Relational Storage of XML: The XML Type
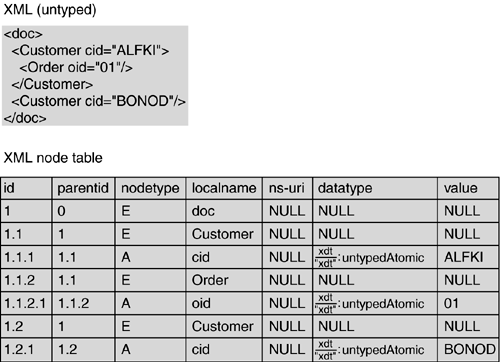
| XQuery processing on XML stored in the database as an LOB depends heavily on the actual physical storage mechanism chosen to store the XML. All LOB-based storage mechanisms have in common that they basically provide a built-in XML datatype. In the following, we use the relational type named XML to designate a new SQL built-in datatype that provides the logical abstraction for XML data stored in a relational database. Listing 7.2 gives an example of a relational table where one column is of type XML . While the example uses an XML document representing structured data that could also be mapped into relational tables, the discussion of the XML datatype below applies equally to any form of XML data (semi-structured and markup data). In what follows , we look first at the logical models for such an XML datatype, discuss the different physical representations, and look into some other important aspects of XML datatypes, such as the relationships of encodings and database collations and their association with XML schemata . Listing 7.2 Example of Relational Table with XML DatatypeCREATE TABLE Order(id int, orderdate date, PODetail XML) Example data (using a string representation of the XML datatype instances): id orderdate PODetail _____________________________________________________________________ 4023 2001-12-01 <purchaseOrder xmlns="http://po.example.com"> <originator billId="0013579"> <contactName> Fred Allen </contactName> <contactAddress> <street>123 2nd Ave. NW</street> <city>Anytown</city> <state>OH</state> <zip-four>99999-1234</zip-four> </contactAddress> <phone>(330) 555-1212</phone> <originatorReferenceNumber> AS 1132 </originatorReferenceNumber> </originator> <order> <item code="34xdl 1278 12ct" quantity="1"/> <item code="57xdl 7789" quantity="1" colorcode="012"/> </order> <shipAddress sameAsContact="true"/> <shipCode carrier="02"/> </purchaseOrder> 5327 2002-04-23 <purchaseOrder xmlns="http://po.example.com"> <originator ... Logical Models for the XML DatatypeThe SQL-2003 standard defines an XML datatype as part of its XML- related extensions that are commonly referred to as SQL/XML [SQLXML]. The standard does not prescribe the exact storage format as long as the type satisfies the XML datatype requirements. One requirement is that the type must be able to represent not only an XML 1.0 document but any element content, including multiple top-level element nodes and text nodes. Listing 7.3 gives an example of an XML datatype instance that has multiple top-level element nodes. The current logical model of the XML datatype is based on an extended XML Infoset in which the document information item has been extended to allow top-level text nodes and more than one top-level element node. Listing 7.3 Example of XML Datatype Instance with Multiple Top-Level Elements<Order> <ID>O1</ID> <OrderDate>2003-01-21<OrderDate> <Amount>7</Amount> <ProductID>P1</ProductID> </Order> <Order> <ID>O2</ID> <OrderDate>2003-06-24<OrderDate> <Amount>3</Amount> <ProductID>P3</ProductID> </Order> This Infoset-based model can easily be mapped to an untyped instance of the XQuery data model by applying the Infoset mapping outlined by [XQ-DM]. The addition of type information is explained below. This model is somewhat more limited than the XQuery data model in the sense that certain components of the XQuery data model, such as top-level attribute nodes, multiple document nodes, top-level typed values and top-level heterogeneous sequences containing such items, cannot be represented. However, these items can still be used inside XQuery expressions. Also, typed values returned by XQuery expressions that can not be represented as XML datatype instances but must be exposed in the relational model have to be mapped into the relational type system. A future version of the XML datatype's logical model may be extended to an XQuery data model. However, in what follows, we work with the Infoset-based model extended with the ability to deal with typed data. As a built-in "scalar" type in the SQL type system, such a type can be cast, for example, from and to the SQL character types using the SQL cast expression. Casting from string to XML will parse and casting from XML to string will serialize the XML data. Physical Models for the XML DatatypeThere exist a wide variety of physical representations for XML datatypes (regardless of the exact logical model). In addition, the storage format has some relation to the questions of whether the XQuery processor should integrate with the existing relational query processor or be a separate component that only executes XQuery expressions, and how the storage format affects the update performance. We will examine several possible storage mechanisms and identify the major issues related to the query-processing approaches and updates. Query-processing aspects are discussed in more detail in a later section. All the storage mechanisms assume that the data actually has been verified to be a well- formed instance of the XML datatype. Users may have different expectations about XML storage fidelity . Generally , we can distinguish among string-level fidelity , in which the XML datatype instance preserves the original XML document code-point for code-point; Infoset-level fidelity , in which the XML datatype instance preserves the XML document structure on the level of the XML Infoset model; and the relational fidelity level , which only preserves information important from a relational point of view, such as the property-value association, and disregards XML-specific properties, such as document order. Obviously the XML datatype's logical model requires at least Infoset-level fidelity. Character LOBWith CLOB, the XML is stored in a character representation. The representation may preserve the original XML data exactly (string-level fidelity), or the data may have been transformed by changing the encoding or by canonicalizing the content, while still providing Infoset-level fidelity. This storage format does not lend itself well to efficient, server-side XQuery processing, since it either requires extensive indexing mechanisms or requires every query to parse the data before executing the query in a separate XQuery component. The indexing mechanisms end up replicating one of the other storage mechanisms in order to take advantage of the existing relational query processing. In addition, basic character LOBs are hard to update on a node level, since most LOB update mechanisms are based on positional ranges and not logical subtrees. Binary LOBThe binary format may represent preprocessed XML in the form of a W3C Document Object Model (DOM) tree, which has been shown empirically to increase the storage size by a factor of two to six over the textual representation due to the storage overhead of the DOM nodes. Some other preprocessed binary format is more likely to be used that may provide more efficient index processing, compression, or other benefits to the query processing. While a binary format could provide string-level fidelity, it usually provides only Infoset-level fidelity. A binary LOB provides an additional level of abstraction over CLOBs at the cost of not being able to read the XML without an access method that reproduces the original textual representation. As with CLOB, XQuery processing often requires additional indexing to take advantage of the relational query processor, or the use of a separate XQuery component such as an embedded XQuery engine written in Java or C#. Propagating node-level updates are often costly since the general BLOB support in relational systems is not designed for logical updates. User -Defined TypeAll the major relational database systems provide (or are going to provide) programmatic extensions inside the database server that allow users to add their own code and datatypes. Of course the database system can also use this mechanism to provide additional, more complex, built-in datatypes such as XML . Such user-defined types may again represent the XML data in many ways, ranging from a string representation over a DOM tree representation to an Infoset object representation. The user-defined type may require the whole instance to be loaded into memory before it can be operated upon, or it may provide some integration into the relational buffers to provide partial loading of the data. Two major approaches are currently advocated for supporting user-defined types. The deep integration approach provides tight integration into the actual query processor at the cost of complex programming and registration requirements, since, for every user-defined type, code specific to the query processor must be provided through predefined APIs (this approach is often called data blade , extender , or cartridge ). The other approach uses a virtual machine such as the Java Virtual Machine or the Common Language Runtime to add user-defined types (the VM approach). This approach trades off better programmability against tighter integration. The integration approach can be used to implement most of the other physical designs outlined in this chapter and integrates tightly into the components of the relational database engine's architecture, such as memory management and query processing, at the cost of flexibility and programmability. The VM approach is an alternative that gives great flexibility in processing XML data at the cost of minimal or no integration with the general storage engine and query processing. In this case, the XQuery engine is usually a component separate from the relational engine that can operate on XML datatype instances that are loaded fully into the VM's memory and use a memory-based representation of the data model. Some examples of the latter are query components written in Java or C# that run inside the virtual machines. Eventually, these two approaches may merge and combine the VM's comparable ease of programming and the efficiency of the integration approach. Updates are provided as another method on the user-defined type. Depending on the internal structure, they may or may not be very efficient. Relational Table MappingsIf XQuery processing is being integrated with the relational query processor, the actual XML data needs to be mapped to relational data and indices. As with mid- tier mapping strategies, a variety of approaches exist. Some of them hide the generated tables from the relational user and thus serve as purely physical models, while others expose the tables in the relational context. By mapping the XML into relational structures, we can define additional relational indices on the tables, integrate the XQuery processing with relational query processing, and perform update processing on the node level. Every relational table mapping has to provide Infoset-level fidelity in order to be usable as physical storage of the XML datatype. Note that several XML-to-relational mappings provided outside of the relational database engine often only provide relational fidelity. Node TablesThe most general approach generates the so-called node table (sometimes also called edge table ) that represents every node in the XML instance as a row in the relational table. It is the most general, since it can represent any XML document structure without loss of information. Unlike the node table that is normally used in mid-tier mappings (see Chapter 6), such node tables may be combined with additional mechanisms such as clustered keys based on a hierarchical Dewey-decimal numbering system (see Figure 7.1 for an example), tokenization of types and names , and additional path and value indices. The Dewey numbered keys, for example, provide document order and physical nearness of parent nodes and their children; combined with the cluster on the keys, this can provide very efficient tree traversals and subtree retrievals. These mechanisms and the ability to map XQuery directly into physical operations instead of SQL queries overcome many of the disadvantages of the mid-tier node-table approach. Figure 7.1. An XML Datatype Node-Table Format with Dewey-Decimal-Numbered Keys Updates generally encounter no problems, although the keys based on the Dewey-decimal system must be managed carefully to keep them balanced. Thus, some variants on the Dewey numbering provide improved key management in the context of updates. Such node-tables are normally not directly exposed to the relational user but hidden behind the abstraction of the XML datatype. Table ShreddingIf additional structural information is available in the form of a schema, we can use the schema information along with potential annotations to provide mappings into related tables , which is colloquially called shredding (see Figure 7.2). Chapter 6 provides a more detailed overview of such shredding-based approaches. Such tables can be exposed to relational users for relational processing or remain hidden behind the XML datatype abstraction. However, this approach still requires additional hidden information that encodes the original order information and therefore does not work well with data formats that are not easily mapped into the relational or extended-relational (e.g., nested) tables of the database system. Figure 7.2. An XML Datatype as Virtual Schema-Driven View CombinationsOf course these different physical models can be combined. For example, a BLOB approach may provide explicit, XML schema-driven indices that map structured XML into relational tables and provide an index based on the node-table approach for unstructured XML. Encodings and CollationsXML documents normally carry their encodings with them in the XML declaration (or are defaulted to UTF-8 or UTF-16). The XML parser uses that encoding information to map the encoded character stream into the Unicode code points of the character information items of the XML Infoset. In relational systems, information is available about the character set and collation used by the database system for storing, indexing, and comparing character data. Collation information describes the equivalence of different code points, characters , and glyphs for different languages and uses. Because it indicates what language ordering and other comparison options, such as case-sensitivity , should be applied when comparing character data, it is important for both the query semantics and for indexing. In relational database systems, collations are attached to data (e.g., to table columns ), whereas the XML model does not provide a way to do this. Instead, XQuery attaches collations to individual string operations. For example, it is possible to sort the same data in two different ways, with two different collations, once for case-sensitive order, and once for case-insensitive order. The impedance mismatch between these two approaches leads to some potential confusion. Relational database systems can make different collation information available for storage and indexing, whereas XQuery assumes a default collation and provides overriding capability only in the operational context. When storing XML, the XML datatype as described in SQL-2003 [SQL2003] translates the given XML encoding into Unicode following the Infoset model. The SQL-2003 standard is currently only concerned with storing and retrieving full instances of XML and does not provide for collation information on the XML datatype. However implementations can associate the relational default collation with the XML data and make it the default collation when executing XQuery expressions on it. For schema-directed mappings, a relational system may also use schema annotations in the mapping to identify character sets and collations to be used when mapping string data to relational columns. It usually also provides a way to directly associate a collation to the XML datatype that is to be used for indexing and querying as in the following example: CREATE TABLE Order( id int, orderdate date, PODetail XML COLLATION EN-US-CASE-SENSITIVE ) The collation information provided when storing the XML can then be picked up as the default collation used by the XQuery expressions (see below for more details). This enables the queries to use the collation-specific indices. Typing an XML DatatypeOne of the important features of XQuery and its data model is the ability to use XML schema information to operate on typed data. Thus, we must be able not only to validate or physically map a relational XML datatype, but to type its value according to an XML schema. Several schema languages could be used to perform the typing, as long as they map into the type system expected by XQuery; here we use the W3C XML Schema language as our XML schema language in order to illustrate the necessary capabilities. This also appears to be the primarily supported XML schema format in all the major XML-enabled relational database systems. In order to provide type information from an XML schema, the type-relevant information, such as the attribute, element, and type declarations contained in the schema, must be managed in the metadata component of the database. W3C XML Schema information is organized and scoped according to target namespace URIs and schema location hints. On the other hand, the naming and scoping of relational database systems components are based on a variant of dot-separated SQL identifiers that identify the catalog, schema, and schema object. For example, the table Customer in the catalog MyCat and the schema MySchema have the three-part name MyCat.MySchema.Customer . Since identifiers fit into the relational naming system but target namespace URIs do not, a relational system usually provides a mechanism to map the target namespaces to SQL identifiers. For example, a schema could be registered using the data-definition statement given in the following example, which registers the content of the schema under the target namespace http://www.example.com/po-schema and any of its imported schemata and gives it the SQL identifier POSchema . CREATE XML SCHEMA POSchema NAMESPACE N'<schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace = "http://www.example.com/po-schema"> ... </schema>' This identifier is then used in the SQL context to refer to the registered XML schemata, whereas the target namespace URIs continue to be used in the XML contexts such as XML Schema and XQuery. The schema management component must also provide for some schema evolution capability, which is outside of the scope of this discussion. Once the relational system provides for an XML schema repository, these schemata can be used for validating individual XML datatype instances, constraining the value of XML-typed columns, and providing type information to XQuery. XML Schema validation offers two functions:
It also offers three validation modes:
Basic validation provides functionality that is often needed in the context of relational check constraints during table definitions and in relational query predicates. Relational systems therefore usually provide a validation function such as isvalid(XML, SchemaComponents, 'lax''strict') Users may want to either validate against the collection of schemata described by the schema's SQL identifier, or restrict it to a single namespace contained in the schema collection or even a single element. Thus the schema-component argument may provide a combination of the SQL identifier with optional indication of a namespace and an element name. While an instance of type XML can be typed via an XML Schema using a dynamic validate operator, it seems more appropriate to make an XML Schema-constrained XML datatype a distinct SQL type. Using the validate operation would require a dynamic association and would not provide enough static information for any form of static processing, while the second approach provides a static association that can be used to perform static processing. The static association allows type information to be used for static constraints of the content of XML columns and variables , to provide additional static hints for storage, and to be used by the static phase of query processing, including XQuery's static typing. We are going to indicate a typed XML type in the following form (as always, the actual syntax may look different): XML TYPED AS SchemaComponents where SchemaComponents denotes a schema collection identifier and, optionally , a namespace or top-level element contained in the schema collection. Listing 7.4 gives an example of a relational table that contains two XML -typed columns. The PurchaseOrders column is statically constrained by an XML Schema, and the OrderForm column is dynamically validated by schema information given in another column using a table-level check constraint. Listing 7.4 Example of XML -Typed ColumnsCREATE TABLE Customers ( CustomerID int PRIMARY KEY, CustomerName nvarchar(100), PurchaseOrders XML TYPED AS POSchema, OrderForm XML, OrderFormType nvarchar(1000) CHECK isvalid(OrderForm, OrderFormType, 'strict') ) The main difference between the handling of the two columns is that the statically typed column can take advantage of the XML Schema information when mapping to the physical level. It can be used to map the relationally structured parts of the XML document to relational tables, fold simple-typed values into the element nodes instead of keeping them as separate text nodes, or provide additional information to design path or value indices. The dynamically constrained column, on the other hand, cannot provide such static information, and physical designs normally do not take such dynamic information into account. In addition, static and dynamic constraints affect the type information accessible to queries over the XML datatypes (see below). In order to type and validate an "untyped" XML datatype instance or retype/revalidate an already typed instance, we can use the SQL casting functionality, as shown in the following example, to cast from the unconstrained to the statically constrained XML type: SELECT CAST(OrderForm AS XML TYPED AS POSchema) FROM Customers Other Aspects of the XML DatatypeThere are many other aspects of the XML datatype that are not directly related to its queryability and thus outside of the scope of this chapter. Among them are SQL functions defined on the XML datatype such as parsing, serializing or concatenation, the issues of how the database APIs provide access to XML datatype instances and columns, and how to cast to and from the XML datatype. For example, should casting a string to XML be equivalent to parsing the string, and casting from XML to string be equivalent to serializing it? |

 boolean that takes an XML instance, schema component identifiers such as the schema's SQL identifier, and the validation mode, and returns a true or false result depending on whether the validation succeeded.
boolean that takes an XML instance, schema component identifiers such as the schema's SQL identifier, and the validation mode, and returns a true or false result depending on whether the validation succeeded. EAN: 2147483647
Pages: 102