Chapter 2: Relational Databases
|
If you're already familiar with database theory, you may just want to skim this chapter. But if you're new to databases, or you feel that you need a bit of a refresher, this chapter is intended to provide you with enough theory to prepare you for those that follow. In it, we'll become familiar with the key concepts and common terms that you will run across throughout your career as a database developer and user. Relax, become familiar with the ideas, and don't get caught up on any one issue if it doesn't make sense to you right away. You can always refer back to this chapter later as a reference. We'll begin with a discussion of a few key database concepts, such as tables, rows, and fields. Then, we'll explore the key differences between relational and non-relational databases. After that, we'll provide an introduction to SQL, to database design, and to normalization. We'll conclude with a brief comparison between SQL Server and Microsoft Access. By the end, you'll know enough to smooth your passage through the next few chapters, and you'll have a base upon which the rest of the book will build.
Database Terms and ConceptsThe term 'database' has many interpretations, the simplest of which is 'a collection of persistent data'. By this definition, a hard drive is a database, since it is certainly a repository of data. But to software developers, a database is much more than ad hoc data on a hard drive. The definition we will use here is more specific, and more useful to software developers who use database management systems (DBMSs) for application development.
Even this definition is not particularly narrow - these criteria are met, for example, by properly formatted comma-separated value files (.csv files), and by spreadsheets. Consider this example of the former:
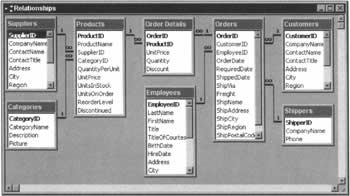
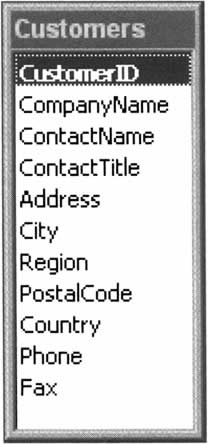
Herbert Hoover, Ex-President Marcus Welbey, M.D. Gandalf, The Grey Jabba, The Hutt Attila, The Hun This whole file represents a single table in a database that contains information about people. Each row in this file represents a row in the table, and contains information about one person. Each row contains two fields: the first is the person's name, and the second is the person's title. And finally, the fields have values - for example, the first field of the first row has the value Herbert Hoover. However, although 'databases' such as this one have their place (and we looked this subject in the previous chapter), this book will concentrate for the most part on the kinds of database that are managed by DBMSs, of which well-known products such as SQL Server and Microsoft Access are but two examples. Such systems are responsible for managing the details of storing and retrieving physical data in the form of a database, and making that data available to the developer. In this chapter, as in the rest of the book, we'll be basing our experiments on and around the sample Northwind database that not only comes with the MSDE we've already installed, but also is available for MS Access and MS SQL Server version 7.0 and later. Northwind is a fictitious company that buys products from suppliers and sells and ships them to its customers. The Northwind database, like our .csv example above, contains tables, one of which is named Customers. This table, like all of the others in the Northwind database, contains rows and fields. Try It Out - Our First Look at Northwind
In this chapter, we're going to use Microsoft Access as our tool for analyzing the Northwind database. If you don't have Access installed, that's not a problem - we'll be illustrating the discussion with screenshots that show exactly what's going on. The Access version of the Northwind database ships with the product, or you can download it from the Microsoft web site (http://office.microsoft.com).
| ||||||||||||||||||||||||||||||||||||||


EAN: 2147483647
Pages: 263