Section 10.4. Full Text Comparison
10.4. Full Text ComparisonAn alternative approach is to compare messages using their entire content, taking into account the insertion and deletion of words and changes in spelling and punctuation. This lets you use all the information content of the text, rather than a single word or phrase, and it allows you to avoid having to define a specific pattern that may not work as well as you had hoped. Text comparison in this general sense is not a simple problem. Simple tools such as grep or diff are not up to the task. Tools based on dynamic programming, which I discuss briefly in Chapter 8 in the context of uncovering plagiarism, are too computationally expensive to be used here. Fortunately, there are a variety of open source text search tools available that can be used. Most of these operate by indexing the significant words in each document and then efficiently comparing those indexes. This approach, in its basic form, treats each word separately, whereas a lot of information is contained in how words are arranged in sentences. In the case of email searches, this is not such an important factor. Some of the leading tools in this area include WebGlimpse (http://webglimpse.net/), Swish-e (http://swish-e.org/) and Lucene (http://lucene.apache.org/). Efficient text comparison is a major component of Internet search engines, and, not surprisingly, these open source tools tend to focus on that application. Rather than show how one of these tools can be adapted for email searching, I have chosen to include a custom Perl script that accomplishes the same basic task. I hope that you will be able to understand the operation of this fairly simple piece of code and then adapt it to your own applications. The script is called search_mailfile.pl and is shown in Example 10-2. Example 10-2. search_mailfile.pl #!/usr/bin/perl -w my $minLength = 5; if(@ARGV < 2 or @ARGV > 3) { die "Usage: $0 <message> <mail file> [<cutoff score>]\n"; } my $cutoff = -1; my $mode = 'score'; if(@ARGV == 3) { $cutoff = $ARGV[2]; $mode = 'select'; } my %msg0 = ( ); my %histogram = ( ); open INPUT, "< $ARGV[0]" or die "$0: Unable to open file $ARGV[0]\n"; while(<INPUT>) { my $block = loadBlock(\%msg0); } close INPUT; open INPUT, "< $ARGV[1]" or die "$0: Unable to open file $ARGV[1]\n"; while(<INPUT>) { my %msg1 = ( ); my $block = loadBlock(\%msg1); my $score = compareWordSets(\%msg0, \%msg1); if($mode eq 'score') { $histogram{$score}++; } else { if($score >= $cutoff) { print "# Score: $score\n"; print "$block\n"; } } } close INPUT; if($mode eq 'score') { foreach my $score (sort {$a <=> $b} keys %histogram) { printf "%-5d %d\n", $score, $histogram{$score}; } } sub loadBlock { my $words = shift; my $block = ''; my $body = 0; while(<INPUT>) { if($body == 0 and /^\s*$/) { $body = 1; } elsif($body == 1 and /^From\s/) { last; } elsif($body == 1) { my $line = lc $_; # fix any quoted-printable encoding $line =~ s/\=([0-7][0-9a-f])/chr hex $1/ge; # convert any punctuation to whitespace $line =~ s/[^a-zA-Z0-9]/ /g; foreach $word (split /\s+/, $line) { if(length $word >= $minLength) { $words->{$word}++; } } } $block .= $_; } $block; } sub compareWordSets { my $msg0 = shift; my $msg1 = shift; my $score = 0; foreach my $word (keys %$msg0) { if(exists $msg1->{$word}) { $score++; } } $score; } The approach it takes is intentionally very simple but works surprisingly well in practice. Each message contained within the mail file is loaded in turn and compared to the single query message. The code skips over the headers in a message, as these are almost guaranteed to vary between examples. Any text in the body of a message that is encoded as quoted-printable is converted to ASCII, as far as is possible. The text is converted to lowercase, and all punctuation is converted to whitespace. All remaining words that are at least five characters in length are then added to a hash for that message. The comparison between two messages is made by counting the number of words that are present in their respective hashes. That number is the similarity score for that comparison. A simple extension of the code would be to take into account the relative frequencies with which each word occurs. You might also exclude words that are found in almost all email messages and that effectively add background noise to the comparison. The script is used in two modes. The first calculates the score for each comparison between the query message and those in the mail file. The expectation is that most messages will not be a good match and so will produce a low score. The few that are very similar will produce a high score and you can use that difference to select the best matches. But without a first pass, it is very difficult to determine what cutoff score should be used. So the first pass outputs a histogram of the number of times that each score is encountered. You can then look at those values and choose a suitable cutoff. In some cases, no significant matches will be found, so no high score outliers will be observed. As an example, I compared a single email message, which was part of a phishing attempt on eBay users, against my Junk mail folder that has about 30,000 messages in it. The command is invoked as follows: % search_mailfile.pl ebay.msg Junk > ebay_scores.dat Figure 10-1 shows the histogram of scores that I plotted from the output of the script. Note that the Y-axis scale is logarithmic. You can see that the vast majority of messages produced scores of 60 or less, but a few of them scored more than 100. These outliers are likely to be very close matches to the query message. A cutoff score of 100 seemed like a good choice with which to separate the two groups of messages. Figure 10-1. Histogram of observed scores for an example text comparison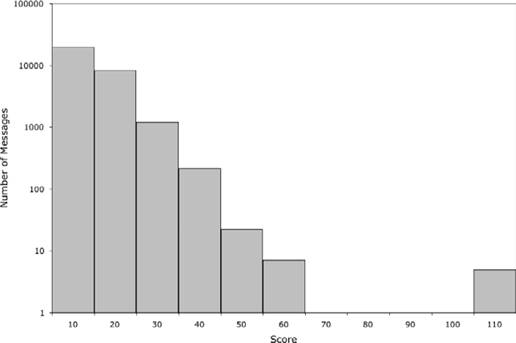 Having made that assessment, I repeated the comparison, including the cutoff score on the command line: % search_mailfile.pl ebay.msg Junk 100 > ebay_matches.msg In this mode, the script outputs each message that scores above that threshold. Having to repeat the search is not particularly efficient, but it avoids having to make the script too complicated. The output from this example search consisted of five messages. Looking at those individually shows them all to be other instances of the original phishing attempt that were sent over period of around 10 months. All five had a similar appearance when viewed in a mail client, but with minor differences that presumably were intended to avoid detection by spam filters. The From and Subject lines of the messages show both similarities and differences within the group:
As you would expect, the fake eBay web site that each message directed users to was different in each example:
The first three are identical in form, suggesting that they have the same origin. The last two may signify that the person or group responsible for the scam has changed their tactics slightly. Alternatively, a second scammer may have copied the email message from the first and used it for a completely separate operation. This possibility has to be kept in mind as you study scams that appear to be linked. If the email messages are very similar but the web pages they point to are quite distinct, then you need to question how closely the two examples are related. Interestingly, in this example, the label for each of these URLs (the string that is visible in the email message) is the same in each message:
With hindsight, the number 00937614 might serve as an excellent signature pattern and might pick up further examples. But I would not have derived this signature without using the full text comparison approach. Searching with signature patterns is efficient, and, if the pattern is truly specific, it can uncover messages that are linked but that contain very different text. Full text comparison makes no prior assumptions about signatures and can find similar messages based on the overall content of a query example. Both approaches have an important role to play and switching between the two in the course of a study can be an effective way to uncover links between different operations. |