8.1 Decomposition and Encapsulation of the Work
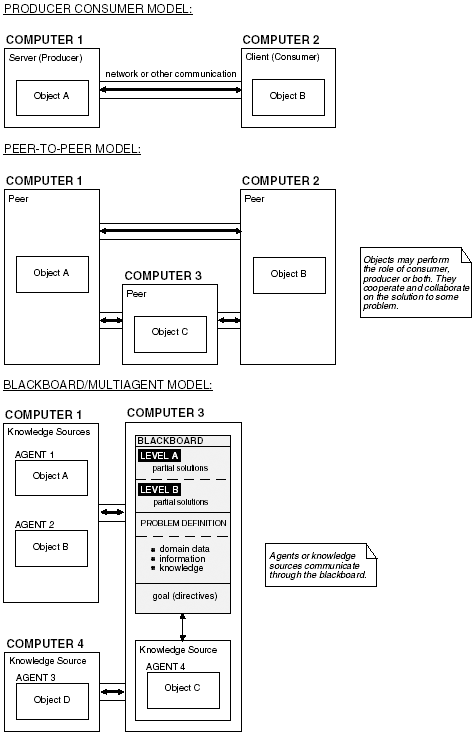
| Object-oriented software design is the process of translating the software requirements into a blueprint where objects model each aspect of the system to be developed and work to be done. The blueprint is centered around the structure and hierarchy of collections of objects and their relationships and interactions. The C++ class keyword is used to support the notion of a software model. There are two basic types of models. The first type of model is a scaled representation of some process, concept, or idea. This type of model is used for the sake of analysis or experimentation. For example, a class can be used to develop a molecular model. The hypothesis and structure of some chemical process within molecules can be modeled using C++'s class concept. A molecule 's behavior when new groups of atoms are introduced can then be studied in software. The second type of software model is a reproduction in software of some real-world task, process, or idea. The purpose of this model is to function as its real-world counterpart as a part of some system or application. The software takes the place of some component in a manual system, or some physical thing. For example, we may use the class concept to model an adding machine. Once we have correctly modeled all of the characteristics and behavior of the adding machine, then an object can be instantiated from that class and used in place of a real adding machine. The software adding machine takes the place of the real-world adding machine. The modeled class serves as a virtual stand-in for some real-world person, place, thing, or idea. The software model captures the essence of the real thing. For our purposes, decomposition is the process of dividing a problem and its solution into units of work, collections of objects, and the relationships between those objects. Likewise, encapsulation is the capturing or modeling of the characteristics, attributes, and behavior of some person, place, thing, or idea using the C++ class construct. This modeling (encapsulation) and decomposition is part of the object-oriented software design phase. Object-oriented applications that contain distributed objects add an additional layer to the design considerations. In one view of the design, the locations of objects within an application should not affect the design of the attributes and characteristics of those objects. The class is a model and unless location is part of that model, the ultimate location of the objects that will instantiate that class should not matter. On the other hand, objects don't exist in a vacuum . They interact and communicate with other objects. If some of the objects that communicate are located on different computers, possibly different networks, then this consideration has to be part of the original software design process. Although there is a lot of disagreement as to where in the design process distribution needs to be considered, it must be considered . The error handling and exception handling between objects located in different processes or computers are different from the error handling and exception handling between objects that are part of the same process. Also, the communication and interaction between objects located within the same process is performed differently if those objects are located in different processes where the processes may be on different computers. This must be taken into account during the design phase. In a distributed object-oriented application, the work that must be done is divided between the objects in the application and is implemented as member functions of the various objects. The objects will be logically divided into some WBM (Work Breakdown Model). They may be divided into a client-server, producer “consumer, peer-to-peer, blackboard, or multiagent model. Figure 8-1 shows the logical structure of each of these models and how the objects are distributed in each model. Figure 8-1. The logical structure and distribution of objects in the producer “consumer, peer-to-peer, blackboard, and multiagent models. In each model shown in Figure 8-1, the objects involved may or may not be on the same computer. However, they will be in different processes. The fact that they are in different processes is what makes them distributed. [1] Each model represents a different approach to the division of work between the objects.
8.1.1 Communication between Distributed ObjectsIf the objects are located within the same process, then parameter passing, regular method invocation, and global variables can be used as a means of communication. If the objects are located in different processes on the same computer, then files, pipes, fifos, shared memory, clipboards, or environment variables are needed to facilitate communication between the objects. If the objects are located on different computers, then sockets, remote procedure calls, and other types of network programming will be required to facilitate communication. Not only must we be concerned with how the objects in a distributed application communicate, we must also be concerned with what they communicate. Object-oriented applications can include anything from simple to complex user -defined classes. These classes are often communicated between objects. So not only do distributed objects need to communicate simple built-in data types such as ints , floats , and doubles , they also need to communicate any type of user-defined class that might be necessary to allow some object to complete its work. Also, one object needs a way to be able to invoke methods of another object located in another address space. To complicate matters, there needs to be some way for one object to know the methods of a remote object. While C++ does support pure object-oriented programming, it does not have distributed communication facilities built in. It does not have built-in methods for locating and querying remote objects. There are several important protocols for distributed object communication. Two of the most important protocols are IIOP (Internet Inter-ORB Protocol; pronounced "eye-op"), and the RMI (Remote Method Invocation). Using these protocols, objects located virtually anywhere on any network can communicate. In this chapter, we will discuss techniques for implementing distributed object-oriented programs using these protocols and the CORBA (Common Object Request Broker Architecture) specification. The CORBA specification is the industry standard for specifying the relationships, the interaction, and the communication between distributed objects. IIOP and GIOP are the two primary protocols that the CORBA specification works with. These protocols operate well with TCP/IP. CORBA is the easiest and most flexible way to add distributed programming to the C++ environment. The facilities provided by a CORBA implementation support the two major models of object-oriented parallelism that we use in this book: blackboards and multiagent systems. Because the CORBA specification reflects object-oriented programming, applications ranging from the small to the very large can be reasonably implemented. In this book we use MICO [2] which is an open -source implementation of the CORBA specification. The MICO implementation supports the major CORBA components and services. C++ interacts with MICO through a collection of classes and class libraries. CORBA supports distributed object-oriented modeling at every level.
8.1.2 Synchronization of the Interaction between the Local and the Remote ObjectsMutexes and semaphores can be used to help synchronize data and resource access between two or more objects located in different processes but on the same computer. This is because each process, although segregated, still has access to the computer's system memory. This system memory acts as a kind of shared memory between processes. However, multiple computers don't have any memory in common and therefore synchronization schemes must be implemented differently when the processes are distributed across different computers. Synchronizing access depending on the WBM used can require considerable communication between the distributed objects. For synchronization we will enhance the traditional methods of synchronization with CORBA's communication abilities . 8.1.3 Error and Exception Handling in the Distributed EnvironmentPerhaps one of the most challenging areas of exception or error handling in a distributed environment is the area of partial failure. In a distributed system, one or more components may fail while the other components operate under the assumption that everything is fine. In a local application where all of the components are within the same process, if one function or routine fails, it is not difficult for the entire application to know about it. This is not so for distributed applications. A network card might fail on one computer and the other objects executing on other computers will have no knowledge that a failure has happened . What happens if one of the objects needs to communicate or interact with an object whose network communications have been mysteriously interrupted ? In a peer-to-peer model of problem solving where we have groups of objects working on various facets of some problem and one of the groups fails, how will the other groups know? Furthermore, what do we do about it? Should a single component's failure lead to system failure? If one client fails, should we shut the server down? If the server fails, should we shut the client down? What if the server or the clients only partially fail? So, in addition to data race and deadlock, we must also find ways to cope with partial failure of a distributed system where one or more of the components in the system have totally or partially failed. Again, what is necessary is a distributed approach to C++'s exception handling mechanism. The CORBA facilities provide a sufficient start. |
EAN: 2147483647
Pages: 133
- Step 2.1 Use the OpenSSH Tool Suite to Replace Clear-Text Programs
- Step 3.1 Use PuTTY as a Graphical Replacement for telnet and rlogin
- Step 3.2 Use PuTTY / plink as a Command Line Replacement for telnet / rlogin
- Step 4.7 Using Public Key Authentication for Automated File Transfers
- Step 5.1 General Troubleshooting