Section 1.5. Definitions of Character Repertoires
1.5. Definitions of Character RepertoiresThe implementation of Unicode support is a long and mostly gradual process. Unicode can be supported by programs on any operating systems, although some systems may allow much easier implementation than others; this mainly depends on whether the system uses Unicode internally so that support to Unicode is built in. Even in circumstances where Unicode is supported in principle, the support usually does not cover all Unicode characters. For example, an available font may cover some part of Unicode that is only practically important in some area. When text data produced in one program is to be processed in another, we should be prepared for difficulties with any unusual characters. For data transfer, it is essential to know which Unicode characters the recipient is able to handle. Thus, although Unicode contains a huge number of characters, not all of them can be used safely. Among the 100,000 or so characters, usually only a small subset can be used in a particular application and context without a serious risk of distorting information. 1.5.1. Formally Defined RepertoiresEach character code, by itself, defines a character repertoire: the collection of characters that can be represented in the code. In addition to this, subsets of such collections can be defined. A character repertoire is any collection of characters, without implying any particular implementation even at the level of code numbers. However, in practice, the simplest way to define a character repertoire is to use Unicode as the basis and simply list the code numbers. Such a definition specifies a closed collection, which does not change if the Unicode standard is enhanced. In contrast, by listing a set of Unicode blocks you define anopen collection, which is fixed at any given moment of time but will automatically expand if new characters are added to any of those blocks in a revision of the Unicode standard. For example, there are three Multilingual European Subsets (MES-1, MES-2, MES-3), defined in a CEN Workshop Agreement, CWA 13873. Among them, MES-2 is the most important. It is a closed collection, covering Latin, Greek, and Cyrillic scripts. The CWA is available at http://www.evertype.com/standards/iso10646/pdf/cwa13873.pdf or via http://www.cenorm.be/cenorm/businessdomains/businessdomains/isss/cwa/. 1.5.2. Practical RepertoiresIn addition to international standards, there are company policies that define various subsets of the character repertoire. A practically important one, especially in regards to support in widely used fonts, is Microsoft's "Windows Glyph List 4" (WGL4), also known as "PanEuropean" character set, listed on the page "Using special characters from Windows Glyph List 4 (WGL4) in HTML" at http://www.alanwood.net/demos/wgl4.html. Contrary to what you might expect, the characters in it have not all been included in MES-2. In data-processing contexts, a character can be considered "safe" if it is certain or very probable that it will be correctly transmitted and presented to the recipient. In a broader sense, being safe entails more: the sender should be sure of the character he means, and the recipient should understand it correctly. Mostly, however, we consider the technical problems: difficulties in presenting the character in a digital form, in sending it over network connections and possibly to a different program and operating environment, and in rendering it visually. Nowadays, it's usually the last phase that poses most problems. From a practical point of view, we can distinguish the following repertoires of characters. Each repertoire listed here contains all the previous repertoires. The list can be useful when you design an application, or instructions on writing things, or a computer language. When selecting which repertoire you use or support, it is advisable to proceed slowly in the list and consider whether the usefulness of extra characters outweighs the risks. The names used for the repertoires here are practical descriptions, not official names. They make liberal use of encoding names, which will be described in more detail in Chapter 3.
To illustrate the repertoire of characters that is reasonably "safe" in many situations, Table 1-2 shows all WGL4 characters. This is just an overview. Many of the characters cannot be identified by their shape only. The classification of the characters used in the table is a practical one, rather thanformal.
|
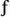
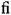

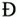




 ßſ
ßſ

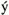 ÿ
ÿ
















 Ĕ
Ĕ












 ģ
ģ






 Ĭ
Ĭ





























 Ŏ
Ŏ












































 ǺǻǼǽǾǿẀẁẂẃẄẅỲỳ
ǺǻǼǽǾǿẀẁẂẃẄẅỲỳ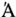







 αβγδε ζηθικλμνξοπρ
αβγδε ζηθικλμνξοπρ στυφχψω
στυφχψω









 ·΄΅
·΄΅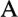


























































































 Ґґ
Ґґ ‗
‗ 
 •
• 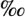 ' " ‼ ‾ ⁄
' " ‼ ‾ ⁄ ~ § ¯ ¶ · °
~ § ¯ ¶ · °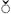 ˉ
ˉ 





 ™ µ
™ µ  ℮
℮




 ↨
↨



 ¬
¬  ∆
∆ 
 ∕ ∙
∕ ∙ 














































 ▌ ▐
▌ ▐ 

 ▲ ► ▼ ◄
▲ ► ▼ ◄
 ▫ ▬
▫ ▬  ● ◘ ◙ ◦
● ◘ ◙ ◦ 





 ♪ ♫
♪ ♫