12.3 Basic Agent Components
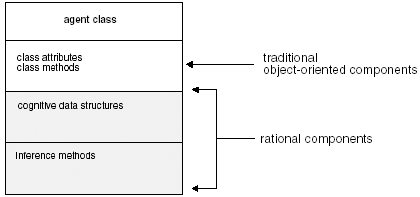
12.3 Basic Agent ComponentsAn agent is declared using the class keyword. The components of an agent will consist of C++ data members and member functions. Figure 12-1 shows the logical layout of an agent class. Figure 12-1. Logical layout of an agent class. The class attributes and methods in Figure 12-1 refer to the typical initialization, read, and write methods that any object would have. The attributes would include state variables that define the object. The methods would include constructors, destructors, assignment operators, exception handlers, and so on. If we stopped with these attributes and methods we would have only a traditional object. The cognitive data structures and the inference methods make up the rational component. It is the rational component that transforms an object into an agent. 12.3.1 Cognitive Data StructuresA data structure is a set of rules for logically organizing data and the rules for accessing that logical organization. It is a method of organization that specifies both how the data should be conceptually structured and how access operations are allowed to be applied to that structure. Whereas datatypes and ADTs (abstract datatypes) focus on what, data structures focus on how. For example, the integer datatype specifies an entity that has a data component and a number of arithmetic operations (i.e., addition, subtraction, multiplication, division, modulo, etc.). That data component does not have a fractional part. The data component consists of negative and positive numbers , and so on. The datatype specification does not mention how the integers should be used or accessed. On the other hand, a data structure specification such as a stack specifies a list of elements stored in a LIFO (last-in-first-out) order. The stack data structure also specifies that elements may only be taken out one at a time from the top of the stack, that is, the last element inserted must be removed before any other elements can be accessed. So not only does the stack data structure specify how the elements are organized, it also specifies how the elements are accessed (i.e., visited, read, changed, deleted, etc.). Cognitive data structures restrict the rules for organizing and accessing data to those found in the fields of logic and epistemology. The rules of inference, the methods of inference (i.e., deduction , induction, and abduction), the notions of epistemic data, knowledge, justification, belief, premises, propositions , fallacies, and conclusions are the defining features of cognitive data structures. [3] Whereas algorithms for sorting, searching, and iterating are commonplace for traditional data structures, inference methods are more commonplace for cognitive data structures. The ADTs used with cognitive data structures often include:
Of course, other datatypes can be used with a cognitive data structure but these are characteristic of programs that use rational software components such as agents . These ADTs are normally implemented as datatypes using the struct or class keywords. For instance: struct question{ //... string RequiredInformation; target_object QuestionDomain; string Tense; string Mood; //... }; class justification{ //... time EventTime; bool Observed; bool Present; //... }; The C++ template and container classes can be used to organize cognitive data structures such as knowledge. For instance: class preliminary_knowledge{ //... map<question,belief> Opinion; map<conclusion,justification> SimpleKnowledge; set<propositions> Argument; //... }; 12.3.1.2 Inference MethodsThe inference methods in Figure 12-1 refer to deduction, induction, and abduction. (See Sidebar 12.1 for an explanation of these methods.) While inference methods are called for in an agent architecture, there is no specific mention on how the inference methods are implmented. Deduction, induction, and abduction are high-level processes. The details of how to implement these processes are up to the software developer. Inference is the process of deriving logical conclusions from premises known or assumed to be true. There is no one right way to implement an inferencing process, sometimes called an inference engine. However, there are several commonly used methods for implementing inference. Forward-chaining or backward-chaining techniques can be used. Means “end analysis techniques can be used. Graph traversal algorithms such as DFS (Depth First Search) and BFS (Breadth First Search) can also be used. There is a host of theorem-proving techniques that can be used to implement inference methods and inference engines. The important point to note here is that an agent class will have one or more inference methods. Table 12-3 contains descriptions for the most basic techniques used to implement the inference methods. Table 12-3. Tables for Descriptions of the Most Basic Inference Implementation Techniques
These techniques are well understood and widely available in many libraries, frameworks, and some programming languages. These techniques are the building blocks for the basic inference methods. To see how this inferencing works lets use one of the rules of inference Modus Ponens and build a simple inference method to support it. Take the following statement: If there is a bus trip from Detroit to New York then John will go on vacation. If we establish that there is a bus trip from Detroit to New York, then we know that John will go on vacation. The Modus Ponens form of this is:
We could design a simple decision support agent to tell us whether John will go on vacation or not. That agent would need to know something about possible bus trips. Let's say we have a list of bus trips:
Each of these trips represents commitments by the ABC Bus Company. If our agent has access to the ABC Bus Company's schedule, then this list of trips can be used to represent part of our agent's beliefs. The question is, how do we get from a list of trips to beliefs? First, lets design a simple statement structure. struct existing_trip{ //... string From; time Departure; string To; time Arrival; //... }; Next let's use a container class that will represent our agent's beliefs about bus trips. set<existing_trips> BusTripKnowledge; If the bus trip is contained in the set BusTripKnowledge , then our agent believes that the bus trip will take place from a certain origin to a certain destination at a certain time. So we might construct a trip accordingly : //... existing_trip Trip; Trip.From.append("Toledo"); Trip.To.append("Cleveland"); Trip.Departure("4:30"); Trip.Arrival("5:45"); BusTripKnowledge.insert(Trip); //... If we place each trip into the BusTripKnowledge set, then our agent's beliefs about the ABC Bus Company's trips are complete. Notice that there is no single trip from Detroit to New York. However, John can get to New York from Detroit if he takes the following bus trips:
So while the ABC Bus Company does not provide a one-stop trip, it does provide a multistop trip. The problem is how does our agent know this? The agent needs some way to conclude based on what it knows about bus trips that there is a trip from Detroit to New York. We use a simple chaining process. We search our BusTripKnowledge for the first trip leaving from Detroit. We find one: Detroit to Chicago. We check the To attribute of this trip. If it is equal to "New York" , we stop because we have found a trip. If it is not, we save this trip on a stack. We then search through the trips to see if there is another trip whose From attribute = "Chicago" . We find that there are no buses leaving from Chicago. Therefore, we pop the Detroit to Chicago trip from the stack. We note that we have used this trip, and we search for the next trip leaving from Detroit to anywhere . We find a trip: Detroit to Toledo. We check to see if the To attribute = "New York" , and since it does not, we save this trip on a stack. We then search through the trips to see if there is another trip whose From attribute = "Toledo" . Here we find one: Toledo to Cleveland. We then place this trip on the stack. We then search through the trips to see if there is another trip whose From attribute = "Cleveland" . At each trip we check the To attribute. If the To attribute = "New York" , then the trips on the stack represent a bus trip from Detroit to New York, with the starting trip at the bottom of the stack and the ending trip on the top of the stack. If we go through the entire list and none of the To attributes = "New York" , or we run out of To attributes for the trip on top of the stack, then we pop the top element of the stack and search for the next item whose From attribute is equal to the To attribute of the element on the top of the stack. This process is repeated until either the stack is empty or we've found a trip. This process uses a simplified DFS technique to determine if there is a trip from point A to point B. Our simple agent would use this DFS technique to establish the existence of the trip from Detroit to New York. Once this fact was established, then the agent would update its beliefs about John. The agent will now believe that John is going on vacation. Let's say we added another precondition to John's vacation:
Here the agent must establish whether John's profits are > 150000 and whether there is a bus trip from Detroit to New York. To establish whether John's profits are > 150000, the agent must first establish whether John has added 15 or more new clients. Suppose we convince the software agent that John has added 23 new clients. Then the agent can infer that John's profits are > 150000. From BusTripKnowledge the agent was able to infer that there was a trip from Detroit to New York. Using the beliefs about the bus trips, and the belief about the 23 new clients, the agent uses the process of forward chaining to deduce that John will go on vacation. We call this forward chaining from the fact that with 23 new clients added and the bus schedule facts, the agent moved to the conclusion. The inference form of this process looks like:
In this example, the agent believes A and C to be true. Using the rules of inference, B and D are established to be true. Therefore, the agent will commit to tell us that John will go on vacation. This kind of processing could be assigned to an agent in a situation where a manager has hundreds or even thousands of employees and decides to have agent software regularly schedule employee hours. The manager would then consult the agent to see who was working, who was on sick leave, who was on vacation, and so on. The agent would be given knowledge and authority to assign work schedules. Each week the agent would commit to a number of acceptable work schedules, vacations , and sick leaves . The agent in this case uses simple forward chaining and DFS to make its inferences. To implement this kind of inferencing we used struct s, and stack and set classes. These classes are used to hold knowledge, propositions, and patterns of reasoning. They allow us to implement our CDS (Cognitive Data Structures). We used DFS techniques to move through the stack data structures and set structures to support the process of inference. The combination of chaining and DFS produces a process whereby one proposition can be affirmed on the basis of previous propositions that have already been accepted. This is important because our agent will know that it is inherently correct when it accomplishes its objectives based on inference. This also affects parallel programming considerations. The fact that the agent is rational and moves according to rules of inference allows the developer to focus on correctly modeling the task that the agent performs instead of getting bogged down in attempts to explicitly control the parallelism in the program. The minimal requirements of parallelization DCS (decomposition, communication, and synchronization) are in large part addressed by the architecture of the agent. Each agent has a rationale for its behavior. That rationale will be based on well defined, well understood rules of inference. The decomposition happens simply as a matter of assigning the agent one or more prime directives. Thinking of the WBS in this way is natural and ultimately results in parallel or distributed programs that are easier to maintain and enhance. It is easier to think about communication between agents than communication between anonymous modules because the boundaries between agents are clear and obvious. Each agent has a purpose that is immediately apparent. The knowledge or information each agent needs to achieve its purpose is easily determined. To allow the agents to communicate, the developer can use simple MPI calls or the object communication facilities that are part of any CORBA implementation. The most challenging aspect of the communication, namely figuring out:
is implied in the design of the agents. All that is left is the physical implementation of the communication, which is easily handled by any of the libraries that support parallelism that we have discussed in this book. Finally, the problems of synchronization are reduced because the agent's rationale tells it when it can and should perform an action. Therefore, the complicated issues of synchronization are transformed into simpler issues of cooperation. This subtle difference is an important paradigm shift because it simplifies what the software developer has to think about. Lets look a little closer at the basic layout of an agent and how we can implement it in C++. |
 Q
Q EAN: 2147483647
Pages: 133