Boundary Value Analysis
|
|
Years ago I read a headline somewhere that said something to the effect that "boundary value analysis is the most important test technique there is." My reaction was, "Of course it is; every animal on my farm can tell you that." Boundary value analysis (BVA) is one of the most fundamental survival techniques there is. The trick is recognizing the boundaries as boundaries and then cataloging their properties correctly.
Boundary value analysis is a test data selection technique in which values are chosen to lie along data extremes. Boundary values include maximum, minimum, just inside and outside boundaries, typical values, and error values. The hope is that if a system works correctly for these special values, then it will work correctly for all values in between. These values are the most important test cases.
Boundary Value Analysis Example
I will continue to use the method of payment test items from Chapter 12. Figure 13.1 shows the payment details page from the Tester's Paradise Web application. Let's consider the matter of credit card authentication.
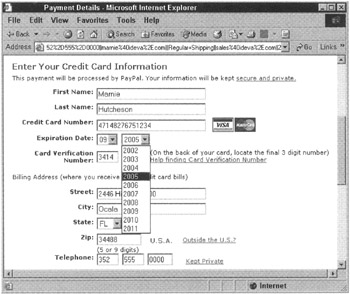
Figure 13.1: The Payment Details page.
There are two types of tests that need to be conducted on this page. First, we need to verify that the individual data fields are being validated correctly, and second, we need to verify that the data set produced by validated field values from this page is being validated correctly.
There is a path on my farm that leads from the barnyard down to the pond and then around the pond to the pasture. My ducks follow this each day as they make their way from breakfast in the barnyard to the water for their day's activities and then back again in the evening for dinner and sleep. One morning there was a branch from an old oak tree about 18 inches in diameter lying across the path. It had fallen during the night.
The ducks approached it cautiously. Each duck inspected the log carefully from the barnyard side, paying special attention to the area where the log met the path. There were gaps between the log and the path, but none big enough for a duck to squeeze through. Once the ducks were satisfied of this, they began to inspect the top of the log, and stretching as far as their necks could reach on tip toe, they examined the other side.
The log was just big enough that they couldn't quite see the ground on the other side, so they would not risk leaping over onto uncertain ground. A couple of the ducks returned to the barnyard. A couple of the ducks decided to explore to the ends of the branch to see if they could find a way around it. And the largest and bravest duck found a way to climb up to the top of the log, and she continued her inspection of the far side from there. Eventually, she found a gentle, branching way to get down to the path on the pond side.
One of the ducks who tried to go around the log through the brush succeeded in getting through and also made it to the pond. The last duck met a big black snake in the brush and would have probably been bitten except for the intervention of the dog.
A few minutes later, I came to the log while walking my horse out to the pasture. He stopped and gave it a similar inspection. First checking, by eye and by smell, the side closest to him, then the log itself, and finally using his height, he thoroughly inspected the far side. He was not interested in stepping over the log until he was quite satisfied with the ground on both sides and the log itself. After the duck's adventure with the snake, I was not inclined to rush him. The interesting thing was that coming back that evening, he again refused to step over the log until he had completed the same inspection from the pond side.
Horses are prey animals, and consequently they do not rationalize obstacles. That means that just because it was safe to go across the log in one direction didn't mean it was safe to go across in the other direction. They treat every side of a boundary as a unique challenge and potential threat. This is a fundamental survival instinct.
I first told this story to a group of testers in a corporation that manufactures huge boom-ables. The consensus was that the ducks were very good testers. But the horse must have been a tester in a safety-critical industry in some past life.
Field validation can happen in the browser or on the server. It is normal to try and do simple field validation in the browser, because it saves the round trip to the server and offloads this minor processing to the client, freeing the server's resources for more important tasks.
A credit authorization requires a valid credit card number of the type of credit card selected-Visa or MasterCard in this case-and a valid expiration date. The expiration date must have a valid month and a valid year and must be the correct expiration date for that particular card number. Further, the user must also provide the correct four-digit security code, called a card verification number, found on the back of the card.
If you are looking at the drop-down selection box in Figure 13.1 and thinking, What is she talking about? You can't test a"-1"or a "13" in the month field since it's a drop-down, then you should think again. Drop down boxes like this one have done a lot to help keep incorrectly typed data from getting to our applications, but they are not a panacea.
Recently, a Web store owner I know called to ask f I could help figure out what was going wrong in his electronic store. It seemed that something locked it up on a regular basis, but the server logs showed nothing. The Visual Basic (.asp)-scripted store would simply stop creating pages about every three days. It required a full server restart to get the store functioning again. The hosting company was not happy to interrupt service on all the Web sites in the server every three days so the store could go on.
I agreed to take a look. Sure enough, I managed to dig up an obscure application log that seemed to have lots of funky-looking command strings in it. After a bit of thinking, I realized I was looking at a series of artificially generated bogus command strings. The store had logged them because it had not been able to process them.
It turns out that it was an easy matter to send edited command strings to the store and lock it up. So, some hacker was creating these command strings in a text editor and sending them to the store. The store's response to these bad command strings was to lock up. Locking up was the only exception processing in the software; there seemed to be no data validation taking place in the application logic. The store's ASP developers were depending entirely on the HTML/ASP user interface to validate the user input.
Hackers have a field day with such weak applications, and someone obviously was onto this one.
Field Validation Tests
As the first example, I will use BVA and a data-reducing assumption to determine the minimum number of tests I have to run to make sure that the application is only accepting valid month and year data from the form.
Translating the acceptable values for boundary value analysis, the expiration month data set becomes:
1 ≤ month ≤ 12
BVA-based data set = {0,1,2,11,12,13} (6 data points)
The values that would normally be selected for BVA are 0, 1, 2, and 11, 12, 13.
Using simple data reduction techniques, we will further reduce this number of data points by the following assumptions.
| Assumption 1. | One of the values, 2 or 11, is probably redundant; therefore, only one midpoint, 6, will be tested. |
Month data set = {0,1,6,12,13} (5 data points)
This next assumption may be arbitrary, especially in the face of the hacker story that I just related, but it is a typical assumption.
| Assumption 2. | Negative values will not be a consideration. |
Figure 13.2 shows how I like to visualize the boundaries for this range. Every value that falls within the hatched area, including my test data, 1, 6, and 12, is valid, and all values outside these areas, for example, 0 and 13, should fail.
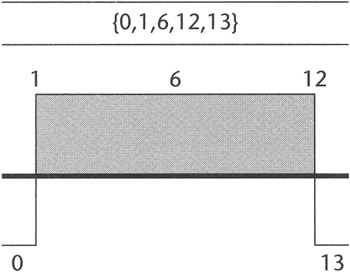
Figure 13.2: The boundary value range for a valid month.
Likewise, the valid field data set for the expiration year becomes
2002 ≤ year ≤ 2011
BVA year data set = {2001,2002,2003,2010,2011,2012}
Again, I will apply a simplifying assumption.
| Assumption 3. | One of the values, 2003 or 2010, is probably redundant; therefore, only the midpoint, 2006, will be tested. |
BVA year data set = {2001,2002,2006,2011,2012}
These two fields, a valid month and a valid year, are combined to become a data set in the credit authorization process. These are the data values that will be used to build that test set. But before I continue with this example, I need to mention one more data reduction technique that is very commonly used but not often formalized.
Matrix Data Reduction Techniques
We all use data reduction techniques whether we realize it or not. The technique used here simply removes redundant data, or data that is likely to be redundant, from the test data sets. It is important to document data reductions so that others can understand the basis of the reduction. When data is eliminated arbitrarily, the result is usually large holes in the test coverage. Because data reduction techniques are routinely applied to data before test design starts, reducing the number of test data sets by ranking them as we did with the paths may not be necessary.
| Note | Generally use matrix data reductions rather than data ranking. |
The following section illustrates some good defensible data reduction techniques. But there are a couple of rules:
-
Do not apply this data reduction technique to individual data items-only to data sets.
-
Use your assumptions and the test inventory to document your data reductions.
The matrix data reduction is accomplished by building the matrix of possible combinations of the individual data and removing redundant sets. Again, be sure to write down the assumptions you use to remove data sets from your test set. In the previous section, I made the assumption that any point between the two boundaries would be OK as a test point-that I didn't need to test a number immediately adjacent to the boundary. In this case, I will be making a similar type of assumption, but the results can have a profound impact on the total number of tests that are left after reduction.
This is a very typical assumption that testers make all the time, but they rarely write it down. Typically, we make a guess about boundaries. In my testing over the last year, I have found that the single biggest source of error is in boundaries in the data entry field.
For the data reduction matrix, I will combine the two individual data sets that were just created in order to make a set of month, year combinations. Once I have done this, I will have to test to validate the month and year. If I have a good month but a bad year, the test is going to fail, or vice versa. Now I will show you how to build a data set matrix that allows you to consider further data reduction of your test sets.
Data Set Tests
A valid expiration date field must have both a valid month and a valid year using the two data sets selected previously:
{0,1,6,12,13} and {2001,2002,2006,2011,2012}
This gives us, {month, year} → 5 × 5 data combinations = 25 possible combinations. Figure 13.3 shows the possible combinations of these data and their truth table outcome.
| 0,2001 FF | 1,2001 TF | 6,2001 TF | 12,2001 TF | 13,2001 FF |
| 0,2002 FT | 1,2002 TT | 6,2002 TT | 12,2002 TT | 13,2002 FT |
| 0,2006 FT | 1,2006 TT | 6,2006 TT | 12,2006 TT | 13,2006 FT |
| 0,2011 FT | 1,2011 TT | 6,2011 TT | 12,2011 TT | 13,2011 FT |
| 0,2012 FF | 1,2012 TF | 6,2012 TF | 12,2012 TF | 13,2012 FF |
Figure 13.3: The data set for a valid date field expanded.
| Note | If I had used all 6 BVA data items, there would be 6 × 6 = 36 data sets to test. So the data reduction assumption saved 11 data set tests. Looking at it another way, applying this data reduction technique reduced the BVA tests by 31 percent. |
Notice the True (T) and False (F) value notation. The shaded areas in the matrix, all the values around the edges, should fail because they contain at least one false value, so the month, year set should fail. There are 16 data sets that should fail. The nine data sets in the middle of the matrix are all true, so they should pass. Notice that there are almost twice as many exceptions as there are passing sets.
This matrix provides a systematic way of visualizing how the data sets behave. I can use this pattern to my advantage if I need to reduce the number of data tests. If I select sets from this matrix, I can make sure I get a representative set, because I can see the pattern, rather than some ad hoc random sampling. I can test the extremes, the mixed sets, and the all-true sets-without testing every single value.
I can make a good guess at the proportions of TT, TF, FT, and FF sets I need to test because I can see how many of each there are. I also know that I have almost twice as many sets that should fail as sets that should pass. Let's say that I want to cut the number of tests in half. I can probably pick a representative test set by choosing
16/2 = 8 failing sets
I would select all four FF sets, 2 TF sets, and 2 FT sets.
And for
9/2 = 4.5 (round up to 5) passing sets
I would select each of the corner TT sets, {1,2002}, {12,2002}, {1,2011}, {12,2002}, and the one in the center of the matrix, {6,2006}.
| Note | This would reduce the number of test sets I plan to test down to 13, or 36 percent test coverage of the original BVA estimate of 36 test sets. |
This is a small and simple example, but it clearly demonstrates the principle of using the matrix data reduction technique. This method is systematic and reproducible-as long as you document your assumptions. In a completely new environment where no components are trustworthy, it would be far better to test all the data sets, but I don't usually have time.
Building the data sets this way is a bottom-up process. I may test from top down, but I build my data sets from the bottom up whenever I can. With that in mind, let's go on to look at another technique for building test data set requirements from the bottom up as we go on to the next step, determining the data sets required to test credit authorization.
Data Set Truth Table
At first glance, Table 13.1 might seem trivial. Obviously, all these values need to be valid or we will never get a credit card authorization to pass. But consider it a different way. Let's say we put in a valid date and a valid credit card number, but we pick the wrong type of credit card. All the field values are valid, but the data set should fail. To build the data sets that I need, I must first understand the rules. This table tells me how many true data values I need for each one card to get a credit authorization.
| Data Set 1-The set of all Valid Data, all in the data set | Is a valid value for the field | Is a valid member of this Data Set | Minimum Number of Data to test | Minimum Number of Data Sets to test |
|---|---|---|---|---|
| Cardholder Name | ||||
| True | True | 1 | |
| True | True | 1 | |
| Billing Address | ||||
| True | True | 1 | |
| True | True | 1 | |
| True | True | 1 | |
| True | True | 1 | |
| Credit Card Information | ||||
| True | True | 1 | |
| True | True | 1 | |
| True | True | 1 | |
| True | True | 1 | |
| True | True | 1 | |
| OUTCOME: | True | True | 10 | 1 |
| Note | My goal is to build the fewest number of test sets possible. If I can, I will build the data sets to verify credit authorization using data that will verify the field processors at the same time. So, I can run one test series and verify both the fields and the function. |
Published Assumptions
| Assumption: | Once the field processors have been verified for one credit card, they will be assumed to be stable for all credit cards. |
We're going to assume once the field processors have been verified for one card, they are going to work for both credit cards. In one test effort our team did assume this initially, and it was a bad assumption, but happily it didn't bite us because we published it in the test plan.
One of the programmers came forward and told us that the field processor for the credit card number in the client was checking to make sure that only numeric data was placed in the field; however, there was another process to validate that it was a valid credit card of the type selected, for example, Visa or MasterCard. This second validation took place after the information was submitted to the online application. The application was using a specific algorithm for each type of card selected by the user.
This is a common problem when testers can't know for sure "where" validation is occurring. We would only have been testing one of the algorithms; we wouldn't have validated both of them. Because we stated this assumption in the test plan, the developers picked up on it and let us know.
The card verification number is another field that might be processed by a different logic routine depending on the type of card. This is another example of one of those hidden boundaries that testers don't know about. If I only define tests to test what I know about, I will probably just run two tests for each card, one valid and one invalid. That's four data set tests in all:
10 valid data + 10 invalid data = 20 field tests for each card
These two test sets should yield two test sets for one card; one will pass authentication and one will fail. This will test each of the field validation processors once.
We have to perform all these tests for both credit cards:
20 x 2 = 40 field tests for 2 credit cards
But as I have just explained, this is too small a test set to detect any hidden boundaries, unless I get very lucky. So, I will want to add some data values to help me probe the code just a bit. Before I add any tests, there is another assumption that I want to consider.
| Assumption: | Whether field data will pass or fail is independent of validity of the data set. |
The field tests don't verify any data sets; they just verify that field tells us that data. Mixing valid data from different sets will cause the data set to be invalid, even though all the field processors have been satisfied. Could be a good credit card number and a good date, but they may not work together. So the field test set is only going to tell us about the field problems. This assumption also addresses the logic flow of the field data validation processing. Whether field data pass or fail is independent of the data combination. I am assuming that once the field processor tells us whether or not it's good data, it will always be able to tell us if it's good data, regardless of whether or not some other field is valid.
So when we count up the minimum number of field tests on the data in all those fields, at minimum there are 10 valid data to make one set, and 10 invalid data. One good case and one bad case. At the very minimum, we have to come up with 20 field data items for one card. Then we have a total for two credit cards, so we multiply by 2 for a total of 40 field tests.
As I said, I don't think that this is enough coverage to provide an adequate test effort. If you are wondering if extra coverage is necessary, see the discussion on Web services in the Caveats section coming up. I don't want to just beat on the application in a random fashion. I would like to identify potential hidden boundaries and test them. I need a tool to help me decompose this large data set into its components so that I can visualize where such hidden boundaries might be found. Table 13.2 shows one approach to accomplish this.
| Data Set Credit Card #1 | Field Test Outcome | Data ∈ Set | Data Set Test Outcome |
|---|---|---|---|
| Valid | Valid | Valid |
| Invalid | Invalid | Invalid |
| Valid | Invalid | Invalid |
| Valid | Invalid | Invalid |
| Valid | Invalid | Invalid |
| Invalid | Invalid | Invalid |
∈ means "is a member of"
∉ means "is NOT a member of"
Each of the six items in Table 13.2 has two distinct possible outcomes for the field and data set validations. Each of these six items is a data set. According to this table, I need six data sets to test the card validation process. This gives me the opportunity to try multiple values for each data item. I will use this number of tests in my actual test count.
The Process for Building Sufficient Data Sets from the Bottom Up
The following is the process I recommend for building sufficient data sets from the bottom up-and which I use for all my work:
-
I start with two good sets of data, one for each card. This will ensure that I have tested the most important all-true paths.
-
Next, I prepare a list of all the invalid data values that I want to test to verify the field validation routines. For example, if I need to check for negative numbers, or nonnumeric characters in numeric fields and so on, then I will quickly build up several tests for the numeric fields-and that means more than two complete test sets. If this happens, I will create more data sets to accommodate these field tests.
-
Most important, I will try to get a look at the logic paths that do the credit authorization. I want to know how the application is verifying the data set for the credit authorization. If I can identify any data boundaries in the application validation logic, I will add test data to create test sets to test those boundaries.
Stated as it is here, this may seem like a trivial example, but it is no accident that most credit card authorization is handled by specialized companies as secured Web services. Anytime there is an opportunity to commit fraud, there are hackers ready to try.
In all, I will prepare at least five sets of invalid data for each credit card. This gives me the opportunity to test at least five exceptions for each data field.
(1 valid set of data + 5 invalid sets) x 2 credit cards = 12 data sets
The next example on the test inventory is the new Purchase Option: Not available in some states (data). This is an adjunct process that must consider each product and compare the buyer's state rules against the rules of the selling state. This is actually an international issue rather than a U.S. interstate issue. Some products can't be sold in some countries. The processing that verifies and says yes or no to a particular sale is quite complex and beyond this discussion.
I have approximated it here by stating that each state will require a test, so the number of tests is 50.
Finally, Minimum Order must be $30.00 (data). I assumed a simple BVA for this test, for example, $29.99, $30.00, and $31.00. Interestingly enough, I recently broke an application trying to make a purchase that was for too large an amount. Having completed this much data analysis, Table 13.3 shows the most recent version of our sample test inventory. The total data set tests, 77, will be carried to the MITs Totals page in the spreadsheet. I will show you the results of the analysis we conduct in Chapters 12 and 13 in the next chapter, "What Our Analysis Tells Us and What's in Store in the Near Future."
| Tester's Paradise (Release 2.0) | Data Sets | Existing Data Tests | System Data Tests |
|---|---|---|---|
| Project Information: | |||
| Fix For Error #123 | 0 | 7 | 0 |
| Fix for Error #124 | 0 | 4 | 0 |
| Tester's Paradise Main Menu | |||
| Our Best System Simulator | |||
| Message Data Flow Checker | |||
| Screen Comparison - Pixel Viewer | |||
| Portable System Monitor (New Function) | |||
| Specifics and Options | |||
| Add-on Platform Adapters | |||
| View Portable System Monitor | |||
| Display Portable System Monitor | |||
| Order Form | |||
| Arrange Payment | |||
| Method of Payment (Path) | |||
| Method of Payment limited to 2 credit cards (Data Sets) | 12 | ||
| Purchase Option: Not Available in some states (data) | 50 | ||
| Minimum Order must be $30.00 (data) | 3 | ||
| Order Confirmation | |||
| Support Packages | |||
| Return to Main Menu | |||
| Cancel | |||
| Installation is automatic at logon | 1 | ||
| Totals | 65 | 11 | 1 |
| Total Data Tests | 77 | ||
|
|
EAN: 2147483647
Pages: 132