Introduction to ADO.NET
|
As described above, there are many different data stores that can provide information to an application. Microsoft realized a long time ago that having a single programming interface for accessing these diverse stores makes sense - it allows applications to make use of the latest versions of database servers with minimal changes to code, and it makes for interoperability between platforms. With every new Microsoft platform comes a new way of accessing data stores. In the .NET Framework, the technology is called ADO.NET, but that builds upon the previous data-access functionality of technologies such as ADO, OLE DB, RDO, DAO, and ODBC. It provides an appropriate method for accessing data in modern applications that are more widely distributed than was previously the case. After describing underlying technologies such as OLE DB and ODBC, this section will place ADO.NET into context with the technologies that came before it, and go on to explain the architecture of ADO.NET in a little detail.
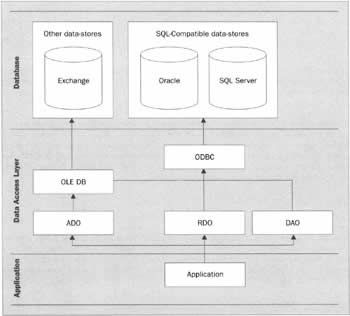
A History of Data Access on the Windows PlatformAs soon as you start to think about accessing data on the Windows platform, you find yourself confronted with a list of abbreviations rather like the one in the second paragraph above. Here, we'll try to untangle the letters, and help you to understand how all of these technologies fit together - which, by and large, they do. In the recent past, most applications communicated with data stores through the software objects provided by ADO, which made use of the lower-level technologies OLE DB and ODBC. In order for this to happen, ADO (and its replacement, ADO.NET) rely on a database conforming to an underlying set of standards. A significant difference between old and new is that ADO.NET has a less demanding, more flexible set of rules, allowing for a greater variety of data sources. To allow applications to make connections to their databases, database vendors have to implement some common sets of functionality (interfaces) that have been devised for this purpose. One such interface is the highly successful ODBC, which is still supported by the vast majority of databases you'll come across. Another technology, OLE DB, was designed as the successor to ODBC, and was the cornerstone of Microsoft's Universal Data Access strategy. It too has become highly successful, and has gained broad support. The diagram below shows a simplified version of how the various pre-.NET data access technologies connect to databases - and even in this diagram you can see that it was all getting a bit complicated! As well as ADO, OLE DB, and ODBC, technologies like RDO and DAO were getting involved too:
DAOLet's start to put some meat on these bones. DAO (Data Access Objects) was Microsoft's first attempt at providing programmers with an object-oriented way of manipulating databases. It was invented for Access v1.0, and updated in later versions of Access and Visual Basic up to Access 97 and Visual Basic v5.0. Many of the original DAO commands have been retained through the years for backwards compatibility, meaning that the syntax required for performing operations can be quite ugly at times. One of the biggest drawbacks of DAO is that it assumes data sources to be present on the local machine. While it can deal with ODBC connections to database servers such as Oracle and FoxPro, there are some things that make sense with remote data sources that cannot be achieved.
RDORDO (Remote Data Objects) is another object-oriented data access interface to ODBC. The methods and objects that it contains are similar in style to DAO, but they expose much more of the low-level functionality of ODBC. Although it doesn't deal very well with databases such as Access, its support for other large databases - Oracle, SQL Server, etc. - made it very popular with a lot of developers. This support focuses on its ability to access and manage the more complicated aspects of stored procedures (compiled commands used to maintain data in the database) and complex record sets (sets of data retrieved from the database).
ADOADO (ActiveX Data Objects) was first released in late 1996, primarily as a method of allowing ASP to access data, and initially supported only very basic client-server data-access functionality. Microsoft intended it eventually to replace DAO and RDO, and pushed everyone to use it, but at the time it only provided a subset of the features of two other technologies that were much more popular. With the release of ADO v1.5, support for disconnected record sets was introduced, as was an OLE DB provider for Microsoft Access. With the release of ADO v2.0 in 1998, it went from being a subset of other technologies, to having a richer set of features. OLE DB drivers for both SQL Server and Oracle were released, meaning that access to enterprise-level database systems was feasible for the first time, and support for native providers (ones that didn't rely on ODBC) was added. Further increases in functionality were introduced in later versions up to v2.7.
ADO.NETADO.NET almost doesn't fit in this discussion - it's an entirely new data access technology that builds on the successes of ADO, but is only really related to it in name. The improvements lie in its support for different types of data store, its optimization for individual data providers, its utility in situations where the data is stored remotely from the client, and its ability to deal with applications where there are large numbers of users simultaneously accessing the data. The key to doing this is through features that separate it from the technologies that preceded it: the use of disconnected data, managed providers (we will look at both of these shortly), and XML.
ADO.NET ArchitectureYou now know that ADO.NET draws on a long history of data access. Almost inevitably, this means that there is quite a lot to learn. Thankfully, Microsoft has put a great deal of thought into its new data access technology, making it more logical and structured than previous attempts, while still providing a wealth of features.
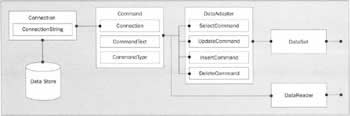
The next few pages are concerned with taking a look at the main ADO.NET objects, and how they cooperate to provide data manipulation. Laid out below is a diagram of the five main object types that you'll be dealing with when you use ADO.NET: If we work our way back from the database, taking the objects one by one, we can see how these objects work together, and what functions they perform:
Looking to the far right of the diagram, you can see two unattached lines - this is where the 'front end' of your application connects to the ADO.NET architecture. The data that is returned here can be used in any way the developer chooses - displaying it to a web page, writing it out to a file, etc.
Data ProvidersOne of the key features of ADO.NET is that it's optimized for the various possible types of data store. Apart from the dataset, which is generic, the other objects in the above list have versions that are specifically geared towards accessing data of a particular type. For example, there are separate data reader classes for dealing with SQL Server and Microsoft Access databases. The umbrella term given to the 'set' of classes that deals with a particular type of data store is a .NET data provider. As discussed, a data provider is a package of classes that implements a set of functionality allowing access to a specific type of data store. While there's a base set of functionality that a data provider must supply in order to be called as such, a particular data provider can have any number of extra properties and methods that are unique to the type of data store that is being accessed. This is very different from ADO, where there was a single set of classes that was used for accessing dissimilar data sources.
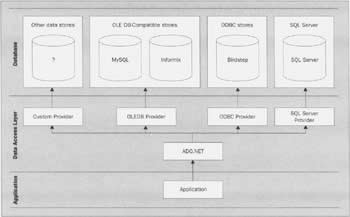
Where do Data Providers Fit in the Scheme of Things?At this point, you're probably starting to think that you're getting a feel for the basic architecture of .NET, and that you can see why data providers allow for more types of data store to be accessed, but you don't know how the two relate to each other. Earlier on, we had a diagram of the technologies that were involved in data access before the introduction of ADO.NET. The following diagram shows how this changes - and how it gets simpler - under ADO.NET.
Standard ProvidersMicrosoft ships the .NET Framework with two data providers as standard: the SQL Server .NET data provider, and the OLE DB .NET data provider. The first of these provides a means of connecting to a SQL Server v7.0 (or later) database, and the classes that it comprises can be found in the System.Data.SqlClient namespace. The second allows access to any of the multitude of OLE DB-compatible data stores that are on the market, and implements similar functionality to the SqlClient provider; it resides in the System.Data.OleDb namespace. A third data provider, which supports ODBC, is available but not installed by default; at the time of writing, it could be downloaded from http://msdn.microsoft.com/downloads/default.asp?URL=/downloads/sample.asp?url=/MSDN-FILES/027/001/668/msdncompositedoc.xml. Once installed, the classes for this provider can be found in the Microsoft.Data.Odbc namespace. Further data providers are under development, including one for Oracle that's in beta at the time of writing. This is also available for download from Microsoft's web site. | ||||||||||||||||||||||||||||||||

EAN: 2147483647
Pages: 263
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter V Consumer Complaint Behavior in the Online Environment
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVII Internet Markets and E-Loyalty