Determining and Prioritizing Deployment Constraints
| Understanding and Deploying LDAP Directory Services > 8. Namespace Design > Analyzing Your Namespace Needs |
Analyzing Your Namespace NeedsNow that you have some idea what you're going to do with your namespace after you define it, it's time to turn our attention to the design process itself. The first step in designing a namespace is to understand what your needs are. Do you need a flat namespace or a hierarchical one? What attributes should you use to name entries? Do you have replication or data partitioning needs that may affect the design of your namespace? What about access control? What applications will the directory be supporting? Are your needs constant, or might they change over time? These questions and others need to be answered before you can have confidence in your namespace design. This section takes you through the major decisions you'll need to make when designing your namespace. Keep in mind that like many other design problems, namespace design involves a series of tradeoffs, such as administrative convenience for future flexibility. As we examine each of these trade-offs, we'll try to point out what you gain and what you sacrifice at each step. At the end of this chapter we provide a checklist summary of the issues you should consider during the design process. Choosing a SuffixYour directory may have only a local scope, or it may be part of a larger, even a global, directory system. In either case, one of the first choices you have to make when designing your namespace is the suffix below which your namespace will live. Picture your namespace as a tree: A suffix (known as a context prefix in X.500 parlance or a domain in Active Directory) is the name of the entry at the top of the subtree you are designing. If you are designing a strictly local namespace, your suffix may be the null string. All this means is that your namespace begins at the top of the tree (not all servers support this ability). If you are designing a namespace for your department, which is only one part of a larger tree designed for the company, your suffix would name the entry at the top of your department's tree. Examples of suffixes are shown in Figure 8.8. Figure 8.8 Examples of directory suffixes. Often, a directory server may hold more than one suffix. Some directory implementations do this automatically: One suffix holds your data and the other holds data needed for the internal operation of the directory itself. You may want to design a service with multiple suffixes if you have two or more directory trees of information that do not have a natural common root. How Suffixes Work It may help to understand how a suffix is used by a directory server when answering a typical directory query. For example, suppose a client wants to modify the entry named uid=bjensen , dc=babs , dc=com . A Netscape Directory Server receiving the modification request compares the DN in the request to the directory suffixes it holds to determine if the entry to be modified is beneath one of the suffixes held by the server. If the server holds the suffix dc=babs , dc=com or the suffix dc=com , the modification proceeds. If the server holds the suffix dc=abc , dc=com or another suffix not matching the query, the server might refer the client to a different directory server that does hold the requested data. Or, the directory server might simply return an error, assuming that the requested entry does not exist. This depends on the directory's configuration. Flat and Hierarchical SchemesOne of the earliest and most basic choices you have to make in designing a namespace is whether to go with a flat or hierarchical scheme. Of course, this is not a binary decision; your real decision is how much hierarchy and what type to introduce. As a guiding design principle, you should strive to make your namespace as flat as possible. Name changes are typically one of the more burdensome administrative tasks of running a directory, inconvenient both for administrators and users. However, the flatter a namespace is, the less likely names are to change. All other things being equal, one would expect the likelihood of a name change to be proportional to the number of components in the name with the potential for change. The more hierarchical a namespace, the more components and the longer the names. The longer a name, the more likely it is to change. Thus, shorter, flatter names will change less frequently. Tip Make your namespace as flat as possible. Flatter names change less and are easier to administer. Long names introduce needless complexity and administrative burden . Other considerations favor a flat namespace as well. For example, shorter names take up less space. Extra space can be used up if your directory implementation stores full names with entries or if it stores entry names as group members , in seeAlso and other attributes, or in directory configuration parameters. For example, increasing the average name by only 20 bytes (the approximate result of adding just one extra component), represents an increase of 2MB in a directory containing 100,000 entries. Add to this the cost of storing and manipulating the extra directory entries used to create the hierarchy. Not overwhelming, perhaps, in today's world of cheaply available multigigabyte disk drives , but it does add up. And not all environments have the disk space to spare. Further constraints may be imposed if an application is performing in-memory caching. Other important, related implications include the extra time it takes to do backups , the extra network bandwidth required to replicate the directory, and so on. The shorter a name, the easier it is to remember ”a clear benefit to users and administrators. Of course, we just got through telling you that names should never be inflicted upon users, and therefore the aesthetics of a name should not be an important consideration. The same argument could be made regarding the benefit of mnemonic names. But other things being equal, easy-to-remember names are better than hard-to-remember names. Figure 8.9 shows an example of a flat namespace that requires only short names. Figure 8.9 An example of a flat namespace.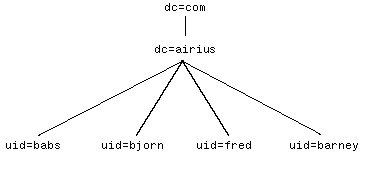 Of course, there are some reasons to introduce a certain amount of hierarchy into a namespace. As described in the previous section, hierarchy can be used to enable data partitioning among multiple servers, replication, and certain kinds of access control. In addition, hierarchy can be useful to applications that want to browse the directory, although these applications are often better served by constructing virtual directory browsing views using attributes such as seeAlso , which can refer to other directory entries. If you anticipate a centralized directory small enough to exist on a single machine, there is no need to introduce hierarchy to enable data distribution. Such a directory is not as constraining as it may sound. An average- sized Pentium II “class machine can handle a directory on the order of millions of entries (depending on your directory implementation, of course), and it could be replicated to several other machines to handle additional read query load. Write load is more problematic . Write load cannot be distributed with replication (assuming all copies of the data are to be kept in sync) because modifications must be made on all replicas. However, a directory that supports multimaster replication may be able to help handle peak write loads. More on these topics is discussed in Chapter 10. Another reason to introduce hierarchy is to enable the distribution of administrative authority via access control. For example, suppose you want to allow an administrator from the marketing department to have control over marketing entries, the engineering administrator to have control over engineering entries, and so on. Many directory products, however, allow this kind of administrative distribution of control only at hierarchical namespace points. With such a system, different access control rules cannot easily be applied to the same subtree. Some modern systems allow the setting of access control based on directory content rather than the directory namespace. With Netscape Directory Server, for example, you could define a single access control rule stating that the engineering administrator has access to all entries with an attribute value indicating they belong to the engineering department (for example ou=engineering ). Carefully examine your chosen directory implementation's access control capabilities to ensure that you understand how they will restrict your namespace design, or look for software that supports your preferred design. If you do need to introduce hierarchy in your namespace, try to do so sparingly and in a way that avoids problematic name changes as much as possible. Much of your flexibility may be removed because of the reason for needing hierarchy in the first place. For example, if you need hierarchy in order to distribute authority to different departments, there is not much hope in avoiding a name change when a user changes departments. However, name changes can be avoided if you are able to design your hierarchy based on information that is not connected to directory information that is likely to change. For example, you could base your hierarchy on the type of objects in each tree, with one area of the tree for people, another for groups, and so on. It is unlikely , to say the least, that an entry would need to move from one area of the hierarchy to another with a scheme like this. This kind of partitioning can make replication easier in some cases as well. Figure 8.10 shows an example of this kind of hierarchical namespace. Figure 8.10 A hierarchical namespace example.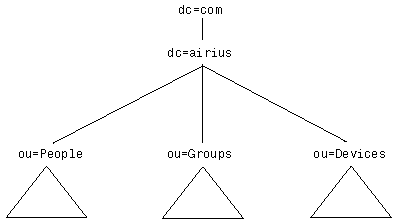 Naming AttributesOnce you've decided on the basic structure of your namespace and the level of hierarchy you need, you need to decide on attributes to use when naming entries. The attribute you should use depends on the type of entry you are naming and other requirements at your site. In this section, we present some general principles that you can apply to naming all kinds of entries. The LDAP model requires taking an attribute from the entry and using it to form the entry's RDN. This might lead you to believe that only attributes naturally occurring in an entry should be used for naming (for example, the cn , or common name, attribute for a person's entry). Actually, there is often little reason for a name to serve any other purpose than to be unique. It is perfectly reasonable, for example, to use an otherwise meaningless attribute that has this uniqueness property. This approach fits well with our earlier admonition about trying to avoid name changes. If the attribute you choose to name an entry serves only that purpose and has no other meaning, the chance of it changing is small. Creating a new attribute may be in conflict with other goals, such as supporting existing (bad) applications that make assumptions about the namespace. If this is the case, you can still use the unique value you created but place it in a compatible, more general-purpose standard attribute such as cn or uid . Although this may offend the sensibilities of some designers, it is a practical alternative that has many advantages. When naming entries, take care to ensure that no two sibling entries (entries with the same immediate parent entry) have the same RDN. This requirement of the LDAP naming model is necessary to ensure that a DN can refer to at most one entry in your LDAP server. One strategy for ensuring uniqueness among RDNs is to choose the kind of naming attribute just described: one that is unique across your entire space of entries. You might accomplish this by assigning entries a sequentially increasing number as they are created (either a time stamp or a number you maintain), or by using some existing unique attribute (for example, an employee number or login ID for person entries). Another approach to guaranteeing uniqueness is to artificially make the attribute you have chosen unique, perhaps by appending a number. For example, suppose you choose the cn attribute to name entries and have two entries with the same parent that would otherwise both be named cn=Barbara Jensen . You could append a number to one or both of the names, making cn=Barbara Jensen 1 and cn=Barbara Jensen 2 the names of the two entries. Although this approach may have some aesthetic value, it also is harder to maintain. In our experience, users generally dislike having their names changed in any way, even for such a clear administrative reason. It may well be better to use something more arbitrary with no value to the user. This scheme may be more difficult to maintain because it requires some external mechanism to manage the process of making names unique. Be sure to pilot any user naming decisions with your user community; it's often hard to predict what they will like and dislike (see Figure 8.11 for examples). This is another good reason to hide DNs from your users. Figure 8.11 Examples of entry names. Some naturally occurring naming attributes may be sensitive in nature, and you may not want to use them for fear of unintentionally revealing information that should not be revealed. A U.S. Social Security number is a good example of such an attribute. If you use it to name your people entries, you guarantee uniqueness ”but at the expense of publishing everybody's Social Security number, a practice guaranteed to make you highly unpopular. In a case such as this, consider using some one-way hash of the value in question rather than the value itself. As long as you choose a good hashing function, the uniqueness property is maintained , and you need not fear anyone being able to deduce easily the sensitive information from the naming attribute. Two popular and good hashing functions are provided by the MD5 and SHA algorithms. The LDAP model also allows the use of multiple attributes from an entry to form a multivalued RDN . The idea behind this capability is to use the additional attributes to distinguish entries that otherwise would have the same name. For example, suppose you have two users named Barbara Jensen, one in the California office and the other in the Michigan office. Using multivalued RDNs, you could distinguish between these two entries by naming one cn=Barbara Jensen + l=California and the other cn=Barbara Jensen + l=Michigan . This practice tends to lead to long, complicated names that change frequently (what if either Barbara moves?). Also, some directory implementations, such as the Netscape Directory Server, do not fully support multivalued RDNs. For these reasons, we strongly discourage their use and encourage you instead to use one of the other naming conflict-resolution strategies discussed. Tip When choosing a naming attribute, use something that is unlikely to change and is unique across your directory. Try to use a standard attribute name and avoid unintentionally exposing sensitive information. Sensitive attributes can sometimes be used by employing a hash of the sensitive value rather than the value itself. Avoid using multivalued RDNs for naming. Pilot your naming scheme to make sure users do not hate it. Application ConsiderationsMost people do not design and run a directory service for its own sake. Typically, the directory is required to support one or more directory-enabled applications. The requirements these applications place on the namespace and other aspects of your design are important design considerations. After all, if your directory does not satisfy the requirements of the applications driving its deployment, your chances of postdeployment employment are small. The requirements an application can place on your directory are as varied as the applications themselves . Lest you become dismayed and think that anticipating the needs of an endless parade of different applications is a lost cause, consider the following. First, focusing on the needs of directory applications existing or being deployed in your organization today will probably provide you with a fairly representative cross-section of requirements. Make sure you understand these needs as well as possible before you consider yourself finished with your directory design (see Chapter 5, "Defining Your Directory Needs" ). Piloting your directory on a smaller, test-scale deployment is also a good idea. Second, some general principles you can follow will help prepare you for that future parade of directory-enabled applications. These principles are important to keep in mind both when designing your directory and when writing a directory-enabled application. For more information, see Chapter 20, "Developing New Applications." A well-written , directory-enabled application makes a concerted effort to assume as little as possible about the directory service it will access. An application should be configurable and able to adapt to new namespaces, new types of acceptable queries, schema differences, nonstandard port numbers , new host names, and more. Of course, not all applications are able to provide this kind of flexibility. How can you design your namespace to anticipate as many of these problems as possible? If your existing needs allow it, one good approach is to use a standard namespace design. Although no real standard exists today, there is ongoing work in this area. For example, there is a current Internet Draft that describes an Internet domain component namespace model. This model solves several namespace design problems, such as choosing the suffix under which the rest of your namespace lives. In the domain component namespace, your suffix is constructed by taking your domain name (for example, netscape.com ) and algorithmically turning it into a DN (for example dc=netscape , dc=com ). Beneath this suffix, namespace design is up to you. This namespace allows you to automatically go from a domain name (as found in an email address, for example) to a DN. An example of this approach to naming is shown in Figure 8.12. Figure 8.12 Examples of standard namespaces. Earlier, we advised that when it comes down to picking the attribute used to name entries, try to use a standard attribute such as cn or uid . If you are considering creating a new attribute to hold the naming value ”for example, employeeID ”consider placing the value of the employeeID attribute in the cn or another standard attribute, and then use that attribute for naming instead of employeeID . Although this might seem aesthetically unpleasant, applications that assume standard attributes for the namespace will not become confused . Namespace and other directory design choices like this are common. When starting from scratch, you can often afford to make things aesthetically pleasing as well as functional. It is rare, unfortunately , that you will be able to start completely from scratch without worrying about any existing applications. Administrative ConsiderationsWhen designing your namespace, consider the effect the namespace will have on common administrative tasks. For example, when adding an entry, can the naming attributes be generated automatically, or is it a manual process? When entries are deleted, can their naming attributes be reused, or should they forever be reserved for the deleted entry? What effect will a name change have? How often are name changes likely to take place? What other dependencies are there on the namespace? The answers to these questions are seldom independent of the design decisions discussed in the previous sections. In this section, we discuss the administrative implications of those decisions. If your organization already has some unique identifier assigned to users (for example, an employee number, login name, or user ID), it may make sense to use it as the value of the naming attribute. This saves you the administrative burden of devising and maintaining another unique identifier and is a good solution for naming user entries. Other entries, perhaps for printers, groups, or other entities, are another matter. In either case, using an existing attribute type can eliminate another small administrative task: defining a new attribute type to use when naming entries. It also reduces the likelihood that a less-than - intelligent client could be confused by an unknown attribute. The maintenance of the naming attribute is also a consideration. Whether or not the directory is the ultimate source of authority, the problem of reusability must be addressed. Depending on your policies, namespace identifiers might be assigned only once and never reassigned, reassigned after a suitable interval, or reassigned immediately. Whatever policy you choose, there must be some way to enforce the policy. Most directory software does not support an out-of-the-box namespace reuse policy. Instead, you have to enforce such a policy either through some external administrative agent or through an extension to the directory software itself. An example of the former might be a tool for adding entries to the directory that consults an external database managing the reuse policy. An example of the latter might be a plug-in to the Netscape Directory Server that performs that same process. Almost inevitably, name changes will occur for various reasons. If you choose a naming attribute that has any significance other than its uniqueness, it can change. If you choose a naming attribute that has a relation to some real-world attribute of the entity being named, or if you choose a hierarchical namespace whose upper components could change, names will also change. The consequences of a name change should be carefully considered . How much trouble will it cause and what is the likelihood of its occurrence? Tip Beware of thinking that a name change will be the exceptional case, so rare that you would not mind handling such occurrences through even a tedious manual process. Our experience shows that such trouble has a habit of occurring more frequently than you might imagine. You also need to consider what will happen as your directory grows (a prediction likely to come true). What may seem uncommon in a small directory can become a downright nuisance in a large one. A final consideration is whether there are other dependencies on the namespace you choose. For example, there might be an application someone has written that assumes a particular structure to the namespace. Without question, this is an example of an evil application. Yet, if the application is servicing your users, you must be concerned about breaking it. Privacy ConsiderationsDirectory names are usually public information available to anyone who can access the directory. Trying to control access to names via your directory's access control mechanism can often lead to difficulties. For this reason, you must carefully consider the privacy implications of your namespace design. Your goal should be not to divulge any information through the namespace that you do not intend to divulge. For example, if you design a namespace for your people entries based on organizational hierarchy, you reveal the part of your organization an entry (and presumably the corresponding person) resides in. The same problem holds true for many other hierarchical namespace designs. As described earlier, the attribute you choose to name your entries after may be considered sensitive. We saw an example earlier involving the use of Social Security numbers for naming attributes. Clearly, this would be a bad idea, so we suggested using a hashed -value form of the sensitive information. There are other, more subtle privacy concerns as well. For example, using the cn attribute containing a person's name to name entries has a host of implications. A person's gender can often be inferred from his or her name, as can other information such as nationality or ethnicity . Not to mention the fact that a name is often enough to gain other information ”such as an address, phone number, and so on ”from other publicly available sources. Care should be taken to protect privacy and to ensure that unwanted disclosure of information is minimized. Keep in mind that things that are obviously acceptable to you may be completely unacceptable to some of your users. For example, you might not mind disclosing your name or even your address to everyone in your company or the world. However, one of your users who might be concerned about potential harassment or stalking ”or even worse ”might feel quite differently. Try to design a namespace that is free of such considerations, and be prepared to make exceptions for people who have legitimate concerns with any design you come up with. It may be a good idea to involve your legal department to help interpret legal issues associated with directory information privacy. Directory privacy is covered in more detail in Chapter 11. Anticipating the FutureFinally, as difficult as it may be, you must try to anticipate the future when designing your namespace. The reason is simple: A namespace redesign is a costly and inconvenient process that you want to avoid. Because none of us has a crystal ball, the best we can do is try to avoid common situations in which namespace changes are required. The question naturally arises, therefore, about the kinds of situations that precipitate a namespace redesign. Some of the more common situations are described in the following list:
Although no one can accurately predict the future, there are some defensive namespace design tactics you can use to minimize your risk. Choosing a flat namespace is one such tactic. Subdividing your namespace based on unchanging information ”perhaps into areas for people, groups, devices ” permits redesigns in one space that do not affect the others.
|
Index terms contained in this sectionaccess controladministrative hierarchical namespaces setting based on directory content administrators access control hierarchical namespaces namespace requirements 2nd 3rd name changes naming attribute maintenance unique user IDs applications conflicts naming attributes namespace requirements 2nd 3rd application flexibility standard attributes standard namespaces text-scale deployments attributes namespace naming 2nd 3rd 4th 5th naming standard benefits flat namespace designs name changes saving space hierachical namespaces administrative access control choosing suffixes 2nd 3rd multiple conflicts application naming attributes content directories access control, setting deployment test-scale measuring namespace application requirements design namespace administrative requirements 2nd 3rd anticipating the future 2nd application requirements 2nd 3rd 4th 5th 6th 7th flat vs. hierarchical designs 2nd 3rd 4th 5th 6th naming attributes 2nd 3rd 4th 5th privacy considerations 2nd 3rd suffixes, choosing 2nd 3rd 4th directories content access control, setting namespaces administrative requirements 2nd 3rd anticipating the future 2nd application requirements 2nd 3rd 4th 5th 6th 7th flat vs. hierachical designs 2nd 3rd 4th 5th 6th naming attributes 2nd 3rd 4th 5th privacy considerations 2nd 3rd suffixes, choosing 2nd 3rd 4th duplicate RDNs naming attributes entries RDNs forming flat namespace designs 2nd avoiding name changes benefits name changes saving space in-memory caching write load hierarchies namespaces 2nd avoiding name changes benefits of 2nd in-memory caching write load maintaining naming attributes namespace administrative requirements multiple suffixes namespace design multivalued RDNs naming attributes 2nd name changes flat namespace designs hierarchical namespace benefits namespace administrative requirements namespaces administrative requirements 2nd 3rd name changes naming attribute maintenance unique user IDs application requirements 2nd 3rd 4th 5th 6th 7th flat vs. hierachical designs 2nd 3rd avoiding name changes in-memory caching write load naming attributes 2nd 3rd 4th 5th application conflicts duplicate RDNs forming entry RDNs multivalued RDNs 2nd naturally occurring 2nd uniqueness 2nd privacy considerations 2nd 3rd cn attribute issues suffixes, choosing 2nd 3rd 4th naming attributes maintaining namespace administrative requirements namespace design 2nd 3rd 4th 5th application conflicts duplicate RDNs forming entry RDNs multivalued RDNs 2nd naturally occuring 2nd uniqueness 2nd naturally occuring naming attributes 2nd needs namespace administrative requirements 2nd 3rd anticipating the future 2nd application requirements 2nd 3rd 4th 5th 6th 7th flat vs. hierachical designs 2nd 3rd 4th 5th 6th naming attributes 2nd 3rd 4th 5th privacy considerations 2nd 3rd suffixes, choosing 2nd 3rd 4th null strings namespace suffixes partitioning hiearchical namespaces privacy namespace considerations 2nd 3rd cn attribute issues RDNs duplicate naming attributes multivalued naming attributes 2nd namespace entries forming replication hiearchical namespaces saving sapce flat namespace designs security privacy anticipating the future 2nd namespace considerations 2nd 3rd space saving flat namespace designs standard attributes application namespace requirements standard namespaces application requirements suffixes choosing 2nd 3rd multiple test-scale deployments measuring namespace application requirements uniqueness duplicate RDNs naming attributes naming attributes 2nd users unquie IDs namespace administrative requirements write load flat vs. hiearchical namespace designs |
| 2002, O'Reilly & Associates, Inc. |
EAN: 2147483647
Pages: 245