XSL Transformations
|
| As you have seen, the XML format is a very useful interchange format for structured data. However, most XML data are not intended for viewing by end users. In this section, we show you how to transform XML data into presentation formats such as HTML or plain text. NOTE
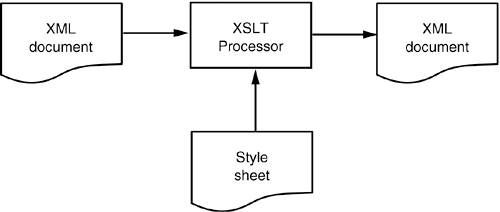
The purpose of a style sheet with transformation templates is to describe the conversion of XML documents into some other format (see Figure 12-8). Figure 12-8. Applying XSL transformations
Here is a typical example. We want to transform XML files with employee records into HTML documents. Consider this input file. <staff> <employee> <name>Carl Cracker</name> <salary>75000</salary> <hiredate year="1987" month="12" day="15"/> </employee> <employee> <name>Harry Hacker</name> <salary>50000</salary> <hiredate year="1989" month="10" day="1"/> </employee> <employee> <name>Tony Tester</name> <salary>40000</salary> <hiredate year="1990" month="3" day="15"/> </employee> </staff> The desired output is an HTML table: <table border="1"> <tr> <td>Carl Cracker</td><td>$75000.0</td><td>1987-12-15</td> </tr> <tr> <td>Harry Hacker</td><td>$50000.0</td><td>1989-10-1</td> </tr> <tr> <td>Tony Tester</td><td>$40000.0</td><td>1990-3-15</td> </tr> </table> This table can be included in a larger HTML document, for example, a page created with JavaServer Pages technology. The XSLT specification is quite complex, and entire books have been written on the subject. We can't possibly discuss all the features of XSLT, so we just work through a representative example. You can find more information in the book Essential XML by Don Box et al. The XSLT specification is available at http://www.w3.org/TR/xslt. A style sheet with transformation templates has this form:
In our example, the xsl:output element specifies the method as HTML. Other valid method settings are xml and text. Here is a typical template: <xsl:template match="/staff/employee"> <tr><xsl:apply-templates/></tr> </xsl:template> The value of the match attribute is an XPath expression. The template states: Whenever you see a node in the XPath set /staff/employee, do the following:
In other words, this template generates the HTML table row markers around every employee record. The XSLT processor starts processing by examining the root element. Whenever a node matches one of the templates, it applies the template. (If multiple templates match, the best-matching one is usedsee the specification for the gory details.) If no template matches, the processor carries out a default action. For text nodes, the default is to include the contents in the output. For elements, the default action is to create no output but to keep processing the children. Here is a template for transforming name nodes in an employee file: <xsl:template match="/staff/employee/name"> <td><xsl:apply-templates/></td> </xsl:template> As you can see, the template produces the <td>...</td> delimiters, and it asks the processor to recursively visit the children of the name element. There is just one child, the text node. When the processor visits that node, it emits the text contents (provided, of course, that there is no other matching template). You have to work a little harder if you want to copy attribute values into the output. Here is an example: <xsl:template match="/staff/employee/hiredate"> <td><xsl:value-of select="@year"/>-<xsl:value-of select="@month"/>-<xsl:value-of select="@day"/></td> </xsl:template> When processing a hiredate node, this template emits
The xsl:value-of statement computes the string value of a node set. The node set is specified by the XPath value of the select attribute. In this case, the path is relative to the currently processed node. The node set is converted to a string by concatenation of the string values of all nodes. The string value of an attribute node is its value. The string value of a text node is its contents. The string value of an element node is the concatenation of the string values of its child nodes (but not its attributes). Example 12-11 contains all transformation templates to turn an XML file with employee records into an HTML table. Example 12-12 shows a different set of transformations. The input is the same XML file, and the output is plain text in the familiar property file format: employee.1.name=Carl Cracker employee.1.salary=75000.0 employee.1.hiredate=1987-12-15 employee.2.name=Harry Hacker employee.2.salary=50000.0 employee.2.hiredate=1989-10-1 employee.3.name=Tony Tester employee.3.salary=40000.0 employee.3.hiredate=1990-3-15 That example uses the position() function, which yields the position of the current node as seen from its parent. We get an entirely different output simply by switching the style sheet. Thus, you can safely use XML to describe your data, even if some applications need the data in another format. Just use XSLT to generate the alternative format. It is extremely simple to generate XSL transformations in the Java platform. Set up a transformer factory for each style sheet. Then get a transformer object, and tell it to transform a source to a result. File styleSheet = new File(filename); StreamSource styleSource = new StreamSource(styleSheet); Transformer t = TransformerFactory.newInstance().newTransformer(styleSource); t.transform(source, result); The parameters of the TRansform method are objects of classes that implement the Source and Result interfaces. There are three implementations of the Source interface: DOMSource SAXSource StreamSource You can construct a StreamSource from a file, stream, reader, or URL, and a DOMSource from the node of a DOM tree. For example, in the preceding section, we invoked the identity transformation as t.transform(new DOMSource(doc), result); In our example program, we do something slightly more interesting. Rather than starting out with an existing XML file, we produce a SAX XML reader that gives the illusion of parsing an XML file by emitting appropriate SAX events. Actually, the XML reader reads a flat file, as described in Volume 1, Chapter 12. The input file looks like this: Carl Cracker|75000.0|1987|12|15 Harry Hacker|50000.0|1989|10|1 Tony Tester|40000.0|1990|3|15 The XML reader generates SAX events as it processes the input. Here is a part of the parse method of the EmployeeReader class that implements the XMLReader interface. AttributesImpl attributes = new AttributesImpl(); handler.startDocument(); handler.startElement("", "staff", "staff", attributes); while ((line = in.readLine()) != null) { handler.startElement("", "employee", "employee", attributes); StringTokenizer t = new StringTokenizer(line, "|"); handler.startElement("", "name", "name", attributes); String s = t.nextToken(); handler.characters(s.toCharArray(), 0, s.length()); handler.endElement("", "name", "name"); . . . handler.endElement("", "employee", "employee"); } handler.endElement("", rootElement, rootElement); handler.endDocument(); The SAXSource for the transformer is constructed from the XML reader: t.transform(new SAXSource(new EmployeeReader(), new InputSource(new FileInputStream(filename))), result); This is an ingenious trick to convert non-XML legacy data into XML. Of course, most XSLT applications will already have XML input data, and you can simply invoke the transform method on a StreamSource, like this: t.transform(new StreamSource(file), result); The transformation result is an object of a class that implements the Result interface. The Java library supplies three classes: DOMResult SAXResult StreamResult To store the result in a DOM tree, use a DocumentBuilder to generate a new document node and wrap it into a DOMResult: Document doc = builder.newDocument(); t.transform(source, new DOMResult(doc)); To save the output in a file, use a StreamResult: t.transform(source, new StreamResult(file)); Example 12-10 contains the complete source code. Examples 12-11 and 12-12 contain two style sheets. This example concludes our discussion of the XML support in the Java library. You should now have a good perspective of the major strengths of XML, in particular, for automated parsing and validation and as a powerful transformation mechanism. Of course, all this technology is only going to work for you if you design your XML formats well. You need to make sure that the formats are rich enough to express all your business needs, that they are stable over time, and that your business partners are willing to accept your XML documents. Those issues can be far more challenging than dealing with parsers, DTDs, or transformations. Example 12-10. TransformTest.java 1. import java.io.*; 2. import java.util.*; 3. import javax.xml.parsers.*; 4. import javax.xml.transform.*; 5. import javax.xml.transform.dom.*; 6. import javax.xml.transform.sax.*; 7. import javax.xml.transform.stream.*; 8. import org.xml.sax.*; 9. import org.xml.sax.helpers.*; 10. 11. /** 12. This program demonstrates XSL transformations. It applies 13. a transformation to a set of employee records. The records 14. are stored in the file employee.dat and turned into XML 15. format. Specify the stylesheet on the command line, e.g. 16. java TransformTest makeprop.xsl 17. */ 18. public class TransformTest 19. { 20. public static void main(String[] args) throws Exception 21. { 22. String filename; 23. if (args.length > 0) filename = args[0]; 24. else filename = "makehtml.xsl"; 25. File styleSheet = new File(filename); 26. StreamSource styleSource = new StreamSource(styleSheet); 27. 28. Transformer t = TransformerFactory.newInstance().newTransformer(styleSource); 29. t.transform(new SAXSource(new EmployeeReader(), 30. new InputSource(new FileInputStream("employee.dat"))), 31. new StreamResult(System.out)); 32. } 33. } 34. 35. /** 36. This class reads the flat file employee.dat and reports SAX 37. parser events to act as if it was parsing an XML file. 38. */ 39. class EmployeeReader implements XMLReader 40. { 41. public void parse(InputSource source) 42. throws IOException, SAXException 43. { 44. InputStream stream = source.getByteStream(); 45. BufferedReader in = new BufferedReader(new InputStreamReader(stream)); 46. String rootElement = "staff"; 47. AttributesImpl atts = new AttributesImpl(); 48. 49. if (handler == null) 50. throw new SAXException("No content handler"); 51. 52. handler.startDocument(); 53. handler.startElement("", rootElement, rootElement, atts); 54. String line; 55. while ((line = in.readLine()) != null) 56. { 57. handler.startElement("", "employee", "employee", atts); 58. StringTokenizer t = new StringTokenizer(line, "|"); 59. 60. handler.startElement("", "name", "name", atts); 61. String s = t.nextToken(); 62. handler.characters(s.toCharArray(), 0, s.length()); 63. handler.endElement("", "name", "name"); 64. 65. handler.startElement("", "salary", "salary", atts); 66. s = t.nextToken(); 67. handler.characters(s.toCharArray(), 0, s.length()); 68. handler.endElement("", "salary", "salary"); 69. 70. atts.addAttribute("", "year", "year", "CDATA", t.nextToken()); 71. atts.addAttribute("", "month", "month", "CDATA", t.nextToken()); 72. atts.addAttribute("", "day", "day", "CDATA", t.nextToken()); 73. handler.startElement("", "hiredate", "hiredate", atts); 74. handler.endElement("", "hiredate", "hiredate"); 75. atts.clear(); 76. 77. handler.endElement("", "employee", "employee"); 78. } 79. 80. handler.endElement("", rootElement, rootElement); 81. handler.endDocument(); 82. } 83. 84. public void setContentHandler(ContentHandler newValue) {handler = newValue;} 85. public ContentHandler getContentHandler() { return handler; } 86. 87. // the following methods are just do-nothing implementations 88. public void parse(String systemId) throws IOException, SAXException {} 89. public void setErrorHandler(ErrorHandler handler) {} 90. public ErrorHandler getErrorHandler() { return null; } 91. public void setDTDHandler(DTDHandler handler) {} 92. public DTDHandler getDTDHandler() { return null; } 93. public void setEntityResolver(EntityResolver resolver) {} 94. public EntityResolver getEntityResolver() { return null; } 95. public void setProperty(String name, Object value) {} 96. public Object getProperty(String name) { return null; } 97. public void setFeature(String name, boolean value) {} 98. public boolean getFeature(String name) { return false; } 99. 100. private ContentHandler handler; 101. } Example 12-11. makehtml.xsl1. <?xml version="1.0" encoding="ISO-8859-1"?> 2. 3. <xsl:stylesheet 4. xmlns:xsl="http://www.w3.org/1999/XSL/Transform" 5. version="1.0"> 6. 7. <xsl:output method="html"/> 8. 9. <xsl:template match="/staff"> 10. <table border="1"><xsl:apply-templates/></table> 11. </xsl:template> 12. 13. <xsl:template match="/staff/employee"> 14. <tr><xsl:apply-templates/></tr> 15. </xsl:template> 16. 17. <xsl:template match="/staff/employee/name"> 18. <td><xsl:apply-templates/></td> 19. </xsl:template> 20. 21. <xsl:template match="/staff/employee/salary"> 22. <td>$<xsl:apply-templates/></td> 23. </xsl:template> 24. 25. <xsl:template match="/staff/employee/hiredate"> 26. <td><xsl:value-of select="@year"/>-<xsl:value-of 27. select="@month"/>-<xsl:value-of select="@day"/></td> 28. </xsl:template> 29. 30. </xsl:stylesheet> Example 12-12. makeprop.xsl[View full width] 1. <?xml version="1.0"?> 2. 3. <xsl:stylesheet 4. xmlns:xsl="http://www.w3.org/1999/XSL/Transform" 5. version="1.0"> 6. 7. <xsl:output method="text"/> 8. 9. <xsl:template match="/staff/employee"> 10. employee.<xsl:value-of select="position()"/>.name=<xsl:value-of select="name/text()"/> 11. employee.<xsl:value-of select="position()"/>.salary=<xsl:value-of select="salary/text()"/> 12. employee.<xsl:value-of select="position()"/>.hiredate=<xsl:value-of select="hiredate javax.xml.transform.TransformerFactory 1.4
javax.xml.transform.stream.StreamSource 1.4
javax.xml.transform.sax.SAXSource 1.4
org.xml.sax.XMLReader 1.4
javax.xml.transform.dom.DOMResult 1.4
org.xml.sax.helpers.AttributesImpl 1.4
|
|
EAN: 2147483647
Pages: 156
- Article 354 Nonmetallic Underground Conduit with Conductors Type NUCC
- Article 426: Fixed Outdoor Electric De-Icing and Snow-Melting Equipment
- Article 700 Emergency Systems
- Example No. D2(c) Optional Calculation for One-Family Dwelling with Heat Pump(Single-Phase, 240/120-Volt Service) (See 220.82)
- Example No. D6 Maximum Demand for Range Loads