9.4 Motivation for Communicators
|
9.4 Motivation for Communicators
Communicators in MPI serve two purposes. The most obvious purpose is to describe a collection of processes. This feature allows collective routines, such as MPI_Bcast or MPI_Allreduce, to be used with any collection of processes. This capability is particularly important for hierarchical algorithms. It also facilitates dividing a computation into subtasks, each of which has its own collection of processes. For example, in the manager-worker example in Section 8.2, it may be appropriate to divide each task among a small collection of processes, particularly if this causes the problem description to reside only in the fast memory cache. MPI communicators are perfect for this; the MPI routine MPI_Comm_split is the only routine needed when creating new communicators. Using ranks relative to a communicator for specifying the source and destination of messages also facilitates dividing parallel tasks among smaller but still parallel subtasks, each with its own communicator.
A more subtle but equally important purpose of the MPI communicator involves the communication context that each communicator contains. This context is essential for writing software libraries that can be safely and robustly combined with other code, both other libraries and user-specific application code, to build complete applications. Used properly, the communication context guarantees that messages are received by appropriate routines even if other routines are not so careful. Consider the example in Figure 9.8 (taken from [48, Section 6.1.2]). In this example, two routines are provided by separate libraries or software modules. One, SendRight, sends a message to the right neighbor and receives from the left. The other, SendEnd, sends a message from process 0 (the leftmost) to the last process (the rightmost). Both of these routines use MPI_ANY_SOURCE instead of a particular source in the MPI_Recv call. As Figure 9.8 shows, the messages can be confused, causing the program to receive the wrong data. How can we prevent this situation? Several approaches will not work. One is to avoid the use of MPI_ANY_SOURCE. This fixes the example, but only if both SendRight and SendEnd follow this rule. The approach may be adequate (though fragile) for code written by a single person or team, but it isn't adequate for libraries. For example, if SendEnd was written by a commercial vendor and did not use MPI_ANY_SOURCE, but SendRight, written by a different vendor or an inexperienced programmer, did use MPI_ANY_SOURCE, then the program would still fail, and it would look like SendEnd was at fault (because the message from SendEnd was received first).
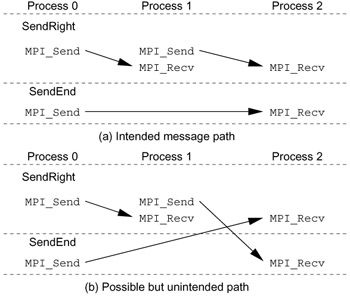
Figure 9.8: Two possible message-matching patterns when MPI_ANY_SOURCE is used in the MPI_Recv calls (from [48]).
Another approach that does not work is to use message tags to separate messages. Again, this can work if one group writes all of the code and is very careful about allocating message tags to different software modules. However, using MPI_ANY_TAG in an MPI receive call can still bypass this approach. Further, as shown in Figure 6.5 in [48], even if MPI_ANY_SOURCE and MPI_ANY_TAG are not used, separate code modules still can receive the wrong message.
The communication context in an MPI communicator provides a solution to these problems. The routine MPI_Comm_dup creates a new communicator from an input communicator that contains the same processes (in the same rank order) but with a new communication context. MPI messages sent in one communication context can be received only in that context. Thus, any software module or library that wants to ensure that all of its messages will be seen only within that library needs only to call MPI_Comm_dup at the beginning to get a new communicator. All well-written libraries that use MPI create a private communicator used only within that library.
Enabling the development of libraries was one of the design goals of MPI. In that respect MPI has been very successful. Many libraries and applications now use MPI, and, because of MPI's portability, most of these run on Beowulf clusters. Table 9.1 provides a partial list of libraries that use MPI to provide parallelism. More complete descriptions and lists are available at www.mcs.anl.gov/mpi/libraries and at sal.kachinatech.com/C/3. Chapter 12 discusses software, including MPI libraries and programs, in more detail.
| Library | Description | URL |
|---|---|---|
| PETSc | Linear and nonlinear solvers for PDEs | www.mcs.anl.gov/petsc |
| Aztec | Parallel iterative solution of sparse linear systems | www.cs.sandia.gov/CRF/aztec1.html |
| Cactus | Framework for PDE solutions | www.cactuscode.org |
| FFTW | Parallel FFT | www.fftw.org |
| PPFPrint | Parallel print | www.llnl.gov/CASC/ppf/ |
| HDF | Parallel I/O for Hierarchical Data Format (HDF) files | hdf.ncsa.uiuc.edu/Parallel_HDF |
| NAG | Numerical library | www.nag.co.uk/numeric/fd/FDdescription.asp |
| ScaLAPACK | Parallel linear algebra | www.netlib.org/scalapack |
| SPRNG | Scalable pseudorandom number generator | sprng.cs.fsu.edu |
|