3.3 REGULAR GRAMMAR
3.2 CONTEXT-FREE GRAMMAR
CFG notation specifies a context-free language that consists of terminals, nonterminals , a start symbol, and productions . The terminals are nothing more than tokens of the language, used to form the language constructs. Nonterminals are the variables that denote a set of strings. For example, S and E are nonterminals that denote statement strings and expression strings, respectively, in a typical programming language. The nonterminals define the sets of strings that are used to define the language generated by the grammar.
They also impose a hierarchical structure on the language, which is useful for both syntax analysis and translation. Grammar productions specify the manner in which the terminals and string sets, defined by the nonterminals, can be combined to form a set of strings defined by a particular nonterminal. For example, consider the production S ’ aSb . This production specifies that the set of strings defined by the nonterminal S are obtained by concatenating terminal a with any string belonging to the set of strings defined by nonterminal S , and then with terminal b . Each production consists of a nonterminal on the left-hand side, and a string of terminals and nonterminals on the right-hand side. The left-hand side of a production is separated from the right-hand side using the " ’ " symbol, which is used to identify a relation on a set ( V ˆ T )*.
Therefore context-free grammar is a four-tuple denoted as:
where:
-
V is a finite set of symbols called as nonterminals or variables,
-
T is a set a symbols that are called as terminals,
-
P is a set of productions, and
-
S is a member of V , called as start symbol.
For example:
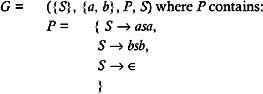
3.2.1 Derivation
Derivation refers to replacing an instance of a given string's nonterminal, by the right-hand side of the production rule, whose left-hand side contains the nonterminal to be replaced . Derivation produces a new string from a given string; therefore, derivation can be used repeatedly to obtain a new string from a given string. If the string obtained as a result of the derivation contains only terminal symbols, then no further derivations are possible. For example, consider the following grammar for a string S :
where P contains the following productions:
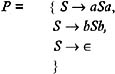
It is possible to replace the nonterminal S by a string aSa . Therefore, we obtain aSa from S by deriving S to aSa . It is possible to replace S in aSa by ˆˆ , to obtain a string aa , which cannot be further derived.
If ± 1 and ± 2 are the two strings, and if ± 2 can be obtained from ± 1 , then we say ± 1 is related to ± 2 by "derives to relation," which is denoted by " ’ ". Hence, we write ± 1 ’ ± 2 , which translates to: ± 1 derives to ± 2 . The symbol ’ denotes a derive to relation that relates the two strings ± 1 and ± 2 such that ± 2 is a direct derivative of ± 1 (if ± 2 can be obtained from ± 1 by a derivation of only one step). Therefore, ![]() will denote the transitive closure of derives to relation, and if we have the two strings ± 1 and ± 2 such that ± 2 can be obtained from ± 1 by derivation, but ± 2 may not be a direct derivative of ± 1 , then we write ± 1
will denote the transitive closure of derives to relation, and if we have the two strings ± 1 and ± 2 such that ± 2 can be obtained from ± 1 by derivation, but ± 2 may not be a direct derivative of ± 1 , then we write ± 1 ![]() ± 2 , which translates to: ± 1 derives to ± 2 through one or more derivations.
± 2 , which translates to: ± 1 derives to ± 2 through one or more derivations.
Similarly, ![]() denotes the reflexive transitive closure of derives to relation; and if we have two strings ± 1 and ± 2 such that ± 1 derives to ± 2 in zero, one, or more derivations, then we write ± 1
denotes the reflexive transitive closure of derives to relation; and if we have two strings ± 1 and ± 2 such that ± 1 derives to ± 2 in zero, one, or more derivations, then we write ± 1 ![]() ± 2 . For example, in the grammar above, we find that S ’ aSa ’ abSba ’ abba . Therefore, we can write S
± 2 . For example, in the grammar above, we find that S ’ aSa ’ abSba ’ abba . Therefore, we can write S ![]() abba .
abba .
The language defined by a CFG is nothing but the set of strings of terminals that, in the case of the string S , can be generated from S as a result of derivations using productions of the grammar. Hence, they are defined as the set of those strings of terminals that are derivable from the grammar's start symbol. Therefore, if G = ( V , T , P , S ) is a grammar, then the language by the grammar is denoted as L ( G ) and defined as:
The above grammar can generate the string ˆˆ , aa , bb , abba , , but not aba .
3.2.2 Standard Notation
-
The capital letters toward the start of the alphabet are used to denote nonterminals (e.g., A , B , C , etc.).
-
Lowercase letters toward the start of the alphabet are used to denote terminals (e.g., a , b , c , etc.).
-
S is used to denote the start symbol.
-
Lowercase letters toward the end of the alphabet (e.g., u , v , w , etc.) are used to denote strings of terminals.
-
The symbols ± , ² , ³ , and so forth are used to denote strings of terminals as well as strings of nonterminals.
-
The capital letters toward the end of alphabet (e.g., X , Y , and Z ) are used to denote grammar symbols, and they may be terminals or nonterminals.
The benefit of using these notations is that it is not required to explicitly specify all four grammar components . A grammar can be specified by only giving the list of productions; and from this list, we can easily get information about the terminals, nonterminals, and start symbols of the grammar.
3.2.3 Derivation Tree or Parse Tree
When deriving a string w from S , if every derivation is considered to be a step in the tree construction, then we get the graphical display of the derivation of string w as a tree. This is called a "derivation tree" or a "parse tree" of string w . Therefore, a derivation tree or parse tree is the display of the derivations as a tree. Note that a tree is a derivation tree if it satisfies the following requirements:
-
All the leaf nodes of the tree are labeled by terminals of the grammar.
-
The root node of the tree is labeled by the start symbol of the grammar.
-
The interior nodes are labeled by the nonterminals.
-
If an interior node has a label A , and it has n descendents with labels X 1 , X 2 , , X n from left to right, then the production rule A ’ X 1 X 2 X 3 X n must exist in the grammar.
For example, consider a grammar whose list of productions is:
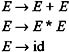
The tree shown in Figure 3.1 is a derivation tree for a string id + id * id.
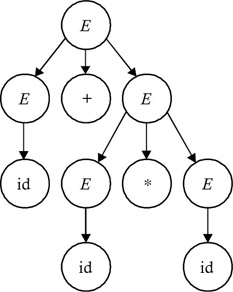
Figure 3.1: Derivation tree for the string id + id * id.
Given a parse (derivation) tree, a string whose derivation is represented by the given tree is one obtained by concatenating the labels of the leaf nodes of the parse tree in a left-to-right order.
Consider the parse tree shown in Figure 3.2. A string whose derivation is represented by this parse tree is abba .
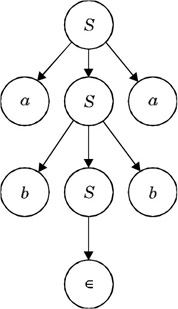
Figure 3.2: Parse tree resulting from leaf-node concatenation.
Since a parse tree displays derivations as a tree, given a grammar G = ( V , T , P , S ) for every w in T *, and which is derivable from S , there exists a parse tree displaying the derivation of w as a tree. Therefore, we can define the language generated by the grammar as:
For some w in L ( G ), there may exist more than one parse tree. That means that more than one way may exist to derive w from S , using the productions of the grammar. For example, consider a grammar having the productions listed below:
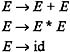
We find that for a string id + id* id, there exists more than one parse tree, as shown in Figure 3.3.
Figure 3.3: Multiple parse trees.
If more than one parse tree exists for some w in L ( G ), then G is said to be an "ambiguous" grammar. Therefore, the grammar having the productions E ’ E + E E * E id is an ambiguous grammar, because there exists more than one parse tree for the string id + id * id in L ( G ) of this grammar.
Consider a grammar having the following productions:
This grammar is also an ambiguous grammar, because more than one parse tree exists for a string abab in L ( G ), as shown in Figure 3.4.
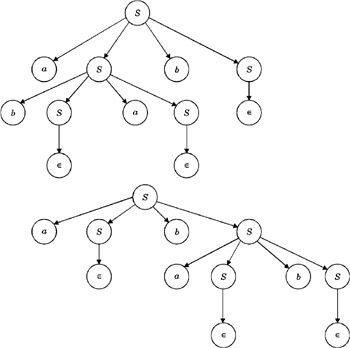
Figure 3.4: Ambiguous grammar parse trees.
The parse tree construction process is such that the order in which the nonterminals are considered for replacement does not matter. That is, given a string w , the parse tree for that string (if it exists) can be constructed by considering the nonterminals for derivation in any order. The two specific orders of derivation, which are important from the point of view of parsing, are:
-
Left-most order of derivation
-
Right-most order of derivation
The left-most order of derivation is that order of derivation in which a left-most nonterminal is considered first for derivation at every stage in the derivation process. For example, one of the left-most orders of derivation for a string id + id * id is:
In a right-most order of derivation, the right-most nonterminal is considered first. For example, one of the right-most orders of derivation for id + id* id is:
The parse tree generated by using the left-most order of derivation of id + id*id and the parse tree generated by using the right-most order of derivation of id + id*id are the same; hence, these orders are equivalent. A parse tree generated using these orders is shown in Figure 3.5.
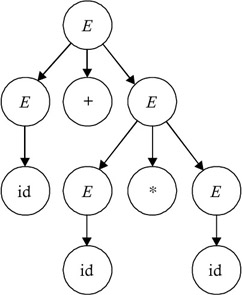
Figure 3.5: Parse tree generated by using both the right- and left-most derivation orders.
Another left-most order of derivation of id + id* id is given below:
And here is another right-most order of derivation of id + id*id:
The parse tree generated by using the left-most order of derivation of id + id* id and the parse tree generated using the right-most order of derivation of id + id* id are the same. Hence, these orders are equivalent. A parse tree generated using these orders is shown in Figure 3.6.
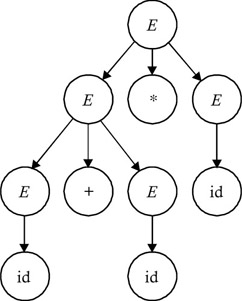
Figure 3.6: Parse tree generated from both the left- and right-most orders of derivation.
Therefore, we conclude that for every left-most order of derivation of a string w , there exists an equivalent right-most order of derivation of w , generating the same parse tree.
| Note | If a grammar G is unambiguous, then for every w in L ( G ), there exists exactly one parse tree. Hence, there exists exactly one left-most order of derivation and (equivalently) one right-most order of derivation for every w in L ( G ). But if grammar G is ambiguous, then for some w in L ( G ), there exists more than one parse tree. Therefore, there is more than one left-most order of derivation; and equivalently, there is more than one right-most order of derivation. |
3.2.4 Reduction of Grammar
Reduction of a grammar refers to the identification of those grammar symbols (called "useless grammar symbols"), and hence those productions, that do not play any role in the derivation of any w in L ( G ), and which we eliminate from the grammar. This has no effect on the language generated by the grammar. For example, a grammar symbol X is useful if and only if:
-
It derives to a string of terminals, and
-
It is used in the derivation of at least one w in L ( G ).
Thus, X is useful if and only if:
-
X
 w , where w is in T *, and
w , where w is in T *, and -
S
 ± X ²
± X ² 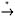 w in L ( G ).
w in L ( G ).
Therefore, reduction of a given grammar G , involves:
-
Identification of those grammar symbols that are not capable of deriving to a w in T * and eliminating them from the grammar; and
-
Identification of those grammar symbols that are not used in any derivation and eliminating them from the grammar.
When identifying the grammar symbols that do not derive a w in T *, only nonterminals need be tested , because every terminal member of T will also be in T *; and by default, they satisfy the first condition. A simple, iterative algorithm can be used to identify those nonterminals that do not derive to w in T *: we start with those productions that are of the form A ’ w that is, those productions whose right side is w in T *. We mark as nonterminal every A on the left side of every production that is capable of deriving to w in T *, and then we consider every production of the form A ’ X 1 X 2 X n , where A is not yet marked . If every X , (for 1<= i <= n ) is either a terminal or a nonterminal that is already marked, then we mark A (nonterminal on the left side of the production).
We repeat this process until no new nonterminals can be marked. The nonterminals that are not marked are those not deriving to w in T *. After identifying the nonterminals that do not derive to w in T *, we eliminate all productions containing these nonterminals in order to obtain a grammar that does not contain any nonterminals that do not derive in T *. The algorithm for identifying as well as eliminating the nonterminals that do not derive to w in T * is given below:
| Input: | G = ( V , T , P , S ) |
| Output: | G 1 = ( V 1 , T , P 1 , S ) |
Let U be the set of nonterminals that are not capable of deriving to w in T *.
Then, begin V 1 old = V 1 new = for every production of the form A w do V 1 new = V 1 new { A } while ( V 1 old V 1 new ) do begin temp = V V 1 new V 1 old = V 1 new For every A in temp do for every A-production of the form A X 1 X 2 ... X n in P do if each Xi is either in T or in V 1 old , then begin V 1 new = V 1 new { A } break; end end V 1 = V 1 new U = V V 1 for every production in P do if it does not contain a member of U then add the production to P 1 end
If S is itself a useless nonterminal, then the reduced grammar is a ˜null grammar.
When identifying the grammar symbols that are not used in the derivation of any w in L ( G ), terminals as well as nonterminals must be tested. A simple, iterative algorithm can be used to identify those grammar symbols that are not used in the derivation of any w in L ( G ): we start with S -productions and mark every grammar symbol X on the right side of every S -production. We then consider every production of the form A ’ X 1 X 2 X n , where A is an already-marked nonterminal; and we mark every X on the right side of these productions. We repeat this process until no new nonterminals can be marked. We do not mark any terminals or nonterminals not used in the derivation of any w in L ( G ). After identifying the terminals and nonterminals not used in the derivation of any w in L ( G ), we eliminate all productions containing them; thus, we obtain a grammar that does not contain any useless symbols-hence, a reduced grammar.
The algorithm for identifying as well as eliminating grammar symbols that are not used in the derivation of any w in L ( G ) is given below:
| Input: | G 1 = ( V 1 , T , P 1 , S ) |
| Output: | G 2 = ( V 2 , T 2 , P 2 , S ) |
begin T 2 = V 2 old = P 2 = V 2 new = { S } While (V 2 old # V 2 new ) do begin temp = V 2 new - V 2 old V 2 old = V 2 new for every A in temp do for every A-production of the form A X 1 X 2 ... X n in P 1 do for each X i (1 <= i <= n) do begin if ( X i is in V 2 old ) then V 2 new = V 2 new { X i } if ( X 1 is in T ) then T 2 = T 2 { X i } end V 2 = V 2 new temp 1 = V 1 V 2 temp 2 = T 1 T 2 for every production in P 1 do add the production to P 2 if it does not contain a member of temp 1 as well as temp 2 G 2 = ( V 2 , T 2 , P 2 , S ) end end
| |
Find the reduced grammar equivalent to CFG
where P contains
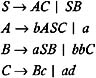
| |
Since the productions A ’ a and C ’ ad exist in form A ’ w , nonterminals A and C are derivable to w in T *, The production S ’ AC also exists, the right side of which contains the nonterminals A and C , which are derivable to w in T *. Hence, S is also derivable to w in T *. But since the right side of both of the B -productions contain B , the nonterminal B is not derivable to w in T *.
Hence, B can be eliminated from the grammar, and the following grammar is obtained:
where P 1 contains
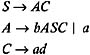
Since the right side of the S -production of this grammar contains the nonterminals A and C , A and C will be used in the derivation of some w in L ( G ). Similarly, the right side of the A -production contains bASC and a ; hence, the terminals a and b will be used. The right side of the C -production contains ad , so terminal d will also be useful. Therefore, every terminal, as well as the nonterminal in G 1, is useful. So the reduced grammar is:
where P 1 contains
3.2.5 Useless Grammar Symbols
A grammar symbol is a useless grammar symbol if it does not satisfy either of the following conditions:
That is, a grammar symbol X is useless if it does not derive to terminal strings. And even if it does derive to a string of terminals, X is a useless grammar symbol if it does not occur in a derivation sequence of any w in L ( G ). For example, consider the following grammar:
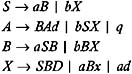
First, we find those nonterminals that do not derive to the string of terminals so that they can be separated out. The nonterminals A and X directly derive to the string of terminals because the production A ’ q and X ’ ad exist in a grammar. There also exists a production S ’ bX , where b is a terminal and X is a nonterminal, which is already known to derive to a string of terminals. Therefore, S also derives to string of terminals, and the nonterminals that are capable of deriving to a string of terminals are: S , A , and X . B ends up being a useless nonterminal; and therefore, the productions containing B can be eliminated from the given grammar to obtain the grammar given below:
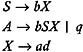
We next find in the grammar obtained those terminals and nonterminals that occur in the derivation sequence of some w in L ( G ). Since every derivation sequence starts with S , S will always occur in the derivation sequence of every w in L ( G ). We then consider those productions whose left-hand side is S , such as S ’ bX , since the right side of this production contains a terminal b and a nonterminal X . We conclude that the terminal b will occur in the derivation sequence, and a nonterminal X will also occur in the derivation sequence. Therefore, we next consider those productions whose left-hand side is a nonterminal X . The production is X ’ ad . Since the right side of this production contains terminals a and d , these terminals will occur in the derivation sequence. But since no new nonterminal is found, we conclude that the nonterminals S and X , and the terminals a , b , and d are the grammar symbols that can occur in the derivation sequence. Therefore, we conclude that the nonterminal A will be a useless nonterminal, even though it derives to the string of terminals. So we eliminate the productions containing A to obtain a reduced grammar, given below:
| |
Consider the following grammar, and obtain an equivalent grammar containing no useless grammar symbols.
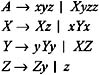
| |
Since A ’ xyz and Z ’ z are the productions of the form A ’ w , where w is in T *, nonterminals A and Z are capable of deriving to w in T *. There are two X -productions: X ’ Xz and X ’ xYx . The right side of these productions contain nonterminals X and Y , respectively. Similarly, there are two Y -productions: Y ’ yYy and Y ’ XZ . The right side of these productions contain nonterminals Y and X , respectively. Hence, both X and Y are not capable of deriving to w in T *. Therefore, by eliminating the productions containing X and Y , we get:
Since A is a start symbol, it will always be used in the derivation of every w in L ( G ). And since A ’ xyz is a production in the grammar, the terminals x , y , and z will also be used in the derivation. But no nonterminal Z occurs on the right side of the A -production, so Z will not be used in the derivation of any w in L ( G ). Hence, by eliminating the productions containing nonterminal Z , we get:
which is a grammar containing no useless grammar symbols.
| |
Find the reduced grammar that is equivalent to the CFG given below:
| |
Since C ’ ad is the production of the form A ’ w , where w is in T *, nonterminal C is capable of deriving to w in T *. The production S ’ aC contains a terminal a on the right side as well as a nonterminal C that is known to be capable of deriving to w in T *.
Hence, nonterminal S is also capable of deriving to w in T *. The right side of the production A ’ bSCa contains the nonterminals S and C , which are known to be capable of deriving to w in T *. Hence, nonterminal A is also capable of deriving to w in T *. There are two B -productions: B ’ aSB and B ’ bBC . The right side of these productions contain the nonterminals S , B , and C ; and even though S and C are known to be capable of deriving to w in T *, nonterminal B is not. Hence, by eliminating the productions containing B , we get:
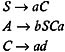
Since S is a start symbol, it will always be used in the derivation of every w in L ( G ). And since S ’ aC is a production in the grammar, terminal a as well as nonterminal C will also be used in the derivation. But since a nonterminal C occurs on the right side of the S -production, and C ’ ad is a production, terminal d will be used along with terminal a in the derivation. A nonterminal A , though, occurs nowhere in the right side of either the S -production or the C -production; it will not be used in the derivation of any w in L ( G ). Hence, by eliminating the productions containing nonterminal A , we get:
which is a reduced grammar equivalent to the given grammar, but it contains no useless grammar symbols.
| |
Find the useless symbols in the following grammar, and modify the grammar so that it has no useless symbols.
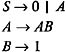
| |
Since S ’ 0 and B ’ 1 are productions of the form A ’ w , where w is in T *, the nonterminals S and B are capable of deriving to w in T *. The production A ’ AB contains the nonterminals A and B on the right side; and even though B is known to be capable of deriving to w in T *, nonterminal A is not capable of deriving to w in T *. Therefore, by eliminating the productions containing A , we get:
Since S is a start symbol, it will always be used in the derivation of any w in L ( G ). And because S ’ 0 is a production in the grammar, terminal 0 will also be used in the derivation. But nonterminal B does not occur anywhere in the right side of the S -production, it will not be used in the derivation of any w in L ( G ). Hence, by eliminating the productions containing nonterminal B , we get:
which is a grammar equivalent to the given grammar and contains no useless grammar symbols.
| |
Find the useless symbols in the following grammar, and modify the grammar to obtain one that has no useless symbols.
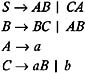
| |
Since A ’ a and C ’ b are productions of the form A ’ w , where w is in T *, the nonterminals A and C are capable of deriving to w in T *. The right side of the production S ’ CA contains nonterminals C and A , both of which are known to be derivable to w in T *.
Hence, S is also capable of deriving to w in T *. There are two B -productions, B ’ BC and B ’ AB . The right side of these productions contain the nonterminals A , B , and C . Even though A and C are known to be capable of deriving to w in T *, nonterminal B is not capable of deriving to w in T *. Therefore, by eliminating the productions containing B , we get:
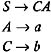
Since S is a start symbol, it will always be used in the derivation of every w in L ( G ). And since S ’ CA is a production in the grammar, nonterminals C and A will both be used in the derivation. For the productions A ’ a and C ’ b , the terminals a and b will also be used in the derivation. Hence, every grammar symbol in the above grammar is useful. Therefore, a grammar equivalent to the given grammar that contains no useless grammar symbols is:
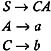
3.2.6 ˆˆ -Productions and Nullable Nonterminals
A production of the form A ’ ˆˆ is called a " ˆˆ -production". If A is a nonterminal, and if A ![]() ˆˆ (i.e., if A derives to an empty string in zero, one, or more derivations), then A is called a "nullable nonterminal".
ˆˆ (i.e., if A derives to an empty string in zero, one, or more derivations), then A is called a "nullable nonterminal".
Algorithm for Identifying Nullable Nonterminals
| Input: | G = ( V , T , P , S ) |
| Output: | Set N (i.e., the set of nullable nonterminals) |
begin N old = N new = for every production of the form A do N new = N new { A } while ( N old N new ) do begin temp = V - N new N old = N new For every A in temp do for every A -production of the form A X 1 X 2 ... X n in P do if each X 1 is in N old then N new = N new { A } end N = N new end
| |
Consider the following grammar and identify the nullable nonterminals.
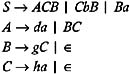
| |
By applying the above algorithm, the results after each iteration are shown below:
Initially:
After the first execution of the for loop:
After the first iteration of the while loop:
After the second iteration of the while loop:
After the third iteration of the while loop:
Therefore, N = { S , A , B , C }; and hence, all the nonterminals of the grammar are nullable.
3.2.7 Eliminating ˆˆ -Productions
Given a grammar G that contains ˆˆ -productions, if L ( G ) does not contain ˆˆ , then it is possible to eliminate all ˆˆ -productions in the given grammar G . Whereas, if L ( G ) contains ˆˆ , then elimination of all ˆˆ -productions from G gives a grammar G in which L ( G 1 ) = L ( G ) - { ˆˆ }. To eliminate the ˆˆ -productions from a grammar, we use the following technique.
If A ’ ˆˆ is an ˆˆ -production to be eliminated, then we look for all those productions in the grammar whose right side contains A , and we replace each occurrence of A in these productions. Thus, we obtain the non- ˆˆ -productions to be added to the grammar so that the language's generation remains the same. For example, consider the following grammar:
To eliminate A ’ ˆˆ form the above grammar, we replace A on the right side of the production S ’ aA and obtain a non- ˆˆ -production, S ’ a , which is added to the grammar as a substitute in order to keep the language generated by the grammar the same. Therefore, the ˆˆ -free grammar equivalent to the given grammar is:
| |
Consider the following grammar, and eliminate all the ˆˆ -productions from the grammar without changing the language generated by the grammar.
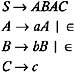
| |
To eliminate A ’ ˆˆ from this grammar, the non- ˆˆ -productions to be added are obtained as follows : the list of the productions containing A on the right-hand side is:
Replace each occurrence of A in each of these productions in order to obtain the non- ˆˆ -productions to be added to the grammar. The list of these productions is:
Add these productions to the grammar, and eliminate A ’ ˆˆ from the grammar. This gives us the following grammar:
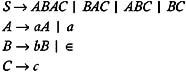
To eliminate B ’ ˆˆ from the grammar, the non- ˆˆ -productions to be added are obtained as follows. The productions containing B on the right-hand side are:
Replace each occurrence of B in these productions in order to obtain the non- ˆˆ -productions to be added to the grammar. The list of these productions is:
Add these productions to the grammar, and eliminate A ’ ˆˆ from the grammar in order to obtain the following:
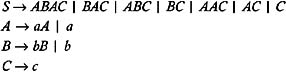
| |
Consider the following grammar and eliminate all the ˆˆ -productions without changing the language generated by the grammar.
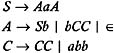
| |
To eliminate A ’ ˆˆ from the grammar, the non- ˆˆ -productions to be added are obtained as follows: the list of productions containing A on right is:
Replace each occurrence of A in this production to obtain the non- ˆˆ -productions to be added to the grammar. This are:
Add these productions to the grammar, and eliminate A ’ ˆˆ from the grammar to obtain the following:
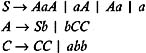
3.2.8 Eliminating Unit Productions
A production of the form A ’ B , where A and B are both nonterminals, is called a "unit production". Unit productions in the grammar increase the cost of derivations. The following algorithm can be used to eliminate unit productions from the grammar:
While there exist a unit production A B in the grammar do { select a unit production A B such that there exists at least one nonunit production B for every nonunit production B do add production A to the grammar eliminate A B from the grammar }
| |
Given the grammar shown below, eliminate all the unit productions from the grammar.
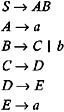
The given grammar contains the productions:
| |
which are the unit productions. To eliminate these productions from the given grammar, we first select the unit production B ’ C . But since no nonunit C -productions exist in the grammar, we then select C ’ D . But since no nonunit D -productions exist in the grammar, we next select D ’ E . There does exist a nonunit E -production: E ’ a . Hence, we add D ’ a to the grammar and eliminate D ’ E . But since B ’ C and C ’ D are still there, we once again select unit production B ’ C . Since no nonunit C -production exists in the grammar, we select C ’ D . Now there exists a nonunit production D ’ a in the grammar. Hence, we add C ’ a to the grammar and eliminate C ’ D . But since B ’ C is still there in the grammar, we once again select unit production B ’ C . Now there exists a nonunit production C ’ a in the grammar, so we add B ’ a to the grammar and eliminate B ’ C . Now no unit productions exist in the grammar. Therefore, the grammar that we get that does not contain unit productions is:
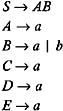
But we see that the grammar symbols C , D , and E become useless as a result of the elimination of unit productions, because they will not be used in the derivation of any w in L ( G ). Hence, we can eliminate them from the grammar to obtain:
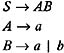
Therefore, we conclude that to obtain the grammar in the most simplified form, we have to eliminate unit productions first. We then eliminate the useless grammar symbols.
3.2.9 Eliminating Left Recursion
If a grammar contains a pair of productions of the form A ’ A ± ² , then the grammar is a "left-recursive grammar". If left-recursive grammar is used for specification of the language, then the top-down parser specified by the grammar's language may enter into an infinite loop during the parsing process on some erroneous input. This is because a top-down parser attempts to obtain the left-most derivation of the input string w; hence, the parser may see the same nonterminal A every time as the left-most nonterminal. And every time, it may do the derivation using A ’ A ± . Therefore, for top-down parsing, nonleft-recursive grammar should be used. Left-recursion can be eliminated from the grammar by replacing A ’ A ± ² with the productions A ’ ² B and B ’ ±² ˆˆ . In general, if a grammar contain productions:
then the left-recursion can be eliminated by adding the following productions in place of the ones above.
| |
Consider the following grammar:
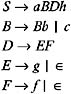
| |
The grammar is left-recursive because it contains a pair of productions, B ’ Bb c . To eliminate the left-recursion from the grammar, replace this pair of productions with the following productions:
Therefore, the grammar that we get after the elimination of left-recursion is:
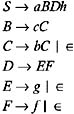
| |
Consider the following grammar:
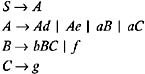
| |
The grammar is left-recursive because it contains the productions A ’ Ad Ae aB aC . To eliminate the left-recursion from the grammar, replace these productions by the following productions:
Therefore, the resulting grammar after the elimination of left-recursion is:
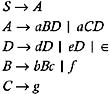
| |
Consider the following grammar:
| |
The grammar is left-recursive because it contains the productions L ’ L , S S . To eliminate the left-recursion from the grammar, replace these productions by the following productions:
Therefore, after the elimination of left-recursion, we get:
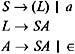
EAN: 2147483647
Pages: 108