Moving Around Through XML
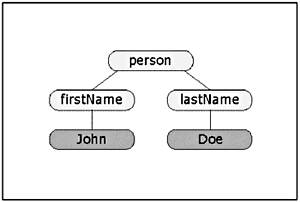
| Remember that Flash uses a DOM-based system for working with XML. Under this system, after you have loaded and parsed some XML, you end up with a tree structure . The most common way to manipulate the XML is to walk through the XML tree to see what's there and extract the relevant information. Each "node" in an XML tree is actually an object. This is important! These objects can be either an XML element or text. For example, the structure listed here has five nodes. Three of those nodes are XML elements (<person>, <firstName>, and <lastName>). The remaining two nodes (John and Doe) are text nodes. When you're stepping though a tree structure to extract information from the nodes, how are you going to know whether you're in an XML element or a text node? Actually, it's easy. The XML object has a property called nodeType. This read-only property can have a value of 1 or 3. A value of 1 tells you that you are inside an XML element (between the brackets). A value of 3 tells you that you're inside a text node. <person> <firstName> John </firstName> <lastName> Doe </lastName> </person> Is nodeType the only XML property that you have access to? Of course not. This would be a good time to stop and take a look at some of the XML object properties that you have access to when you are working with nodes:
Remember these properties. They'll come in handy in a moment. Now picture the previous XML structure graphically represented as a tree. You would see something like Figure 23.1. You might have noticed that your tree structure looks just like a family tree. In fact, Flash uses a lot of genealogy terminology, such as parent, child, and sibling, for moving around inside XML trees. Figure 23.1. The XML hierarchy as a tree structure. After Flash has loaded and parsed an XML document, the XML object that it was loaded into contains a single link to the new data structure, firstChild. This property of the XML object points to the root node of the tree. In the previous case, it would point to the <person> node. To find the firstChild for any XML object you have created, you just have to reference this firstChild. To test this, work your way through Exercise 23.2. Exercise 23.2 Determining the Node in the Tree Structure In this exercise, you'll use the file that you created in Exercise 23.1 and add some code to determine the nodeName and nodeType of the root node.
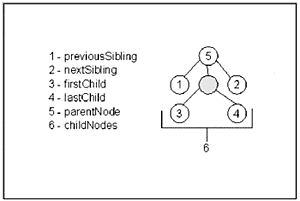
All nodes in the tree have properties to point to other nodes. The way they all work is illustrated in Figure 23.3. (The current node is the highlighted one.) Figure 23.3. The nodes in an XML document all have relationships to each other based on their position in the document tree. The childNodes property might seem a bit confusing, but it's actually pretty simple; it's just an array of all the child nodes under a given node. In the Figure 23.2 example, childNodes would contain two elements, node 3 and node 4. When you are working with XML, you already know that you're dealing with nodes. I've alluded to child nodes. You can also have parent nodes and sibling nodes. It's really not as bad as it sounds. Go back and look at the XML structure that we were using earlier: <person> <firstName> John </firstName> <lastName> Doe </lastName> </person> You have all three types of nodes represented. <firstName> is the child node of <person>. <lastName> is also a child node of <person>. <person> is the parent node for both <firstName> and <lastName>. <firstName> and <lastName> are siblings. It goes even further than that. Remember that text also counts as a node, so John is the child of <firstName> and Doe is the child of <lastName>. John and Doe, however, are not siblings. You can use some additional XML properties to access these different nodes:
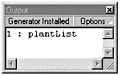
Now it's time to pull all this together and do something useful with all these new properties. Using Node PropertiesA complex but often used method of exploiting these properties is to print the XML document to the output window and format it for debugging purposes. This is particularly useful when you are importing XML from an outside source. Think for a moment about how you are going to accomplish this. After your XML document loads, you'll simply have to make a call to a function that will read and print the data. In addition, you will want to print a nicely formatted XML tree to the output windowwith brackets around XML element nodes, indents, the whole works. Sounds pretty straightforward doesn't it? It's not. To build the tree, you need to actually do something called a "depth first search." This means that you go down as deep into the tree as you can and then move on. You can do this by having the function call itself, or behave recursively. Recursion is very useful when you are dealing with tree structures. It can also be a difficult topic to wrap your head around. The first issue that you need to deal with before you plunge into the next exercise is how recursion works. Recursion is just a way of subdividing a problem into increasingly smaller pieces. It is possible to use recursion when writing a function. A recursive function internally calls itself. It sends itself a smaller and smaller piece to solve until it has worked down to the smallest piece. Then it climbs back out to solve the next bigger piece. If you think about it, that works well with XML because every piece of XML looks the same (for example, every node has child nodes). In the next exercise, you'll use the nodeType, nodeValue, firstChild, and nextSibling properties, along with recursion to read the XML tree structure and format it for printing to the output window. You'll continue to build on the file that you've already started. Exercise 23.3 Using the XML Properties
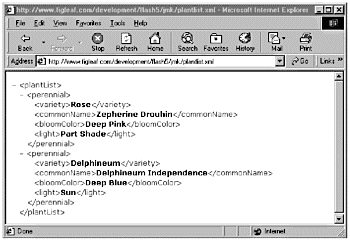
What's the deal with all those blank lines? This brings up another issue that you need to deal with when working with Flash and XML: whitespace. Whitespace, XML, and FlashUnlike with most other XML parsers, whitespace is significant to Flash. Flash sees spaces, tabs, hard returns, and so on as actual nodes in the tree. This means that you should always look for the actual contents of a node rather than just assuming that the data that you want will be at a certain position in the tree. If you rerun this code but change the XML file being loaded to plantList.xml, which has all whitespace stripped out, you'll get a much nicer format: <plantList> <perennial> <variety> Rose </variety> <commonName> Zepherine Drouhin </commonName> <bloomColor> Deep Pink </bloomColor> <light> Part Shade </light> </perennial> <perennial> <variety> Delphineum </variety> <commonName> Delphineum Independence </commonName> <bloomColor> Deep Blue </bloomColor> <light> Sun </light> </perennial> </plantList> If you are running Internet Explorer 5.0 or higher, you can use IE's built-in parser to display your XML file in the browser window. (See Figure 23.4.) IE will build a color -coded collapsible tree for youand it doesn't care about whitespace. Figure 23.4. If you have Internet Explorer 5+, you can display a color-coded version of your XML file directly in the browser window. But you still have to deal with whitespace in Flash. The most recent version of the Flash Player (R41/42) has an ignoreWhite property that also eliminates the whitespace problem, but be careful using this: If your target audience doesn't have the most recent revision of the Player, they're going to have problems with your parsed data. XML and AttributesIn addition to the element and text nodes you've looked at in XML files, element nodes can also have attributes . In fact, depending on your data, you can use attributes to replace child nodes altogether. Why would you do that? Because it's fast. Remember that one of the things that slows parsing of XML files in Flash is a deep file structure. If you will have only one type of a particular piece of information for a node, you can make that information an attribute of the node. If you look at the original XML for the example that you've been working with (see Listing 23.2) you'll see that the first XML element node had an attribute called name . You'll notice that the attribute didn't get picked up when you walked recursively through your file. That's just because you didn't ask Flash to look for any attributes. What if you want to know what the attributesas well as the nodesare? Well, it turns out that attributes are actually pretty easy to deal with! Listing 23.2 The plantList Element Node Has an Attribute Called name With a Value of My List<plantList name="My List"> <perennial> <variety>Rose</variety> <commonName>Zepherine Drouhin</commonName> <bloomColor>Deep Pink</bloomColor> <light>Part Shade</light> </perennial> <perennial> <variety>Delphineum</variety> <commonName>Delphineum Independence</commonName> <bloomColor>Deep Blue</bloomColor> <light>Sun</light> </perennial> </plantList> Each XML element node has an attributes property. This property is actually an object, with each property of the object being an attribute. For example, this code would loop over an XML element node and print all the attributes and their values: for (i in node.attributes){ trace(i+" = " + node.attributes[i])); } Note This is a slightly different version of the for loop than you've seen. Instead of setting up a counter to loop through your code until a condition is met, the for/in loop lets you loop through the properties of an objectin this case, the array of properties associated with the attributes object. If you want the printXML() function that you created in the last exercise to pick up attributes as well as child nodes, all you need to do is add the code between the asterisks in Listing 23.3. Listing 23.3 To Get the printXML() Function to Also Pick Up an Attribute of Any Tags,You Just Have to Add a Little Bit More Code and Change One Line function printXML(node, spaces){ if (node.nodeType == 3){ trace(spaces + node.nodeValue); }else{ // ***************************************************************** var attr = ""; for (var i in node.attributes){ attr += " " + i + "='" + node.attributes[i]+"'"; } trace(spaces +"<" + node.nodeName + attr + ">"); // ***************************************************************** var tempNode = node.firstChild; while (tempNode != null){ printXML(tempNode, spaces+" "); tempNode = tempNode.nextSibling; } trace(spaces +"</" + node.nodeName + ">"); } } myXML.load("plantListAttributes.xml") Note that the line trace(spaces +"<" + node.nodeName + ">"); was replaced by this line: trace(spaces +"<" + node.nodeName + attr + ">"); But what if you want to convert the existing XML file to use attributes rather than child nodes? You know that this would be faster, and it would work nicely with the existing data. You just need to alter the existing code (see Listing 23.2) to this: <plantList name="My List"> <perennial variety="Rose" commonName="Zepherine Drouhin" bloomColor="Deep Pink" light="Part Shade"></perennial> <perennial variety="Delphineum" commonName="Delphineum Independence" bloomColor="Deep Blue" light="Sun"></perennial> </plantList> You can still use the exact same code that you were using in the earlier exercise to walk through this file and print it in the output window. If you want to print the attributes as well, you'll need to add the code in Listing 23.3. You can test this by saving plantListAttributes.xml and plantListAttributes (from the Chapter_23/Assets folder on the CD) to the same directory on your hard drive and then testing the Flash file. So now you know how to navigate through your XML structure. What else can you do with XML? |
EAN: 2147483647
Pages: 257