The Sed Stream Editor
|
| < Day Day Up > |
|
The sed stream editor is not new to the UNIX programmer community. Because most of the initial Linux community was comprised of UNIX-based professionals, they were familiar with the sed editor which, like many other UNIX tools, is available on the Linux platform. The sed editor works on streams rather than (interactive) screens. The basic input and output are handled through I/O streams. Figure 3.4 shows the entities involved in the process of using the sed editor in a typical scenario. The source to be edited is read through the input stream, along with a script file containing instructions telling the editor what to do on the input data. We prepare the instructions in sed syntax and format. The output from the sed editor is redirected to the output stream (or standard output). Because the editor uses the input and output streams, the input can be coming from a pipe attached to the output of another command, and similarly the output can be redirected to a pipe attached to the input stream of another command. The pipes are a very convenient IPC (interprocess communication) phenomena and are discussed in Chapter 9 in more detail. They are used to connect input and output streams between commands (or custom applications).
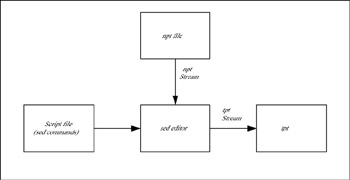
Figure 3.4: How the sed editor works.
The sed editor is built upon the principles introduced by the ed line editor. The ed line editor is interactive but works only on one line at a time. It is not discussed in the book because the vi screen editor is more commonly used, and the interactive screen editing is faster and easier than interactive line editing. Although the sed editor works on one line at a time, because there is no user intervention in the editing process, the question of inconvenience does not arise. In addition, the sed editor does not suffer from insufficient memory problems because it works on one line at a time (unlike the vi and Emacs editors, which open the whole file into the buffer). However, the sed editor is not suitable for creating a new file because it is not interactive. It is also not suitable for making minor corrections in a file. It is most useful where repetitive and monotonous edits are to be performed on large files and large number of files. In simple words, it is useful for performing text transformations and where such transformations are programmable (or scriptable). The following discussion will help the readers to understand the principles behind using the sed editor. However, all the features of the editor are not going to be discussed here, and the user is encouraged to check manual pages or other documentation for more information.
How Does It All Work?
Let us consider a sample program segment and examine different ways of using the sed command. The program segment shown here is incomplete, and if you try to compile, it will fail. The purpose of this piece of code is to demonstrate the use of the sed command. This code is saved in a file named sample_in.cpp.
if (c_LCount == 2 || f_dest_index == 1) { f_temp = GetStr(f_source_index); DelStr(f_source_index); InsStr(1, f_temp); return; } if (f_dest_index >= c_LCount) { f_temp = GetStr(f_source_index); DelStr(f_source_index); AddStr(f_temp); return; } Now let us execute the following command and see the results.
$ sed 's/index/INDEX/' sample_in.cpp
The command name is followed by an instruction enclosed in single quotes and then by the input file name. Notice that the instruction is itself a subcommand, where the s is the substitution instruction, followed by <pattern1> and <pattern2>, each separated by the forward slash character, /. The <pattern1> should be replaced by the <pattern2>. The instruction is completed by an ending forward slash. The sed command edits each line where the <pattern1> is found, in this case the word ‘index’, and replaces it by the <pattern2>, in this case the word ‘INDEX’. The result is displayed in the following listing.
if (c_LCount == 2 || f_dest_INDEX == 1) { f_temp = GetStr(f_source_INDEX); DelStr(f_source_INDEX); InsStr(1, f_temp); return; } if (f_dest_INDEX >= c_LCount) { f_temp = GetStr(f_source_INDEX); DelStr(f_source_INDEX); AddStr(f_temp); return; } The interesting feature is that the results are output to the standard output without modifying the input file. If we need to capture the results to a file, we have to redirect the output to a file, as shown here.
$ sed 's/index/INDEX/' sample_in.cpp > sample_out1.cpp
When this command is executed, the output is saved to the file ‘sample_out1.cpp’. An important point to note is that the instruction part of the command does not always have to be enclosed in quotes. However, when there are embedded spaces or special characters as part of the patterns, it is necessary to enclose the instruction in quotes; otherwise the instruction is broken into multiple parts and conveys a different meaning to the sed command or even to the Linux shell that is executing the command. Therefore, it is a good practice to always enclose the instruction in quotes. In this way, we can be sure that we always convey the right message to the command.
As mentioned earlier, sed instructions are scriptable. This means that the instructions can be put in a script file and pass it at the command-line with –f option, as shown here.
$ sed –f <script.in> sample_in.cpp > sample_out2.cpp
In this command, the script file script.in contains the sed instructions, which we used to give at the command line. The sample_out2.cpp is the output file that contains the edits made by sed as instructed in the script file. With script files, we can put more than one instruction in the file. This is a distinct advantage over the command-line execution. (Although command-line execution also lets us specify more than one instruction, it is really not as convenient). The sed editor reads the source input file line-by-line, and on each line applies all the instructions from the script file sequentially. Therefore, we have to be careful to provide sequential instructions in the script file. After applying the first instruction, the input line is changed and the second instruction is applied on the changed line, and then the third instruction is applied on the second version of the changed line, and so on. The contents of the original line would be lost after the very first change. After all the instructions are applied on the currently buffered line, then the next line is read into the buffer, and all the instructions are applied in the sequence from first to last. This process continues until all the lines in the input file are edited. This may seem uncomfortable to those using the sed editor for the first time, but the most important feature is that our input file is preserved from being overwritten with the edits (provided we take the precaution of not directing the standard output to the original file). The buffer into which sed reads a line (thus making it the current line) is also called the pattern space.
As an example, create the ‘script.in’ file with the following instructions, and execute the sed command as mentioned before with the –f option.
S/index/INDEX/g s/f_source/fSource/g s/f_dest/fDest/g
The output of the command, as stored in the sample_out2.cpp file, looks as given here.
if (c_LCount == 2 || fDest_INDEX == 1) { f_temp = GetStr(fSource_INDEX); DelStr(fSource_INDEX); InsStr(1, f_temp); return; } if (fDest_INDEX >= c_LCount) { f_temp = GetStr(fSource_INDEX); DelStr(fSource_INDEX); AddStr(f_temp); return; } The sed instructions are also known as commands. The sed commands may be optionally preceded by an address (an absolute address or a pattern that could evaluate to an address), as in [address]command. Here, the square brackets are used to denote that the address is optional and not in the sense that was conveyed by the pattern matching rules discussed earlier. If an address precedes the sed command, sed applies the command only to the lines that fall within the address. If there is no address, the command is applied to all the lines in the input file. Please note that each of the commands in the script file may be governed by the addressing system, if desired, as shown in the example that follows. Table 3.9 displays the most commonly used sed commands and their description.
| Command Character(s) | Command Description |
|---|---|
| d | Deletes the current line in the pattern space. |
| [n]d | Deletes the nth line in the input stream. |
| [n,]d | Deletes to the end of stream from the nth line in the input stream. |
| $d | Deletes the last line of the input stream. |
| s/<pattern1>/ | This is a substitution command and is most widely used <pattern2>/ in the edit process. The sed editor replaces (or substitutes) the pattern1 (or the pattern evaluated from the corresponding regular expression) with the pattern2 in the line currently in the pattern space. n Immediately outputs the content of the pattern space (the current line) and reads the next line of input into the pattern space. |
| N | Reads the next line of input into the pattern space without outputting the current line, thus converting the single-line pattern space into multiline pattern space. |
| i \<text><\n> | Inserts the specified text and the newline character. Please note that \n represents the newline character, which is automatically inserted into the script file by pressing the RETURN key. |
| a \<text><\n> | This command will append the specified text and the newline character. |
| q | Quits the script file without further processing the input stream. |
| # comment | Commands can be added to the sed script files for documentation purposes. Everything typed after the # sign and up to the next newline character is identified as comment and not processed by the sed editor. |
| : <label> | Labels are used to introduce branching logic into the script files. The b command or the t command uses these labels for the purpose of branching. |
| b [label] | This is an unconditional branch command. The sed editor branches to the specified label. If the label is not specified, it branches to the end of the script, skipping all the commands after this and to the end of script file. |
| t [label] | This is a test and (conditional) branch command. If the previous substitution command (or the s command) was successful, then it branches to the specified label. If the label is not specified, it branches to the end of the script, skipping all the commands after this and to the end of script file. |
| {c1<\n>c2\n…} | Multiple commands can be grouped within the curly braces. If an address specifier precedes the group, then all the commands are applied to the lines affected by the address specifier. It is to be noticed that the <\n> indicates a newline character typed in the script file, which means that the commands have to be typed on subsequent lines. |
To see the impact of the last command in the table coupled with an address range, change the contents of the script file as follows.
3,${ s/index/INDEX/g s/f_source/fSource/g s/f_dest/fDest/g } The address specifier 3,$ indicates that the commands grouped within the curly braces must be applied to the third line onward to the end of the input file (as the $ symbol indicates end of file). When the sed command is executed (as shown earlier with the –f option), the following output is thrown to the output file.
if (c_LCount == 2 || f_dest_INDEX == 1) { f_temp = GetStr(f_source_INDEX); DelStr(fSource_INDEX); InsStr(1, f_temp); return; } if (fDest_INDEX >= c_LCount) { f_temp = GetStr(fSource_INDEX); DelStr(fSource_INDEX); AddStr(f_temp); return; } An examination of the output shows that the first two lines are not affected by the edits applied by the sed editor, as instructed in the script file. What has been discussed in this section is only to help you to understand how powerful the sed editor is. It is up to you to try the examples and to test the strength of the command. For more details on the command, you are advised to go through the manual pages or any other documentation on the sed editor.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 86