2.5 Step-by-Step Approach for Creating an MPEG-7 Document
|
| < Day Day Up > |
|
2.5 Step-by-Step Approach for Creating an MPEG-7 Document
This section gives a step-by-step methodology for creating an MPEG-7 document based on a practical application scenario. It covers important parts of the Multimedia Content Description Interface (Part 5 [MDS] and Part 3 [Visual]). It is not intended to cover the complete spectrum of the Multi-media Content Description Interface, which would detract the reader's attention from the practical aspect of the step-by-step approach. This approach is also helpful for creating a document relying on parts of the description interface not covered here.
The complete DDL for the Multimedia Content Description Interface may be found at http://m7itb.nist.gov/M7Validation.html (without any conceptual model). Conceptual models for most of the descriptors may be found in the MPEG-7 overview by Martínez; [7] however, without an explanation on how to create an MPEG-7 document or the DDLs. Manjunath et al.'s [8] book on MPEG-7 describes the first six parts of MPEG-7 in a comprehensive way and gives examples. In addition to these documents, we give a practical guide for the creation of MPEG-7 descriptions containing structural and visual descriptors and semantics of image and video data. The complete International Standard MPEG-7 may be found in the ISO-IEC 15938-1-8. These documents may be obtained from ISO or from a national body.
2.5.1 Example Scenario
The example scenario is the description of the content structure of a given video. It shall specify the video segments and specify for each segment its color distribution. These low-level descriptions may be used for content-based querying. Moreover, for each segment, we like to retain and describe a key frame that enables browsing functionality. Finally, the semantics of the video segment shall be described using entities such as objects, events, concepts, states, places, and time. This allows the user to search videos on the basis of their semantic content.
The sample MPEG-1 video contains two shots from a tourist video of Pisa. The first shot scans the Pisa Leaning Tower from top to bottom, and the second one shows the palazzo besides the leaning tower. The key frames for the two shots as well as the last frame in the video are displayed in Exhibit 2.7. For a better visualization of the complete video content, Exhibit 2.7 also presents the mosaic panorama of the video, which is a very useful representation of the video.
Exhibit 2.7: Top: Key frames of the two shots and final frame (to the right); Bottom: Mosaic image of the video.

Note that we used an in-house built segmentation tool for the segmentation of the video and for describing the visual features of the segments. Information on the video such as semantics and classification had to be added manually, because there is as of yet no support for automatic annotation. General information for supporting annotation tools may be found in Section 2.9.
2.5.2 Choosing the MPEG-7 Root Element
The first decision when writing an MPEG-7 document is to choose the appropriate root element: creating either a complete description or a description unit. A complete description is useful if one desires to describe multimedia content using the top-level types. For example, the description of an image is a complete description. A description unit is useful if one desires to describe an instance of a D or a DS. A description unit can be used to represent partial information from a complete description. For example, the description of the shape or color of an image is a description unit. In our example, we want to describe a complete video; thus, we use a complete description.
The choice between a complete description and a description unit is shown in the DDL of the root element Mpeg7. If a complete description is chosen, the element Description has to be used; for a description unit, the element DescriptionUnit has to be selected.
<! - Definition of Mpeg7 root element - > <element name="Mpeg7"> <complexType> <complexContent> <extension base="mpeg7:Mpeg7Type"> <choice> <element name="DescriptionUnit" type="mpeg7: Mpeg7BaseType"/> <element name="Description" type="mpeg7: CompleteDescriptionType" minOccurs="1" maxOccurs="unbounded"/> </choice> </extension> </complexContent> </complexType> </element>
2.5.3 Choosing the MPEG-7 Top-Level Type
The following top-level types are used in complete descriptions to describe multimedia content and metadata related to content management. Each top-level type contains the description tools that are relevant for a particular description task, that is, for describing an image or a video.
-
ContentDescriptionType (abstract): top-level type for complete description of multimedia content
ContentEntityType: top-level type for describing multimedia content entities such as images, videos, audio, collections, and so forth
ContentAbstractionType (abstract): top-level type for describing abstractions of multimedia content
-
SemanticDescriptionType: top-level type for describing semantics of multimedia content
-
ModelDescriptionType: top-level type for describing models of multimedia content
-
SummaryDescriptionType: top-level type for describing summaries of multimedia content
-
ViewDescriptionType: top-level type for describing views and view decompositions of AV signals
-
VariationDescriptionType: top-level type for describing variations of multimedia content
-
-
ContentManagementType (abstract): top-level type for describing metadata related to content management
UserDescriptionType: top-level type for describing a user of a multimedia system
CreationDescriptionType: top-level type for describing the process of creating multimedia content
UsageDescriptionType: top-level type for describing the usage of multimedia content
ClassificationDescriptionType: top-level type for describing a classification scheme for multimedia content
The top-level types are organized under the type hierarchy shown in Exhibit 2.8 (note that not all concrete subtypes are shown, but typical examples are given). The CompleteDescriptionType forms the root base type of the hierarchy. The top-level types ContentDescriptionType and ContentManagementType extend CompleteDescriptionType. Similarly, the top-level types ContentEntityType and ContentAbstractionType extend ContentDescriptionType. ContentEntityType aggregates elements of type MultimediaContentType, which is the super type of VideoType, AudioType, ImageType, and so forth.
Exhibit 2.8: Illustration of the type derivation hierarchy for top-level types.
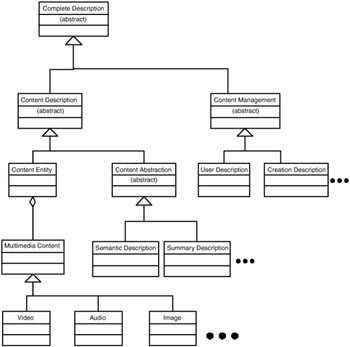
In our running example, we want to describe the complete structure and the semantics content of a video. There are two alternative ways in doing this. We may use the ContentEntityType or the ContentAbstractionType. In the first case, the semantics is embedded into the structural content descriptions of the ContentEntityType, in the other case the structural information of the video is embedded into the ContentAbstractionType. The decision of which way to take down in the type derivation hierarchy depends on the importance of the structural and semantics description part in the complete description. In our example, the structure is the anchor for our description, and we therefore rely on the ContentEntityType.
With this choice, let us create the following frame for our MPEG-7 document:
<Mpeg7> <Description xsi:type="ContentEntityType"> ... </Description> </Mpeg7>
Note that there is no element of type ContentDescriptionType specified in the document. ContentEntityType is introduced by "casting" the Content-DescriptionType of Description to the appropriate subtype ContentEntityType. This type is defined in the following DDL part:
<! - Definition of ContentEntity Top-level Type - > <complexType name="ContentEntityType"> <complexContent> <extension base="mpeg7:ContentDescriptionType"> <sequence> <element name="MultimediaContent" type="mpeg7: MultimediaContentType" minOccurs="1" maxOccurs="unbounded"/> </sequence> </extension> </complexContent> </complexType>
Now we have to select what AV content to describe. Following the type hierarchy shown in Exhibit 2.8, we select Video. To introduce the VideoType, we again have again to use the xsi:type mechanism, this time for MultimediaContent (as shown in the former DDL). Hence the frame for our MPEG-7 document becomes
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="VideoType"> ... </MultimediaContent> </Description> </Mpeg7>
The complex type VideoType defines the element Video for further detailing the video content. Note that Video is of type VideoSegmentType that is a subtype of SegmentType.
<! - Definition of Video Content Entity - > <complexType name="VideoType"> <complexContent> <extension base="mpeg7:MultimediaContentType"> <sequence> <element name="Video"type="mpeg7: VideoSegmentType"/> </sequence> </extension> </complexContent> </complexType>
2.5.4 Detailed Description of the Content with the SegmentType and Its Subtypes (Video, Audio, etc.)
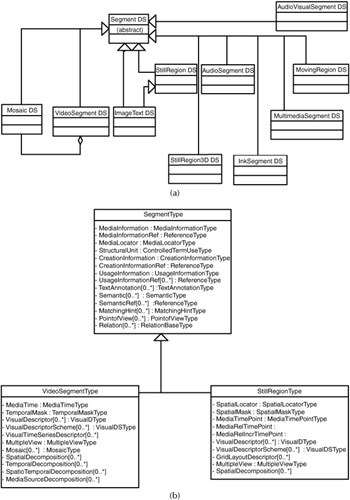
The SegmentType is the root type for describing the characteristics of segments, such as creation information, media information, usage information, semantic information, text annotation, matching hints, point of view descriptions, and so forth. From the SegmentType derives the special descriptions for the different media. Exhibit 2.9a shows the principal subentities of Segment DS that are available in MPEG-7 for different media.
In our example we are interested in describing the video and its key frames, which leads to the VideoSegment DS and the StillRegion DS. To employ useful descriptions there, the elements of the main type, the SegmentType have to be studied first and then the VideoSegmentType for the video and the StillRegionType for the key frames is introduced.
Exhibit 2.9b gives an overview of the elements (and their cardinalities), which the SegmentType, VideoSegmentType, and StillRegionType provide.
2.5.5 SegmentType
The SegmentType supplies rich description elements for describing the structural media content. We shortly describe the purpose of the important elements and then point to the subsequent sections for further details.
<! - Definition of Segment DS - > <complexType name="SegmentType" abstract="true"> <complexContent> <extension base="mpeg7:DSType"> <sequence> <choice minOccurs="0"> <element name="MediaInformation" type= "mpeg7: MediaInformationType"/> <element name="MediaInformationRef" type= "mpeg7:ReferenceType"/> <element name="MediaLocator" type="mpeg7: MediaLocatorType"/> </choice> ... other elements detailed below
The first element to be specified is either a MediaInformation or a MediaLocator. The MediaLocator contains simple information about the location of the media, whereas the MediaInformation may unfold exact information on the property of each frame in the video, including location information of the video. Section 2.5.1 details the usage of the MediaInformation and MediaLocator.
Exhibit 2.9: (a) Principal subclasses of the segment description schemes for describing multimedia content; (b) subtypes of the SegmentType and their elements.
Note that the MediaInformation may be obtained either directly by using the element MediaInformation or by reference mechanism through the element MediaInformationRef of type ReferenceType. This distinction between direct inclusion of descriptions or referencing is drawn through the complete framework of MPEG-7, where complex descriptions are employed.
<element name="StructuralUnit" type="mpeg7:ControlledTermUseType" minOccurs="0"/>
The next element is the StructuralUnit. It describes the role of the segment in the context of the multimedia content. Examples of values of a StructuralUnit include "story," "scene," and "shot." The values may depend on the particular form of the multimedia content; for example, a movie or daily news report.
The type of this element is ControlledTermUseType, which may have an attribute of mpeg7:termReferenceType referring to a term in a Classification Schema. This term allows us to characterize the content as daily news report with the standardized term urn:mpeg:mpeg7:cs:GenreCS:2001:1.3.1. A Classification Schema is an important feature of MPEG-7 allowing using terms in a standardized way (see also Section 2.6).
The next element describes the creation information related to the actual segment. It may be specified directly or by reference. The CreationInformation DS contains the following information:
<choice minOccurs="0"> <element name="CreationInformation" type="mpeg7: CreationInformationType"/> <element name="CreationInformationRef" type="mpeg7: ReferenceType"/> </choice>
-
Creation and production information: Information about the creation and production of the content not perceived in the content, such as author, director, characters, target audience, and so forth, and information about the creation process that may be perceived in the content, such as actors in a video, players in a concert, and so forth.
-
Classification information: information related to the classification of the content, such as target audience, style, genre, rating, and so forth.
Section 2.5.2 details this description scheme.
The other important element is the usage information related to this segment. It is a well-structured and comprehensive description scheme that may be understood from the schema definition. Once again, it may be detailed directly or by reference. Briefly, the principal components are
-
Rights information: information about the rights for using the multimedia content
-
Usage information: information about the ways and means to use the multimedia content (e.g., edition, emission, and so forth) and the results of the usage (e.g., audience)
-
Financial information: information about the financial results of the production (in the FinancialResults D within the UsageInformation DS) and of the publication (in the Financial D within each Availability DS and UsageRecord DS) of the multimedia content
<choice minOccurs="0"> <element name="UsageInformation" type="mpeg7: UsageInformationType"/> <element name="UsageInformationRef" type="mpeg7: ReferenceType"/> </choice>
The next child element is TextAnnotation. It is an important element for characterizing the content using (structured) free-text and keyword annotation. Note that only a minimum of a type concept is supplied with this annotation mechanism. For the description of semantic entities involved in a scene, the semantics tools of MPEG-7, as indicated in the next element, have to be used.
<element name="TextAnnotation" minOccurs="0" maxOccurs="unbounded"> <complexType> <complexContent> <extension base="mpeg7:TextAnnotationType"> <attribute name="type" use="optional"> <simpleType> <union memberTypes="mpeg7: termReferenceType string"/> </simpleType> </attribute> </extension> </complexContent> </complexType> </element>
The element TextAnnotation is a complex type that extends the TextAnnotationType and adds an attribute type that indicates the type or purpose of the textual annotation (optional). It is defined as follows:
<complexType name="TextAnnotationType"> <choice minOccurs="1" maxOccurs="unbounded"> <element name="FreeTextAnnotation" type="mpeg7: TextualType"/> <element name="StructuredAnnotation" type="mpeg7: StructuredAnnotationType"/> <element name="DependencyStructure" type="mpeg7: DependencyStructureType"/> <element name="KeywordAnnotation" type="mpeg7: KeywordAnnotationType"/> </choice> <attribute name="relevance" type="mpeg7: zeroToOneType" use="optional"/> <attribute name="confidence" type="mpeg7: zeroToOneType" use="optional"/> <attribute ref="xml:lang"/> </complexType>
Thus, we may employ the following means for annotating a text:
-
FreeTextAnnotation: describes a free text annotation;
-
StructuredAnnotation: describes a thematically structured annotation;
-
DependencyStructure: describes a textual annotation with a syntactic parse-tree based on dependency structures;
-
KeywordAnnotation: describes a keyword annotation.
The FreeTextAnnotation is the simplest annotation and is, therefore, frequently used. To introduce the minimum structure, one may use the other three variations; for instance, the structured annotation that supplies the following structuring frame (note that the content is not typed, but the structure):
-
Who: describes animate objects or beings (people and animals) or legal persons (organizations and person groups) using free text.
-
WhatObject: describes inanimate objects using free text.
-
WhatAction: describes actions using free text.
-
Where: describes a place using free text.
-
When: describes a time using free text.
-
Why: describes a purpose or reason using free text.
-
How: describes a manner using free text.
The following XML fragment shows a simple example of the FreeTextAnnotation and the StructuredAnnotation:
<TextAnnotation> <FreeTextAnnotation xml:lang="en"> This video shows the Leaning Tower in Pisa. </FreeTextAnnotation> <StructuredAnnotation> <WhatObject> <Name xml:lang="en"> Leaning Tower </Name> </WhatObject> <WhatAction> <Name xml:lang="en"> Visit of the Tower </Name> </WhatAction> </StructuredAnnotation> </TextAnnotation>
The Semantic element describes the semantics of the scene depicted in the segment with the help of semantic entities, like persons, events, objects, concepts, and their relationships (optional). The SemanticType is defined in Section 2.5.3. Again, one may use the direct inclusion or the reference mechanisms for the specification of the semantics.
<choice minOccurs="0" maxOccurs="unbounded"> <element name="Semantic" type="mpeg7:SemanticType"/> <element name="SemanticRef" type="mpeg7: ReferenceType"/> </choice>
The MatchingHint element describes the relative importance of instances of description tools in the segment DS (or parts of instances of description tools) for matching segments (optional). A segment description can include multiple MatchingHints to describe multiple matching criteria or different combinations of descriptors. An example is given below.
The PointOfView element describes the relative importance of the segment given a specific point of view (optional). Finally, the Relation element describes a relation that the segment participates in (optional). Those elements lead to more or less complicated description schemes and are not detailed here; their conceptual model may be found in the MPEG-7 overview by Martínez. [9]
<element name="MatchingHint" type="mpeg7: MatchingHintType" minOccurs="0" maxOccurs="unbounded"/> <element name="PointOfView" type="mpeg7: PointOfViewType" minOccurs="0" maxOccurs="unbounded"/> <element name="Relation" type="mpeg7:RelationType" minOccurs="0" maxOccurs="unbounded"/>
The MatchingHint may specify a subjective reliability factor of the hint values defined. The relationship of the hint to the description elements, the relative importance of which is described, is done via xpath expressions. A simple example (assuming that we may choose among different low-level color descriptors):
<MatchingHint reliability="0.8"> <Hint value="0.5" xpath=.."/../../ColorStructure"/> <Hint value="0.6" xpath=.."/../../DominantColor"/> <Hint value="0.7" xpath=.."/../../ColorLayout"/> </MatchingHint>
The SegmentType is an abstract type, and its elements may occur in an instance document only in connection with one of its subtypes. The example scenario comprises the description of video contents and its keyframes, so the types VideoSegmentType and StillRegionType are described now.
2.5.6 VideoSegmentType
The subtypes of the SegmentType describe specific media content; the VideoSegmentType is now specific to videos. It naturally extends the SegmentType:
<! - Definition of VideoSegment DS - > <complexType name="VideoSegmentType"> <complexContent> <extension base="mpeg7:SegmentType"> ...other elements detailed below
The first element of the VideoSegment is the MediaTime element. It is used as a temporal locator to describe a temporally connected subinterval by specifying the start time and the duration of the video segment. It may be visualized as putting a frame (box) on the video aligned in the timeline. Section 2.5.1 gives an example. If the segment cannot be described as a single connected interval; that is, it is composed of several disconnected intervals, then the TemporalMask has to be used.
<choice minOccurs="0"> <element name="MediaTime" type="mpeg7: MediaTimeType"/> <element name="TemporalMask" type="mpeg7: TemporalMaskType"/> </choice>
The following example shows how a temporal interval consisting of two subintervals (the first being 0 to 3 seconds, and the second being 3 to 8 seconds) may be laid over the first video segment of our video (0 to 8 seconds):
<TemporalMask> <SubInterval> <MediaTimePoint>T00:00:00</MediaTimePoint> <MediaDuration>PT0M3S</MediaDuration> </SubInterval> <SubInterval> <MediaTimePoint>T00:00:03</MediaTimePoint> <MediaDuration>PT0M5S</MediaDuration> </SubInterval> </TemporalMask>
The next child elements describe the visual features of the video segment. They are of type VisualDType or VisualDSType and may be attributed to a single frame or a sequence of frames. Typical features include color disribution, texture, and shape.
The color descriptors available as subtypes from the VisualDType are detailed in Section 2.5.4. Precise details of all VisualDescriptorType subtypes can be found in the Visual Specification, ISO-IEC 15938-3. An overview is given (without DDL) by Sikora. [10] The additional reference, VisualTimeSeriesDescriptor, describes a temporal sequence of visual features in the video segment and is derived from the basic VisusalDescriptorTypes.
<choice minOccurs="0" maxOccurs="unbounded"> <element name="VisualDescriptor" type="mpeg7: VisualDType"/> <element name="VisualDescriptionScheme" type="mpeg7: VisualDSType"/> <element name="VisualTimeSeriesDescriptor" type= "mpeg7:VisualTimeSeriesType"/> </choice>
The MultipleView element describes visual features of a three-dimensional moving physical object depicted in the video segment as seen from one or more viewing positions or angles. The Mosaic element describes the panoramic view of a video segment (see Exhibit 2.7 for a Mosaic of the whole Pisa video).
<element name="MultipleView" type="mpeg7: MultipleViewType" minOccurs="0"/> <element name="Mosaic" type="mpeg7:MosaicType" minOccurs="0" maxOccurs="unbounded"/>
The video segment decomposition tools, as shown below, describe the decomposition of a video segment into one or more subsegments in space, time, and media source. They all extend the SegmentDecompositionType. These tools are detailed in Section 2.5.5.
<choice minOccurs="0" maxOccurs="unbounded"> <element name="SpatialDecomposition" type="mpeg7: VideoSegmentSpatialDecompositionType"/> <element name="TemporalDecomposition" type="mpeg7: VideoSegmentTemporalDecompositionType"/> <element name="SpatioTemporalDecomposition" type= "mpeg7:VideoSegmentSpatioTemporal Decomposition Type"/> <element name="MediaSourceDecomposition" type="mpeg7: VideoSegmentMediaSourceDecompositionType"/> </choice>
2.5.7 StillRegionType
The StillRegionType is used for the descriptions of describes an image or a two-dimensional spatial region of an image or a video frame. StillRegion3DType has to be used for three-dimensional images and differs from the StillRegionType only in the way the decomposition is specified. For the description of the key frames within a VideoSegment, we will use the StillRegionType.
First of all, the StillRegionType extends the SegmentType:
<complexType name="StillRegionType"> <complexContent> <extension base="mpeg7:SegmentType"> ...other elements detailed below
Then we may lay a SpatialLocator or a SpatialMask over the image to detail regions of interest:
<choice minOccurs="0"> <element name="SpatialLocator" type="mpeg7:R egionLocatorType"/> <element name="SpatialMask" type="mpeg7:S patialMaskType"/> </choice>
SpatialMasks have to be defined in terms of polygon points describing the subregion's boundary. For instance, a two-dimensional image with two disconnected subregions, identified by five polygon points:
<SpatialMask> <SubRegion> <Polygon> <Coords mpeg7:dim="2 5"> 10 15...</Coords> </Polygon> </SubRegion> <SubRegion> <Polygon> <Coords mpeg7:dim="2 5"> 20 30... </Coords> </Polygon> </SubRegion> </SpatialMask>
As an alternative to a SpatialLocator or Mask, we may specify that the StillRegion to be described is part of a video by using the MediaTime elements as follows (this feature is useful for specifying the key frame of a VideoSegment):
<choice minOccurs="0"> <element name="MediaTimePoint" type="mpeg7: mediaTimePointType"/> <element name="MediaRelTimePoint" type="mpeg7: MediaRelTimePointType"/> <element name="MediaRelIncrTimePoint" type="mpeg7: MediaRelIncrTimePointType"/> </choice>
It follows the VisualDescriptors in the same way as for a VideoSegement. The reader is referred to Section 2.5.4 for more details.
<choice minOccurs="0" maxOccurs="unbounded"> <element name="VisualDescriptor" type="mpeg7: VisualDType"/> <element name="VisualDescriptionScheme" type="mpeg7: VisualDSType"/> <element name="GridLayoutDescriptors" type="mpeg7: GridLayoutType"/> </choice>
Finally, we have first the MultipleView element
<element name="MultipleView" type="mpeg7: MultipleViewType" minOccurs="0"/>
and then the specificiation of the StillRegion's subregions. The decomposition tools are detailed in Section 2.5.5.
<element name="SpatialDecomposition" type="mpeg7: StillRegionSpatialDecompositionType" minOccurs="0" maxOccurs="unbounded"/>
2.5.8 Media Description Tools
The description of the media involves a single top-level element, the MediaInformation DS. It is composed of an optional MediaIdentification D and one or several MediaProfile Ds. The MediaInformation DS is a highly structured description tool to reflect the description possibilities of the media in forms of profiles, formats, and so forth. Most of the proposed descriptors are straightforward in their meaning, and therefore, no DDL is given here. Instead, we briefly review the different components available and give a complete MediaInformation of the sample pisa.mpg video.
The MediaIdentification D contains description tools that are specific to the identification of the AV content, independent of the different available instances.
The MediaProfile D contains different description tools that allow the description of one profile of the media AV content being described. The MediaProfile D is composed of
-
MediaFormat D, which contains description tools that are specific to the coding format of the media profile.
-
MediaInstance D, which contains the description tools that identify and locate the media instances available for a media profile.
-
MediaTranscodingHints D, which contains description tools that specify transcoding hints of the media being described. The purpose of this D is to improve quality and reduce complexity for transcoding applications. The transcoding hints can be used in video transcoding and motion estimation architectures to reduce the computational complexity. This D may be used in connection with MPEG-21 Digital Item Adaptation descriptions, as introduced in Chapter 3.
-
MediaQuality D represents quality rating information of audio or visual content. It can be used to represent both subjective quality ratings and objective quality ratings.
A possible description of media information of our MPEG-1 video pisa.mpg is given below. Note that it does not yet contain the segmentation information to keep the document more readable.
The video is 10 seconds plus 13 frames long (which corresponds to 13/25ths of a second, as the frame rate is 25 frames/second; PT0H0M10S13N25F), its resolution is 240 × 320, the file size is 947.361 bytes, the frame rate is 25 Hz, the file format is MPEG-1 (CS term used urn:mpeg:mpeg7:cs:FileFormatCS:2001:3), the visual coding format is the MPEG-1 video coding format (CS term used urn:mpeg:mpeg7:cs:VisualCodingFormatCS:2001:1), and the colorDomain is used.
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="VideoType"> <Video> <MediaInformation> <MediaIdentification> <EntityIdentifier organization="MPEG" type="MPEG7ContentSetId">pisa1 </EntityIdentifier> </MediaIdentification> <MediaProfile> <MediaFormat> <Content href="MPEG7ContentCS"> <Name>visual</Name> </Content> <FileFormat href="urn:mpeg:mpeg7:cs: FileFormatCS:2001:3"> <Name>mpg</Name> </FileFormat> <FileSize>947631</FileSize> <VisualCoding> <Format href="urn:mpeg:mpeg7:cs: VisualCodingFormatCS:2001:1" colorDomain="color"/> <Frame height="240" rate="25" width="320"/> </VisualCoding> </MediaFormat> <MediaInstance > <InstanceIdentifier organization="MPEG" type="MPEG7ContentSetOnLineId"> mpeg7/mpeg/ </InstanceIdentifier> <MediaLocator> <MediaUri>pisa.mpg</MediaUri> </MediaLocator> </MediaInstance> </MediaProfile> </MediaInformation> <MediaTime> <MediaTimePoint>T00:00:00</MediaTimePoint> <MediaDuration>PT0H0M10S13N25F </MediaDuration> </MediaTime> </Video> </MultimediaContent> </Description> </Mpeg7>
2.5.9 Creation and Production Tools
The creation and production description tools describe author-generated information about the generation and production process of the AV content. This information can usually not be extracted from the content itself. It is related to the material, but is not explicitly included in the actual content.
The description of the creation and production information has, as a top-level element, the CreationInformation DS, which is composed of one required Creation D, one optional Classification D, and several optional RelatedMaterial Ds; see the following DDL:
<! - Definition of CreationInformation DS - > <complexType name="CreationInformationType"> <complexContent> <extension base="mpeg7:DSType"> <sequence> <element name="Creation" type="mpeg7:CreationType"/> <element name="Classification" type="mpeg7: ClassificationType" minOccurs="0"/> <element name="RelatedMaterial" type="mpeg7: RelatedMaterialType" minOccurs="0" maxOccurs="unbounded"/> </sequence> </extension> </complexContent> </complexType>
The Creation D contains the detailed description tools related to the creation of the content, including places, dates, actions, materials, staff (technical and artistic), and organizations involved. The following elements may be declared:
<! - Definition of Creation DS - > <complexType name="CreationType"> <complexContent> <extension base="mpeg7:DSType"> <sequence> <element name="Title" type="mpeg7:TitleType" minOccurs="1" maxOccurs= "unbounded"/> <element name="TitleMedia" type="mpeg7: TitleMediaType" minOccurs="0"/> <element name="Abstract" type="mpeg7: TextAnnotationType" minOccurs="0" maxOccurs="unbounded"/> <element name="Creator" type="mpeg7: CreatorType" minOccurs="0" maxOccurs="unbounded"/> <element name="CreationCoordinates" minOccurs="0" maxOccurs= "unbounded"> <complexType> <sequence> <element name="Location" type="mpeg7: PlaceType" minOccurs="0"/> <element name="Date" type="mpeg7: TimeType" minOccurs="0"/> </sequence> </complexType> </element> <element name="CreationTool" type="mpeg7: CreationToolType" minOccurs="0" maxOccurs="unbounded"/> <element name="CopyrightString" type="mpeg7: TextualType" minOccurs="0" maxOccurs="unbounded"/> </sequence> </extension> </complexContent> </complexType>
For instance, for the sample video pisa.mpg, the following information on the creation of the content is useful: the creator of the video is Stephan Herrmann, and he was the producer of the video. This information is specified through the CS Term urn:mpeg:mpeg7:cs:RoleCS:2001:PRODUCER of the RoleCS. The following MPEG-7 document contains this information (for better readability, the video information and segmentation are omitted).
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="VideoType"> <Video> <MediaLocator> <MediaUri>file://pisa.mpg</MediaUri> </MediaLocator> <CreationInformation> <Creation> <Title xml:lang="en">Pisa Video</Title> <Abstract> <FreeTextAnnotation> This short video shows the Pisa Leaning Tower. </FreeTextAnnotation> </Abstract> <Creator> <Role href="urn:mpeg:mpeg7:cs:RoleCS: 2001:PRODUCER"> <Name xml:lang="en">Anchorman</Name> </Role> <Agent xsi:type="PersonType"> <Name> <GivenName>Stephan</GivenName> <FamilyName>Herrmann</FamilyName> </Name> </Agent> </Creator> </Creation> <Classification> <ParentalGuidance> <ParentalRating href="urn:mpeg:mpeg7:cs: FSKParentalRatingCS:2003:1"/> <Region>de</Region> </ParentalGuidance> </Classification> </CreationInformation> </Video> </MultimediaContent> </Description> </Mpeg7>
The Classification D contains the description tools that allow the classification of the AV content. It allows the specification of user-oriented classifications (e.g., language, style, genre, etc.) and service-oriented classifications (e.g., purpose, parental guidance, market segmentation, media review, etc.).
In the previous example, we used a regional classification (for Germanspeaking countries) for the parental rating. The video has no violent scene; thus, it is open to the greater public, and the term urn:mpeg:mpeg7:cs:FSK-ParentalRatingCS:2003:1 has to be applied. The FSKParentalRating is not included in the predefined MPEG-7 CS list. Section 2.6 details how this new FSK rating system was introduced to MPEG-7 via its proper extension mechanism.
Finally, the RelatedMaterial D contains the description tools related to additional information about the AV content available in other materials. This could be the description of a Web page and its location; for example, the Pisa City Web homepage
<RelatedMaterial> <DisseminationFormat href = "urn:mpeg:mpeg7:cs: DisseminationFormatCS:2001:4"/> <MaterialType> <Name xml:lang = "en">Pisa City Web Page</Name> </MaterialType> <MediaLocator> <MediaUri>http://www.comune.pi.it/</MediaUri> </MediaLocator> </RelatedMaterial>
2.5.10 Visual Descriptors
MPEG-7 visual description tools consist mainly of descriptors that cover color, texture, shape, motion and face recognition. They mainly use a histogram-based approach of representation; that is, they compute a vector (histogram) of elements each representing the number of pixels (regions) in a given image, which have similar characteristics.
For example, let us suppose that we want to represent the color of an image using the RGB (red, green, and blue) color space. Each color channel is encoded using 8 bits, leading to a maximum of 256 × 256 × 256 bins in a color histogram. The height of each histogram bin is computed as follows: for each discrete value from the interval [0, 256 × 256 × 256], compute how many pixels of the given image have this color value. Obviously, such a fine representation would not be efficient in terms of space; thus, a quantization to a smaller number of bins in the histogram is required. Let us suppose that the color histogram consists of only 256 bins. Then we have to regroup three-color values to one bin value. This may be done by merging three successive values in a linear quantization to one value. For big images, the height of the bin may become quite large. Therefore, a second quantization of the height of the bin is often applied (sometimes referred as amplitude quantization, as it is applied of the amplitude [height] of the bins).
Here we will focus on a color representation of an image. Methods for shape, texture, and so forth also use similar representation techniques. An overview (without a DDL) of them may be found in the article written by Sikora; [11] the complete DDL is available in ISO-IEC 15938-3.
2.5.10.1 Color Descriptors.
There are seven color descriptors available for description in MPEG-7: color space, color quantization, dominant colors, scalable color, color structure, color layout, and the group of frames (GoF) and group of pictures (GoP) color. Here we give a brief overview of these descriptors (including their DDL) and show how descriptions are created. For details on the content (without DDL), the reader is referred to Manjunath et al. [12]
2.5.10.2 Color Space Descriptor.
This feature is the color space that is to be used. The following main color spaces are supported for description:
-
R,G,B Color Space: three values to represent a color in terms of red, green, and blue. It is, as preferred, machine-readable color space.
-
Perceptual Color Spaces available for descriptions are:
-
Y,Cr,Cb Color Space: Y is the luminance, and Cb and Cr are the chrominance values of this color space.
-
H,S,V Color Space: HSV (hue, saturation, and value) is close to perception. The hue and saturation values clearly distinguish pure colors.
-
HMMD (Hue-Max-Min-Diff): Color Space is closer to a perceptually uniform color space than H,S,V Color Space.
-
2.5.10.3 Color Quantization Descriptor.
This descriptor defines a uniform quantization of a color space. The number of bins, which the quantizer produces, is configurable such that great flexibility is provided for a wide range of applications. For a meaningful application in the context of MPEG-7, this descriptor has to be combined with dominant color descriptors; for example, to express the meaning of the values of dominant colors.
2.5.10.4 Dominant Color(s) Descriptor.
This color descriptor is most suitable for representing local (object or image region) features where a small number of colors are enough to characterize the color information in the region of interest. It is also applicable on whole images; for example, flag images or color trademark images.
The DDL of dominant color is shown below. At most, eight dominant colors may be specified for one image. The most relevant elements to be specified are color quantization, used to extract a small number of representing colors in each region/image (use the ColorQuantization element together with the ColorSpace if RGB is not used); percentage of each quantized color in the region, calculated correspondingly (percentage element); spatial coherency on the entire descriptor, a single value that tells us how closely connected are the pixels having the dominant color. The Index element specifies the index of the dominant color in the selected color space as defined in ColorQuantization. The number of bits for each component is derived from the ColorQuantization element. Finally, the optional ColorVariance specifies an integer array containing the value of the variance of color values of pixels corresponding to the dominant color in the selected color space.
Note that all color descriptors extend the VisualDType to be employed in the description of a video/image as required by the VideoSegmentType and StillRegionType.
<complexType name="DominantColorType" final="#all"> <complexContent> <extension base="mpeg7:VisualDType"> <sequence> <element name="ColorSpace" type="mpeg7: ColorSpaceType" minOccurs="0"/> <element name="ColorQuantization" type="mpeg7: ColorQuantizationType" minOccurs="0"/> <element name="SpatialCoherency" type="mpeg7: unsigned5"/> <element name="Value" minOccurs="1" maxOccurs="8"> <complexType> <sequence> <element name="Percentage" type="mpeg7:unsigned5"/> <element name="Index"> <simpleType> <restriction> <simpleType> <list itemType="mpeg7:unsigned12"/> </simpleType> <length value="3"/> </restriction> </simpleType> <element name="ColorVariance" minOccurs="0"> ... </sequence> </complexType> </element> </sequence> </extension> </complexContent> </complexType>
The following MPEG-7 document shows the DominantColor description for a completely red image. Note that the MPEG-7 DDL gives constraint on the coding of the values; for instance, the percentage has to be coded by mpeg7:unsigned5. A percentage value of 100% is coded to the value 31.
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="ImageType"> <Image> <MediaLocator> <MediaUri> file://red.jpg</MediaUri> </MediaLocator> <TextAnnotation> <FreeTextAnnotation> A completely red image </FreeTextAnnotation> </TextAnnotation> <VisualDescriptor xsi:type="DominantColorType"> <SpatialCoherency>31</SpatialCoherency> <Value> <Percentage>31</Percentage> <Index>255 0 0</Index> <ColorVariance>1 0 0</ColorVariance> </Value> </VisualDescriptor> </Image> </MultimediaContent> </Description> </Mpeg7>
2.5.10.5 Scalable Color Descriptor.
The Scalable Color Descriptor (SCD) is a color histogram in the HSV Color Space that is encoded by a Haar transform. The Haar transformation corresponds to a low-pass filter on the histogram values obtained from counting the number of pixels that fall into a certain color range. It has been shown that a much more compact descriptor is obtained by applying this transformation without loss of retrieval accuracy.
The SCD binary representation is scalable in terms of bin numbers and bit representation of the amplitudes. It is useful for image-to-image comparison where the spatial distribution of the color is not a significant retrieval factor. Retrieval accuracy increases with the number of bits used in the representation.
The definition of the ScalableColorType is given here:
<complexType name="ScalableColorType" final="#all"> <complexContent> <extension base="mpeg7:VisualDType"> <sequence> <element name="Coeff" type="mpeg7: integerVector"/> </sequence> <attribute name="numOfCoeff" use="required"> <simpleType> <restriction base="integer"> <enumeration value="16"/> <enumeration value="32"/> <enumeration value="64"/> <enumeration value="128"/> <enumeration value="256"/> </restriction> </simpleType> </attribute> <attribute name="numOfBitplanesDiscarded" use= "required"> <simpleType> <restriction base="integer"> <enumeration value="0"/> <enumeration value="1"/> <enumeration value="2"/> <enumeration value="3"/> <enumeration value="4"/> <enumeration value="6"/> <enumeration value="8"/> </restriction> </simpleType> </attribute> </extension> </complexContent> </complexType>
In addition to the histogram values given in Coeff, two attributes have to be specified: numOfCoeff specifies the number of coefficients used in the scalable histogram representation—possible values are 16, 32, 64, 128, and 256; numOfBitplanesDiscarded specifies the number of bitplanes discarded in the scalable representation for each coefficient—possible values are 0, 1, 2, 3, 4, 6, and 8.
A complete example of a SCD is given within the context of the GoF and GoP Color Descriptor for a video, found later in this section.
2.5.10.6 Color Structure Descriptor.
The Color Structure Descriptor (CSD) is a color feature descriptor that captures both color content (similar to a color histogram) and information about the structure of this content. Its main functionality is image-to-image matching where an image may consist of possibly disconnected regions.
Example 1: Consider the two images in Exhibit 2.10.
Exhibit 2.10: Sample image for showing the usefulness of the color structure descriptor.

A descriptor based only on the global color distribution (e.g., the Scalable Color Descriptor) may not distinguish these two images. Thus, we need to introduce a means of describing the spatial layout (structure) of the color distribution.
The extraction method embeds color structure information into the descriptor by taking into account all colors in a structuring element of 8 × 8 pixels that slides over the image, instead of considering each pixel separately. Color values are represented in the double-coned HMMD Color Space, which is quantized nonuniformly into 32, 64, 128, or 256 bins (see the definition of the simpleType for the element value in the DDL below). Each bin amplitude value is represented by an 8-bit code.
Example 2: Consider the image in Exhibit 2.11. The table on the right of the image shows which bins (representing group of colors) are updated for the sample 8× 8 structuring element.
Exhibit 2.11: Sample image for showing the construction process of the histogram.
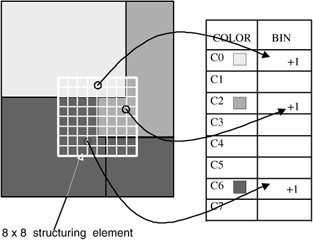
The DDL of the ColorStructureType is shown below:
<complexType name="ColorStructureType" final="#all"> <complexContent> <extension base="mpeg7:VisualDType"> <sequence> <element name="Values"> <simpleType> <restriction> <simpleType> <list itemType="mpeg7:unsigned8"/> </simpleType> <minLength value="1"/> <maxLength value="256"/> </restriction> </simpleType> </element> </sequence> <attribute name="colorQuant" type="mpeg7: unsigned3" use="required"/> </extension> </complexContent> </complexType>The two images from example 1 would be expressed by the following MPEG-7 documents. Note that for simplicity we use only nine values, corresponding to the nine possible positions of the structuring element in the images. For a real application, at least 32 values have to be specified. The colorQuant attribute tells us the number of bins used: 1 means 32, 2 means 64, and so on. The colorQuant value used in this example is, therefore, a dummy value.
Left image:
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="ImageType"> <Image> <MediaLocator> <MediaUri> file://left.jpg</MediaUri> </MediaLocator> <TextAnnotation> <FreeTextAnnotation> The left black and white image of Exhibit 2.10 </FreeTextAnnotation> </TextAnnotation> <VisualDescriptor xsi:type="ColorStructureType" colorQuant="1"> <Values> 9 0 0 0 ... 0 9 </Values> </VisualDescriptor> </Image> </MultimediaContent> </Description> </Mpeg7>Right image:
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="ImageType"> <Image> <MediaLocator> <MediaUri> file://right.jpg</MediaUri> </MediaLocator> <TextAnnotation> <FreeTextAnnotation> The right black and white image of Exhibit 2.10 </FreeTextAnnotation> </TextAnnotation> <VisualDescriptor xsi:type= "ColorStructureType" colorQuant="1"> <Values> 6 0 0 0 ... 0 7 </Values> </VisualDescriptor> </Image> </MultimediaContent> </Description> </Mpeg7>
2.5.10.7 Color Layout Descriptor.
The Color Layout Descriptor (CLD) represents the spatial distribution of color in an image in a compact form. The input image is divided into 64 (8 × 8) blocks. The average color is used as representative for each block. Discrete cosine transform is then applied to each subpart of the image, and 63 coefficients are extracted. This compactness allows image-matching functionality with good retrieval efficiency at small computational costs. The DDL of the CLD mainly consists of the enumeration of the 63 coefficients and is not shown here.
2.5.10.8 GoF and GoP Color Descriptor.
The GoF and GoP Descriptor extends the ScalableColor Descriptor (SCD) (defined earlier for still images) to color description of a video segment or a collection of still images. Two additional bits (to the SCD) allow the inclusion of information on how the color histogram was calculated (by average, median, or intersection) before the Haar transformation was applied to it.
The DDL of the GoFGoPColorType is shown below:
<complexType name="GoFGoPColorType" final="#all"> <complexContent> <extension base="mpeg7:VisualDType"> <sequence> <element name="ScalableColor" type="mpeg7: ScalableColorType"/> </sequence> <attribute name="aggregation" use="required"> <simpleType> <restriction base="string"> <enumeration value="Average"/> <enumeration value="Median"/> <enumeration value="Intersection"/> </restriction> </simpleType> </attribute> </extension> </complexContent> </complexType>
The Average histogram, which refers to averaging the counter value of each bin across all frames or pictures, is equivalent to computing the aggregate color histogram of all frames and pictures with proper normalization. The Median Histogram refers to computing the median of the counter value of each bin across all frames or pictures. The Intersection Histogram refers to computing the minimum of the counter value of each bin across all frames or pictures to capture the least common color traits of a group of images.
We will use the GoF/GoP Color Descriptor to describe the color characteristics of our sample video, pisa.mpg. We thereby use a descriptor for each segment to enable similarity matching to the segment granularity. The following is an MPEG-7 document describing the video segmentation of pisa.mpg (the StillRegions are left out for better readability, and only the GoF for the first segment is included).
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="VideoType"> <Video> <MediaLocator> <MediaUri>file://pisa.mpg</MediaUri> </MediaLocator> <TemporalDecomposition> <VideoSegment > <TextAnnotation> <FreeTextAnnotation> Pisa Leaning Tower </FreeTextAnnotation> </TextAnnotation> <VisualDescriptor xsi:type="GoFGoPColorType" aggregation="Average"> <ScalableColor numOfCoeff="4" numOfBitplanesDiscarded="0"> <Coeff>7 0 2 0 0 0 0 0 0 0 7 0 13 7 42 98 81 13 3 0 0 0 0 0 3 12 46 51 67 112 92 231 218 26 1 1 0 0 0 0 0 8 31 45 83 182 146 469 244 27 1 0 0 0 0 0 0 24 22 28 65 151 119 601 835 196 106 43 18 5 41 32 131 279 590 386 491 642 367 1387 4046 783 47 6 0 1 2 8 92 157 278 206 275 609 581 643 1666 149 3 0 0 0 0 0 6 7 4 7 21 106 204 213 649 28 0 0 0 0 0 0 0 0 0 0 1 14 64 1211 5436 2144 418 106 40 12 56 112 511 2381 1258 372 403 618 512 754 4879 1532 36 3 0 0 0 10 18469 8102 3961 178 50 211 311 54 683 260 0 0 0 0 0 0 0 0 0 0 0 1 12 0 51 32 0 0 0 0 0 0 0 0 0 0 0 0 0 91 275 98 19 5 2 0 1 1 4 104 43 29 31 55 49 10 79 20 0 0 0 0 0 0 442 394 13 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0</Coeff> </ScalableColor> </VisualDescriptor> <MediaTime> <MediaTimePoint>T00:00:00:0F25< /MediaTimePoint> <MediaIncrDuration mediaTimeUnit="PT1N25F">218< /MediaIncrDuration> </MediaTime> </VideoSegment> <VideoSegment > <TextAnnotation> <FreeTextAnnotation> Pisa Palais </FreeTextAnnotation> </TextAnnotation> <MediaTime> <MediaTimePoint>T00:00:08:18F25< /MediaTimePoint> <MediaIncrDuration mediaTimeUnit="PT1N25F">45< /MediaIncrDuration> </MediaTime> </VideoSegment> </TemporalDecomposition> </Video> </MultimediaContent> </Description> </Mpeg7>
2.5.11 Semantic Description Tools
For some applications, the structure of the media is only of partial use; in addition, the user is interested in the semantic of the content. For such applications, MPEG-7 provides the semantic description tools. The core type of the semantic description tools is the SemanticBase DS, which describes semantic entities in a narrative world.
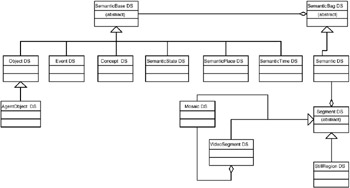
The available semantic entities are shown in Exhibit 2.12 and are described here.
Exhibit 2.12: Organization of semantic entities in MPEG-7.
-
The Semantic DS is the "connecting DS" to the structural DSs, for example, the Segment DS, as depicted in Exhibit 2.12. It simply extends the SemanticBag DS. The SemanticBag DS is an abstract tool that is the base of the DSs that describe a collection of semantic entities and their relation.
-
The Object DS describes a perceivable or abstract object. A perceivable object is an entity that exists; that is, has temporal and spatial extent in a narrative world (e.g., "the leaning tower"). An abstract object is the result of applying abstraction to a perceivable object (e.g., "any tower"). Essentially, this generates an object template.
-
The AgentObject DS extends the Object DS. It describes a person, an organization, a group of people, or personalized objects (e.g. "myself, Roger Moore").
-
The Event DS describes a perceivable or abstract event. A perceivable event is a dynamic relation involving one or more objects occurring in a region in time and space of a narrative world (e.g., "myself climbing the leaning tower"). An abstract event is the result of applying abstraction to a perceivable event (e.g., "anyone climbing a tower").
-
The Concept DS describes a semantic entity that cannot be described as a generalization or abstraction of a specific object, event, time place, or state. It is expressed as a property or collection of properties (e.g., "harmony"). It may refer to the media directly or to another semantic entity being described.
-
The SemanticState DS describes one or more parametric attributes of a semantic entity at a given time or spatial location in the narrative world or in a given location in the media (e.g., "the tower is 50 meters high").
-
Finally, SemanticPlace and SemanticTime DSs describe respectively a place and a time in a narrative world.
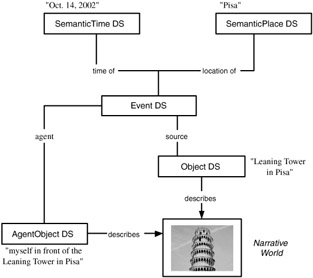
The conceptual aspect of a concrete description can be organized in a tree or in a graph (see Exhibit 2.13). The graph structure is defined by a set of nodes representing semantic notions and a set of edges specifying the relationship between the nodes. Edges are described by the SemanticRelation DSs.
Exhibit 2.13: Semantic graph description for the running example.
2.5.11.1 Application to the Running Example.
A possible conceptual aspect description for the first frame of our sample video pisa.mpg is illustrated in Exhibit 2.13. The narrative world involves myself, Harald Kosch (not shown), standing in front of the Pisa Leaning Tower and taking a picture of the tower. The semantic event is characterized by a semantic time description: "14th of October 2002" and a semantic place: "Pisa." The description of the event contains one object, the "Leaning Tower," and one person, "Harald Kosch" (myself).
The MPEG-7 document for this semantic scene graph is given below. For a better readability, only the semantic aspects are specified in the document. The semantic relations are identified by terms of a CS. A total of 82 terms are predefined. New terms are added as described in Section 2.7. Note that the SemanticPlace and SemanticTime are child elements of Event and do not require a Semantic Relation.
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="ImageType"> <Image> <Semantic> <Label> <Name> Harald Kosch takes a photo of the Leaning Tower </Name> </Label> <SemanticBase xsi:type="EventType" > <Label> <Name> Description of the event of taking a photo </Name> </Label> <Relation type="urn:mpeg:mpeg7:cs: SemanticRelationCS:2001:agent" target="#Harald"/> <Relation type="urn:mpeg:mpeg7:cs: SemanticRelationCS:2001:source" target="#Tower"/> <SemanticPlace> <Label> <Name>Pisa</Name> </Label> </SemanticPlace> <SemanticTime> <Label> <Name>October 14, 2002</Name> </Label> </SemanticTime> </SemanticBase> <SemanticBase xsi:type="ObjectType" > <Label> <Name> Leaning Tower </Name> </Label> </SemanticBase> <SemanticBase xsi:type="AgentObjectType" > <Label> <Name> Harald </Name> </Label> <Agent xsi:type="PersonType"> <Name> <GivenName abbrev="Harry"> Harald </GivenName> <FamilyName> Kosch </FamilyName> </Name> </Agent> </SemanticBase> </Semantic> </Image> </MultimediaContent> </Description> </Mpeg7>
2.5.12 Media Decomposition Tools
The Segment DS is recursive, that is, it may be subdivided into subsegments, and thus may form a hierarchy (decompositon tree). The resulting decomposition tree is used to describe the media source, the temporal, or the spatial structure of the AV content. For example, a video clip may be temporally segmented into various levels of scenes, shots, and segments. The decomposition tree may be used to generate a table of contents.
Exhibit 2.14 shows the possible decompositions for the description scheme introduced in this chapter, for example, VideoSegment DS and StillRegion DS, and derived from Segment DS. The principal decomposition mechanisms are denoted by lines and are labeled by the decomposition type (time -> temporal descomposition, space -> spatial decomposition, spaceTime -> spatial and temporal, media -> decomposition in different media tracks). The AudioVisual segment can contain both audio and visual segments. The last members in the chain of segments may be Audio, Video, and Still region.
Exhibit 2.14: Multimedia decomposition in MPEG-7.
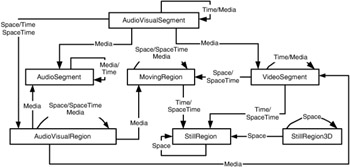
The root type for the description of segment decomposition is the abstract SegmentDecompositionType. It defines a set of basic attributes defining the type of subdivision: temporal, spatial, or spatio-temporal. They are related to the spatial and temporal subdivisions that may leave gaps and overlaps between the subsegments. The definition of the SegmentDecompostionType is given below.
<! - Definition of SegmentDecomposition DS - > <complexType name="SegmentDecompositionType" abstract="true"> <complexContent> <extension base="mpeg7:DSType"> <attribute name="criteria" type="string" use="optional"/> <attribute name="overlap" type="boolean" use="optional" default="false"/> <attribute name="gap" type="boolean" use="optional" default="false"/> </extension> </complexContent> </complexType>
From the root type, four abstract second-level types are derived: SpatialSegmentDecomposition DS, TemporalSegmentDecomposition DS, SpatioTemporalSegmentDecomposition DS, and MediaSourceSegmentDecomposition DS, describing the spatial, temporal, spatio-temporal, and media source decompositions, respectively, of segments.
The concrete tools to be employed for a given multimedia element (e.g., of type VideoSegmentType) extend these four second-level types. For instance, we have seen that in a VideoSegment, we require four types to describe any possible decomposition. In the following DDL extract, four elements are defined with the according types.
<choice minOccurs="0" maxOccurs="unbounded"> <element name="SpatialDecomposition" type="mpeg7: VideoSegmentSpatialDecomposition- Type"/> <element name="TemporalDecomposition" type="mpeg7: VideoSegmentTemporalDecompositionType"/> <element name="SpatioTemporalDecomposition" type="mpeg7:VideoSegmentSpatioTemporal DecompositionType"/> <element name="MediaSourceDecomposition" type="mpeg7:VideoSegmentMediaSource DecompositionType"/> </choice>
The instantiation of the decomposition involved in a Segment DS can be viewed as a hierarchical segmentation problem where elementary entities (region, video segment, and so forth) have to be defined and structured by inclusion relationship within a tree. In this sense, the following decomposition tree (Exhibit 2.15) may describe our sample video. We have two children segments, one for the leaning tower and one for the palais. For each segment, we retain a keyframe that gives a second level in the tree.
Exhibit 2.15: Decomposition tree for the running example.
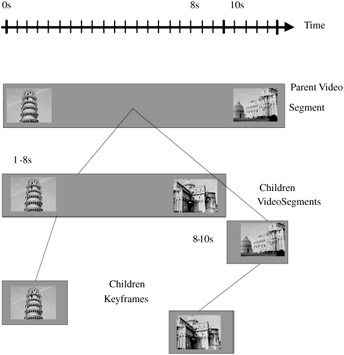
The following XML document translates the decomposition tree of Exhibit 2.15 into a valid MPEG-7 description. Note that MediaInformation, Visual Descriptors, and Creation and Production Information are omitted for better readability. Using a SpatioTemporalDecomposition element within the declaration of the VideoSegment specifies the key frame for each Videosegment. The key frame is a StillRegion and its position in the stream is defined relative to the beginning of the VideoSegment (i.e., MediaRelIncrTimePoint of the StillRegion to MediaTimePoint of the VideoSegment). The relative time distance is given in frames. For this, the frame rate has to be provided. This is done by specifying PT1N25F as mediaTimeUnit in the MediaRelIncrTimePoint element.
<Mpeg7> <Description xsi:type="ContentEntityType"> <MultimediaContent xsi:type="VideoType"> <Video> <MediaLocator> <MediaUri>pisa.mpg</MediaUri> </MediaLocator> <TemporalDecomposition> <VideoSegment > <TextAnnotation> <FreeTextAnnotation> Pisa Leaning Tower </FreeTextAnnotation> </TextAnnotation> <MediaTime> <MediaTimePoint>T00:00:00:0F25< /MediaTimePoint> <MediaIncrDuration mediaTimeUnit="PT1N25F">218< /MediaIncrDuration> </MediaTime> <SpatioTemporalDecomposition> <StillRegion> <MediaRelIncrTimePoint mediaTimeUnit="PT1N25F">23< /MediaRelIncrTimePoint> <SpatialDecomposition/> </StillRegion> </SpatioTemporalDecomposition> </VideoSegment> <VideoSegment > <TextAnnotation> <FreeTextAnnotation> Pisa Palais </FreeTextAnnotation> </TextAnnotation> <MediaTime> <MediaTimePoint>T00:00:08:18F25< /MediaTimePoint> <MediaIncrDuration mediaTimeUnit="PT1N25F">45 </MediaIncrDuration> </MediaTime> <SpatioTemporalDecomposition> <StillRegion> <MediaRelIncrTimePoint mediaTimeUnit="PT1N25F">32< /MediaRelIncrTimePoint> <SpatialDecomposition/> </StillRegion> </SpatioTemporalDecomposition> </VideoSegment> </TemporalDecomposition> <MediaLocator> <MediaUri>pisa.mpg</MediaUri> </MediaLocator> </Video> </MultimediaContent> </Description> </Mpeg7>
[7]Martínez, J.M., Overview of the MPEG-7 Standard. ISO/IEC JTC1/SC29/WG11 N4980 (Klagenfurt Meeting), July 2002, http://www.chiariglione.org/mpeg/.
[8]Manjunath, B.S., Salembier, P., and Sikora, T., Introduction to MPEG-7, John Wiley & Sons, New York, 2002.
[9]Martínez, J.M., Overview of the MPEG-7 Standard. ISO/IEC JTC1/SC29/WG11 N4980 (Klagenfurt Meeting), July 2002, http://www.chiariglione.org/mpeg/.
[10]Sikora, T., The MPEG-7 visual standard for content description—an overview, IEEE Trans. Circuits Syst. Video Technol., 11, 703–315, 2001.
[11]Sikora, T., The MPEG-7 visual standard for content description—an overview, IEEE Trans. Circuits Syst. Video Technol., 11, 703–315, 2001.
[12]Manjunath, B.S., Ohm, J.-R., Vasudevan, V.V., and Yamada, A., Color and texture descriptors, IEEE Trans. Circuits Syst. Video Technol., 11, 703–315, 2001.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 77