XML Structured Data
| [ LiB ] |
Entire books have been written on XML (eXtensible Markup Language) but, for our purposes, it really doesn't have to be terribly complex. Simply put, XML is a way to store string data in a structured form. That means not only can you store names and values of variables (like URL-encoded text), you also can ascertain descriptive properties of what's contained. That is, you can find out how many of a particular type of variable is contained. If your XML file contains data for a quiz, for instance, you can structure it so thatonce importedFlash can immediately know how many questions are contained. In addition, Flash can see that one question has three possible answers and another has four. When we were loading URL-encoded text, we pretty much needed to know the structure or use an additional variable for that information. With XML you get a picture of the data as well as the values in the data.
Note
Flash and DTDs
There's actually more information that XML files can include in the form of a document type description (DTD). These are sort of like a table of contents for what follows . Flash can read the "DOCTYPE" declaration through the XMLDocTypeDecl property, but it can't parse though all the DTD data. Fortunately, the natural hierarchy structure of XML files will be enough to make our lives easier.
The hierarchical structure of an XML file is tags inside of tags (although you'd call them "children" inside "nodes"). In addition, any tag can include named attributes (like properties). It doesn't matter whether you store values inside of tags or as attributes of tags. However, because tags can nest multiple tags inside of themselves , grabbing the value of a tag can return an array full of subtags. Grabbing an attribute's value always returns a single value.
Here's an example from which you can learn a few terms:
1 <quiz> 2 <question q="What is the capital of Oregon?"> 3 <answers correct="2"> 4 <possible>Portland</possible> 5 <possible>Salem</possible> 6 <possible>Eugene</possible> 7 </answers> 8 </question> 9 <question q="2+2 is 4"> 10 <answers correct="1"> 11 <possible>true</possible> 12 <possible>false</possible> 13 </answers> 14 </question> 15 </quiz>
Without knowing any XML, you can probably agree with the following statements:
-
Within quiz there are two questions .
-
The first question's q is "What is the capital of Oregon?" .
-
Inside the answers tag for the first question you can see the correct is "2" .
-
There are a total of three possibilities inside the answers of the first question .
-
Finally, the second question has two possible answers .
Notice these statements include references to values as well as structure (for example, how the second question has two possible answers). Does the file say "2 possible answers" anywhere ? No, we just counted them. This is the same as how an array's length property provides structural information.
Loading XML
Loading data contained in an XML file is virtually identical to loading text. However, you create an instance of the XML object rather than the LoadVars object (see Listing 6.17).
Listing 6.17. Skeleton XML.load() Code
1 my_xml = new XML(); 2 my_xml.ignoreWhite=true; 3 4 my_xml.onLoad = function(success) { 5 if (!success) { 6 trace("problem"); 7 } else { 8 trace("okay"); 9 } 10 }; 11 12 my_xml.load("quiz.xml"); The only new thing, really, is line 2. Basically, by ignoring white space you're free to put spaces and hard returns into your XML file.
I wish that at this point I could say that you now know everything about XML. In fact, after running the preceding skeleton code you can get information and grab values from the my_xml instance. However, digging deep into a structured XML file requires a bit of parsing.
Parsing XML
After you've successfully loaded XML data, you can access data contained in one of three general ways: Just grab specific expected values inside the instance as needed; parse through the expected structure and store values inside other variables (such as arrays or generic objects); or run a generic parser that automatically moves the values into arrays and objects. People have written several automatic parsers that dive into any legitimate XML data and churn out easily accessible Flash variables. (You'll find one at my site for this book: www.phillipkerman.com/rias.)
I find that it's usually easier to deal with the data restructured into Flash variables. If you plan to import data, change it, and then send it back to a server (as the XML object supports sendAndLoad() like LoadVars), however, you may want to keep the data as XML. That way you can make changes and just send it back when you have finished.
To make your own parser or to grab individual values, you need to get a good handle on the object's structure. Listing 6.18 shows just a few one-line expressions to grab either information or values from the my_xml instance (after it loads the quiz.xml data shown earlier). They look a bit gnarly, but I'll explain what I derived from them next .
Listing 6.18. Practice Expressions
my_xml.onLoad=function(){ trace("total questions: "+ this.firstChild.childNodes.length); trace("question 1: "+ this.firstChild.firstChild.attributes.q); trace("correct one: "+ this.firstChild.firstChild.firstChild.attributes.correct); trace("total possible: "+ this.firstChild.firstChild.firstChild.childNodes.length); trace("first possible: "+ this.firstChild.firstChild.firstChild.  childNodes[0].firstChild.nodeValue); trace("second possible: "+ this.firstChild.firstChild.firstChild. childNodes[1].firstChild.nodeValue); trace("third possible: "+ this.firstChild.firstChild.firstChild. childNodes[2].firstChild.nodeValue); }
childNodes[0].firstChild.nodeValue); trace("second possible: "+ this.firstChild.firstChild.firstChild. childNodes[1].firstChild.nodeValue); trace("third possible: "+ this.firstChild.firstChild.firstChild. childNodes[2].firstChild.nodeValue); } First, notice this is all within the onLoad event, because I don't want to execute any of it until the data is fully loaded. (It also means this is effectively my_xml.) Without going through each line, let me summarize by saying you can grab the following:
-
Nodes (which return an array of nodes)
-
A single node (which returns an XML object)
-
Attributes of node (which return generic objects)
-
Values of nodes or attributes (which return strings)
From there, you just have to figure out how far down the hierarchy to dive. Note that even though the quiz node appears to be at the root of the file, it's actually the first child (either this.firstChild or this.childNodes[0]) . Therefore, this.childNodes[0].childNodes[0] grabs the first entire question node. The attributes property returns a generic object full of all the named attributes in a particular node. Finally, nodeValue will return the text between the tags of a particular node. The part that messes me up all the time is that when you dig down and find the node, you have to get the nodeValue of its first childnot just the node's nodeValue! For example, the third possible is shown here ( nodeName returns "possible" ): this.childNodes[0].childNodes[0].childNodes[0].childNodes[2].nodeName;
However, to get the value of a node, you can't just change nodeName to nodeValue . You must use firstChild.nodeValue .
It makes sense to begin any parsing effort by writing a few expressions as I did in the preceding listing. Those are the handles I'll need to extract any data contained. However, deriving those expressions often involves a lot of hunting and pecking. Here's an easy way: Just get the skeleton code that imports the XML data and do a Debug Movie. For example, Figure 6.8 shows how I found the first question.
Figure 6.8. Digging into an XML object is easiest with the Debugger.
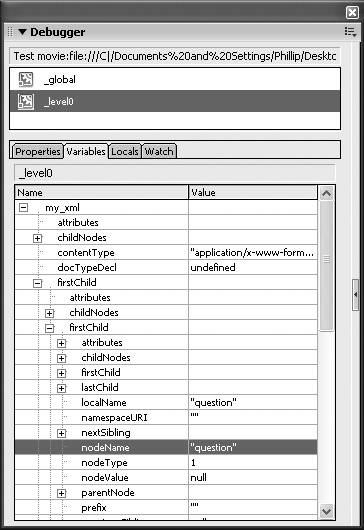
I just selected the my_xml variable, clicked firstChild ( my_xml.firstChild ) where I saw "quiz" for the nodeName , and then clicked firstChild again ( my_xml.firstChild.firstChild ), and I saw "question" for the nodeName. And, finally, I clicked attributes ( my_xml.firstChild.firstChild.attributes ), where I saw both the q property and its value "What's the..." . Hopefully, diving in this way makes an otherwise unwieldy expression such as the one in the following trace() clearer:
trace("first q "+my_xml.firstChild.firstChild.attributes.q); You'll still probably need to do a bit of pecking when parsing through an XML object, but I've found the Debugger invaluable.
For a good exercise, try to re-create the entire quiz example from earlier in this chapter using XML the way I structured here. You can find my solution within the downloadable files for this chapter.
Browsing Amazon Through Flash
The quiz is cool and all, but here's an example that is not only practical, it's also really cool. Online retailer Amazon.com has a version of their web service that returns XML structured data. In Listing 6.19, I create a LoadVars instance but pass it an XML object when performing a sendAndLoad() . (Remember, one instance is to fashion the data you're sending and one is to carry the data getting returned.) The only thing you'll need to make this work is the Amazon Web Services Kit (downloadable from Amazon.com; just search for "web services"). Download the kit and apply for a "token" (an ID). Amazon controls access to their data.
Listing 6.19. Importing Amazon Product Details
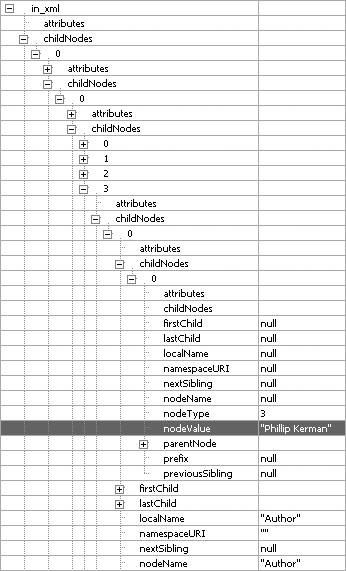
1 in_xml=new XML(); 2 in_xml.ignoreWhite=true; 3 in_xml.onLoad=function(){ 4 trace("first author is :"+ this.childNodes[0].childNodes[0].childNodes[3].childNodes[0]. childNodes[0].nodeValue) 5 } 6 7 out_vars=new LoadVars(); 8 out_vars.ignoreWhite=true; 9 out_vars.t=" webservices -20"; 10 out_vars["dev-t"]="YOUR_TOKEN_GOES_HERE"; 11 out_vars.AsinSearch="0735712956";//or any ISBN 12 out_vars.type="heavy"; 13 out_vars.f="xml"; 14 15 out_vars.sendAndLoad("http://xml.amazon.com/onca/xml2", 16 in_xml,"GET"); Not too bad eh? One thing to notice is that Flash doesn't like the dash in the developer token property ( dev-t ) on line 10, so I just set it using the string/ bracket reference technique. Remember to replace "YOUR_TOKEN_GOES_HERE" with the token provided when you sign up. And, you can try other book ISBNs, too. Of course, the trace() statement in line 4 is a bit longbut that's just where the author name was hiding. Again, I used the Debugger to figure it out (see Figure 6.9).
Figure 6.9. You can find all kinds of data in the XML object returned from Amazon.
Note
Loading Data from Outside Your Domain
Before you get too excited about loading XML, realize that this example won't work after you publish it and post it on a web server. That's because the Flash player is restricted from accessing data on other domains (unless your domain is on the list of approved domains in the policy file on the other domainin this case Amazon.com). There are a few ways around this: Place a policy file on the domain that you want to access, but load XML from your same domain, or place a script on your domain that fetches the outside data and returns it to Flash. This last solution is called a proxy script, which you can find in Macromedia TechNote 16520.
The steps to make the Amazon example work with a proxy script on ColdFusion are as follows:
- Download the template proxy.cfm (from Macromedia's 16520 TechNote).
- Change the second line to read:
<cfset dataURL="http://xml.amazon.com/onca/xml2?"&CGI.QUERY_STRING/>
( CGI.QUERY_STRING adds the parameters sent from Flash.)
- Change line 15 (in Listing 6.19) to point to the installed proxy.cfm file:
out_vars.sendAndLoad("http://localhost/proxy.cfm", in_xml,"GET");
This solution means Flash only accesses your domain. It's just that your domain can go get data from outside and send it back to Flash. If you think this is a dumb rule that app servers can break but Flash can't, please realize that only the Flash SWF actually downloads and runs as a script on the user 's machine. App servers execute scripts on the server and then return plain HTML (or other text values). You definitely wouldn't want a malicious SWF snooping around your local network or local domains.
You can certainly expand this to allow the user to type in various book titles. You'll find all kinds of additional properties that you can send when making the sendAndLoad() request. It's actually possible to entirely re-create the Amazon web site, with searching and shopping carts, all with a Flash interface. You'll see other cool applications like this when we look at Remoting and the Data Management components in Chapter 7, "Exchanging Data with Outside Services," but this example is particularly cool because it doesn't require any middleware.
| [ LiB ] |
EAN: 2147483647
Pages: 120
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Measuring ROI in E-Commerce Applications: Analysis to Action
- Managing IT Functions
- Governance Structures for IT in the Health Care Industry