Section 9.1. Levels of Text Representation and Processing
9.1. Levels of Text Representation and ProcessingThe Unicode standard defines the termhigher-level protocol as denoting "any agreement on the interpretation of Unicode characters that extends beyond the scope of this standard." It adds a note: "Such an agreement need not be formally announced in data; it may be implicit in the context." For example, an agreement such as the XML specification says that a sequence of characters like π will be understood as a character reference (denoting the Greek small letter pi π, U+03C0, in this case). This is an example of a very explicit agreement. The scope of this agreement consists of XML documents, though it can, by separate conventions, be extended to apply elsewhere as well. The same information can often be expressed at different protocol levelse.g., at the character level or in a program-specific data format. There is no simple answer to the question of which level should be used. Factors to be considered include the following:
9.1.1. Plain Text, Rich Text, and MarkupRoughly speaking, we can characterize some basic formats of text as follows, using widely known software as examples for concreteness:
The normal data formats used by word processors are not text at all in the sense discussed here. This may sound surprising, since when people use such software to create a document with a filename suffix like .doc, they usually think they work with text. After all, that's the normal way of typing text to many people. The explanation to this paradox is that such formats (as well as, for example, PDF documents and text databases) contain text, but their overall data format is not textual. There is more about this in the last section of this chapter ("Media Types for Text"). When you send a document, or request for a document, by email or otherwise, it is important to specify the format in an understandable way. Do not assume that most people know the distinctions described here. It is often best to specify the format exactly (e.g., "RTF format") rather than generally (e.g., "rich text"), since the specific formats are more widely known. When requesting documents, it is nice to offer a list of allowed formats. Beware, however, that conversions between plain text, rich text formats, and markup formats may lose information and may require human intervention (interaction)i.e., cannot be reliably automated in general. Data (whether text or not) can be accompanied by information (metadata) that tells how it should be interpretedi.e., what its data format is. Such information is often included in Internet message headers, as explained in Chapter 10. It should not be confused with markup, which is part of the data itself and typically applies to parts of a document, not the document as a whole. The information about data format should be available before any markup in the document is interpreted, for example, since the format specifies whether anything in the data is to be treated as markup in the first place. 9.1.1.1. Plain textA plain text file, such as a file written with Notepad, is just a sequence of characters. It is true that it has a line structure, but that structure is expressed using control characters. When displayed, the text appears in some font, but this is just a choice that can be made for the text as a whole. A plain text file does not contain any font information. When we move from plain text to word processinge.g., in MS Wordthe most obvious change is that we can use different font faces and sizes for different parts of text. Font changes are not encoded into the characters but expressed using internal data, which is not shown to the user as such but is used to modify the rendering of characters. If you select File In a typical word processor, there is much more data that is not shown as part of the document, such as authorship information, date stamps, language information, styling information, and perhaps even a revision history. Styling includes margins, text justification, character and word spacing, etc. 9.1.1.2. Rich text formatsData that consists of text and associated formatting or structural information is often called rich text. This general concept should not be confused with particular formats such as Rich Text Format (RTF), which is a specific format used for interchange of text between word processors so that formatting information is retained. Rich text is also called styled text. For example, in the RTF format, underlined text like foo is written as {\ul foo}. There is no clear line between rich text and markup. Usually, however, we use the name "rich text" for formats with presentational information that is typically generated by a word processor, email program, or other software, to encode the effect of the formatting commands that the user has given. Markup might also be generated in a similar way, but often markup is oriented toward describing document structures, with some separation of structure from presentation. Markup usually contains elements for the overall structure and layout of a document, and markup could be generated programmatically, or even written "by hand" (i.e., using a text editor). 9.1.1.3. Text with markupIf formatting or structural information is written using normal characters, it is usually referred to as markup. The most widely know markup is the HTML markup used on web pages. For example, the string <h2>Summary</h2> can be interpreted as containing the textual content "Summary" surrounded by the two tags, <h2> and </h2>. If a program interprets the data according to HTML rules, it would treat the textual content as a second-level heading. If it applies some other interpretationfor example, in an XML contextthe tags might mean something completely different. Anyway, such interpretations mean that the data is not taken as plain text but as marked-up text. The interpretation could lead to a particular rendering of the textual content, or it might affect automatic processing such as the construction of a table of contents. Alternatively, a program could interpret <h2>Summary</h2> just as a string and display it as such, for example. One of the practical differences between markup like HTML and the internal formats used by word processors is that markup can be viewed and edited as text. You can work with HTML using just a plain text editor and writing all the tags yourself. This is however impractical in many cases. Markup is often so verbose and complicated that an HTML or XML document is very hard to read as such, as "source." Instead, people use various specialized tools, like WYSIWYG (What You See Is What You Get) editors, which handle most of the markup invisibly. In practice, this means that the distinction between markup and word processors' data formats has been obscuredeven more so when word processors use an XML-based format, as they often do these days. 9.1.1.4. Quasi-markupAs an intermediary between plain text and marked-up text, people often use notations created with special characters, such as slash (solidus) characters around a word to simulate writing it in italics. Some software such as email programs might interpret the special characters in a markup-like manner, displaying /foo/ as foo in italics (perhaps retaining the slashes: /foo/). This may cause problems when a message contains the string /foo/ and this should be interpreted and displayed literally. Most of the time, however, such markup-like conventions in plain text work reasonably well, even if some readers see them literally and need to understand the underlying convention. Common conventions of this kind include using asterisks for strong emphasis or bolding (*foo* means foo in bold face) and underscores (low lines) for underlining or emphasis (_foo_ means foo underlined or emphasized in a manner that corresponds to using italics: foo). Thus, we cannot really say that some text is plain text or marked-up text as such. Rather, it can be interpreted or processed as plain text, or according to some markup rules. The border between plain text and rich text or marked-up text is not absolute. In a sense, punctuation characters could be regarded as markup. A good example is the Spanish use of paired question marks: the text ¿Cómo? is structurally similar to XML markup like <question>Cómo</question>. The main reason for not regarding punctuation marks as markup is that they became a traditional part of writing systems long before the age of computers. 9.1.1.5. Conversion to plain textYou may need to convert rich text or marked-up text to plain text for various reasonse.g., when filling out a form that accepts plain text only or when inserting text into an email message body that needs to be plain text. Quite often, you could just cut and paste the text, but you could also open a text file in a word processor and use the "Save As" command to create a plain text version. Irrespective of the method, the conversion may lose information, as described later in this chapter. If you convert 106 (with "6" in superscript style, not as the character superscript six) to plain text, you get 106, which is all wrong. There is no simple way to check whether such things happen, but superscripts are a common reason to stay alert. Moreover, even if the data is reasonably convertible to plain text, there are practical reasons to consider character encoding issues as well. Often, the reasons for converting to plain text imply the necessity of restricting the character repertoire as well. In email message bodies, for example, you often need to stick to ASCII, or at least to ISO-8859-1. For example, if you use MS Word to save a Word document's content in plain text, you first select File 9.1.2. Example: Nonbreaking HyphenAs mentioned in section "General Punctuation" in Chapter 8, the common way of inserting a "nonbreaking hyphen" in MS Word does not insert the Unicode character with that name. Instead, when you press Ctrl-Shift-hyphen in Word, you insert the control character U+001F. MS Word displays it as a normal ASCII hyphen. For an illustration, open MS Word, type an ASCII hyphen, and then Ctrl-Shift-hyphen, and finally insert a nonbreaking hyphen (U+2011)e.g., by typing Alt-8209. You get something like "---," where the last hyphen is usually different from the other two. This is because since the nonbreaking hyphen character is not present in many fonts, Word often needs to take it from another font. When the nonbreaking hyphen is from another font, a trained eye may notice a disturbing typographic difference between various hyphens. Thus, the MS Word approach of using a control character is in some ways safer than using a special character. It works with any font. On the other hand, it is program-specific. If you save a document as plain text or cut and paste text containing the control character, you may get nothing, or a space, or an error, depending on program. If you use markup such the HTML markup <td nowrap>foo-bar</td>, where the nowrap attribute forbids line breaks inside the td (table cell) element, you achieve the same effect as using a nonbreaking hyphen (<td>foo‑bar</td>). That way, you avoid the risks involved in this relatively poorly supported character. On the other hand, if the content is saved as plain text from a browser or copied and pasted, the information in the markup is lost. 9.1.3. Example: Formatting in Word ProcessingSuppose that you need to write the notation Ka when composing a document in a word processor. The practical method is to write the letters "Ka," then select the letter "a" with the mouse and use the word processor's tools for making text appear as subscript. For example, in MS Word you would use the command Format You can exchange data between different word processors without losing such formatting information. Word processors can often read files in formats written by other word processors. Moreover, you can save the document in the RTF format (Rich Text Format), which preserves the formatting, including subscripting. In theory, you could alternatively use the Unicode character Latin subscript small letter "a" (U+2090). This would let you use subscripts even in plain text. The character U+2090 is, however, hardly available in fonts that people use. It was added to Unicode in Version 4.1. In some applications, the approach could be feasible, though. You could, for example, store data using such characters into a database and make sure that all software that extracts and renders data from it contains code that deals with the subscript characters. For example, it could be converted into a data format like the one used by MS Word or, much simpler, into HTML format (<sub>a</sub>), for display with a web browser. Similar considerations apply to almost all subscripts, superscripts, underlining, italics, and other formatting, even when it indicates basic differences between symbols and not just emphasis or styling. Some exceptions to this were mentioned in Chapter 8. 9.1.4. Example: HTML Markup and CSSConsider the following fragment of markup from a web page. It is rather obvious intuitively what it means, if you know or guess that nobr means "no break." This is not meant to be an example of good, modern HTML markup: <nobr>Hello <font color="red" size="+1">world</font></nobr> When rendered by a web browser, this displays as "Hello world" with the second word in larger font and in red. Moreover, a line break will never appear between the words. The markup is deprecated and even nonstandard, but it illustrates the simple idea of inserting markup into a stream of characters. The font markup affects features that are beyond the scope of character standards, such as text color and font size. The nobr markup, on the other hand, affects things that could be affected at the character level too, using a no-break space character instead of a normal space. In a more modern approach, features of character presentation are not expressed in HTML but in CSS (Cascading Style Sheets), although CSS constructs could be embedded into HTML, for example, as follows: <div style="white-space: nowrap">Hello <span style= "color:red; font-size: larger">world</span></div> We could adopt a more structured approach by moving the CSS code away from the document itself, making the HTML code, e.g.: <div >Hello <span >world</span></div> Figure 9-1. A mathematical equation written with a simple formula editor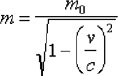 In that case, a separate CSS file (which would be referred to in the HTML document) would contain the formatting instructions, as "out of band" information: div.greering { white-space: nowrap; } span.emphatic { color:red; font-size: larger; }In such an approach, as in the pure HTML approach, the formatting instructions would be completely independent of the character data. This means that the formatting is not preserved when data is transferred as plain text. The formatting information might be converted as part of conversion to another data format, such as RTF or PDF, but this requires specific conversion software. 9.1.5. Linear Text Versus Mathematical NotationsAlthough several character repertoires, most notably Unicode, contain mathematical and other symbols, the presentation of mathematical formulas is much more than just a character level issue. At the character level, symbols such as integral and n-ary summation can be defined, and their code positions and encodings defined, and representative glyphs shown, and perhaps some usage notes given. However, the construction of real formulase.g., for a definite integral of a functionis a different thing, no matter whether one considers formulas abstractly (how the structure of the formula is given) or presentationally (how the formula is displayed on paper or on screen). To mention just a few approaches to such issues, the TeX system is widely used by mathematicians to produce high-quality presentations of formulas, and MathML is an ambitious effort for creating a markup language for mathematics so that both structure and presentation can be handled. In practice, people often use simpler tools such as formula editors, some of which are included in word processors. To illustrate how the problems of mathematical notations exceed the character-level, consider the relatively simple formula shown in Figure 9-1. The formula was created using the built-in formula editor of MS Word, invoked via the Insert If you use a formula editor to produce expressions that will appear as separate blocks, you have the problem that symbols that you use in text may look rather different from the same symbols in the blocks. For example, your formula editor might let you express subscript zero or a square root nicely, but in text paragraphs, you would need to resort to other Figure 9-2. A sample from MathWorld, containing text as images Figure 9-3. MathWorld sample with increased font size methods, like the square root character, Similar considerations apply to the use of images. Especially in web publishing, it is common to present any complicated formulas as images, created using, for example, a formula editor or the TeX software. For example, MathWorld (available at http://mathworld.wolfram.com) contains an impressive amount of mathematical expressions, but almost exclusively as images. Probably partly to prevent mismatch between symbols in text and in block formulas, the site uses images even inside text, "inline images." The pages have been designed so that you might not notice this but think that those images are normal text characters, as illustrated in Figure 9-2. However, if you change the font size (this may require a special override of document-specified font sizes)e.g., because you cannot read small textyou notice a difference. The images are not scaled, as illustrated in Figure 9-3. Note that apart from one use of a subscript, all symbols used in the text could well be written in characters. You will often be forced to use images for text, especially in formulas. As the example shows, it might be the lesser of evils to use special characters and not images inside linear text, within reasonable limits, even though this might make a symbol in text look different than a symbol in a formula block. For high-quality typesetting, you would need to use software that avoids both problems. 9.1.6. Unicode and MathematicsUnicode can't do math, of course. You can't compute even 1 + 1 in Unicode. You can only write mathematical expressions in Unicode. As explained in the previous section, even this has serious limitations, since much of the conventional mathematical notations are not linear texti.e., text that can be written simply as lines. In addition, there is very large (and increasing) number of mathematical symbols that are typographic variants of letters, with specialized meanings, such as the mathematical sans-serif italic small "a" U+1D4B6 (which more or less looks like a). Although many mathematical symbols have been included in Unicode, they are not widely supported in fonts or in programs. The crucial question is whether it is necessary and possible to make the distinction between a normal letter and a mathematical symbol in plain text. Quite often, other data formats are more suitable, such as HTML, TeX, or MathML. In HTML, for example, maybe you should not use U+1D4B6 (or the equivalent reference 𝒶) but markup like <i style="font-family: sans-serif">a</i>. The latter surely works more widely in current browsers, but is the meaning the same? We will discuss such problems, in a more general framework, in the section "Selecting the Appropriate Level of Expression" later in this chapter. There are other issues, too, in presenting mathematical notations. They are discussed in the Unicode Technical Report UTR #25, "Unicode Support for Mathematics," http://www.unicode.org/reports/tr25/. Much of the material there is largely theoretical at present, due to lack of support in software, and it competes with other approaches, such as MathML, the mathematical markup language. To take a simple example, you probably know that even in elementary algebra, we often write a product without using any multiplication symbol. We can write the product of a and b as axb or as a·b, but also as ab, when there is no ambiguity. This is problematic in processing, since how could a computer program know that ab here denotes a product, instead of just being a variable or something else? In a markup language, you could indicate it as a product using, for example, the following (made-up) markup: <product><factor>a</factor><factor>b</factor></product> Using markup, you could express the structure, to be potentially used in any program that recognizes the markup, without necessarily affecting rendering in the least. Software that recognizes markup in general but not this particular markup could simply ignore the tags and use just the textual content. In order to allow such information to be expressed in plain text as welli.e., even when no markup is availableUnicode contains the character invisible times (U+2062). As the name suggests, it is invisible (has no width), and it is basically defined as having a logical meaning only. In essence, it corresponds to logical markup. Similar characters exist for a few other logical constructs as well, such as the function application (U+2061), which you could use before the left parenthesis in an expression like f(a+b) to indicate the presence of a function invocation rather than, for example, a product or other use of parentheses. You may ask, what's the point of using invisible markup-like characters? And that's a good question. Their usefulness will probably be limited to applications where you need to work with plain text (e.g., in a database or in the internal strings in a program) but need to include structural information expressible with those characters. On output or on transfer of data to other applications, you would probably need to remove those characters, possibly inserting equivalent markup. 9.1.7. Characters Outside the RepertoireThe available repertoire of characters is limited by several factors:
Methods for exceeding different limitations are discussed in various parts of this book. Here we ask what to do if no such method helps. The ultimate limitation is the character code. Naturally, you can often override such a limitation by switching to another character code, such as from ASCII to an ISO 8859 code or to Unicode. It is, however, possible that such solutions cannot be applied, perhaps because the character you need is not even in Unicode. You might need a very rare charactere.g., because it appears in an old manuscript that you need to convert to a digital form, or because you want, or someone else wants, to introduce a new symbol for use in mathematical, technical, or otherwise special text. You probably cannot wait several years until the character can be added to Unicode and implemented in fonts. 9.1.7.1. Different workaroundsIndependently of the nature of the limitation that you need to overcome, there are three basic ways to use a character outside the available repertoire:
The first approach can work only in an environment where you can control font usage. The approach as such does not violate Unicode principles, if you use the Private Use area instead of code points allocated to characters in the Unicode standard. Naturally, the approach would depend on "private agreement," and texts using it would not be portable across systems and applications. The second approach has mostly been used in situations where the character repertoire is limited by practical constraints that do not allow the use of full Unicode. You can still find web pages that represent special characters as images, since authors do not know about Unicode, or since they estimate that the characters are not widely enough available on users' systems. Thus, a character like black spade suit Some of the typographical problems are avoided in the third approach, which represents an entire paragraph or other block, such as a long mathematical equation, as a single image. The idea is to use a tool such as a formula editor or a typesetting program to produce nicely formatted text, containing special characters, as an image that can be embedded into a document where the character set is more limited. This approach is often used when presenting mathematical expressions on web pages. 9.1.7.2. Using a character versus using a small imageQuite often, people insert characters as small images, typically in GIF format. This looks like a simple solution to the problem of presenting special characters, and it has several benefits:
On the other hand, the method has several drawbacks:
9.1.7.3. Button-like symbolsA typical case of using an image in place of a character is in an instruction manual where you need to refer to a particular symbol in a button or other user interface. You may need to write, for example, "then press the ⌫ key" or "look for places marked with the Consider the case of an instruction manual where you need to tell the user to press a particular button, labeled with a symbol that is not in Unicode. It is normally vain to hope that the symbol will be added to Unicode. Generally, Unicode contains characters used in text, not graphic symbols in general. Although some symbols that you might wish to use may conceivably appear in many texts like instruction manuals, the same applies to virtually all small graphic symbols. There would be no end to adding characters that might casually appear in text as depicting graphic symbols. There are some Unicode characters that seem to contradict the above, such as the watch ⌚ (U+232A), but they have mostly been included due to their presence in other character codes or for some special reasons. Computer keyboard symbols and common symbols seen on a computer screen seem to have made their way to Unicode relatively easily, perhaps due to their assumed need to be included in written instructions. A graphic symbol that is essentially iconici.e., an image that imitates another image (such as something engraved into a button)is best regarded as a symbol that is not a character. The imitated image may have a symbolic meaning (e.g., it could stand for "pause" in a key that makes something pause), but this does not make it a character. If it is used in texts only to stand for the imitated image, it is still essentially an image. If people started using it as a general shorthand notation for the concept or word "pause," effectively turning it into an ideograph, it would become a character. For example, people nowadays often use a heart symbol ♡ in text to mean love (e.g., "I ♡ Unicode"), and this would justify encoding it, if it did not exist in Unicode already (white heart suit, U+2661). Suppose, for example, that you are writing an instruction manual for a device that has a control panel with physical buttons, with some symbols on them. For example, it might have a double vertical rectangle on a pause button'a common convention, though the specific shape varies. There is one possible form of such a button in Figure 9-4. Such a symbol does not exist in Unicode. It might be added some day to Unicode, but that's questionable. What benefits would it produce? You could use it in texts, assuming you have a font that contains it, so you could write some things in some instructions using plain text, instead of embedding an image. However, this would mean that the shape of the character varies. When writing a manual for a particular device, it would be better to use the specific shapes (and perhaps colors) that appear on its buttons. On such grounds, it is better to use embedded images instead of, for example, a Private Use character or a simulation of the shape using Unicode characters with similar appearance, such as the box Figure 9-4. A pause button symbol, not available as a character drawings double vertical Computer keyboard symbols are a somewhat different issue, since people may wish to use generic symbols when writing, for example, a manual for software that may be used with different keyboards. The same applies to symbols in some other equipment, such as telephones, and to symbols that may appear on screen with variation in shape but with a recognizable identity. It can be useful to be able to write "press the option key ⌥" using a character (option key, U+2325) rather than a small image, since you wish to refer to generically to a key assumed to exist in the user's keyboard as marked with a symbol, but in varying shapes. This is one reason why there are several such symbols in Unicode, especially in the Miscellaneous Technical block. Sometimes the name of a Unicode character suggests a more "iconic" use than it is meant for. The eject symbol (U+23CF) consists of a solid triangle above a horizontal bar, and it might be understood as a symbol of a button. However, it is described under the heading "Keyboard and UI symbols" and with the note "UI symbol to eject media." Thus, it relates to user interface (UI) symbols used in computer software. There are also some keyboard symbols from the ISO 9995-7 standard, for example. Generally, button-like symbols are available as Unicode characters only when they are computer-oriented. Even in such cases, the use of images is often a better choice, since the characters are relatively new and do not belong to most fonts. 9.1.7.4. Using an image for esthetic reasonsFor example, in many widely used fonts such as Times New Roman, the male and female sign, Many of the aspects discussed here also apply to the use of images to present texts like a heading, a product name, or button text. For example, in order to make letters multicolored (as in the Google logo), you need to use an image. 9.1.8. Selecting the Appropriate Level of ExpressionWe often have a choice between expressing some information at the character level and expressing it in text formatting, markup, or other methods. Some specific questions of this type have been discussed previously in this chapter, and there will be some further discussion in the section "Characters and Markup" later in the chapter. Here we will consider some general criteria and the impact of different choices. As an example, consider the expression m2. It normally means "square meter," though in mathematics or physics, it might have other meanings, too. There are several ways to express the superscript in a document:
Similarly, assuming you wish or need to conform to the convention that a number and a unit be separated by a space, you could write an expression like "5 m" (for "five meters") in several different ways. The ways depend on whether you wish to express that the space should be non-breakable (i.e., a line break between "5" and "m" is not permitted) and whether you wish to affect the exact amount of spacing. The ways also depend on whether you try to express these things at the character level or elsewhere. Some ways were discussed in the section "General Punctuation" in Chapter 8. There is no universal answer to the question about the choice between character level and other protocol levels. It depends on many aspects, some of which are summarized in Table 9-1. You could well use different strategies in the same document. For example, you could write "5 m2" using the superscript two character but using a normal space, expressing the non-breakability and the width of spacing in a stylesheet. Checking the criteria in the table, it is relatively easy to see the benefits of using the superscript two character, whereas the no-break space could be more problematic. (For example, it can cause surprises in text justification, since it is typically of fixed width.)
When information is expressed at the character level, by the choice of specific Unicode code points, the information persists through all processes that correctly preserve the identity of plain text characters. For example, cut and paste operations may or may not preserve formatting information (such as fonts), but they can be expected to preserve character identity. If the target of pasting is in a program that does not support Unicode, characters may be lost. However, an implementation of Unicode is required to preserve characters, instead of, for example, dropping out characters that it does not recognize. It may well fail to display them, but they should be available in the data by other means. For example, for the expression m2, the first two methods just discussed imply that in cut and paste, the result preserves the information: m2. (For method 2, we assume that you cut from the formatted document, not from XML or HTML source.) For methods 3 and 4, cut and paste normally converts the text to "m2," unless the operation takes place inside a program or between programs that recognize the method used. Thus, if you copy and paste the string "m2" where "2" is formatted as a superscript, the formatting is preserved when working inside a word processor, but not when copying from it into a plain text editor like Notepad. When method 5 is used, the data copied is of course "m2." Similarly, when data is read by a program, information expressed at the character level is always available to the program, though it may not make use of it. Information expressed in markup is normally available, too, since programs normally read the markup source, but they would need to recognize the markupat least to the extent that it can skip it, instead of treating markup as data! Reading data in a word processor's internal format is possible, too, but requires complicated software. Mostly, if you wish to process, say, Word or PDF documents programmatically (e.g., to compute word concordances or to compute statistics on the text), you would first convert the document to plain text or some other easily processable format. Availability of information at the character level is not always an asset. It may imply that a program for processing the data must deal with a larger variation of characters. For example, if the expression "5 m2" is written using the no-break space and the superscript two, what will happen if the expression is used as input to a program that is prepared to handle ASCII data only? If you wish to write a program that can handle all the ways in which the expression could be written in Unicode, in principle, you have lots of cases to consider. For example, someone might write the letter "m" using the fullwidth Latin small letter "m" (U+FF4D), for some good reason. Even if you have no use for the information involved in this choice, you would need to deal with this possibility. You might convert the data to a suitable normalization form (prior to other processing) to reduce the variation considerably. The following list suggests guidelines on choosing the level where information is given, with an emphasis on what should or should not be done at the character level:
9.1.9. Subscripts and SuperscriptsThe need for subscripts or superscripts is one of the most common cases where plain text appears to be insufficient. Most subscripts and superscripts that are needed in practice could be written as Unicode characters, but such an approach is often not feasible. As described in Chapter 8, the repertoire of such characters is relatively large, but only superscripts 1, 2, and 3 are widely supported. The use of subscripts and superscripts can be classified as follows:
Purely stylistic superscripting or subscripting is best handled above the character level, in styling of some kind. Structural superscripting or subscripting should be handled at markup level when possible, and expressing it at the character level is better than making it purely stylistic, though often impractical. The in-between cases are more difficult, and we can only give some general guidelines about them. Many notations are mostly unambiguous even if subscripting or superscripting is removed, but they may create a risk of confusion in special cases. For example, notations for isotopes in chemistry, such as 14C, conventionally use a superscripted number, but omitting the superscripting does not usually cause any ambiguity. In rare cases, however, the text might also contain notations like 14C in a completely different meaning (e.g., as codes of some kind or perhaps as hexadecimal numbers). It is probably best to treat in-between usage as structural, unless there are good reasons to treat it as presentational. Note that in chemistry, notations like C-14 are recommended when superscripting is impossible. 9.1.9.1. Visual appearance of subscripts and superscriptsWhen considering the use of subscript or superscript characters in Unicode, note that the appearance will in general be different from what you get by using other tools. The characters have a fixed appearance in each font. You have no tools for affecting, for example, the vertical position of the superscript with respect to the base letter, except coarsely by trying different fonts. Superscripts are typically more legible in sans-serif fonts than in serif fonts; compare, for example, a2 in Times with a2 in Arial. If you use font formatting commands in a word processor to create subscripts and superscripts, the appearance is different from subscript and superscript characters. Moreover, the appearance can be modified with the tools of the program more flexibly. Compare, for example, the expressions m2 and m2. The appearance of the latter, containing the digit two in superscript style, can be modified with styling commands. For example, in MS Word, you could select the "2" and choose Format Similar notes apply to using sub or sup markup in HTML or similar markup in other markup languages. Their appearance and effect can be tuned in CSS by using the properties font-size, vertical-align, and line-height. If you create your own markup system that has elements for subscripts or superscripts, these three properties should be set suitably in your CSS stylesheet. When different methods for expressing subscripts or superscripts are mixed, the result is usually typographically poor due to style variation. Therefore, do not express superscript and subscript numbers using the Unicode characters unless you can be reasonably sure that you can consistently use that method for all superscripts and subscripts in the document. 9.1.9.2. Replacement notations for superscripts and subscriptsSince superscripting is often structural, especially in mathematics, different methods have been used to describe superscripting in plain text. To express x to the power y, xy, programming languages typically use x^y or x**y or a functional notation like pow(x,y). Such notations are often used even in normal text, but you should not expect people to know them in general without explanations, or find them natural. Notations like x Subscripting can often be removed without affecting the basic meaning, but if you need some replacement, an underscore might be best, writing ai as a_i when needed. 9.1.9.3. Suggested policy on subscripting and superscriptingThere is really no simple general answer to the question of whether you should use subscript and superscript characters or other methods, such as word processor commands or markup. Some guidelines can be given, though:
9.1.10. Characters and AccessibilityAccessibility means making content and services available to anyone irrespective of physical or mental disability. In a broader sense, accessibility means availability to anyone irrespective of variation between people and between the situations where they act. There are worldwide recommendations and national guidelines and even legal rules on accessibility, especially in the digital and networked environment. There are W3C recommendations on accessibility at http://www.w3.org/WAI/. In the U.S., the so-called Section 508 legislation makes accessibility considerations mandatory in some contexts that involve federal funding, see http://www.section508.gov/. 9.1.10.1. Characters in non-visual presentationThe most commonly presented example of accessibility is how to make web pages and other digital content available to the blind. Tools used for this usually involve speech synthesis: textual content is used as input to an automatic speech synthesizer, which reads the text audibly. The synthesizer may use metainformation presented in markup, for example, in order to read headings emphatically and to leave pauses between paragraphs. Alternatively, text could be presented via a Braille "display," which is a device that renders a character using a combination of dots (a Braille pattern) that can be sensed by the user's fingertips. These examples deal with a very narrow part of accessibility, but they illustrate well how accessibility deals with the character level, too. Unicode is oriented toward characters that are displayed visibly. The very character concept deals with elements of written text, even though it does not mandate a particular presentation. Strings of Unicode characters can, however, be presented in other ways, too. Speech synthesis needs much more than just characters. It must be strongly language-dependent to be correct or even to get close. Braille display works more directly at the character level, but different schemes exist for converting text to sequences of Braille patterns. Those patterns have been encoded into Unicode in a block of their own, but they are defined just as dot patterns, without assigning any specific character or other meaning to them. Therefore, Braille rendering is language-dependent, too. Both speech synthesis and Braille rendering were originally designed to handle a small repertoire of characters, such as a subset of ASCII characters. Therefore, you often have problems in such modes of rendering even for characters that work well in most visible presentations, like accented letters. In visible rendering, the user mostly has the option of changing the font in order to see whether some other font would work better. Perhaps he could even download additional fonts. In non-visual rendering, problematic characters might not be rendered at all, or they might be indicated by their names or numbers. 9.1.10.2. Understandability of charactersIn all modes of presentation, failures are possible since the user might not understand the character used, even if it is presented in a technically flawless way. If you write "5 µm," it is quite possible that the µ character gets messed up in the presentation, but even if it does not, the reader might simply not recognize and understand it. Similarly, the phonetic symbol ə, though widely used by linguists, is unknown to most people, so an essential part of a pronunciation instruction using it might not be understood at all. There is no simple cure for the problem. We need to be cautious, and we need to explain the special characters, as well as special notations, that we use. Unicode lets you use a huge number of characters, but most people understand just a small subset. Although the understandability of characters and the technical possibilities of rendering them are quite different aspects, they are interconnected in practice. If you use technically "safe" characters such as ASCII characters only, for example, the odds are that people understand the characters and that specialized software, like Braille devices, can handle them well. People and programs understand the "safe" characters because they are widely used in computers. Even if they don't know exactly what you mean by an asterisk, *, the character probably looks familiar to them. If you use a more fancy star-shaped Unicode character, like the black star 9.1.10.3. Explaining charactersWhen you use characters that are not widely known to your audience, you should try to explain them. Usually the explanations should be presented in normal textual content, perhaps in the copy text, perhaps in footnotes or some other way; the choice depends on how important the explanation is. Identifying characters by Unicode numbers or names or both can be useful in specialized technical contexts, but it can be alienating when writing for the general public. A mixed explanation like the following might be useful in a legend, though, if readers may need to use the character themselves and therefore need its Unicode identification:
In hypertext, you could make the "U+0259" a link to a more detailed technical description of the character, such as http://www.fileformat.info/info/unicode/char/0259/. |
 Save As and pick up the plain text format (*.txt), all the formatting information disappears; only the character data is saved.
Save As and pick up the plain text format (*.txt), all the formatting information disappears; only the character data is saved. Save As. Then, in the menu for file type selection, select "Encoded text or "Plain text" or something similar (depending on the version of Word). When you click on "Save" in the dialog, you will be prompted for the encoding. If you select ASCII, for example, Word performs some conversions like replacing "smart" quotes with "straight" quotes and dashes with hyphens. The replacements are rather coarse and mechanic, and for any tailored conversion, you need to use a separate converter or use the Find and Replace function of a word processor or a text editor.
Save As. Then, in the menu for file type selection, select "Encoded text or "Plain text" or something similar (depending on the version of Word). When you click on "Save" in the dialog, you will be prompted for the encoding. If you select ASCII, for example, Word performs some conversions like replacing "smart" quotes with "straight" quotes and dashes with hyphens. The replacements are rather coarse and mechanic, and for any tailored conversion, you need to use a separate converter or use the Find and Replace function of a word processor or a text editor. (1 - (v/c)2)." Moreover, this plain text representation uses characters that are not widely available in fonts, especially the subscript zero.
(1 - (v/c)2)." Moreover, this plain text representation uses characters that are not widely available in fonts, especially the subscript zero. (U+2660) might be represented using a tag for image embedding, <img src="/books/1/536/1/html/2/spade.gif alt="spades">, rather than the character as such or the character reference ♠. The image would need to represent the character in a size that matches the font size. Using a stylesheet (CSS), you could specify that the size be scaled so that it depends on the font size, but the scaling performed by browsers can be rather coarse. Moreover, it is difficult to make the embedded image appear smoothly as if it were a character; its shape and exact size might not match the font design, and the spacing around it may differ from normal character spacing.
(U+2660) might be represented using a tag for image embedding, <img src="/books/1/536/1/html/2/spade.gif alt="spades">, rather than the character as such or the character reference ♠. The image would need to represent the character in a size that matches the font size. Using a stylesheet (CSS), you could specify that the size be scaled so that it depends on the font size, but the scaling performed by browsers can be rather coarse. Moreover, it is difficult to make the embedded image appear smoothly as if it were a character; its shape and exact size might not match the font design, and the spacing around it may differ from normal character spacing. symbol." The symbols used in the examples actually exist in Unicode as characters (erase to the left U+232B and place of interest sign U+2318), but you might need to use symbols that have not been encoded in Unicode. You might also wish to use images for symbols that exist in Unicode but are not well supported in fonts or have shapes too different from what suit your needs.
symbol." The symbols used in the examples actually exist in Unicode as characters (erase to the left U+232B and place of interest sign U+2318), but you might need to use symbols that have not been encoded in Unicode. You might also wish to use images for symbols that exist in Unicode but are not well supported in fonts or have shapes too different from what suit your needs. (U+2551) or two copies of the medium vertical bar ❙ (U+2759). When limited to plain text, you could just explain the image verbally, perhaps using a very coarse approximation of the shape as an auxiliary hinte.g., "Looks somewhat like ||" (where || is just two copies of a common ASCII character, the vertical line U+007C).
(U+2551) or two copies of the medium vertical bar ❙ (U+2759). When limited to plain text, you could just explain the image verbally, perhaps using a very coarse approximation of the shape as an auxiliary hinte.g., "Looks somewhat like ||" (where || is just two copies of a common ASCII character, the vertical line U+007C). and
and  , look somewhat disproportionate. Their appearance in Arial (
, look somewhat disproportionate. Their appearance in Arial ( (U+02DC), but usually this involves differences other than just size. For many characters, there are narrow and wide forms, but this relates to East Asian typography that needs to adapt foreign characters to the principles of ideograph usage. Note that reduction of font size inside text has varying meanings, and this affects the kind of markup you would use for it; in English, reduced font size usually means less important text, while in some other writing systems, it means more important. Size variation may have other semantics, too.
(U+02DC), but usually this involves differences other than just size. For many characters, there are narrow and wide forms, but this relates to East Asian typography that needs to adapt foreign characters to the principles of ideograph usage. Note that reduction of font size inside text has varying meanings, and this affects the kind of markup you would use for it; in English, reduced font size usually means less important text, while in some other writing systems, it means more important. Size variation may have other semantics, too. y or power(x,y) might be somewhat more understandable, though the upward arrow
y or power(x,y) might be somewhat more understandable, though the upward arrow 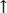 n, 2^n, 2**n, or super(2,n)).
n, 2^n, 2**n, or super(2,n)). (U+2605), in your text, it will not work technically in all circumstances, and it may make people wonder whether it is a typo or something. Therefore, make sure you have a good reason to take these risks.
(U+2605), in your text, it will not work technically in all circumstances, and it may make people wonder whether it is a typo or something. Therefore, make sure you have a good reason to take these risks.