7.4 Recognizing Where to Handle Defects versus Where to Handle Exceptions
7.4 Recognizing Where to Handle Defects versus Where to Handle ExceptionsIn general, software defects (which are the result of programmer error) should be detected and corrected during the testing phases defined in Table 7-1. Table 7-1. Types of Testing Used During the Software Development Process
Through the process of testing and debugging, defects should be identified and removed. On the other hand, exceptions are handled during execution of the program at runtime. We also distinguish between exceptional conditions and unwanted conditions. For instance, if we have designed a program that will add a list of numbers typed in by the user and the user types in some numbers and some characters that are not numbers , then this is an unwanted condition, not an exceptional condition. We should design programs to be robust through input validation so that the user is forced to enter the data that our program requires for proper execution. If part of a program that we design saves information to external storage and the program encounters an out-of-space condition, then the out-of-space condition is an unwanted situation, not an exceptional or extraordinary condition. We reserve exception handling for the unusual, not the unwanted. We reserve exception handling techniques for the unanticipated . Situations that are unwanted but have a reasonable probability should be handled by ordinary program logic such as the following: If Input data not acceptable then request input data again else perform required operation end if Checking conditions in this way is part of the fundamental art of programming. This kind of programming prevents problems from happening. It certainly doesn't rise to the definition of exception. There is a difference between defects and exceptions and between exceptions and unwanted conditions. Defects are dealt with using testing and debugging. Unwanted conditions are handled within the confines of the regular program logic and exceptions are handled using exception handling programming techniques. Table 7-2 contrasts the difference between the characteristics of error handling, exception handling, and the handling of unwanted conditions. Table 7-2. Differences between the Characteristics of Error and Exception Handling and the Handling of Unwanted Conditions
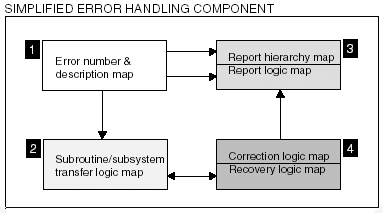
The goal is to build error handling and exception handling components that can then be integrated with the other components that make up our parallel or distributed programs. The error handling and exception handling components must have the capability of identifying and reporting what the problem is as well as recovering from or correcting the problem. The recovery and correction can involve everything from prompting the user to reenter the data to restarting a subsystem within the software. Recovery and correction efforts can involve extensive file processing, database backouts, network rerouting, processor masking, device reinitialization, and for some systems, even hardware part replacements . Error and exception handling components can take on a range of forms, from simple assertion statements to smart agents whose sole purpose it is to anticipate failures and prevent them before they happen. A significant portion of any serious piece of software will be devoted to the error and exception handling components. Figure 7-3 shows the architecture for a simple error handling component. Figure 7-3. Architecture of a simplified error handling component. Component 1 in Figure 7-3 is a simple map component that contains a list of error numbers and their descriptions. Component 2 contains a map object that maps the error numbers to jump locations, functions, or subsystems. Depending on what the error number is, component 2 is used to determine where to transfer. Component 3 is a map that maps the error numbers to the report hierarchy and report logic. The report hierarchy contains who or what should be notified of the error. The report logic determines what the notification should be. Component 4 contains two map objects. The first object maps the error numbers to objects whose purpose it is to correct some failure condition. The second object maps error numbers to objects who will return the system to a stable or at least a partially stable state. The simple error handling component in Figure 7-3 can be applied to software of all sizes and shapes . How the error handling and exception handling components are used will be determined by the amount of software reliability desired. |
EAN: 2147483647
Pages: 133