Section 1.7. Encoding Characters as Octet Sequences
1.7. Encoding Characters as Octet SequencesWhen we need to store character data on a computer, we might consider storing it in an exact visual shape. Some people would call this a very naive idea, but it is in fact quite feasible, even necessaryfor some purposes. If you have an old manuscript to be stored digitally, you need to scan it with high resolution and store it in some image format. Sometimes you would do that for individual characters as well. On web pages, for example, it is common to use images containing text for logos, menu items, buttons, etc., in order to produce a particular visual appearance. Figure 1-10. Using Windows Notepad, a simple plain text editor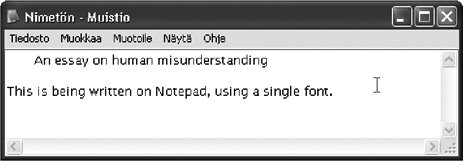 For most processing of texts on computers, however, we need a more abstract presentation. It would be highly impractical to work on scanned images of characters in storing and transferring text, not to mention comparing strings for example. We do not want to do the process of recognizing a character's identity every time we use the character. Instead, we use characters as atoms of information, identified by their code numbers or some other simple way. This is really what "abstract characters" are about. 1.7.1. Plain Text and Other Formats for TextPlain text is a technical term that refers to data consisting of characters only, with no formatting information such as font face, style, color, or positioning. However, formatting such as line breaks and simple spacing using space characters may be included, to the extent that it can be expressed using control characters only. Moreover, all characters are to be taken as such, without interpreting them as formatting instructions or tags. For example, HTML or XML is not plain text. Plain text is a format that is readable by human beings when displayed as such. The reader needs to know the human language used in the text, of course. The display of plain text depends on the font that happens to be used. This can often be changed within a program, but such settings change the font of all text. (As an exception, if the font chosen does not contain all the characters used in the text, a clever program might use other fonts as backup for missing characters.) Plain text is a primitive format, but it is extremely important. In processing texts, the ultimate processing such as searching, comparison, editing, or automatic translation takes place at the plain text level. Databases often use plain text format for strings for simplicity, even though data extracted from them is presented as formatted. Plain text is universal, since no special software is needed for presenting it, as long as a suitable font can be used. In Windows, you can use Notepad, the very simple editor, to write and display plain text, as illustrated in Figure 1-10. There are many plain text editors, some of which contain fairly sophisticated processing tools. However, their character repertoire is often very small. Plain text is commonly used, and normally should be used, in email, Internet discussion forums, simple textual documents (like readme.txt files shipped with software), and many Figure 1-11. Using Microsoft Word, a text-processing program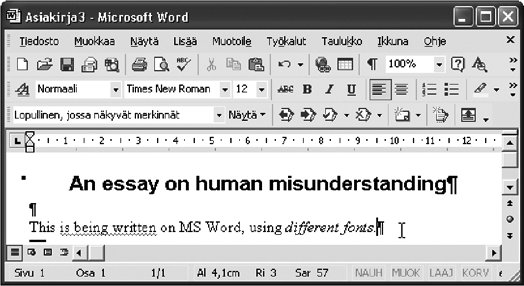 other purposes. For example, the RFC (Request for Comments) series of documents, describing the standards, protocols, and practices on the Internet, have ASCII plain text as their format. The phrase "ASCII file" or "ASCII text" is often used to denote plain text in general, even in contexts where ASCII is obviously not used and could not be used. This is because ASCII has been used so long and so widely, and quite often "ASCII" is mentioned as an opposed to anything that is not plain text (e.g., "ASCII" versus "binary" transfer). Text-processing programs such as Microsoft Word normally process and store text data in a format that is somehow "enhanced" with formatting and other information. This includes the use of different fonts for different pieces of text, specific positioning and spacing, and invisible metadata ("data about data") such as author name, program version, and revision history. Figure 1-11 illustrates the use of Microsoft Word. If you create a file containing just the word "Hello" using a plain text editor, the file size will be five octets, or maybe 10 octets, depending on encoding. If you do the same using a text-processing program such Microsoft Word, you might get, for example, a file size of 24 kilobytes (24,576 octets), because a text-processing program inserts a lot of basic information in its internal format, in addition to the text itself and some information about its appearance (font face and size). This means that if you accidentally open a Word file in a plain text editor or process it with a program prepared to deal with plain text only, you get a mess. This is illustrated in Figure 1-12, which contains a Word document with just the text "This is a simple document." written into it, opened in Notepad. Similar considerations apply to widely used document formats such asPDF (Portable Document Format). There are also intermediate formats, which contain text and formatting information, such asRTF (Rich Text Format). It was designed for purposes like exchanging text data between different text-processing programs. Figure 1-12. Part of a Word document accidentally opened in Notepad If you are not familiar with the idea of formats like plain text, Word format (often called ".doc format" due to the common filename extension), and RTF, you could launch your favorite text-processing program. Write a short document and save it, and then use the "Save As" option in the "File" menu (or equivalent), and study and test the alternative save formats you find there. Save the document in each format in the same folder, and then view the contents of the folder, with file sizes displayed. You might then see what happens if you open each format in a text editor like Notepad, just to get a general idea. Such exercises will prepare you to deal with requests like "Please send your proposal in RTF format." This will also aid you in recognizing situations like receiving an RTF file when you have asked for something else. 1.7.2. Bytes and OctetsIn computers and in data transmission between themi.e., in digital data processing and transferdata is internally presented as octets, as a rule. An octet is a small unit of data with a numerical value between 0 and 255, inclusively. The numerical values are presented in the normal (decimal) notation here, but other presentations are widely used too, especially octal (base 8) or hexadecimal (base 16) notation. The hexadecimal values of octets thus range from 0 to FF. Internally, an octet consists of 8 bitshence the name, from Latin octo "eight." A bit, or binary digit, is a unit of information indicating one of two alternatives, commonly denoted with the digits 0 and 1 in writing but internally represented by some small physical entity that has two distinguishable states, such as the presence or absence of a small hole or magnetization. The digits 0 and 1 that symbolize the values are also called bits (0 bit, 1 bit). When a bit has the value 1, we often say that the bit has been set. In character code contexts, we rarely need to go into bit level. We can think of an octet as a small integer, usually without thinking how it is internally represented. However, in some contexts the concept of most significant bit (MSB), also called first bit or sign bit is relevant. If the most significant bit of an octet is set (1), then in terms of numerical values of octets, the value is greater than 127 (i.e., in the range 128255). In various contexts, such octets are sometimes interpreted as negative numbers, and this may cause problems, unless caution is taken. The word "byte" is more common than "octet," but the octet is a more definite concept. A byte is a sequence of bits of a known length and processed as a unit. Nowadays it is almost universal to use 8-bit bytes, and therefore a distinction between a byte and an octet is seldom made. However, in character code standards and related texts, the term octet is normally used. There is nothing in an octet that tells how it is to be interpreted. It is just a bit pattern, a sequence of eight 0s or 1s, with no indication of whether it represents an integer, a character, a truth value, or something else. For example, the octet with value 33 in decimal, 00010001 in binary (as bits), could represent the exclamation sign character !, or it could mean just the number 33 in some numeric data. It could well be just part of the internal representation of a number or a character. Information about the interpretation needs to be kept elsewhere, or implied by the definition of some data structure or file format. 1.7.3. Character EncodingsA character encoding can be defined as a method (algorithm) for presenting characters in digital form as sequences of octets. We can also say that an encoding maps code numbers of characters into octet sequences. The difference between these definitions is whether we conceptually start from characters as such or from characters that already have code numbers assigned to them. There are hundreds of encodings, and many of them have different names. There is a standardized procedure for registering an encoding, and this means that a primary name is assigned to it, and possibly some alias names. For example, ASCII, US-ASCII, ANSI_X3.4-1986, and ISO646-US are different names for an encoding. There are also many unregistered encodings and names that are used widely. The Windows Latin 1 encoding, which is very common in the Western world, has only one registered name, windows-1252, but it is often declared as cp-1252 or cp1252. The case of letters is not significant in character encoding names. Thus, "ASCII" and "Ascii" are equivalent. Hyphens, on the other hand, are significant in the names. 1.7.4. Single-Octet EncodingsFor a character repertoire that contains at most 256 characters, there is a simple and obvious way of encoding it: assign a number in the range 0255 to each character and use an octet with that value to represent that character. Such encodings, called single-octet or 8-bit encodings, are widely used and will remain important. There is still a large amount of software that assumes that each character is represented as one octet. Various historical reasons dictate the assignments of numbers to characters in a single-octet encoding . Usually letters AZ are in alphabetic order and digits are in numeric order, but the assignments are otherwise more or less arbitrary. Besides, any extra Latin letters, as used in many languages, are most probably assigned to whatever positions that were "free" in some sense. Thus, if you compare characters by their code numbers in a single-octet encoding, you will generally not get the right alphabetic ordering by the rules of, for example, French or German. 1.7.5. Multi-Octet EncodingsAs you may guess, the next simpler idea of using two octets for a single character has been invented, formalized, and used. It is not as common as you might suspect, though. A simple two-octet encoding is sufficient for a character repertoire that contains at most 65,536 characters. An octet pair (m,n) represents the character with number 256 x m + n. Alternatively, we can say that the number is represented by its 16-bit binary form. This makes processing easy, but there are two fundamental problems with the idea:
Thus, encodings that use a variable number of octets per character are more common. The most widely used among such encodings is UTF-8 (UTF stands for Unicode Transformation Format), which uses one to four octets per character. For those writing in English, the good news is that UTF-8 represents each ASCII character as one octet, so there is no increase in data size unless you use characters outside ASCII. If you accidentally view an UTF-8 encoded document in a program that interprets the data as ASCII or windows-1252 encoded, you will notice no difference as long as the data contains ASCII only. In fact, any ASCII data can trivially be declared as UTF-8 encoded as well. If the data contains characters other than ASCII, they would in this case be displayed each as two or more characters, which have no direct relationship with the real character in the data. This is because consecutive octets would be interpreted as each indicating a character, instead of being treated according to the encoding as a unit. 1.7.6. The "Character Set" ConfusionCharacter encodings are often called character sets, and the abbreviation charset is used in Internet protocols to denote a character encoding. This is confusing because people often understand "set" as "repertoire." However, character set means a very specific internal representation of characters, and for the same repertoire, several different "character sets" can be used. A character set implicitly defines a repertoire, though: the collection of characters that can be represented using the character set. It is advisable to avoid the phrase "character set" when possible. The term character code can be used instead when referring to a collection of characters and their code numbers. The term character encoding is suitable when referring to a particular representation. For example, the word "ASCII" can mean a certain collection of characters, or that collection along with their code numbers 0127 as assigned in the ASCII standard, or even more concretely, those code numbers (and hence the characters) represented using an 8-bit byte for each character. Figure 1-13. An extract from a Save As dialog in Notepad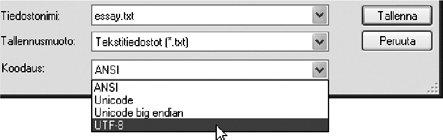 |