Section 8.10. Mathematical and Technical Symbols
8.10. Mathematical and Technical SymbolsThere is a large and growing amount of characters that are used as special symbols in mathematical and technical texts, often in highly specialized meaning and context. The use of mathematical notations is increasingly common even in social sciences and humanities. Rules for usage are generally well established, though with some typographic and other variation. See, for example, the extensive international standard ISO 31-11, "Quantities and Units. Part 11: Mathematical signs and symbols for use in the physical sciences and technology." The MathWorld web site http://mathworld.wolfram.com illustrates and explains the conventional mathematical notations. In Unicode, digits and other numeric symbols appear in different script-specific blocks, including Basic Latin, of course. There are also some very commonly used mathematical operators and other symbols in blocks like Basic Latin, Latin-1 Supplement, and General Punctuation. In addition to these, there are several blocks for mathematical and technical symbols, allocated in a rather confusing way for historical reasons. An overview of this situation is given in Table 8-13. For more information, consult the Unicode Technical Report 25, "Unicode Support for Mathematics," http://www.unicode.org/reports/tr25/.
8.10.1. Superscripts and SubscriptsSuperscripts are used partly as stylistic variation, as in writing "first" as "1st" and not "1st." On the other hand, superscripting is used to indicate exponentiation and other semantic relations; for example, "23" is certainly not just a stylistic variant of "23." Subscripting is mostly a matter of established notational convention, as in "H2O." Both superscripting and subscripting are mostly something applied to character data, rather than part of the data itself. However, largely reflecting the practices of older character codes, Unicode contains some characters that are superscript or subscript variants of other characters, usually defined as compatibility equivalents. Many of them are letters, such as masculine ordinal indicator º (U+00BA), which is a superscript letter "o," and modifier letter small "h" ʰ (U+02B0), which is a phonetic symbol. Superscript variants that can be used for mathematical purposes exist in Unicode for digits 09, letters "i" and "n," plus and minus sign, equals sign, and normal parentheses. For historical reasons, superscript variants of 1, 2, and 3 are not in the Superscripts and Subscripts block but in the Latin-1 Supplement. Subscript variants exist for digits 09, plus and minus sign, equals sign, and normal parentheses. Thus, you could write relatively complicated superscripts or subscripts. However, this is not very common and it would not take you very far. You would inevitably meet restrictions in writing superscript or subscript expressions. Normally other methods are used, such as markup languages or special formatting, as discussed in Chapter 9. 8.10.2. The Number Forms BlockThe Number Forms block covers the range from U+2150 to U+218F and contains some relatively uninteresting characters, which are special presentations of some numerals. Almost all of them are compatibility characters. Currently the block contains only characters for Roman numerals and for some vulgar (common) fractions . 8.10.2.1. Roman numeralsThe characters for Roman numerals are not meant to be used in normal text. Instead of U+2612 Roman numeral three, Ⅲ, you normally use a sequence of capital letters, "III." The special characters for Roman numerals have been included in Unicode for compatibility with other character codes. It has been argued, though, that the special characters for Roman numerals might be preferable due to their more specific semantics. The character U+2610 Roman numeral one unambiguously denotes a number, while the Latin capital letter "I" has multiple uses. A speech generator, for example, would in principle be in a much better position to decide how to pronounce the notation. But this will probably remain just theory. 8.10.2.2. FractionsFractional numbers such as 1/4 (one fourth) are commonly written in linearized notation, using normal digits and a normal solidus (slash) character. However, in typesetting traditions, fractions are often presented in a different style, perhaps using special glyphs, like ¼. There are two basic variants of the style: "shilling" fractions, where the numerator and denominator are separated by a slanted slash, and "vertical" fractions, where the numerator is right above the denominator and there is a horizontal line between them. Some frequently used fractions have been included into Unicode as separate characters. For example, there is the character U+00BC, vulgar fraction one fourth (¼), which is compatibility equivalent to the three-character sequence 1/4. In most fonts, the appearance is "shilling" fraction. The only such fractions in ISO Latin 1 are ½, ¼, and ¾. They appeared in some typewriter keyboards and may still appear in some computer keyboards. Moreover, when you type, say, the characters 1/4 in succession, your word processor might convert the sequence to ¼, as described in Chapter 2. This can be undesirable especially if your document contains other fractions, like 1/3, which would appear in a quite different style. In Unicode, the Number Forms block contains a few more fraction characters, namely for 1/3, 2/3, 1/5, 2/5, 3/5, 4/5, 1/6, 5/6, 1/8, 3/8, 5/8, 7/8, as well as for numerator one (1/). However, only a few fonts contain glyphs for them. As a different approach, you could use the U+2044 fraction slash character. This character, absent in many fonts, has an appearance similar to that of the common solidus, though it is often more slanted, even in an 45° angle, as in ⁄. More important, it has special semantics, as suggested by its name. It unambiguously separates the numerator and the denominator of a fraction and never has any other meaning. Moreover, a program that is capable of rendering fractions in a classic typographic style should do that automatically. However, such behavior is not common in programs. In MS Word, you probably get just something like the following: 1⁄4 (i.e., normally rendered 1 and 4 separated with the fraction slash). Thus, if you wish to produce typographically formatted fractions, you mostly need tools above the character level, such as typesetting commands. The web page "How to create fractions in Word," http://word.mvps.org/FAQs/Formatting/CreateFraction.htm, illustrates some techniques in producing both "vertical" fractions and "shilling" fractions. 8.10.3. Characters in SI NotationsThis subsection discusses the character-level issues of presenting values of physical quantities according to the SI, the International System of Units (Système international). For general information on the SI, please refer to the Metric System FAQ http://www.cl.cam.ac.uk/~mgk25/metric-system-faq.txt. Note especially its item 1.12, "What is the correct way of writing metric units?," which also mentions some practical typing methods not discussed here. The organization responsible for the definition of SI units is the General Conference on Weights and Measures (CGPM), http://www.bipm.org/en/convention/cgpm/. Official information is also available from the Bureau International des Poids et Mesures (BIPM), see http://www.bipm.org/en/si/, and the National Institute of Standards and Technology (NIST), see http://physics.nist.gov/cuu/Units/. There are also international ISO standards and national standards on the use of the SI. 8.10.3.1. Conceptual levels of SI notationsThe use of the SI can be considered at different levels, which are defined by different standards, conventions, and other norms:
Here we mostly consider the last but one level, characters, or abstract characters to be more exact. 8.10.3.2. Notes on individual charactersMost characters used in SI notations can easily be identified as abstract characters, or more specifically, as Unicode characters. For example, the symbol of the meter, "m," is apparently the character named Latin small letter "m" in Unicode, with the code position 6D in hexadecimal, therefore it's often denoted by U+006D in Unicode contexts. But the following characters need to be considered:
8.10.3.3. Letterlike symbols and the SIPeople interested in unit symbols and Unicode have become surprised when they have found that, for example, the unit "degree Celsius" has a symbol of its own, U+2103, presenting °C as a single character. Similarly, for degree Fahrenheit (a completely non-SI unit of course), there is U+2109; for siemens, U+2127; and for Kelvin, U+212A, for example, in the Letterlike Symbols block. Educated people may well think that it is better to use such specific characters, with limited semantics, especially if dealing with documents that might be read by a text-to-speech converter later on, or otherwise processed by software that might use semantic information about characters. They might also be seen as typographically suitable, since they allow detailed formatting that corresponds to the specific meanings. But in addition to being poorly supported in most fonts, such characters are inadequate in principle, by Unicode rules. For example, degree Celsius U+2103 is compatibility equivalent to U+00B0 U+0043 (i.e., degree sign followed by letter C). It has little to do with typographic correctness. Rather, it is a matter of compatibility, so that data containing that character in some non-Unicode encoding can be encoded in Unicode without losing the distinction between that character and the U+00B0 U+0043 pair, should someone wish to retain that distinction. This means that the data can also be converted back to the original encoding and get the original data exactly. It is not recommended for use in new, originally Unicode data. The Unicode standard says, in the discussion of unit symbols :
Unfortunately, the Unicode standard has wrong information about the symbol for the liter. The official position in the SI system is that both "l" and "L" are allowed, with no expressed preference (although in the U.S., "L" is preferred by national authorities). The special letterlike characters discussed here were taken into Unicode due to their presence in some character codes used in East Asia, such as the Japanese JIS X 0212. These characters do their job in allowing conversions between character codes without losing information. Problems arise when people use utilities like the Character Map (described in Chapter 2) without knowing the background and looking just at the characters and their names. To conclude, it is acceptable and recommendable to use normal Latin letters as SI unit symbols, such as "K" for kelvin. |
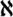
 ,
, 
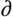 , ∆,
, ∆,  ,
,  ,
, 
 , ▲,
, ▲,  , ◙
, ◙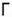 ,
,  ,
,  ,
, ,
,  ,
, 
 ,
,  ,
, 
 ,
,  ,
,  , ⌚
, ⌚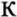
 for kilogram in Russian.
for kilogram in Russian. s
s (U+2126, in the Symbols Area). It has a specific meaning, but it is defined as canonical equivalent to Greek capital letter omega Ω (U+03A9), and the Unicode standard recommends using the latter. The ohm sign has somewhat wider support in fonts. If a font contains both, they may look somewhat different.
(U+2126, in the Symbols Area). It has a specific meaning, but it is defined as canonical equivalent to Greek capital letter omega Ω (U+03A9), and the Unicode standard recommends using the latter. The ohm sign has somewhat wider support in fonts. If a font contains both, they may look somewhat different. is not an approved symbol for the liter." Such confusions will be separately discussed in the next section.
is not an approved symbol for the liter." Such confusions will be separately discussed in the next section.