> <ADDRESS> State: California</ADDRESS> <ADDRESS> Zip: 96045</ADDRESS> <ADDRESS> County: USA</ADDRESS> <BR> </BODY> </HTML> XML, Where Past Is PrologueA review of XML's background shows some further thinking behind the development of XML, as well as its current readiness as a tool for business. XML is a subset of the Standard Generalized Markup Language ( SGML ), a markup language first conceived in the late 1960s. A committee of the Graphic Communications Association ( GCA ) determined the need for standard page-composition instructions sent from publishers of books and journals to printing plants. Individual printers at the time had their own means of marking up the text with codes that translated into font sizes or effects, such as boldface or italics. They recognized that a standard means of marking up the text would make it possible for any publisher to communicate in the same way with any printer, and save the publishers the headaches of reconciling one form of markup with another. HTML's large set of features was designed to handle the demanding requirements of scientific and technical documentation and went well beyond the needs of people and companies to display text and images or exchange business messages. The GCA committee proposed separating the information content from the presentation format and developing a generic code to represent the format, rather than trying to decipher each printer's specific coding scheme. The generic code would be represented in a set of descriptive tags.The tags would indicate where the information for the heading of the document resided ”identification of the author, date, title, and other general details ”as opposed to the body of the document that contained the intellectual product. By 1969, Charles Goldfarb, then working at IBM, led a research project to build on the GCA committee's ideas for a Generalized Markup Language ( GML ) for text editing and formatting to enable electronic document sharing and retrieval. GCA, working first with the American National Standards Institute ( ANSI ) and then with the International Organization of Standards ( ISO ), moved GML from an IBM proposal into a recognized international standard ”the Standard Generalized Markup Language ( SGML ), ISO 8879, in 1986.[6] Based on this standard, the U. S. Department of Defense, the Internal Revenue Service, and other such organizations with large numbers of complex documents were able to invest in systems to help them manage their electronic publishing operations. The European Particle Physics Laboratory in Geneva (which uses the organization's original French acronym, CERN ) became another major user of SGML. While on staff at CERN, Tim Berners-Lee developed HTML as an application of SGML in the late 1980s and early 1990s.[7] The development of SGML predated the emergence of the Internet, at least as we know it in the year 2001. What attracted Berners-Lee and many of the other web pioneers to the Internet was its decentralized nature and a design that allowed any kind of computing platform to plug in, as long as it complied with the Net's protocols. The public availability of the Internet created the potential for anyone to exchange such marked -up documents with ease.[8] HTML transformed the Internet from islands of hard-to-find content into one homogeneous whole that's visible through a web browser interface. Meanwhile, companies, agencies, and organizations with large electronic publishing operations ”usually technical, scientific, engineering, financial, or legal ” found SGML useful in managing their documents and re-purposing the content in those documents. Because of its nurturing in the publishing world, however, SGML contains complexity that the average user finds intractable. Its large set of features was designed to handle the demanding requirements of scientific and technical documentation and went well beyond the needs of people and companies to display text and images or exchange business messages.[9] Figure 4.1 shows the timeline for development of XML and the other main markup languages, as well as EDI and ebXML. The development of the web-based markup languages, both HTML and XML, came about in part to provide an alternative to the highly complex and feature-rich SGML. With HTML, the ability to write web pages with simple and inexpensive tools (free, in many cases) makes everyone with a web connection a potential publisher. Figure 4.1. Evolution of markup technologies. And the numbers seem to point out that the world has responded accordingly . According to Whois.Net, more than 32 million domain names with .com , .net , or .org extensions were registered as of November 2000, and NetCraft's domain search engine lists nearly 1,000 domains with XML somewhere in the name.[10] While HTML offered an effective way of presenting images, text, and multimedia content on the Internet, it still didn't meet many of the critical needs of business information dissemination . HTML has a fixed set of tags. While easy to learn, it's too generalized, and in particular doesn't provide any means to interpret the context of the information within a web page. XML aimed to bridge the gap. Figure 4.2 shows how the needs can be viewed as four interrelated technologies: the Internet delivering content, HTML presenting it, XML identifying the data content, and Java and similar programming tools providing the process control. Figure 4.2. The role of XML: the four-legs-of-the-table metaphor. Having identified the need, the World Wide Web Consortium committee convened in 1996, and, led by Jon Bosak of Sun Microsystems and Tim Bray of Textuality, designed XML for electronic publishing. The group focused on creating a simpler form of markup to overcome the obstacles to broad adoption shown by SGML. They therefore set 10 design objectives for the new language:
XML Validation and ParsingAn XML document by itself is just arbitrary text. To describe the actual rules to be followed in creating your particular type of XML content, you need an additional mechanism. One of the features of SGML that carried over into XML version 1.0 is the concept of a schema, which describes the layout of a document, also known as the Document Type Definition ( DTD ). The role of both schemas and DTDs is to allow the author to define the structure permitted for any given XML document, including the relationships among elements in the document.Think of schemas or DTDs like the instructions that come with a Lego bricks model for assembling the pieces in the correct order. The terms schema and DTD are often used interchangeably, but they have specific meanings. A schema is a generic term for document or data structures with a predetermined set of rules. A DTD is one type of schema, specified in SGML and XML 1.0. The DTD also provides a way of testing the structure of a document against the prescribed structure in the DTD, a process called validation. This validation step, designed as a quality check for documents, also can be used to check the structure of business messages sent using XML. The combination of its extensibility, structure, and validation makes XML useful not only for electronic publishing but for business messages sent between companies. The XML schema or DTD therefore performs two roles. It acts as a blueprint to allow someone who has no prior knowledge of your particular XML to create that content. It also allows software to check content to make sure it is correctly structured. But XML allows for sending documents without such validation being required. The XML creators allowed for XML documents that are correctly tagged, but that don't have a schema DTD, and thus can't be tested for any structural validity. These documents are referred to as well- formed documents, indicating that they meet the basic XML markup syntax rules. A valid XML document is both well-formed and meets the additional requirements of the schema DTD.[12] Again, the Lego model is instructive; if you lose the printed directions, you can probably still build an interesting model, but you won't know if it exactly matches the original design. The combination of its extensibility, structure, and validation makes XML useful not only for electronic publishing but for business messages sent between companies. The ability to define the elements exchanged between companies and the structure of the elements means that trading partners can define messages in advance and thus process the messages automatically on receipt. Having validation means that trading partners can test the messages against the associated schema DTD, and thus provide a form of quality assurance. To validate an XML message with a DTD, the message needs to be read and interpreted, in a process called parsing. A software component called a parser reads the XML message and interprets the XML tags it finds. A validating parser tests the message against the predefined rules of the schema DTD and then reports any errors. To help provide software programmers using parsers with a standard connection between the message and the parser, the W3C developed the Document Object Model ( DOM ), independent of software languages or computing platforms.[13] XML documents have a nested structure that resembles a tree with a trunk and branches. The DOM represents the XML message as an inverted hierarchical tree, starting with the root element and branching out from there. By defining this logical structure in a common application program method, parsers and other software packages can manipulate messages consistently. Software developers call this kind of tool an Application Program Interface ( API ). Microsoft's web browser, Internet Explorer (IE), displays XML documents using the DOM. If you open a well-formed XML document with IE 5.0 or higher, you'll see the document hierarchy clearly portrayed.The W3C approved Level 1 of the DOM in 1998, but had some enhancements approved as of November 2000.[14] Under the hood, IE 5.0 provides an automatic visual display of an XML document with another technology called the Extensible Stylesheet Language ( XSL ), and a default stylesheet. One limitation of the DOM approach is that the whole XML document must be stored in memory at the same time. Obviously, this doesn't work for high transaction-volume or large- sized business information flows. In a process befitting the free and open nature of the Internet, members of the XML Developers mailing list (XML-DEV) developed an event-based programming interface called Simple API for XML (SAX), while waiting for the W3C to finish work on the more complex DOM specifications. SAX therefore allows programmers to process just fragments of XML content at high speed.[15] Therefore, SAX is an event-based rather than a tree-based API. The event-based approach looks for tags and content meeting some conditional criteria that identifies the fragment within the overall information stream.The SAX API then passes that fragment to a custom event handler (software program) that the programmer has defined. SAX lets systems access and query only those parts of XML documents without loading them entirely into memory, thus working faster and more efficiently . All the major vendors providing XML parser implementations support SAX.[16] XML's Global Reach and AccessibilityAlthough XML is a creation of the W3C, companies don't need the web to send and receive XML messages. XML's first design objective makes XML straightforwardly usable over the Internet, not just the web. As a result, trading partners can exchange documents with email messages or File Transfer Protocol ( FTP ) downloads, as well as over the web. With XML, the means of transporting the messages is independent of the message content. We often take the ASCII-English alphabet codeset for granted, but we forget that most of the world uses alphabets and characters not based on simple Latin (Roman) characters . XML Works with Non “English Character SetsSince the Internet made the information technology business truly a worldwide endeavor, the designers of XML added an important XML feature, namely the ability to support non “English character sets. In North America and Western Europe, we often take the ASCII-English alphabet codeset for granted, but we forget that most of the world uses alphabets and characters not based on simple Latin (Roman) characters. XML supports the Unicode standard, a system for representing text characters for computer processing of all the known 50,000 written languages on the planet. The latest version of Unicode (3.0) matches up to the international standard for character sets, ISO/IEC 10646-1:2000. It uses pairs of two bytes or 16 bits to represent characters, which allows for encoding most of the world's known character sets, including scientific and mathematical symbols. As a result, Unicode provides codes for more than 65,000 characters.[17] With the worldwide nature of business today, this ability to represent non “English characters has become vital for many businesses.[18] Fortunately, the design of XML is backwardly compatible with today's ASCII 8-bit encoding, so regular ASCII editors and tools work just fine handling and creating what are labeled as "UTF-8 encoded" XML documents. XML Works with JavaWhile the development of the Java[19] programming language preceded the development of XML, the two technologies now complement each other. Java is a high-level language used extensively in distributed applications over the web. Sun Microsystems developed Java to run on any computing platform. Programs written in Java are first compiled into an intermediate form called bytecodes ”machine codes that are interpretable on most computing platforms.[20] In 1997, Jon Bosak of Sun Microsystems, one of the creators of XML, wrote a white paper describing ways that the two technologies could work together. Bosak pointed out that "XML gives Java something to do." He described potential applications of XML in which the processing is distributed among client and server sites rather than centralized in a single server, using Java applets. For example, a design engineer could download XML data from a manufacturer's web site, and then use distributed Java code to try the circuits in various configurations.[21] Matthew Fuchs notes several affinities between XML and Java that make them a productive partnership. Java uses a simple and predictable package structure that follows the structure of a typical Windows or UNIX filesystem. As a result, when sharing data with XML documents, programmers can easily route the data to the correct location thanks to this property of Java. Another feature of Java loads code dynamically at runtime, which allows for applets ”pieces of Java code that browsers can download and run locally rather than relying on a full program at a remote site. This ability allows applets to run code that can process XML documents locally at much higher speeds and with much less overhead. XML supports the use of style sheets that contain the instructions for presenting data on screens, in print and in audio formats. Style sheets provide the formatting details for visual display or printing, such as page size , margins, and fonts. Fuchs also names Java Beans technology as an innovation that works well with XML. Java Beans are a set of application program interfaces that work as components with other software.[22] XML Works with Style SheetsEarly in this chapter we discussed how markup languages such as XML separate content from its presentation format. Since business-to-business exchanges involve sending data from one computer to another, they don't require a human-readable version at either end of the exchange. But many business processes need to present the exchanged data in some human-readable presentation form. XML supports the use of style sheets that contain the instructions for presenting data on screens, in print, and in audio formats.[23] Style sheets provide the formatting details for visual display or printing, such as page size, margins, and fonts.They are used frequently in word processing (but often called templates ); for example, many organizations have a standard fax cover page template. Style sheets have important business uses and do much more than just make data look pretty. For example, documents formatted for North American customers generally need to be printed on standard letter-size pages (8 1/2 inches by 11 inches), while other parts of the world commonly use the A4 size (210 x 297 mm). While HTML by itself offers some ways to present text and images on a web page, its features are limited and don't provide enough power or flexibility for professional print content designers. Another problem with HTML is consistency and reuse. This problem has been addressed in advanced word processing products by the use of styles ; the user can apply a paragraph style, a table of contents style, an indented list style, and so on. HTML also has a need to use consistent style of text display size, font, and layout. HTML needs a separate style system, called Cascading Style Sheets ( CSS ), to display web page content. CSS can also be used to display XML content in the same way.[24] The method CSS uses is very simple, but requires that the content of the XML already be structured in a way that matches the output layout. The W3C has developed an even more powerful style sheet for XML documents, called the Extensible Style Sheet Language (XSL), that gets around the restrictions of CSS and has two sets of core features:
The transformation features of XSL give it extra power over CSS. With XSL, you can add or remove elements from an XML file, rearrange the elements, and make decisions about the display of the elements.[25] Figure 4.3 shows an example of XSL stylesheets displaying XML data on an HTML page. Figure 4.3. How a style sheet works to display XML as HTML. The next need is to locate information consistently within an XML document. What if you need the second occurrence of Address , not the first? Associated with XSL Transformations ( XSLT ) is the XML Path Language, also called Xpath, which permits the location of any part of the tree branch path of an XML document hierarchy to be specified. Figure 4.3 gives an example of this capability, to find and select Database/People/Person. A transformation using XSLT needs to address specific components in an XML document, and Xpath provides that ability. It works like a pair of programming tweezers to find and return the exact piece of an XML document desired. XSLT can also change the hierarchical structure of an XML document using a set of predefined XSLT syntax rules that dynamically inspect and traverse the document structure.[26][27][28] Using either CSS or XSL style sheet references with an XML document provides a way to visually display XML content to end users, or to morph XML documents for input processing by business application software.[29] |

EAN: 2147483647
Pages: 100