Related Languages and Standards
Related Languages and StandardsThe designers of XQuery did not begin with a completely blank slate. The design of XQuery was strongly constrained by the requirement for compatibility with established standards and was also influenced by the design of other query languages with which the members of the working group were familiar. This section describes some of the ways in which XQuery was influenced by related languages and standards. XML and NamespacesSince XQuery is a query language for XML data sources, it is obvious that the language must be strongly influenced by the structure of XML itself [XML]. From XML comes the notion that information is represented as a hierarchy of elements that have names , optional attributes, and optional content. The content of an element may consist of text, nested elements, or some mixture of these. The content of an XML document has an intrinsic order, and it is often important to preserve this order. XQuery was also influenced by some of the lexical conventions of XML. Since XML is a case-sensitive language, it was decided that XQuery should be case-sensitive also. Since XML allows a hyphen to be used as part of a name , XQuery adopted the same convention. A consequence of this convention is that whitespace is sometimes significant in XQuery expressions. For example, spaces are used to distinguish the arithmetic expression a b from the name a-b . One important feature of an XML query language is the ability to construct an element with a given name and content. One of the ways in which XQuery supports element construction is by using XML notation. An XQuery element constructor can consist of a start tag and an end tag , enclosing character data that is interpreted as the content of the element, as illustrated in the following example: <price>15.99</price> Within an element constructor, curly braces are used to enclose expressions that are to be evaluated rather than treated as text, as in the following example, which computes a price from two variables named $regprice and $discount : <price>{$regprice - $discount}</price> Namespaces are very important to XML because they define the structure of an XML name. Namespaces provide a way for XML applications to be developed independently while avoiding the risk of name collisions. Qualified names (QNames ), as defined in the XML Namespaces specification [NAMESP], are used as the names of XML elements and attributes. XQuery also uses QNames as the names of functions, types, and variables. A QName consists of two identifiers, called the namespace prefix and the local part , separated by a colon. The namespace prefix and colon are optional. If present, the namespace prefix must be bound to a Uniform Resource Identifier (URI) that uniquely identifies a namespace. As an example, suppose that the namespace prefix student is bound to the URI http://example.org/student , and the namespace prefix investment is bound to the URI http://example.org/investment . Then the QNames student:interest and investment:interest are recognized as distinct names even though their local parts are the same. XQuery provides two ways of binding a namespace prefix to a URI. The first of these is by a declaration in the prolog , a part of a query that sets up the environment for query execution. Namespace prefixes declared in the prolog remain in scope throughout the query. This method of declaring a namespace prefix is illustrated by the following example: declare namespace student = "http://example.org/student" The second way to bind a namespace prefix to a URI in XQuery can be used when an element is constructed and defines a namespace prefix for use within the scope of the element. This method relies on an attribute with the prefix xmlns , which indicates that the attribute is binding a namespace prefix. For example, in the following start tag, the attribute named xmlns:student binds the namespace prefix student to a given URI within the scope of a constructed element named school : <school xmlns:student = "http://example.org/student"> XQuery allows a user to specify, in the prolog, default namespace URIs to be associated with QNames that have no namespace prefix. Separate default namespaces can be specified for names of functions and for names of elements and types. XQuery also provides a set of predefined namespace prefixes that can be used in any query without an explicit declaration. For example, the prefix xs is automatically bound to the namespace of XML Schema, so it is easy to refer to the names of built-in schema types such as xs:integer . Similarly, the prefix fn is automatically bound to the namespace of the XQuery core function library [XQ-FO], so it is easy to refer to the names of built-in XQuery functions such as fn:max and fn:string . If a query does not declare otherwise , the default namespace for function names is the namespace of the XQuery core function library (also bound to the prefix fn .) XML SchemaAs noted earlier, one of the major goals of the XML Query Working Group has been to define a query language based on the type system of XML Schema. This goal was made more difficult by the fact that XML Schema was designed to support validation of documents rather than to serve as the type system for a query language. XML Schema has had a strong impact on XQuery because its type system is quite complex and includes some unusual features. The influences of XML Schema on the design of XQuery include the following:
XML Schema defines a large set of built-in primitive types and an additional set of built-in >derived types . In general, XQuery operators are defined on the primitive types of XML Schema, and operators on derived types are defined to promote their operands to the nearest primitive type. However, an exception to this rule was made for the type integer . Although integer is considered by most languages to be a primitive type, XML Schema considers it to be derived from decimal . If the general rule of promoting derived types to their primitive base types were applied to integers, arithmetic operations on integers such as 2 + 2 would return decimal results. As a consequence, an expression such as 2 + 2 would raise a type error when used in a function call where an integer is expected. In order to avoid these type errors, operations on integers in XQuery are defined to return integers even though XML Schema considers integer to be a derived type. XML Schema defines a duration type, which consists of six components named year , month , day , hour , minute , and second . This definition ignores the experience of the relational database community, which has discovered that neither comparison nor arithmetic operators can be supported by a duration type defined in this way. The following questions illustrate the problems encountered by operations on the duration type of XML Schema: Which is greater, one month or thirty days? What is the result of dividing one month by two? To deal with these problems, the SQL Standard in 1992 [SQL92] introduced two datatypes called a "year-month interval" and a "day-time interval." Each of these supports a well-defined set of arithmetic and comparison operators, but they cannot be mixed in a single expression. In order to facilitate arithmetic and comparison operations on dates, times, and durations, XQuery followed the practice of SQL in defining subtypes of duration called xdt:yearMonth Duration and xdt:dayTimeDuration ( xdt is a predefined namespace prefix that represents the namespace containing all new datatypes defined by the XQuery specification). Following the mandate of its charter, the working group designed XQuery to be fully compatible with XML Schema. At the same time, the group attempted to design XQuery in a way that would not preclude its adaptation to alternative schema definition languages. XQuery might be viewed as relying on an external schema facility for defining types and type hierarchies and for determining the type of a given element (in XML Schema, this process is called validation ). To the extent that a schema facility meets these requirements, it can be considered compatible with XQuery. XPathComparable to XML Schema in its influence on the design of XQuery is XPath [XPATH1], which has been a W3C Recommendation since November 1999. XPath is widely used in the XML community as a compact notation for navigating inside XML documents, and it is an integral part of other standards, including XSLT [XSLT] and XPointer [XPTR]. The functionality of XPath is clearly needed as part of an XML query language, and there is a clear precedent that this functionality should be expressed using the syntax of XPath Version 1. Therefore, from the beginning, compatibility with XPath Version 1 was a major objective and constraint on the design of XQuery. Initially, the Query working group considered using the path expression of XPath as a "leaf expression" in the XQuery syntaxthat is, as a primitive form of expression that could be used as an operand in higher-level XQuery expressions but could not in turn contain other XQuery operators. However, at the same time that XQuery was being designed, the XSLT working group had collected a set of requirements for new functionality in XPath [XPATH2REQ], and these requirements overlapped substantially with the functionality proposed for XQuery. As a result, it was decided that a new version of XPath would be developed jointly by the XSLT and Query working groups. The new version, to be called XPath Version 2 [XPATH2], would be a syntactic subset of XQuery, would be backward-compatible with XPath Version 1, and would be available for use in XSLT and other standards. XPath Version 2 would include many of the features of XQuery and would be fully integrated with the rest of the XQuery syntax rather than serving as a non-decomposable "leaf expression." Types in XPathFor XPath to be used in a query language based on the type system of XML Schema, its own type system had to be revised. XPath Version 1 recognized only four types: Boolean, string, "number" (a double-precision, floating numeric type), and "node-set" (an unordered collection of nodes). XPath Version 1 was designed with a very permissive view of types, in which conversions of one type to another could be done with very few limitations. For example, if a node-set is encountered where a number is expected, the string value of the first node in the node-set (in document order) is extracted and cast into a number. These permissive rules were deliberately designed to minimize the likelihood of non-recoverable errors during the processing of path expressions, which are often used in rendering web pages by a browser or in other contexts where run-time errors are unwelcome. From a type system based on only four types, XPath had to be adapted to the type system of XML Schema, which included forty-four built-in types and a complex set of rules for defining additional types, encompassing atomic, simple, complex, primitive, derived, list, union, and anonymous types, as well as two forms of inheritance, twelve "constraining facets," substitution groups, and various other features. Also, from a very permissive set of type-conversion rules, XPath had to be adapted to a philosophy of strict typing, including both static and dynamic type-checking. Users of XPath were assured that these changes constituted an improvement. Adaptation of XPath to the XML Schema type system also provided an opportunity to make a very small number of incompatible changes to the semantics of the language. Syntax and SemanticsThe adoption of XPath as a subset had significant effects on both the syntax and semantics of XQuery, including the following:
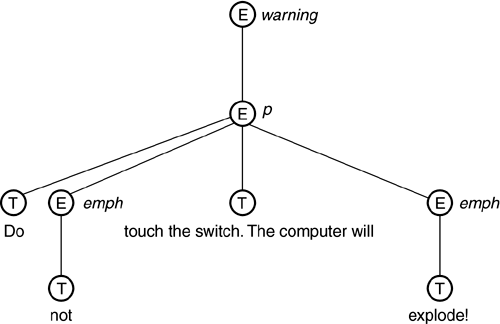
Document order is an ordering that is defined among all the nodes in the Query data model representation of a document. As defined in XPath, document order corresponds to the order in which the XML representations of the various nodes would be encountered if the document were to be serialized in XML format. In other words, each element node is followed by its namespace nodes, its attribute nodes, and its children (text, element, comment, and processing instruction nodes) in the order in which they naturally appear in the document. Reverse document order is defined as the reverse of document order. One of the defining features of XPath is the path expression , which consists of a series of steps , each of which selects a set of nodes. In the set of nodes selected by a step, each node has a position based on its relationship to the other nodes in (forward or reverse) document order. In effect, the set of nodes resulting from each step must be sorted on the basis of document order, a potentially expensive process. The idea of sorting intermediate results was particularly unfamiliar to people with a background in relational databases, in which sets of data values have no intrinsic order. The working group briefly considered relaxing this requirement and allowing the nodes selected by each step to remain in the order in which they were generated (based on iterating over the nodes selected by the previous step). This idea was put to rest by an example suggested by Michael Kay. The example is based on the following input document: <warning> <p> Do <emph>not </emph> touch the switch. The computer will <emph>explode!</emph> </p> </warning> The representation of this input document in the Query data model is shown in Figure 2.2, in which element nodes are represented as circles labeled E , and text nodes are represented as circles labeled T . Figure 2.2. Query Data Model Representation of "Warning" Document Against this input document we wish to execute the following path expression: /warning//text() In XPath Version 1, this path expression would return all the text nodes that are descendants of the warning element, in document order. The concatenated content of these nodes is as follows : Do not touch the switch. The computer will explode! It is interesting to consider how the result of this path expression would change if each step in the path preserved the order of nodes generated by the previous step rather than sorting its results in document order. Under these rules, the path expression would be executed as follows:
The concatenated contents of the text nodes returned by the final step is as follows: Do touch the switch. The computer will not explode! This example is a good illustration of how processing documents places some requirements on a query language that are beyond the scope of a traditional database query language. The Query working group included representatives from both the database and document processing communities, and these individuals had much to learn from each other during the process of designing XQuery. PredicatesXPath has several kinds of predicates , which are tests that are used to filter sequences of nodes. All of these predicates have the general form E1[E2] , in which the expression E2 is used to filter the items in the sequence generated by expression E1 . The different kinds of XPath predicates are illustrated by the following examples:
For XQuery, it was necessary to preserve all these kinds of predicates, but to generalize their definitions so that the value of an expression (either E1 or E2 in the above format) could be a heterogeneous sequence of nodes and atomic values. In XQuery, E1[E2] is defined as follows: For each item e1 in the sequence returned by E1 , the expression E2 is evaluated with e1 as the context item (the context item serves as the "starting point" for a path expression). For a given e1 , if E2 returns a number n , the value e1 is retained only if its ordinal position in the E1 -sequence is equal to n . Otherwise, e1 is retained only if the Effective Boolean Value of E2 is true . Effective Boolean Value is defined to be false for an empty sequence and for the following single atomic values: the Boolean value false , a numeric or binary zero, a zero-length string, or the special float value NaN . Any other sequence has an Effective Boolean Value of true . Note especially that the Effective Boolean Value of any node is true , regardless of its content, and the Effective Boolean Value of any sequence of length greater than one is true , regardless of its content. This definition of Effective Boolean Value is used not only in predicates but also in other parts of XQuery where it is necessary to reduce a general sequence to a Boolean value (for example, in conditional expressions and quantified expressions). The definition was arrived at by considerations of XPath Version 1 compatibility, logical consistency, and performance. This definition has the desirable property that the Effective Boolean Value of a sequence of arbitrary length depends only on the value of the first item in the sequence and the existence (but not the values) of additional items. It also has the surprising property that an element with the Boolean content false has an Effective Boolean Value of true (as required for compatibility with XPath Version 1). Another surprising property of this definition is that a sequence of atomic values, all of which are false , has the Effective Boolean Value of true (because it contains more than one item). Implicit Operations and TransitivityXPath Version 1 is defined to perform many implicit conversions during the processing of an expression. Some of these conversions are illustrated by the following example: //book[author = "Mark Twain"] On the left side of the = operator, we find author , which denotes a sequence of zero or more element nodes. On the right side of the = operator, we find "Mark Twain" , which is a string. Since a sequence of zero or more nodes is not the same thing as a string, these expressions are made comparable by the following implicit actions:
These implicit actions make the above expression equivalent to the following expression in which the same actions are represented explicitly: //book[some $a in ./author satisfies string(data($a)) = "Mark Twain"] In keeping with the basic principle of conciseness as well as the principle of backward compatibility, XQuery preserved these implicit XPath conversions and in fact extended them in a uniform way to apply to other parts of the XQuery language. The extraction of atomic values from nodes is called atomization in XQuery, and is applied to sequences as well as to individual nodes. For example, the expression avg(/employee/salary) extracts numeric values from a sequence of salary nodes before applying the avg function. The implicit conversions described above led to a serious concern for the designers of XQuery: They caused the comparison operators such as = and > to lack the transitivity property. Thus, if $book1/author = $book2/author is true , and $book2/author = $book3/author is true , it is not possible to conclude that $book1/author = $book3/author is true . For example, this inference would fail if $book1/author has the value ("Billy", "Bonnie"), $book2/author has the value ("Bonnie", "Barry"), and $book3/author has the value ("Barry", "Benny"). Transitivity is a useful property for comparison operators. For example, transitivity of equality comparisons is required for certain kinds of query transforms that are useful in optimization. Transitivity of a comparison operator is also required if the operator is to serve as the basis for imposing a global ordering on a sequence of values. Since the six general comparison operators ( = , != , > , >= , < , and <= ) lack transitivity, the designers of XQuery decided to supplement them with six more primitive value comparison operators ( eq , ne , gt , ge , lt , and le ) that have the transitivity property. These primitive comparison operators can be used to compare single atomic values, but they raise an error if either of the operands to be compared is not a single value. The value comparison operators always treat an untyped operand as a string. Incompatible ChangesDespite the general objective of backward compatibility, a small number of XPath Version 1 features remained unacceptable to the designers of XQuery. Some of these features were considered important for other usages of XPath, such as XSLT style sheets that had been written to exploit these features. To deal with this problem, an "XPath Version 1 compatibility mode" was defined for XPath Version 2. When embedded in XQuery, XPath Version 2 will not run in compatibility mode, and the semantics of certain operators will be different from those of XPath Version 1. Other host environments of XPath Version 2, such as XSLT, are free to interpret XPath Version 2 in compatibility mode to preserve the semantics expected by existing applications. The cases in which compatibility mode influences the semantics of XPath Version 2 include the following:
Other Query LanguagesThe influence of other languages on XQuery is not limited to directly related standards such as XPath and XML Schema. XQuery has also been strongly influenced by other query languages used in both the database and information retrieval communities. In several cases, designers of these precursor languages have also contributed to the design of XQuery. The immediate ancestor of XQuery is Quilt [QUILT], a language proposal submitted to the XML Query Working Group by three of its participants in June 2000. Quilt provided the basic framework of XQuery as a functional language based on several types of composable expressions, including an iterative expression and an element constructor. The FLWOR expression, one of the most important of the XQuery expression types, was adopted from Quilt (though the original Quilt version did not have an order-by clause). From its origin in the Quilt proposal, XQuery has evolved by changing the syntax for element constructors, adding a more complex syntax for declaring the types of function parameters, and adding some new kinds of expressions, such as validate , instance-of , and typeswitch . The XQuery specification is also much more complete and rigorous than the original Quilt proposal in formally specifying the semantics of various kinds of expressions, as described in Chapter 4. The Quilt proposal, in turn, reflects the influence of several other query languages. In fact, the name "Quilt" was intended to suggest that features had been patched together from a variety of sources to form a new language. From SQL [SQL99] and from the relational database community in general, XQuery adopted an English-keyword notation and a rich collection of use cases. Many SQL facilities such as grouping and outer join have their counterparts in XQuery, though they are often expressed in different ways. The select-from-where query block of SQL has a rough analogy in the for-let-where-order-return (FLWOR) expression of XQuery, in the sense that both kinds of expression are used for both selection (retaining certain items while discarding others) and projection (retaining certain properties of the selected items while discarding others.) Some features of SQL, however, such as a special null value and three-valued logic for the and and or operators, were considered unnecessary in the XML context and were not duplicated in XQuery. From XML-QL [XML-QL], Quilt (and hence XQuery) adopted the approach of binding variables to sequences of values and then constructing new output elements based on the bound variables. An XML-QL query consists of a WHERE clause followed by a CONSTRUCT clause. The result of the WHERE clause is a stream of tuples of bound variables. The CONSTRUCT clause is executed once for each of these tuples, generating a stream of output elements. As in XQuery, the combination of WHERE and CONSTRUCT is a nestable unit from which queries can be constructed. The creation of an ordered stream of tuples, and iteration over these tuples to generate output, have direct counterparts in the FLWOR expression of XQuery. XQuery also adopted from XML-QL the convention of prefixing variable names with a $ sign. From OQL [OQL], Quilt (and hence XQuery) adopted the approach of designing the language around a fully composable set of expressions, all of which use a common data model for their operands and results. The select-from-where expression of OQL, rather than providing a frame work for the whole language, as in SQL, is simply one of several independent expressions that include arithmetic and set operators, function calls, and universal and existential quantifiers. Similarly, in XQuery, the FLWOR expression is simply one of many types of expressions that can be combined in various ways. The atoms , structures, and collections in the OQL data model are suggestive of the atomic values, elements, and sequences in the Query data model (though the Query data model supports only one kind of collection). Interestingly, OQL (like Quilt) has a fully independent sort -by operator that can be applied to any sequence of values, whereas in XQuery the sorting facility is supported only as a clause inside the FLWOR expression, for reasons described under Issue 8 ("Ordering Operators") in the following section. |
EAN: 2147483647
Pages: 102