Early Bus Networks (10BASE-5 and 10BASE-2)
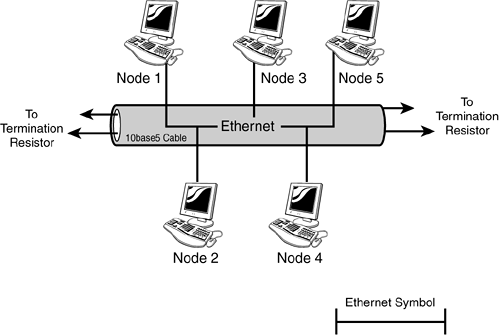
| About this time a consortium of manufacturers working at Xerox's PARC (Pacific Area Research Center) released a really strange device called "Ethernet" that would do exactly what was needed ”namely share PC resources. Ethernet used signaling that was well into the radio frequency spectrum and utilized a long coaxial cable (up to 500 meters ) as a medium to connect PCs and peripherals. A coaxial cable consists of a single copper center conductor, covered by a dielectric material (insulator), which in turn is covered by a braid of copper wire, all of which is covered by a polyvinyl chloride (PVC) or Teflon jacket. (See Figure 3.1.) Figure 3.1. Coaxial Cable. It is easy to see why installers preferred 10BASE-2 cable (right) over 10BASE-5 cable (left). This type of cable is relatively immune to radio frequency interference from the outside, and also does a good job of containing radio frequency signals on the inside. Without these two properties, the cable would actually become a huge antenna, with all kinds of nasty consequences. However, there is a downside to this type of cable, and all other cables, including fiber optics. The downside is that an impedance mismatch will reflect a signal. An impedance mismatch occurs where the properties of the cable change. Joining a cable to another with different properties will create an impedance mismatch. Nicking a cable will also create a mismatch, or we can go for the biggest mismatch of all and just whack the thing in half. Of course, all cables must end one way or another, so to avoid the resulting impedance mismatch, both ends of the coaxial cable were terminated with resistors (terminators). These terminators would dissipate the electrical energy rather than reflect it (see Figure 3.2). This assembly in its entirety is called a backbone or bus topology . Figure 3.2. Bus topology. A bus topology provides a single transmission cable called a bus . Network nodes connecting to the bus share its transmission capacity. When coaxial cable is used for the bus, a terminator (resistor) must be installed at each end to eliminate reflections. Notice how the Ethernet symbol in the lower right resembles the bus design.
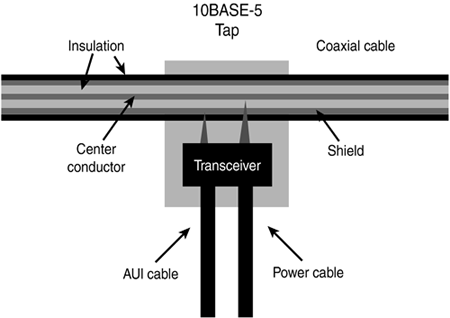
The backbone cable was a really good idea but without a way to attach stations or nodes it was useless, and this is where things got messy. Originally, nodes or stations were attached to the bus by way of a tap , which physically pierced the cable (see Figure 3.3). Figure 3.3. 10BASE-5 taps. These taps were quickly nicknamed vampire taps for obvious reasons, and the name has stayed with them ever since. The tap included a transceiver (transmitter/receiver) for signaling, and was attached to the PC by an attachment unit interface ( AUI ) cable. The AUI cable was often called a drop cable and closely resembled today's serial cable. The PC itself was provided an interface card for attaching the drop cable and a piece of software called a redirector that routed resource requests either to the transceiver for transmission on the bus or to a locally attached resource, such as a printer or hard disk.
The layout of a single transmission medium, like a coaxial cable, providing connectivity to a number of stations or nodes is referred to as a bus topology (actually, the proper name for the backbone is bus but in practice the terms are used interchangeably). Although multiple stations (Multiple Access) were connected to the bus, only one signal could traverse the bus at any one time ( Baseband). Multiple signals were eliminated because each of the network interfaces had a circuit that sensed voltage on the bus ( Carrier Sense ). If a voltage or carrier was present, the interface would delay transmission until the voltage again dropped to zero. So, a situation where two or more signals ended up on the bus at the same time would be highly unlikely .
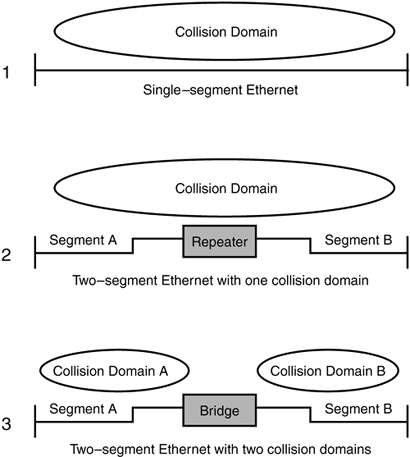
A signal takes time to move from one end of the bus to the other, so it is quite possible a station on one end would transmit, not knowing there was already a signal on the other end of the bus. Two or more signals on the bus would create an over-voltage condition, which (you guessed it) would be sensed ( Collision Detection ) by the same circuit that was monitoring the voltage in the first place. When this occurred, the network interface would send a jam signal to busy out the entire bus, wait for a random time period of no carrier or voltage on the bus, and then retransmit the original signal. The random period of time was to prevent a second collision when the two or more network interfaces that originally caused the collision retransmit. Now you know why all Ethernets are categorized as Carrier Sense, Multiple Access, Collision Detection ( CSMA / CD ) networks. Pushing Distance Limitations (Repeaters)The network we described previously was standardized as a 10BASE-5 (10Mbps, baseband, 500 meters) network and theoretically, if you stayed within the standards, everything would work fine. However, it was a lot cheaper to extend the bus a little over the 500 meter limit than to install a whole new bus, and that is what many people did. The problem was that as a signal travels down a medium, it loses a bit of its strength (attenuates) for every meter it travels . All standards tend to be conservative so in most cases this did not create a major problem. As people pushed the distance more and more, or used lower quality materials, attenuation began to cause problems. So it was not long before a nifty device called a repeater was developed to address signal attenuation. A repeater is a Layer 1 (Physical layer) device installed between two segments of a bus (the bus is actually cut and then reconnected through the repeater). A repeater does not care about addresses, frames , packets, or any of the upper-layer protocols we have discussed. A repeater simply senses a voltage or signal on one side, rebuilds and retimes the signal, and then sends it out the other side (repeats). Do not make the assumption, however, that repeaters eliminate distance restrictions. Like railroads, all networks operate on a foundation of timing. It takes time for a signal to move down a cable and it takes even more time for a repeater to rebuild, retime , and retransmit a signal. So long as we stay within the established timing standards for our type of network, everything is fine. If we exceed those standards, things get ugly fast (see Figure 3.4). Figure 3.4. A segment is always a subset of a network (1). Both a repeater and a bridge will divide a network into segments (2 & 3). However, only a device with bridging functionality will create separate collision domains as well as segments (3).
Pushing Station Limitations (Bridges)So now we have a flexible network that can be easily expanded and provides sharing of expensive resources. The requirements have been met and everybody is happy. Well, not quite. The economies generated by shared resources provided a very real and tangible incentive for adding more stations to the network, and that is exactly what companies did. After all, an Ethernet segment could have as many as 1,024 nodes, which should be far more than anybody would ever need. The problem was that very few organizations made it to 1,024 nodes. Degradation in response time and throughput became a problem long before the magic number 1,024 was ever reached. Even more disturbing were traffic studies that revealed an incredibly high number of collisions with very little data transiting the network. So what was happening? Well, it turns out that every node or station added to an Ethernet network increases the probability of a collision. When a collision occurs, the node interface sends out a jam signal that stops all transmission on the network. The interface then waits for a random period of silence before retransmitting the original frame of data. All of this takes time, and although the network is busy, very little data is moving across the network. At some point the network reaches its capacity of 10Mbps with the majority of that capacity used for collision recovery. Depending on the type of traffic, that ceiling is usually reached when approximately 4Mbps of data are moving across the network. Furthermore, if we attempt to push even more data through a saturated Ethernet, the total capacity available to data will decrease as the number of collisions increase. In short, Ethernet has the remarkable characteristic of providing excess capacity when you don't need it and reduced capacity when you do. Well, no engineer can tolerate this kind of situation so it was not long before another nifty device called a bridge was developed. A bridge allows you to cut the Ethernet cable and then reattach it using the bridge. The bridge, like a repeater, has two network interfaces, with each attached to a segment of the cable. When a frame is launched on one segment (let's call it "A"), the bridge copies the entire frame into a buffer, reads the source address and destination address, and performs a Cyclical Redundancy Check ( CRC ) to ensure the frame is complete and accurate.
A Cyclical Redundancy Check is a number attached to the end of a frame that was derived by running the digits of the frame through a specific computation. The bridge performs the same computation and if the resulting number is equal to the one stored in the CRC field, then the frame is considered accurate and complete. Because the bridge reads the entire frame, it is considered a Store and Forward device. The bridge then writes the source address of the frame to a reference table for segment "A" and checks to see if the destination address has also been logged as a source address on segment "A". If the destination address is in fact listed in the table, the bridge then knows that both the source and destination addresses are on segment "A" and the frame is discarded. However, if the destination address is not already listed in the table, the bridge assumes the address must be located on segment "B" and the frame is passed on through the second interface to segment "B". Of course the same thing is happening at the interface for segment "B". Within a few seconds the bridge will have compiled tables for the stations on both segments of the network and frames will either be checked and passed or stopped and discarded based on destination address and completeness of the frame. The ability of bridges to automatically build and update network tables led many to call them learning bridges. So, what did all of this really accomplish? First, traffic that is moving between stations on the same segment stayed on that segment and did not tie up the resources of the other segment. It was like gaining the capacity of two networks with all of the benefits of a single network. Secondly, because a CRC was performed on each frame needing transit across segments, only good frames were actually passed. This effectively limits collisions to a single segment which also frees the other segment to carry traffic. When a network is segmented with a bridge, each of the segments is considered a separate collision domain (see Figure 3.4). Prior to segmentation, the entire network was one collision domain. We can also add multiple bridges, and create multiple collision domains, which would greatly expand our capacity for additional stations.
So, with all of these benefits, was there a downside to using bridges? Of course, it took time for a bridge to read and analyze each frame. Multiple bridges could easily exceed the timing restrictions of a network. When this happened , stations or entire segments at one end of the network would be completely unaware that stations at the other end of the network had begun transmitting. The resulting collisions storms could and did shut down entire networks. It was also possible to accidentally create a loop with multiple bridges that would cause frames to endlessly race around the loop until the network got so clogged it could no longer function. The Spanning Tree Protocol ( STP ) was eventually developed so that bridges could communicate with each other to determine which bridges would be active and which would be held in reserve. This not only eliminated loops but also allowed for redundancy in the network. Even with these drawbacks, the bridge solved many more problems than it created and greatly advanced the capabilities of networking. Layer 3 Expansion (Routers)However (you knew this was coming didn't you?), there was one limitation to bridges that could not be overcome . That limitation had to do with scalability or size. I am sure you noticed how many times the term "frame" was used in the previous paragraphs. You already know from Chapter 2 that in the OSI model, "frame" is the PDU for Layer 2, and Layer 2 is where MAC addresses are defined. So it would not be unreasonable to assume that bridge functions were based on the MAC address of the network interface attached to stations in the network. If you made that assumption you are absolutely correct!
Bridges are Layer 2 devices and the foundation of their operation is the MAC address. You will probably also recall from Chapter 2 that MAC addresses have a problem with scalability. Maintaining a unique address across many networks required going to a higher level (Layer 3) where a logical network address was defined.
The need for a different address scheme was not the only problem encountered when data was passed across or between different networks. There was almost always a change in media type, signaling requirements, and interface hardware. The whole issue of network overhead also became a major problem. Network stations needed a way to identify the addresses of other stations on the network. One popular network software package accomplished this by having each station broadcast its MAC address every three seconds. Now imagine you bridged the networks of two remote corporate divisions over a 56Kb leased line that costs $100,000 a month. With every station broadcasting its address across that link every three seconds, how much real data could get through? Some other device was clearly needed and that device was called a router . Routers and bridges differ in that bridges use the MAC address (Layer 2) to perform their functions while routers use the network address (Layer 3). That, folks, "is the difference, the whole difference, and nothing but the difference"! Routers rely on a routing protocol for the definition and establishment of network addresses, and there is more than one protocol. You are already familiar with at least one routing protocol named IP, which is a part of TCP/IP and stands for Internet Protocol. Others include Novell's IPX and Apple's AppleTalk. However, regardless of protocol, all routers fall into one of two types: static or dynamic . Most smaller, single site applications use static routers. A static router, or fixed configuration router, is initially configured by the user and then it stays that way until the user goes back and manually changes the configuration. Configuring a router is done using a command-line interface or a Web-based interface developed by the manufacturer. Most static routers today have a Web-based interface with very limited options so it will be easier for the end user to configure. Simplicity is good in a static router because most of those end users have little if any computer training. The good news is that once a static router is configured it will merrily chug away forever, which is great for single location with a stable network environment. The bad news is that every time the environment changes, somebody has to physically change the operating parameters of the router. The really bad news is that if the environment changes and the organization has multiple sites, somebody, hopefully not you, has to reconfigure each router individually. This reconfiguration can usually be done through a utility such as telnet, but in many cases requires a personal visit. So if you get into a situation which uses static routers in multiple locations, keep your bags packed and be prepared to make house calls. The limitations of static routers were a major problem for big decentralized companies with "big bucks" budgets , so it did not take long for a new type of router to arrive on the scene. A router that could automatically adjust to changes in the network environment, be configured and managed remotely, and provide even more filtering capability would be perfect, and that folks is exactly what a dynamic router or flexible configuration router does. A major hurtle to development of dynamic routers was finding a way to make the router aware of changes in the network and then provide it with a method for determining the best route to a given address. Therefore, it should not be surprising that the advent of dynamic routers coincided with advent of routing protocols . A routing protocol provides a way for routers to exchange information from their routing tables and then determine the best route to a network given that information. Each protocol handles this function slightly differently, and each has its own set of benefits and drawbacks. RIP (Routing Information Protocol) and IGRP (Interior Gateway Routing Protocol) are examples of protocols that use a distance vector algorithm for determining the best route. A distance vector routing protocol requires each router to exchange information with its direct neighbors. In this way, information travels from router by router throughout the network. Some refer to this approach as "routing by rumor." OSPF (Open Shortest Path First) and IS - IS (Intermediate System to Intermediate System) are examples of protocols that use link state routing. Link state routing requires each router to exchange information with every other router in the network. We will be going into each of these approaches in Chapter 7. However, for now it is enough to know that:
Configuring a static router or fixed configuration router can be intimidating, and they are designed for simplicity. Configuration of a dynamic router or flexible configuration router can be downright otherworldly. Initial configuration of a dynamic router is usually done through a command-line interface. However, instead of having a dozen or so parameters like a static router, a dynamic router can easily have thousands. The scary part is that not only do you have to find where a parameter is set in a complex command-line interface, but you also have to know the ramifications that setting will have on all of the other parameters that interact with it. We are not trying to scare you here (well maybe a little). The real thing we want to get across is that setting up large dynamic routers is not a task to be taken lightly. Becoming a Cisco Certified Network Associate (CCNA) is your first step to joining the elite few who can really handle these complex systems. We have arrived at a point where we have large bridged coaxial cable-based networks connected by dynamic routers that are talking to each other and keeping the whole system running like a top. In fact, the new coaxial cable standard called 10BASE-2 (see Figure 3.1) largely replaced the bulky 10BASE-5 systems. 10BASE-2 installations use a much thinner coaxial cable and replaced the dreaded vampire tap with a simple "T" connector (see Figure 3.5). So now everybody should be ecstatic, right? The problems of installation were greatly reduced, networks could be segmented with bridges to allow more users, and routers provided long distance connectivity. What more could possibly be needed? The answer is something other than coax. Figure 3.5. 10BASE-2 Networking. Figure 3.5 shows the "T" connector used to attach the bus to the station. The leg of the "T" ( facing forward) attaches to the interface card in the station, while the top of the "T" provides a straight through connection for the cable. |


EAN: N/A
Pages: 155