6.1 TOKENS, IDENTIFIERS, AND VARIABLE NAMES
|
6.1 TOKENS, IDENTIFIERS, AND VARIABLE NAMES
Tokens are the most basic syntactical constituents of source code. The set of all tokens can be visualized as shown in Figure 6.1. A token can be an operator, such as +, *, etc.; a keyword, such as main, #include, etc.; a string literal; a punctuation; an identifier; and so on. In both C++ and Java, tokens can be delimited by white space (meaning, spaces, tabs, newline characters, and form-feed characters)[1] and by operators, punctuation marks, and other symbols that are not permitted to be within identifiers, keywords, and so on. As illustration, the number of tokens in
cout << "Height is: " + height << endl;
is 8. The first three and the last two tokens are NOT separated by white space.
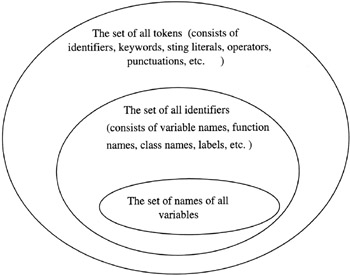
Figure 6.1
Let's now talk about identifiers, since a variable name must be an identifier. Identifiers in both C++ and Java are used for naming constants, variables, labels, functions, objects, classes, and so on. In both C++ and Java, an identifier consists of a sequence of characters that must be letters or digits or the underscore character (_), with the stipulation that the first character is either a letter or the underscore. Some examples of identifiers in C++ are
x y i j hello var0 var1 var_x var_y ....
Identifiers in C++ are usually written using the 7-bit ASCII character set. As you know already from C, ASCII associates with each character a binary code word whose decimal value is between 0 and 127 (that is, the binary code words range from 0000000 to 1111111). For example, the binary pattern associated with the letter A has a decimal value of 65. Some computers extend ASCII to 8 bits so that 256 characters can be represented.
An identifier in Java looks very much like an identifier in C++ except that the definition of a letter and a digit is now much broader because a 16-bit Unicode representation is used for characters in Java. This means Java can use a character set containing 65,536 characters. The first 256 characters of Unicode constitute the Latin-1 character set and the first 128 of these are equivalent to the 7-bit ASCII character set. The 16-bit representation for characters allows for letters and digits from many different geographical regions of the world to be included in a Java identifier. Current Java environments read ASCII or Latin-1 files, converting them to Unicode on the fly. Converting an ASCII character to a Unicode character means in most cases extending the bit pattern of an ASCII character with a byte of zeros.
[1]That white space is not always a delimiter of tokens should be clear from the fact that it can appear as the content of a character literal or as a part of a string literal:
char ch = ' '; string str = "hi there";
|
EAN: 2147483647
Pages: 273