Chapter 11. Java and the XML DOM
| CONTENTS |
- Getting XML for Java
- Setting CLASSPATH
- Creating a Parser
- Displaying an Entire Document
- Filtering XML Documents
- Creating a Windowed Browser
- Creating a Graphical Browser
- Navigating in XML Documents
- Modifying XML Documents
This chapter is all about using XML with Java to create standalone programs. In fact, I'll even create a few browsers in this chapter. Here, the programs we write will be based on the XML DOM, and I'll use the XML for Java (XML4J) packages from IBM alphaWorks (http://www.alphaworks.ibm.com/tech/xml4j). This is the famous XML parser that adheres to the W3C standards and has implemented the W3C DOM level 1 (and part of level 2). It's the most widely used standalone XML Java parser available. As of this writing, the current version is 3.0.1, and it's based on the Apache Xerces XML Parser Version 1.0.3.
The alphaWorks site proudly announces:
XML Parser for Java is a validating XML parser written in 100% pure Java. The package (com.ibm.xml.parser) contains classes and methods for parsing, generating, manipulating, and validating XML documents. XML Parser for Java is believed to be the most robust XML processor currently available and conforms most closely to the XML 1.0 Recommendation.
In fact, this points out one of the problems with working with modern XML Java parsers they're always in a state of flux. It turns out that the com.ibm.xml.parser package mentioned here is now deprecated, which in Java terms means that it's obsolete (although still supported) and scheduled to be removed in a future release. Instead, we'll use the org.apache.xerces.parsers package, which is the successor to com.ibm.xml.parser.
This is an occupational hazard when working with third-party parsers, which historically have been extremely volatile. For example, when XML was still very young, I wrote a book based largely on the Microsoft XML Java parser, which was the only commercial-grade Java XML parser available at that time. And just before the book appeared on shelves, Microsoft changed its parser utterly so that virtually none of the code in the book worked. (The Microsoft XML Java parser is not even available as a standalone package anymore.) That's not an uncommon experience.
On the other hand, the alphaWorks parser has been changed so that it's now based on the W3C DOM (the package we'll be using to support nodes and elements in code will be alphaWork's org.w3c.dom package), which means that things have finally become standardized. However, the package names and the actual parsers we'll use, such as org.apache.xerces.parsers.DOMParser in this chapter, are still subject to change. By the time you read this, the alphaWorks packages may well have changed, something that's beyond our control here. In that case, you should refer to the XML for Java documentation to see what changes you need to make to your code now that the W3C DOM is available, those changes should be minimized compared to what happened in the past.
This chapter and the next one provide you with a good introduction to the XML for Java parser. However, there's enough material here to take up a whole book in fact, such books have been published, as recently as last year. (Those books are now obsolete because of changes in the parser surprise!) The XML for Java packages are extensive and come with hundreds of pages of documentation, so if you want to pursue XML for Java programming beyond the techniques that you see in these chapters, dig into that documentation.
We saw XML for Java in this book as early as Chapter 1, "Essential XML," where I used an example that comes with XML for Java named DOMWriter that lets you validate XML documents based on DTDs. In Chapter 1, we saw this document, greeting.xml:
<?xml version="1.0" encoding="UTF-8"?> <DOCUMENT> <GREETING> Hello From XML </GREETING> <MESSAGE> Welcome to the wild and woolly world of XML. </MESSAGE> </DOCUMENT>
I tested this document using DOMWriter like this, where you can see that it reports validation errors:
%java dom.DOMWriter greeting.xml greeting.xml: [Error] greeting.xml:2:11: Element type "DOCUMENT" must be declared [Error] greeting.xml:3:15: Element type "GREETING" must be declared [Error] greeting.xml:6:14: Element type "MESSAGE" must be declared. <?xml version="1.0" encoding="UTF-8"?> <DOCUMENT> <GREETING> Hello From XML </GREETING> <MESSAGE> Welcome to the wild and woolly world of XML. </MESSAGE> </DOCUMENT>
In this chapter, we'll build our own Java programs using XML for Java directly, including parsing and filtering XML documents, as well as creating standalone browsers and even a specialized graphical browser that uses XML documents not to display text, but to display circles. That's one advantage of being able to create your own programs using parsers like the ones in XML for Java: You can create your own specialized browsers.
Getting XML for Java
The first step is to download XML for Java at http://www.alphaworks.ibm.com/tech/xml4j. Currently, you only need to navigate to that site, click the Download button, then select a file to download, and click the Download Selected File button. For example, if you're on a UNIX system, you can select the file labeled Binary distribution packaged as a UNIX Tar.gz file, which is XML4J-bin.3.0.1.tar.gz as of this writing. If you're on Windows, you can select the file labeled Binary distribution packaged as a Windows ZIP file, which is XML4J-bin.3.0.1.zip as of this writing. You can also download the XML for Java source code, which means that you can build everything for yourself.
After you've downloaded the compressed XML for Java file, you must uncompress it yourself (in Windows, make sure that you use an unzip utility that can handle long filenames). That's all for actually installing XML for Java now you must make sure that Java can find it.
Setting CLASSPATH
As far as we're concerned, XML for Java is a huge set of classes ready for us to use. Those classes are stored in Java JAR (Java Archive) files, and we must make sure that Java can search those JAR files for the classes that it needs.
I discussed this process a little in the last chapter when I mentioned using the Java CLASSPATH environment variable. This is the variable that you set to tell Java where to look for additional classes your code may require. In our case, the JAR files we'll need to search for classes are called xerces.jar and xercesSamples.jar (these names may have changed by the time you read this).
Unfortunately, the way you set the CLASSPATH variable can vary by system. For example, to permanently set the class path in Windows NT, you use the Control Panel. In the System Properties dialog box, you click the Environment tab, then click the CLASSPATH variable, and enter the new value there. In Windows 95 or 98, you can use the MS-DOS SET command in autoexec.bat, which sets the value of environment variables. Note, however, that you can also use the MS-DOS SET command to set the class path in Windows 95, 98, and NT to set the class path until the MS-DOS window is closed, which is perhaps the easiest way. For example, if xerces.jar and xercesSamples.jar are in the directory C:\xmlparser\XML4J_3_0_1 on your system, you could use a SET command like this (and put it all on one line):
C:\>SET CLASSPATH=%CLASSPATH%;C:\xmlparser\XML4J_3_0_1\xerces.jar; C:\xmlparser\XML4J_3_0_1\xercesSamples.jar
Take a look at the Java documentation to see how to set CLASSPATH on your system. There's a shortcut if you can't get the CLASSPATH variable working; you can use the -classpath switch when working with the javac and java tools. For example, here's how I compile and run a program named browser.java using that switch to specify the class path I want to use (both commands should be on one line):
%javac -classpath C:\xmlparser\XML4J_3_0_1\xerces.jar; C:\xmlparser\XML4J_3_0_1\xercesSamples.jar browser.java %java -classpath C:\xmlparser\XML4J_3_0_1\xerces.jar; C:\xmlparser\XML4J_3_0_1\xercesSamples.jar browser
We're ready to start working with code. I'll start by writing an example that parses an XML document.
Creating a Parser
This first XML for Java example will get us started by parsing an XML document and displaying the number of a certain element in it. In this chapter, I'm taking a look at using the XML DOM with Java, and I'll use the XML for Java DOMParser class, which creates a W3C DOM tree as its output.
The document we'll parse is one we've seen before customer.xml:
<?xml version = "1.0" standalone="yes"?> <DOCUMENT> <CUSTOMER> <NAME> <LAST_NAME>Smith</LAST_NAME> <FIRST_NAME>Sam</FIRST_NAME> </NAME> <DATE>October 15, 2001</DATE> <ORDERS> <ITEM> <PRODUCT>Tomatoes</PRODUCT> <NUMBER>8</NUMBER> <PRICE>$1.25</PRICE> </ITEM> <ITEM> <PRODUCT>Oranges</PRODUCT> <NUMBER>24</NUMBER> <PRICE>$4.98</PRICE> </ITEM> </ORDERS> </CUSTOMER> <CUSTOMER> <NAME> <LAST_NAME>Jones</LAST_NAME> <FIRST_NAME>Polly</FIRST_NAME> </NAME> <DATE>October 20, 2001</DATE> <ORDERS> <ITEM> <PRODUCT>Bread</PRODUCT> <NUMBER>12</NUMBER> <PRICE>$14.95</PRICE> </ITEM> <ITEM> <PRODUCT>Apples</PRODUCT> <NUMBER>6</NUMBER> <PRICE>$1.50</PRICE> </ITEM> </ORDERS> </CUSTOMER> <CUSTOMER> <NAME> <LAST_NAME>Weber</LAST_NAME> <FIRST_NAME>Bill</FIRST_NAME> </NAME> <DATE>October 25, 2001</DATE> <ORDERS> <ITEM> <PRODUCT>Asparagus</PRODUCT> <NUMBER>12</NUMBER> <PRICE>$2.95</PRICE> </ITEM> <ITEM> <PRODUCT>Lettuce</PRODUCT> <NUMBER>6</NUMBER> <PRICE>$11.50</PRICE> </ITEM> </ORDERS> </CUSTOMER> </DOCUMENT>
In this example, the code will scan customer.xml and report how many <CUSTOMER> elements the document has.
To start this program, I'll import the XML for Java classes that we'll need the org.w3c.dom classes, which support the W3C DOM interfaces, such as Node and Element, and the XML for Java DOM parser we'll use is org.apache.xerces.parsers.DOMParser:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; . . .
I'll call this first program FirstParser.java, so the public class in that file is FirstParser:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class FirstParser { public static void main(String[] args) { . . . } To parse the XML document, you need a DOMParser object, which I'll call parser:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class FirstParser { public static void main(String[] args) { DOMParser parser = new DOMParser(); . . . } } The DOMParser class is derived from the XMLParser class, which in turn is based on the java.lang.Object class:
java.lang.Object | +--org.apache.xerces.framework.XMLParser | +--org.apache.xerces.parsers.DOMParser
The default constructor for the DOMParser class is DOMParser(). The methods of the DOMParser class are listed in Table 11.1.
The keyword protected is an access specifier, just like private and public. The protected access specifier is the same as private, except that derived classes also have access to members that were declared protected in the base class. In addition, the callback methods listed in Table 11.1 are called by DOMParser objects. We'll see how to work with callback methods in the next chapter.
| Method | Description |
|---|---|
| void attlistDecl(int elementTypeIndex, int attrNameIndex, int attType, java.lang. String enumString, int attDefaultType, int attDefaultValue) | Serves as a callback for attribute declarations |
| void characters(int dataIndex) | Serves as a callback for characters |
| void comment(int dataIndex) | Serves as a callback for comments |
| void elementDecl(int elementTypeIndex, XMLValidator.ContentSpec contentSpec) | Serves as a callback for element declarations |
| void endCDATA() | Serves as a callback for the end of CDATA section |
| void endDocument() | Serves as a callback for the end of the document |
| void endDTD() | Is called at the end of the DTD |
| void endElement(int elementTypeIndex) | Serves as a callback for the end of elements |
| void endEntityReference(int entityName, int entityType, int entityContext) | Serves as a callback for the end of entity references |
| void endNamespaceDeclScope(int prefix) | Serves as a callback for the end of the scope of a namespace declaration |
| void externalEntityDecl(int entityNameIndex, int publicIdIndex, int systemIdIndex) | Serves as a callback for external entity references |
| void externalPEDecl(int entityName, int publicId, int systemId) | Serves as a callback for external parameter entities declarations |
| boolean getCreateEntityReferenceNodes() | Is true if entity references in the document are included in the document as EntityReference nodes |
| protected Element getCurrentElementNode() | Returns the current element node |
| protected boolean getDeferNodeExpansion() | Is true if the expansion of nodes is deferred |
| Document getDocument() | Returns the document itself |
| protected java.lang.String getDocumentClassName() | Returns the qualified class name of the document factory |
| boolean getFeature(java.lang.String featureId) | Gets the current state of any feature in a SAX2 parser |
| java.lang.String[] getFeaturesRecognized() | Gets a list of features that this parser recognizes |
| boolean getIncludeIgnorableWhitespace() | Is true if there are ignorable whitespace text nodes in the DOM tree |
| java.lang.String[] getPropertiesRecognized() | Gets a list of properties that the parser recognizes |
| java.lang.Object getProperty(java.lang.String propertyId) | Gets the value of a property in a SAX2 parser |
| void ignorableWhitespace(int dataIndex) | Serves as a callback for ignorable whitespace |
| protected void init() | Initializes or reinitializes the parser to a pre-parse state |
| void internalEntityDecl(int entityNameIndex, int entityValueIndex) | Serves as a callback for an internal entity declaration |
| void internalPEDecl(int entityName, int entityValue) | Serves as a callback for an internal parameter entity declaration |
| void internalSubset(int internalSubset) | Supports DOM Level 2 internalSubsets |
| void notationDecl(int notationNameIndex, int publicIdIndex, int systemIdIndex) | Serves as a callback for notation declarations |
| void processingInstruction(int targetIndex, int dataIndex) | Serves as a callback for processing instructions |
| void reset() | Resets the parser |
| void resetOrCopy() | Resets or copies the parser |
| protected void setCreateEntity ReferenceNodes(boolean create) | Indicates whether entity references in the document are part of the document as EntityReference nodes |
| protected void setDeferNodeExpansion (boolean deferNodeExpansion) | Indicates whether the expansion of the nodes is deferred |
| protected void setDocumentClassName (java.lang.String documentClassName) | Lets you decide which document factory to use |
| void setFeature(java.lang.String featureId, boolean state) | Sets the state of any feature in a SAX2 parser |
| void setIncludeIgnorableWhitespace (boolean include) | Specifies whether ignorable whitespace text nodes are included in the DOM tree |
| void setProperty(java.lang.String propertyId, java.lang.Object value) | Sets the value of any property in a SAX2 parser |
| void startCDATA() | Serves as a callback for the start of a CDATA section |
| void startDocument(int versionIndex, int encodingIndex, int standAloneIndex) | Serves as a callback for the start of a document |
| void startDTD(int rootElementType, int publicId, int systemId) | Serves as a callback for the start of a DTD |
| void startElement(int elementTypeIndex, XMLAttrList xmlAttrList, int attrListIndex) | Serves as a callback for the start of an element |
| void startEntityReference(int entityName, int entityType, int entityContext) | Serves as a callback for the start of an entity reference |
| void startNamespaceDeclScope (int prefix, int uri) | Serves as a callback for the start of the scope of a namespace declaration |
| void unparsedEntityDecl(int entityNameIndex, int publicIdIndex, int systemIdIndex, int notationNameIndex) | Serves as a callback for an unparsed entity declaration |
The DOMParser class is based on the XMLParser class, and the XMLParser class has a great deal of functionality that you frequently use in XML for Java programming. The XMLParser constructor is protectedXMLParser(). The methods of the XMLParser class are listed in Table 11.2.
| Method | Description |
|---|---|
| void addRecognizer(org.apache.xerces.readers. XMLDeclRecognizer recognizer) | Adds a recognizer |
| abstract void attlistDecl(int elementType, int attrName, int attType, java.lang. String enumString, int attDefaultType, int attDefaultValue) | Serves as a callback for an attribute list declaration |
| void callCharacters(int ch) | Calls the characters callback |
| void callComment(int comment) | Calls the comment callback |
| void callEndDocument() | Calls the end document callback |
| boolean callEndElement(int readerId) | Calls the end element callback |
| void callProcessingInstruction (int target, int data) | Calls the processing instruction callback |
| void callStartDocument(int version, int encoding, int standalone) | Calls the start document call back |
| void callStartElement(int elementType) | Calls the start element callback |
| org.apache.xerces.readers.XMLEntityHandler. EntityReader changeReaders() | Is called by the reader subclasses at the end of input |
| abstract void characters(char[] ch, int start, int length) | Serves as a callback for characters |
| abstract void characters(int data) | Serves as a callback for characters using string pools |
| abstract void comment(int comment) | Serves as a callback for comment |
| void commentInDTD(int comment) | Serves as a callback for comment in DTD |
| abstract void elementDecl(int elementType, XMLValidator.ContentSpec contentSpec) | Serves as a callback for an element declaration |
| abstract void endCDATA() | Serves as a callback for end of the CDATA section |
| abstract void endDocument() | Serves as a callback for the end of the document |
| abstract void endDTD() | Serves as a callback for the end of the DTD |
| abstract void endElement(int elementType) | Serves as a callback for end of the element |
| void endEntityDecl() | Serves as a callback for the end of an entity declaration |
| abstract void endEntityReference (int entityName, int entityType, int entityContext) | Serves as a callback for the end of an entity reference |
| abstract void endNamespaceDeclScope (int prefix) | Serves as a callback for the end of a namespace declaration scope |
| java.lang.String expandSystemId (java.lang.String systemId) | Expands a system id and returns the system id as an URL |
| abstract void externalEntityDecl (int entityName, int publicId, int systemId) | Serves as a callback for an external general entity declaration |
| abstract void externalPEDecl(int entityName, int publicId, int systemId) | Serves as a callback for an external parameter entity declaration |
| protected boolean getAllowJavaEncodings() | Is true if Java encoding names are allowed in the XML document |
| int getColumnNumber() | Gives the column number of the current position in the document |
| protected boolean getContinueAfterFatalError() | Is true if the parser will continue after a fatal error |
| org.apache.xerces.readers.XMLEntityHandler. EntityReader getEntityReader() | Gets the Entity reader |
| EntityResolver getEntityResolver() | Gets the current entity resolver |
| ErrorHandler getErrorHandler() | Gets the current error handler |
| boolean getFeature(java.lang.String featureId) | Gets the state of a feature |
| java.lang.String[] getFeaturesRecognized() | Gets a list of features recognized by this parser |
| int getLineNumber() | Gets the current line number in the document |
| Locator getLocator() | Gets the locator used by the parser |
| protected boolean getNamespaces() | Is true if the parser preprocesses namespaces |
| java.lang.String[] getPropertiesRecognized() | Gets the list of recognized properties for the parser |
| java.lang.Object getProperty(java.lang. String propertyId) | Gets the value of a property |
| java.lang.String getPublicId() | Gets the public id of the InputSource |
| protected org.apache.xerces.validators. schema.XSchemaValidator getSchemaValidator() | Gets the current XML schema validator |
| java.lang.String getSystemId() | Gets the system id of the InputSource |
| protected boolean getValidation() | Is true if validation is turned on |
| protected boolean getValidationDynamic() | Is true if validation is determined based on whether a document contains a grammar |
| protected boolean getValidation WarnOnDuplicateAttdef() | Is true if an error is created when an attribute is redefined in the grammar |
| protected boolean getValidationWarnOnUndeclaredElemdef() | Is true if the parser creates an error when an undeclared element is referenced |
| abstract void ignorableWhitespace(char[] ch, int start, int length) | Serves as a callback for ignorable whitespace |
| abstract void ignorableWhitespace(int data) | Serves as a callback for ignorable whitespace based on string pools |
| abstract void internalEntityDecl (int entityName, int entityValue) | Serves as a callback for internal general entity declaration |
| abstract void internalPEDecl(int entityName, int entityValue) | Serves as a callback for an internal parameter entity declaration |
| abstract void internalSubset (int internalSubset) | Supports DOM Level 2 internalSubsets |
| boolean isFeatureRecognized (java.lang.String featureId) | Is true if the given feature is recognized |
| boolean isPropertyRecognized (java.lang.String propertyId) | Is true if the given property is recognized |
| abstract void notationDecl(int notationName, int publicId, int systemId) | Serves as a callback for a notation declaration |
| void parse(InputSource source) | Parses the given input source |
| void parse(java.lang.String systemId) | Parses the input source given by a system identifier |
| boolean parseSome() | Supports application-driven parsing |
| boolean parseSomeSetup(InputSource source) | Sets up application-driven parsing |
| void processCharacters(char[] chars, int offset, int length) | Processes character data given a character array |
| void processCharacters(int data) | Processes character data |
| abstract void processingInstruction (int target, int data) | Serves as a callback for processing instructions |
| void processingInstructionInDTD (int target, int data) | Serves as a callback for processing instructions in a DTD |
| void processWhitespace(char[] chars, int offset, int length) | Processes whitespace |
| void processWhitespace(int data) | Processes whitespace based on string pools |
| void reportError(Locator locator, java.lang.String errorDomain, int majorCode, int minorCode, java.lang.Object[] args, int errorType) | Reports errors |
| void reset() | Resets the parser so that it can be reused |
| protected void resetOrCopy() | Resets or copies the parser |
| int scanAttributeName(org.apache.xerces. readers.XMLEntityHandler.EntityReader entityReader, int elementType) | Scans an attribute name |
| int scanAttValue(int elementType, int attrName) | Scans an attribute value |
| void scanDoctypeDecl(boolean standalone) | Scans a doctype declaration |
| int scanElementType(org.apache.xerces. readers.XMLEntityHandler.EntityReader entityReader, char fastchar) | Scans an element type |
| boolean scanExpectedElementType (org.apache.xerces.readers.XMLEntityHandler. EntityReader entityReader, char fastchar) | Scans an expected element type |
| protected void setAllowJavaEncodings (boolean allow) | Supports the use of Java encoding names |
| protected void setContinueAfterFatalError (boolean continueAfterFatalError) | Lets the parser continue after fatal errors |
| void setEntityResolver(EntityResolver resolver) | Specifies the resolver (resolves external entities) |
| void setErrorHandler(ErrorHandler handler) | Sets the error handler |
| void setFeature(java.lang.String featureId, boolean state) | Sets the state of a feature |
| void setLocale(java.util.Locale locale) | Sets the locale |
| void setLocator(Locator locator) | Sets the locator |
| protected void setNamespaces(boolean process) | Specifies whether the parser preprocesses namespaces |
| void setProperty(java.lang.String propertyId, java.lang.Object value) | Sets the value of a property |
| void setReaderFactory(org.apache.xerces. readers.XMLEntityReaderFactory readerFactory) | Sets the reader factory |
| protected void setSendCharDataAsCharArray) (boolean flag) | Sets character data processing preferences |
| void setValidating(boolean flag) | Indicates to the parser that we are validating |
| protected void setValidation(boolean validate) | Specifies whether the parser validates |
| protected void setValidationDynamic (boolean dynamic) | Lets the parser validate a document only if it contains a grammar |
| protected void setValidationWarnOn) DuplicateAttdef(boolean warn) | Specifies whether an error is created when attributes are redefined in the grammar |
| protected void setValidationWarnOn UndeclaredElemdef(boolean warn) | Specifies whether the parser causes an error when an element's content model references an element by name that is not declared |
| abstract void startCDATA() | Serves as a callback for start of the CDATA section |
| abstract void startDocument(int version, int encoding, int standAlone) | Serves as a callback for the start of the document |
| abstract void startDTD(int rootElementType, int publicId, int systemId) | Serves as a callback for the start of the DTD |
| abstract void startElement(int elementType, XMLAttrList attrList, int attrListHandle) | Serves as a callback for the start of the element |
| boolean startEntityDecl(boolean isPE, int entityName) | Serves as a callback for the start of an entity declaration |
| abstract void startEntityReference (int entityName, int entityType, int entityContext) | Serves as a callback for start of an entity reference |
| abstract void startNamespaceDeclScope (int prefix, int uri) | Serves as a callback for the start of a namespace declaration scope |
| boolean startReadingFromDocument (InputSource source) | Starts reading from a document |
| boolean startReadingFromEntity(int entityName, int readerDepth, int context) | Starts reading from an external entity |
| void startReadingFromExternalSubset (java.lang.String publicId, java.lang.String systemId, int readerDepth) | Starts reading from an external DTD subset |
| void stopReadingFromExternalSubset() | Stops reading from an external DTD subset |
| abstract void unparsedEntityDecl (int entityName, int publicId, int systemId, int notationName) | Serves as a callback for unparsed entity declarations |
| boolean validEncName(java.lang.String encoding) | Is true if the given encoding is valid |
| boolean validVersionNum(java.lang.String version) | Is true if the given version is valid |
To actually parse the XML document, you use the parse method of the parser object. I'll let the user specify the name of the document to parse on the command by parsing args[0]. Note that you don't need to pass the name of a local file to the parse method you can pass the URL of a document on the Internet, and the parse method will retrieve that document.
When you use the parse method, you need to enclose your code in a try block to catch possible errors, like this:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class FirstParser { public static void main(String[] args) { try { DOMParser parser = new DOMParser(); parser.parse(args[0]); . . . } catch (Exception e) { e.printStackTrace(System.err); } } } If the document is successfully parsed, you can get a Document object based on the W3C DOM, corresponding to the parsed document, using the parser's getDocument method:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class FirstParser { public static void main(String[] args) { try { DOMParser parser = new DOMParser(); parser.parse(args[0]); Document doc = parser.getDocument(); . . . } catch (Exception e) { e.printStackTrace(System.err); } } } The Document interface is part of the W3C DOM, and you can find the methods of this interface in Table 11.3.
| Method | Description |
|---|---|
| Attr createAttribute(java.lang.String name) | Creates an attribute of the given name |
| Attr createAttributeNS(java.lang.String namespaceURI, java.lang.String qualifiedName) | Creates an attribute of the given qualified name and namespace |
| CDATASection createCDATASection (java.lang.String data) | Creates a CDATASection node |
| Comment createComment(java.lang.String data) | Creates a Comment node |
| DocumentFragment createDocumentFragment() | Creates an empty DocumentFragment object |
| Element createElement(java.lang.String tagName) | Creates an element of the type given |
| Element createElementNS(java.lang.String namespaceURI, java.lang.String qualifiedName) | Creates an element of the given qualified name and namespace |
| EntityReference createEntityReference (java.lang.String name) | Creates an EntityReference object |
| ProcessingInstruction createProcessing Instruction(java.lang.String target,java.lang.String data) | Creates a ProcessingInstruction node with the given name and data |
| Text createTextNode(java.lang.String data) | Creates a Text node |
| DocumentType getDoctype() | Gets the document type declaration for this document |
| Element getDocumentElement() | Gets the root element of the document |
| Element getElementById(java.lang. String elementId) | Gets the element with the given id |
| NodeList getElementsByTagName (java.lang.String tagname) | Returns a NodeList of all the elements with a given tag name |
| NodeList getElementsByTagNameNS(java.lang. String namespaceURI, java.lang.String localName) | Returns a NodeList of all the elements with a given local name and namespace URI |
| DOMImplementation getImplementation() | Gets the DOMImplementation object |
| Node importNode(Node importedNode, boolean deep) | Imports a node from another document |
The Document interface is based on the Node interface, which supports the W3C Node object. Nodes represent a single node in the document tree (as you recall, everything in the document tree, including text and comments, is treated as a node). The Node interface has many methods that you can use to work with nodes; for example, you can use methods such as getNodeName and getNodeValue to get information about the node, and we'll use this kind of information a great deal in this chapter. This interface also has data members, called fields, which hold constant values corresponding to various node types, and we'll see them in this chapter as well. You'll find the Node interface fields in the following bulleted list and the methods of this interface in Table 11.4. As you see in Table 11.4, the Node interface contains all the standard W3C DOM methods for navigating in a document that we already used with JavaScript in Chapter 7, "Handling XML Documents with JavaScript," including getNextSibling, getPreviousSibling, getFirstChild, getLastChild, and getParent. We'll put those methods to work here as well.
-
static short ATTRIBUTE_NODE
-
static short CDATA_SECTION_NODE
-
static short COMMENT_NODE
-
static short DOCUMENT_FRAGMENT_NODE
-
static short DOCUMENT_NODE
-
static short DOCUMENT_TYPE_NODE
-
static short ELEMENT_NODE
-
static short ENTITY_NODE
-
static short ENTITY_REFERENCE_NODE
-
static short NOTATION_NODE
-
static short PROCESSING_INSTRUCTION_NODE
-
static short TEXT_NODE
| Method | Description |
|---|---|
| Node appendChild(Node newChild) | Adds the newChild node as the last child node of this node |
| Node cloneNode(boolean deep) | Creates a duplicate of this node |
| NamedNodeMap getAttributes() | Gets a NamedNodeMap containing the attributes of this node |
| NodeList getChildNodes() | Gets a NodeList that contains all children of this node |
| Node getFirstChild() | Gets the first child of this node |
| Node getLastChild() | Gets the last child of this node |
| java.lang.String getLocalName() | Gets the local name of the node |
| java.lang.String getNamespaceURI() | Gets the namespace URI of this node |
| Node getNextSibling() | Gets the node immediately following this one |
| java.lang.String getNodeName() | Gets the name of this node |
| short getNodeType() | Gets a code representing the type of the node |
| java.lang.String getNodeValue() | Gets the value of this node |
| Document getOwnerDocument() | Gets the Document object that owns this node |
| Node getParentNode() | Gets the parent of this node |
| java.lang.String getPrefix() | Gets the namespace prefix of this node |
| Node getPreviousSibling() | Gets the node immediately before this one |
| boolean hasChildNodes() | Is true if this node has any children |
| Node insertBefore(Node newChild, Node refChild) | Inserts the node newChild before the child node refChild |
| void normalize() | Normalizes text nodes by making sure that there are no immediately adjacent or empty text nodes |
| Node removeChild(Node oldChild) | Removes the child node oldChild |
| Node replaceChild(Node newChild, Node oldChild) | Replaces the child node oldChild with newChild |
| void setNodeValue (java.lang.String nodeValue) | Sets a node's value |
| void setPrefix(java.lang.String prefix) | Sets a prefix |
| boolean supports(java.lang.String feature, java.lang.String version) | Is true if the DOM implementation implements a specific feature supported by this node |
At this point, we have access to the root node of the document. Our goal here is to check how many <CUSTOMER> elements the document has, so I'll use the getElementsByTagName method to get a NodeList object containing a list of all <CUSTOMER> elements:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class FirstParser { public static void main(String[] args) { try { DOMParser parser = new DOMParser(); parser.parse(args[0]); Document doc = parser.getDocument(); NodeList nodelist = doc.getElementsByTagName("CUSTOMER"); . . . } catch (Exception e) { e.printStackTrace(System.err); } } } The NodeList interface supports an ordered collection of nodes. You can access nodes in such a collection by index, and we'll do that in this chapter. You can find the methods of the NodeList interface in Table 11.5.
| Method | Description |
|---|---|
| int getLength() | Gets the number of nodes in this list |
| Node item(int index) | Gets the item at the specified index value in the collection |
In Table 11.5, you'll see that the NodeList interface supports a getLength method that returns the number of nodes in the list. This means that we can find how many <CUSTOMER> elements there are in the document like this:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class FirstParser { public static void main(String[] args) { try { DOMParser parser = new DOMParser(); parser.parse(args[0]); Document doc = parser.getDocument(); NodeList nodelist = doc.getElementsByTagName("CUSTOMER"); System.out.println(args[0] + " has " + nodelist.getLength() + " <CUSTOMER>elements."); } catch (Exception e) { e.printStackTrace(System.err); } } } You can see the results of this code here, indicating that customer.xml has three <CUSTOMER> elements, which is correct:
%java FirstParser customer.xml customer.xml has 3 <CUSTOMER> elements.
If you prefer to use the -classpath switch instead of explicitly setting the class path, you could use javac like this, assuming the needed .jar files are in the current directory:
javac -classpath xerces.jar;xercesSamples.jar FirstParser.java
And then execute the code like this:
javac -classpath xerces.jar;xercesSamples.jar FirstParser customer.xml
That's all it takes to get started with the XML for Java parsers.
Displaying an Entire Document
In this next example, I'm going to write a program that will parse and display an entire document, indenting each element, processing instruction, and so on, as well as displaying attributes and their values. For example, if you pass customer.xml to this program, which I'll call IndentingParser.java, that program will display the whole document properly indented.
I start by letting the user specify what document to parse and then parsing that document as before. To actually parse the document, I'll call a new method, displayDocument, from the main method:
public static void main(String args[]) { displayDocument(args[0]); . . . } In the displayDocument method, I'll parse the document and get an object corresponding to that document:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class IndentingParser { public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); . . . } catch (Exception e) { e.printStackTrace(System.err); } . . . The actual method that will parse the document, display, will be recursive, as we saw when working with JavaScript. I'll pass the document to parse to that method, as well as the current indentation string (which will grow by four spaces for every successive level of recursion):
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class IndentingParser { public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); display(document, ""); } catch (Exception e) { e.printStackTrace(System.err); } } . . . In the display method, I'll check to see whether the node passed to us is really a node if not, return from the method. The next job is to display the node, and how we do that depends on the type of node we're working with. To get the type of node, you can use the node's getNodeType method; I'll set up a long switch statement to handle the different types:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class IndentingParser { public static void displayDocument(String uri) { . . . } public static void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { . . . To handle output from this program, I'll create an array of strings, displayStrings, placing each line of the output into one of those strings. I'll also store our current location in that array in an integer named numberDisplayLines:
public class IndentingParser { static String displayStrings[] = new String[1000]; static int numberDisplayLines = 0; . . . I'll start handling various types of nodes in this switch statement now.
Handling Document Nodes
At the beginning of the document is the XML declaration, and the type of this node matches the constant Node.DOCUMENT_NODE defined in the Node interface (see Table 11.4). This declaration takes up one line of output, so I'll start the first line of output with the current indent string, followed by a default XML declaration.
The next step is to get the document element of the document we're parsing (the root element), and you do that with the getDocumentElement method. The root element contains all other elements, so I pass that element to the display method, which will display all those elements:
public static void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { case Node.DOCUMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?xml version=\"1.0\" encoding=\""+ "UTF-8" + "\"?>"; numberDisplayLines++; display(((Document)node).getDocumentElement(), ""); break; } . . . Handling Element Nodes
To handle an element node, we should display the name of the element, as well as any attributes the element has. I start by checking whether the current node type is Node.ELEMENT_NODE; if so, I place the current indent string into a display string, followed by a < and the element's name, which I can get with the getNodeName method:
switch (type) { . . . case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); . . . Handling Attributes
Now we've got to handle the attributes of this element, if it has any. Because the current node is an element node, you can use the method getAttributes to get a NodeList object holding all its attributes, which are stored as Attr objects. I'll convert the node list to an array of Attr objects, attributes, like this note that I first create the attributes array after finding the number of items in the NodeList object with the getLength method:
switch (type) { . . . case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attributes[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attributes[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } . . . You can find the methods of the Attr interface in Table 11.6.
| Method | Description |
|---|---|
| java.lang.String getName() | Gets the name of this attribute |
| Element getOwnerElement() | Gets the Element node to which this attribute is attached |
| boolean getSpecified() | Is true if this attribute was explicitly given a value in the original document. |
| java.lang.String getValue() | Gets the value of the attribute as a string |
Because the Attr interface is built on the Node interface, you can use either the getNodeName and getNodeValue methods to get the attribute's name and value, or the Attr methods getName and getValue methods. I'll use getNodeName and getNodeValue here. In this case, I'm going to loop over all the attributes in the attributes array, adding them to the current display line: AttrName = "AttrValue". (Note that I escape the quotation marks around the attribute values as \" so that Java doesn't interpret them as the end of the string.)
switch (type) { . . . case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attributes[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attributes[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } for (int loopIndex = 0; loopIndex < attributes.length; loopIndex++) { Attr attribute = attributes[loopIndex]; displayStrings[numberDisplayLines] += " "; displayStrings[numberDisplayLines] += attribute.getNodeName(); displayStrings[numberDisplayLines] += "=\""; displayStrings[numberDisplayLines] += attribute.getNodeValue(); displayStrings[numberDisplayLines] += "\""; } displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; . . . This element may have child elements, of course, and we have to handle them as well. I do that by storing all the child nodes in a NodeList object with the getChildNodes method. If there are any child nodes, I add four spaces to the indent string and loop over those child nodes, calling display to display each of them:
switch (type) { . . . case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attributes[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attributes[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } for (int loopIndex = 0; loopIndex < attributes.length; loopIndex++) { Attr attribute = attributes[loopIndex]; displayStrings[numberDisplayLines] += " "; displayStrings[numberDisplayLines] += attribute.getNodeName(); displayStrings[numberDisplayLines] += "=\""; displayStrings[numberDisplayLines] += attribute.getNodeValue(); displayStrings[numberDisplayLines] += "\""; } displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; NodeList childNodes = node.getChildNodes(); if (childNodes != null) { length = childNodes.getLength(); indent += " "; for (int loopIndex = 0; loopIndex < length; loopIndex++ ) { display(childNodes.item(loopIndex), indent); } } break; } . . . That's it for handling elements; I'll handle CDATA sections next.
Handling CDATA Section Nodes
Handling CDATA sections is particularly easy. All I have to do here is to enclose the value of the CDATA section's node inside "<![CDATA[" and "[[>":
case Node.CDATA_SECTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<![CDATA["; displayStrings[numberDisplayLines] += node.getNodeValue(); displayStrings[numberDisplayLines] += ""; numberDisplayLines++; break; } . . . Handling Text Nodes
The W3C DOM specifies that the text in elements must be stored in text nodes, and those nodes have the type Node.TEXT_NODE. For these nodes, I'll add the current indent string to the display string, and then I'll trim off leading and trailing whitespace from the node's value with the Java String object's trim method:
case Node.TEXT_NODE: { displayStrings[numberDisplayLines] = indent; String newText = node.getNodeValue().trim(); . . . The XML for Java parser treats all text as text nodes, including the spaces used for indenting elements in customer.xml. I'll filter out the text nodes corresponding to indentation spacing; if a text node contains only displayable text, however, I'll add that text to the strings in the displayStrings array:
case Node.TEXT_NODE: { displayStrings[numberDisplayLines] = indent; String newText = node.getNodeValue().trim(); if(newText.indexOf("\n") < 0 && newText.length() > 0) { displayStrings[numberDisplayLines] += newText; numberDisplayLines++; } break; } . . . Handling Processing Instruction Nodes
The W3C DOM also lets you handle processing instructions. Here, the node type is Node.PROCESSING_INSTRUCTION_NODE, and the node value is simply the processing instruction itself. For example, let's say that this is the processing instruction:
<?xml-stylesheet type="text/css" href="style.css"?>
Then this is the value of the associated processing instruction node:
xml-stylesheet type="text/css" href="style.css"
That means all we have to do is to straddle the value of a processing instruction node with <? and ?>. Here's what the code looks like:
case Node.PROCESSING_INSTRUCTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?"; String text = node.getNodeValue(); if (text != null && text.length() > 0) { displayStrings[numberDisplayLines] += text; } displayStrings[numberDisplayLines] += "?>"; numberDisplayLines++; break; } } . . . And that finishes the switch statement that handles the various types of nodes. There's only one more point to cover.
Closing Element Tags
Displaying element nodes takes a little more thought than displaying other types of nodes. In addition to displaying <, the name of the element, and >, you also must display a closing tag, </, the name of the element, and >, at the end of the element.
For that reason, I'll place some code after the switch statement to add closing tags to elements after all their children have been displayed. (Note that I'm also subtracting four spaces from the indent string, using the Java String substr method so that the closing tag lines up vertically with the opening tag.)
if (type == Node.ELEMENT_NODE) { displayStrings[numberDisplayLines] = indent.substring(0, indent.length() - 4); displayStrings[numberDisplayLines] += "</"; displayStrings[numberDisplayLines] += node.getNodeName(); displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; indent += " "; } } And that's it. I parse and display customer.xml like this after compiling IndentingParser.java in this case, I'll pipe the output through the more filter to stop it scrolling off the screen. (The more filter is available in MS-DOS and certain UNIX ports; it displays one screenful of information, and waits for you to type a key to display the next screenful.)
%java IndentingParser customer.xml | more
You can see the results in Figure 11.1. As you see in that figure, the program works as it should the document appears with all elements and text intact, indented properly. Congratulations now you're able to handle most of what you'll find in XML documents using the XML for Java packages.The complete listing for IndentingParser.java is in Listing 11.1. Note that you can use this program as a text-based browser: You can give it the name of any XML document on the Internet not just local documents to parse, and it'll fetch that document and parse it.
Figure 11.1. Parsing an XML document.
Listing 11.1 IndentingParser.java
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class IndentingParser { static String displayStrings[] = new String[1000]; static int numberDisplayLines = 0; public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); display(document, ""); } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { case Node.DOCUMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?xml version=\"1.0\" encoding=\""+ "UTF-8" + "\"?>"; numberDisplayLines++; display(((Document)node).getDocumentElement(), ""); break; } case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attributes[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attributes[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } for (int loopIndex = 0; loopIndex < attributes.length; loopIndex++) { Attr attribute = attributes[loopIndex]; displayStrings[numberDisplayLines] += " "; displayStrings[numberDisplayLines] += attribute.getNodeName(); displayStrings[numberDisplayLines] += "=\""; displayStrings[numberDisplayLines] += attribute.getNodeValue(); displayStrings[numberDisplayLines] += "\""; } displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; NodeList childNodes = node.getChildNodes(); if (childNodes != null) { length = childNodes.getLength(); indent += " "; for (int loopIndex = 0; loopIndex < length; loopIndex++ ) { display(childNodes.item(loopIndex), indent); } } break; } case Node.CDATA_SECTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<![CDATA["; displayStrings[numberDisplayLines] += node.getNodeValue(); displayStrings[numberDisplayLines] += ""; numberDisplayLines++; break; } case Node.TEXT_NODE: { displayStrings[numberDisplayLines] = indent; String newText = node.getNodeValue().trim(); if(newText.indexOf("\n") < 0 && newText.length() > 0) { displayStrings[numberDisplayLines] += newText; numberDisplayLines++; } break; } case Node.PROCESSING_INSTRUCTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?"; displayStrings[numberDisplayLines] += node.getNodeName(); String text = node.getNodeValue(); if (text != null && text.length() > 0) { displayStrings[numberDisplayLines] += text; } displayStrings[numberDisplayLines] += "?>"; numberDisplayLines++; break; } } if (type == Node.ELEMENT_NODE) { displayStrings[numberDisplayLines] = indent.substring(0, indent.length() - 4); displayStrings[numberDisplayLines] += "</"; displayStrings[numberDisplayLines] += node.getNodeName(); displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; indent += " "; } } public static void main(String args[]) { displayDocument(args[0]); for(int loopIndex = 0; loopIndex < numberDisplayLines; loopIndex++){ System.out.println(displayStrings[loopIndex]); } } } Filtering XML Documents
The previous example displayed the entire document, but you can be more selective than that through a process called filtering. When you filter a document, you extract only those elements that you're interested in.
Here's an example named searcher.java. In this case, I'll let the user specify what document to search and what element name to search for like this, which will display all <ITEM> elements in customer.xml:
%java searcher customer.xml ITEM
I'll start this program by creating a new class, FindElements, to make the programming a little easier. All I have to do is to pass the document to search and the element name to search for to the constructor of this new class:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class searcher { public static void main(String args[]) { FindElements findElements = new FindElements(args[0], args[1]); } } In the FindElements class constructor, I'll save the name of the element to search for in a string named searchFor and then call the displayDocument method as in the previous example to display the document. That method will fill the displayStrings array with the output strings, which we print:
class FindElements { static String displayStrings[] = new String[1000]; static int numberDisplayLines = 0; static String searchFor; public FindElements (String uri, String searchString) { searchFor = searchString; displayDocument(uri); for(int loopIndex = 0; loopIndex < numberDisplayLines; loopIndex++){ System.out.println(displayStrings[loopIndex]); } }s In the displayDocument method, we want to display only the elements with the name that's in the searchFor string. To find those elements, I use the getElementsByTagName method, which returns a node list of matching elements. I loop over all elements in that list, calling the display method to display each element and its children:
public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); NodeList nodeList = document.getElementsByTagName(searchFor); if (nodeList != null) { for (int loopIndex = 0; loopIndex < nodeList.getLength(); loopIndex++ ) { display(nodeList.item(loopIndex), ""); } } } catch (Exception e) { e.printStackTrace(System.err); } } The display method is the same as in the previous example.
That's all it takes; here I search customer.xml for all <ITEM> elements:
%java searcher customer.xml ITEM | more
You can see the results in Figure 11.2. The complete code for searcher.java is in Listing 11.2.
Figure 11.2. Filtering an XML document.
Listing 11.2 searcher.java
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class searcher { public static void main(String args[]) { FindElements findElements = new FindElements(args[0], args[1]); } } class FindElements { static String displayStrings[] = new String[1000]; static int numberDisplayLines = 0; static String searchFor; public FindElements (String uri, String searchString) { searchFor = searchString; displayDocument(uri); for(int loopIndex = 0; loopIndex < numberDisplayLines; loopIndex++){ System.out.println(displayStrings[loopIndex]); } } public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); NodeList nodeList = document.getElementsByTagName(searchFor); if (nodeList != null) { for (int loopIndex = 0; loopIndex < nodeList.getLength(); loopIndex++ ) { display(nodeList.item(loopIndex), ""); } } } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { case Node.DOCUMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?xml version=\"1.0\" encoding=\""+ "UTF-8" + "\"?>"; numberDisplayLines++; display(((Document)node).getDocumentElement(), ""); break; } case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attrs[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attrs[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } for (int loopIndex = 0; loopIndex < attrs.length; loopIndex++) { Attr attr = attrs[loopIndex]; displayStrings[numberDisplayLines] += " "; displayStrings[numberDisplayLines] += attr.getNodeName(); displayStrings[numberDisplayLines] += "=\""; displayStrings[numberDisplayLines] += attr.getNodeValue(); displayStrings[numberDisplayLines] += "\""; } displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; NodeList childNodes = node.getChildNodes(); if (childNodes != null) { length = childNodes.getLength(); indent += " "; for (int loopIndex = 0; loopIndex < length; loopIndex++ ) { display(childNodes.item(loopIndex), indent); } } break; } case Node.CDATA_SECTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<![CDATA["; displayStrings[numberDisplayLines] += node.getNodeValue(); displayStrings[numberDisplayLines] += ""; numberDisplayLines++; break; } case Node.TEXT_NODE: { displayStrings[numberDisplayLines] = indent; String newText = node.getNodeValue().trim(); if(newText.indexOf("\n") < 0 && newText.length() > 0) { displayStrings[numberDisplayLines] += newText; numberDisplayLines++; } break; } case Node.PROCESSING_INSTRUCTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?"; displayStrings[numberDisplayLines] += node.getNodeName(); String text = node.getNodeValue(); if (text != null && text.length() > 0) { displayStrings[numberDisplayLines] += text; } displayStrings[numberDisplayLines] += "?>"; numberDisplayLines++; break; } } if (type == Node.ELEMENT_NODE) { displayStrings[numberDisplayLines] = indent.substring(0, indent.length() - 4); displayStrings[numberDisplayLines] += "</"; displayStrings[numberDisplayLines] += node.getNodeName(); displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; indent+= " "; } } } The examples we've created so far have all created text-based output using the System.out.println method. However, few browsers these days work that way. In the next section, I'll take a look at creating a windowed browser.
Creating a Windowed Browser
Converting the code we've written to display a document in a window isn't difficult because that code was purposely written to store the output in an array of strings; I can display those strings in a Java window. In this example, I'll upgrade that code to a new program, browser.java, which will use XML for Java to display XML documents in a window.
Here's how it works; I start by parsing the document that the user wants to parse in the main method:
public static void main(String args[]) { displayDocument(args[0]); . . . Then I'll create a new window using the techniques we've seen in the previous chapter. Specifically, I'll create a new class named AppFrame, create an object of that class, and display it:
public static void main(String args[]) { displayDocument(args[0]); AppFrame f = new AppFrame(displayStrings, numberDisplayLines); f.setSize(300, 500); f.addWindowListener(new WindowAdapter() {public void windowClosing(WindowEvent e) {System.exit(0);}}); f.show(); } The AppFrame class is specially designed to display the output strings in the displayStrings array in a Java window. To do that, I pass that array and the number of lines to display to the AppFrame constructor, and store them in this new class:
class AppFrame extends Frame { String displayStrings[]; int numberDisplayLines; public AppFrame(String[] strings, int number) { displayStrings = strings; numberDisplayLines = number; } . . . All that's left is to display the strings in the displayStrings array. When you display text in a Java window, you're responsible for positioning that text as you want it. To display multiline text, we'll need to know the height of a line of text in the window, and you can find that with the Java FontMetrics class's getHeight method.
Here's how I display the output text in the AppFrame window. I create a new Java Font object using Courier font, and install it in the Graphics object passed to the paint method. Then I find the height of each line of plain text:
public void paint(Graphics g) { Font font = new Font("Courier", Font.PLAIN, 12); g.setFont(font); FontMetrics fontmetrics = getFontMetrics(getFont()); int y = fontmetrics.getHeight(); . . . Finally, I loop over all lines of text, using the Java Graphics object's drawString method:
public void paint(Graphics g) { Font font = new Font("Courier", Font.PLAIN, 12); g.setFont(font); FontMetrics fontmetrics = getFontMetrics(getFont()); int y = fontmetrics.getHeight(); for(int index = 0; index < numberDisplayLines; index++){ y += fontmetrics.getHeight(); g.drawString(displayStrings[index], 5, y); } } You can see the result in Figure 11.3. As you see in that figure, customer.xml is displayed in our windowed browser. The code for this example, browser.java, appears in Listing 11.3.
Figure 11.3. A graphical browser.

Listing 11.3 browser.java
import java.awt.*; import java.awt.event.*; import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class browser { static String displayStrings[] = new String[1000]; static int numberDisplayLines = 0; public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); display(document, ""); } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { case Node.DOCUMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?xml version=\"1.0\" encoding=\""+ "UTF-8" + "\"?>"; numberDisplayLines++; display(((Document)node).getDocumentElement(), ""); break; } case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attrs[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attrs[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } for (int loopIndex = 0; loopIndex < attrs.length; loopIndex++) { Attr attr = attrs[loopIndex]; displayStrings[numberDisplayLines] += " "; displayStrings[numberDisplayLines] += attr.getNodeName(); displayStrings[numberDisplayLines] += "=\""; displayStrings[numberDisplayLines] += attr.getNodeValue(); displayStrings[numberDisplayLines] += "\""; } displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; NodeList childNodes = node.getChildNodes(); if (childNodes != null) { length = childNodes.getLength(); indent += " "; for (int loopIndex = 0; loopIndex < length; loopIndex++ ) { display(childNodes.item(loopIndex), indent); } } break; } case Node.CDATA_SECTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<![CDATA["; displayStrings[numberDisplayLines] += node.getNodeValue(); displayStrings[numberDisplayLines] += ""; numberDisplayLines++; break; } case Node.TEXT_NODE: { displayStrings[numberDisplayLines] = indent; String newText = node.getNodeValue().trim(); if(newText.indexOf("\n") < 0 && newText.length() > 0) { displayStrings[numberDisplayLines] += newText; numberDisplayLines++; } break; } case Node.PROCESSING_INSTRUCTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?"; displayStrings[numberDisplayLines] += node.getNodeName(); String text = node.getNodeValue(); if (text != null && text.length() > 0) { displayStrings[numberDisplayLines] += text; } displayStrings[numberDisplayLines] += "?>"; numberDisplayLines++; break; } } if (type == Node.ELEMENT_NODE) { displayStrings[numberDisplayLines] = indent.substring(0, indent.length() - 4); displayStrings[numberDisplayLines] += "</"; displayStrings[numberDisplayLines] += node.getNodeName(); displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; indent+= " "; } } public static void main(String args[]) { displayDocument(args[0]); AppFrame f = new AppFrame(displayStrings, numberDisplayLines); f.setSize(300, 500); f.addWindowListener(new WindowAdapter() {public void windowClosing(WindowEvent e) {System.exit(0);}}); f.show(); } } class AppFrame extends Frame { String displayStrings[]; int numberDisplayLines; public AppFrame(String[] strings, int number) { displayStrings = strings; numberDisplayLines = number; } public void paint(Graphics g) { Font font = new Font("Courier", Font.PLAIN, 12); g.setFont(font); FontMetrics fontmetrics = getFontMetrics(getFont()); int y = fontmetrics.getHeight(); for(int index = 0; index < numberDisplayLines; index++){ y += fontmetrics.getHeight(); g.drawString(displayStrings[index], 5, y); } } } Now that we're parsing and displaying XML documents in windows, there's no reason to restrict ourselves to displaying the text form of an XML document. Take a look at the next topic.
Creating a Graphical Browser
In Java, text is just a form of graphics, so we've already been working with graphics. In this next example, I'll create a nontext browser that reads an XML document and uses it to draw graphics figures circles. Here's what a document this browser might read, circles.xml, looks like I'm specifying the (x, y) origin of the circle and the radius of the circle as attributes of the <CIRCLE> element:
<?xml version = "1.0" ?> <!DOCTYPE DOCUMENT [ <!ELEMENT DOCUMENT (CIRCLE|ELLIPSE)*> <!ELEMENT CIRCLE EMPTY> <!ELEMENT ELLIPSE EMPTY> <!ATTLIST CIRCLE X CDATA #IMPLIED Y CDATA #IMPLIED RADIUS CDATA #IMPLIED> <!ATTLIST ELLIPSE X CDATA #IMPLIED Y CDATA #IMPLIED WIDTH CDATA #IMPLIED HEIGHT CDATA #IMPLIED> ]> <DOCUMENT> <CIRCLE X='200' Y='160' RADIUS='50' /> <CIRCLE X='170' Y='100' RADIUS='15' /> <CIRCLE X='80' Y='200' RADIUS='45' /> <CIRCLE X='200' Y='140' RADIUS='35' /> <CIRCLE X='130' Y='240' RADIUS='25' /> <CIRCLE X='270' Y='300' RADIUS='45' /> <CIRCLE X='210' Y='240' RADIUS='25' /> <CIRCLE X='60' Y='160' RADIUS='35' /> <CIRCLE X='160' Y='260' RADIUS='55' /> </DOCUMENT>
I'll call this example circles.java. We'll need to decode the XML document and store the specification of each circle. To store that data, I'll create an array named x to hold the x coordinates of the circles, y to hold the y coordinates, and radius to hold the radii of the circles. I'll also store our current location in these arrays in an integer named numberFigures:
public class circles { static int numberFigures = 0; static int x[] = new int[100]; static int y[] = new int[100]; static int radius[] = new int[100]; . . . As we parse the document, I'll filter out elements and search for <CIRCLE> elements. When I find a <CIRCLE> element, I'll store its x, y, and radius values in the appropriate array. To check whether the current node is a <CIRCLE> element, I'll compare the node's name, which I get with the getNodeName method, to "CIRCLE" using the Java String method equals, which you must use with String objects instead of the == operator:
if (node.getNodeType() == Node.ELEMENT_NODE) { if (node.getNodeName().equals("CIRCLE")) { . . . } . . . To find the value of the X, Y, and RADIUS attributes, I'll use the getAttributes method to get a NamedNodeMap object representing all the attributes of this element. To get the value of specific attributes, I get the node corresponding to that attribute with the getNamedItem method. I get the attribute's actual value with getNodeValue like this, where I'm converting the attribute data from strings to integers using the Java Integer class's parseInt method:
if (node.getNodeType() == Node.ELEMENT_NODE) { if (node.getNodeName().equals("CIRCLE")) { NamedNodeMap attrs = node.getAttributes(); x[numberFigures] = Integer.parseInt((String)attrs.getNamedItem("X").getNodeValue()); y[numberFigures] = Integer.parseInt((String)attrs.getNamedItem("Y").getNodeValue()); radius[numberFigures] = Integer.parseInt((String)attrs.getNamedItem("RADIUS").getNodeValue()); numberFigures++; } . . . You can find the methods of the NamedNodeMap interface in Table 11.7.
| Method | Description |
|---|---|
| int getLength() | Returns the number of nodes in this map |
| Node getNamedItem(java.lang.String name) | Gets a node indicated by name |
| Node getNamedItemNS(java.lang.String namespaceURI, java.lang.String localName) | Gets a node indicated by a local name and namespace URI |
| Node item(int index) | Gets an item in the map by index |
| Node removeNamedItem (java.lang.String name) | Removes a node given by name |
| Node removeNamedItemNS(java.lang. String namespaceURI, java.lang.String localName) | Removes a node given by a local name and namespace URI |
| Node setNamedItem(Node arg) | Adds a node specified by its nodeName attribute |
| Node setNamedItemNS(Node arg) | Adds a node specified by its namespaceURI and localName |
After parsing the document, the required data is in the x, y, and radius arrays. All that's left is to display the corresponding circles, and I'll use the Java Graphics object's drawOval method to do that. This method draws ellipses and takes the (x, y) location of the figure's origin, as well as the minor and major axes' length. To draw circles, I'll set both those lengths to the radius value for the circle. It all looks like this in the AppFrame class, which is where we draw the browser's window:
class AppFrame extends Frame { int numberFigures; int[] xValues; int[] yValues; int[] radiusValues; public AppFrame(int number, int[] x, int[] y, int[] radius) { numberFigures = number; xValues = x; yValues = y; radiusValues = radius; } public void paint(Graphics g) { for(int loopIndex = 0; loopIndex < numberFigures; loopIndex++){ g.drawOval(xValues[loopIndex], yValues[loopIndex], radiusValues[loopIndex], radiusValues[loopIndex]); } } And that's all it takes; you can see the results in Figure 11.4, where the browser is displaying circles.xml. The complete listing appears in Listing 11.4.
Figure 11.4. Creating a graphical XML browser.
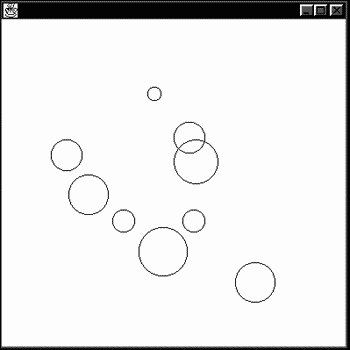
Listing 11.4 circles.java
import java.awt.*; import java.awt.event.*; import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class circles { static int numberFigures = 0; static int x[] = new int[100]; static int y[] = new int[100]; static int radius[] = new int[100]; public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); display(document); } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node) { if (node == null) { return; } int type = node.getNodeType(); if (node.getNodeType() == Node.DOCUMENT_NODE) { display(((Document)node).getDocumentElement()); } if (node.getNodeType() == Node.ELEMENT_NODE) { if (node.getNodeName().equals("CIRCLE")) { NamedNodeMap attrs = node.getAttributes(); x[numberFigures] = Integer.parseInt((String)attrs.getNamedItem("X").getNodeValue()); y[numberFigures] = Integer.parseInt((String)attrs.getNamedItem("Y").getNodeValue()); radius[numberFigures] = Integer.parseInt((String)attrs.getNamedItem("RADIUS").getNodeValue()); numberFigures++; } NodeList childNodes = node.getChildNodes(); if (childNodes != null) { int length = childNodes.getLength(); for (int loopIndex = 0; loopIndex < length; loopIndex++) { display(childNodes.item(loopIndex)); } } } } public static void main(String args[]) { displayDocument(args[0]); AppFrame f = new AppFrame(numberFigures, x, y, radius); f.setSize(400, 400); f.addWindowListener(new WindowAdapter() {public void windowClosing(WindowEvent e) {System.exit(0);}}); f.show(); } } class AppFrame extends Frame { int numberFigures; int[] xValues; int[] yValues; int[] radiusValues; public AppFrame(int number, int[] x, int[] y, int[] radius) { numberFigures = number; xValues = x; yValues = y; radiusValues = radius; } public void paint(Graphics g) { for(int loopIndex = 0; loopIndex < numberFigures; loopIndex++){ g.drawOval(xValues[loopIndex], yValues[loopIndex], radiusValues[loopIndex], radiusValues[loopIndex]); } } } Navigating in XML Documents
As you saw earlier in Table 11.4, the Node interface contains all the standard W3C DOM methods for navigating in a document that we've already used with JavaScript in Chapter 7, including getNextSibling, getPreviousSibling, getFirstChild, getLastChild, and getParent. You can put those methods to work here as easily as in Chapter 7; for example, here's the XML document that we navigated through in Chapter 7, meetings.xml:
<?xml version="1.0"?> <MEETINGS> <MEETING TYPE="informal"> <MEETING_TITLE>XML In The Real World</MEETING_TITLE> <MEETING_NUMBER>2079</MEETING_NUMBER> <SUBJECT>XML</SUBJECT> <DATE>6/1/2002</DATE> <PEOPLE> <PERSON ATTENDANCE="present"> <FIRST_NAME>Edward</FIRST_NAME> <LAST_NAME>Samson</LAST_NAME> </PERSON> <PERSON ATTENDANCE="absent"> <FIRST_NAME>Ernestine</FIRST_NAME> <LAST_NAME>Johnson</LAST_NAME> </PERSON> <PERSON ATTENDANCE="present"> <FIRST_NAME>Betty</FIRST_NAME> <LAST_NAME>Richardson</LAST_NAME> </PERSON> </PEOPLE> </MEETING> </MEETINGS>
In Chapter 7, we navigated through this document to display the third person's name, and I'll do the same here. The main difference between the XML for Java and the JavaScript implementations in this case is that the XML for Java implementation treats all text as text nodes including the spacing used to indent meetings.xml. This means that I can use essentially the same code to navigate through the document here that we used in Chapter 7, bearing in mind that we must step over the text nodes which only contain indentation text. Here's what that looks like in a program named nav.java:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class nav { public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); Document document = parser.getDocument(); display(document); } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node) { Node textNode; Node meetingsNode = ((Document)node).getDocumentElement(); textNode = meetingsNode.getFirstChild(); Node meetingNode = textNode.getNextSibling(); textNode = meetingNode.getLastChild(); Node peopleNode = textNode.getPreviousSibling(); textNode = peopleNode.getLastChild(); Node personNode = textNode.getPreviousSibling(); textNode = personNode.getFirstChild(); Node first_nameNode = textNode.getNextSibling(); textNode = first_nameNode.getNextSibling(); Node last_nameNode = textNode.getNextSibling(); System.out.println("Third name: " + first_nameNode.getFirstChild().getNodeValue() + ' ' + last_nameNode.getFirstChild().getNodeValue()); } public static void main(String args[]) { displayDocument("meetings.xml"); } } And here are the results of this program:
%java nav Third name: Betty Richardson
Ignoring Whitespace
You can eliminate the indentation spaces, called "ignorable" whitespace, if you want. In that case, you must provide the XML for Java parser some way of checking the grammar of your XML document so that it knows what kind of whitespace it may ignore, and you can do that by giving the document a DTD:
<?xml version="1.0"?> <!DOCTYPE MEETINGS [ <!ELEMENT MEETINGS (MEETING*)> <!ELEMENT MEETING (MEETING_TITLE,MEETING_NUMBER,SUBJECT,DATE,PEOPLE*)> <!ELEMENT MEETING_TITLE (#PCDATA)> <!ELEMENT MEETING_NUMBER (#PCDATA)> <!ELEMENT SUBJECT (#PCDATA)> <!ELEMENT DATE (#PCDATA)> <!ELEMENT FIRST_NAME (#PCDATA)> <!ELEMENT LAST_NAME (#PCDATA)> <!ELEMENT PEOPLE (PERSON*)> <!ELEMENT PERSON (FIRST_NAME,LAST_NAME)> <!ATTLIST MEETING TYPE CDATA #IMPLIED> <!ATTLIST PERSON ATTENDANCE CDATA #IMPLIED> ]> <MEETINGS> <MEETING TYPE="informal"> <MEETING_TITLE>XML In The Real World</MEETING_TITLE> <MEETING_NUMBER>2079</MEETING_NUMBER> <SUBJECT>XML</SUBJECT> <DATE>6/1/2002</DATE> <PEOPLE> <PERSON ATTENDANCE="present"> <FIRST_NAME>Edward</FIRST_NAME> <LAST_NAME>Samson</LAST_NAME> </PERSON> <PERSON ATTENDANCE="absent"> <FIRST_NAME>Ernestine</FIRST_NAME> <LAST_NAME>Johnson</LAST_NAME> </PERSON> <PERSON ATTENDANCE="present"> <FIRST_NAME>Betty</FIRST_NAME> <LAST_NAME>Richardson</LAST_NAME> </PERSON> </PEOPLE> </MEETING> </MEETINGS>
Now I call the parser method setIncludeIgnorableWhitespace with a value of false to turn off ignorable whitespace, and I don't have to worry about the indentation spaces showing up as text nodes, which makes the code considerably shorter:
import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; public class nav { public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.setIncludeIgnorableWhitespace(false); parser.parse(uri); Document document = parser.getDocument(); display(document); } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node) { Node meetingsNode = ((Document)node).getDocumentElement(); Node meetingNode = meetingsNode.getFirstChild(); Node peopleNode = meetingNode.getLastChild(); Node personNode = peopleNode.getLastChild(); Node first_nameNode = personNode.getFirstChild(); Node last_nameNode = first_nameNode.getNextSibling(); System.out.println("Third name: " + first_nameNode.getFirstChild().getNodeValue() + ' ' + last_nameNode.getFirstChild().getNodeValue()); } public static void main(String args[]) { displayDocument("meetings.xml"); } } Modifying XML Documents
As you saw earlier in Table 11.4, the Node interface contains a number of methods for modifying documents by adding or removing nodes. These methods include appendChild, insertBefore, removeChild, replaceChild, and so on. You can use these methods to modify XML documents on the fly.
If you do modify a document, however, you still have to write it out. (In Chapter 7, we couldn't do that using JavaScript in a browser, so I sent the whole document to an ASP script that echoed it back to be displayed in the browser.) The XML for Java packages do support an interface named Serializer that you can use to serialize (store) documents. However, that interface is not included in the standard JAR files that we've already downloaded in fact, it's easy enough to simply store the modified XML document ourselves because we print out that document anyway. Instead of using System.out.println to display the modified document on the console, I'll use a Java FileWriter object to write that document to disk.
In this example, I'll assume that all the people listed in customer.xml (you can see this document at the beginning of this chapter) are experienced XML programmers. In addition to the <FIRST_NAME> and <LAST_NAME> elements, I'll give each of them XML as a middle name by adding a <MIDDLE_NAME> element. Like <FIRST_NAME> and <LAST_NAME>, <MIDDLE_NAME> will be a child element of the <NAME> element:
<NAME> <LAST_NAME> Jones </LAST_NAME> <FIRST_NAME> Polly </FIRST_NAME> <MIDDLE_NAME> XML </MIDDLE_NAME> </NAME>
Adding a <MIDDLE_NAME> element to every <NAME> element is easy enough to do all I have to do is make sure that we're parsing the <NAME> element, and then use the createElement method to create a new element named <MIDDLE_NAME>:
case Node.ELEMENT_NODE: { if(node.getNodeName().equals("NAME")) { Element middleNameElement = document.createElement("MIDDLE_NAME"); . . . Because all text is stored in text nodes, I also create a new text node with the createTextNode method to hold the text XML:
case Node.ELEMENT_NODE: { if(node.getNodeName().equals("NAME")) { Element middleNameElement = document.createElement("MIDDLE_NAME"); Text textNode = document.createTextNode("XML"); . . . Now I can append the text node to the new element with appendChild:
case Node.ELEMENT_NODE: { if(node.getNodeName().equals("NAME")) { Element middleNameElement = document.createElement("MIDDLE_NAME"); Text textNode = document.createTextNode("XML"); middleNameElement.appendChild(textNode); . . . Finally, I append the new element to the <NAME> node, like this:
case Node.ELEMENT_NODE: { if(node.getNodeName().equals("NAME")) { Element middleNameElement = document.createElement("MIDDLE_NAME"); Text textNode = document.createTextNode("XML"); middleNameElement.appendChild(textNode); node.appendChild(middleNameElement); } . . . Using this code, I'm able to modify the document in memory. As before, the lines of this document are stored in the array displayStrings, and I can write that array out to a file called customer2.xml. To do that, I use the Java FileWriter class, which writes text stored as character arrays in files. To create those character arrays, I can use the Java String object's handy toCharArray method, like this:
public static void main(String args[]) { displayDocument(args[0]); try { FileWriter filewriter = new FileWriter("customer2.xml"); for(int loopIndex = 0; loopIndex < numberDisplayLines; loopIndex++){ filewriter.write(displayStrings[loopIndex].toCharArray()); filewriter.write('\n'); } filewriter.close(); } catch (Exception e) { e.printStackTrace(System.err); } } That's all there is to it; after running this code, this is the result, customer2.xml, complete with the new <MIDDLE_NAME> elements:
<?xml version="1.0" encoding="UTF-8"?> <DOCUMENT> <CUSTOMER> <NAME> <LAST_NAME> Smith </LAST_NAME> <FIRST_NAME> Sam </FIRST_NAME> <MIDDLE_NAME> XML </MIDDLE_NAME> </NAME> <DATE> October 15, 2001 </DATE> <ORDERS> <ITEM> <PRODUCT> Tomatoes </PRODUCT> <NUMBER> 8 </NUMBER> <PRICE> $1.25 </PRICE> </ITEM> <ITEM> <PRODUCT> Oranges </PRODUCT> <NUMBER> 24 </NUMBER> <PRICE> $4.98 </PRICE> </ITEM> </ORDERS> </CUSTOMER> <CUSTOMER> <NAME> <LAST_NAME> Jones </LAST_NAME> <FIRST_NAME> Polly </FIRST_NAME> <MIDDLE_NAME> XML </MIDDLE_NAME> </NAME> <DATE> October 20, 2001 </DATE> <ORDERS> <ITEM> <PRODUCT> Bread </PRODUCT> <NUMBER> 12 </NUMBER> <PRICE> $14.95 </PRICE> </ITEM> <ITEM> <PRODUCT> Apples </PRODUCT> <NUMBER> 6 </NUMBER> <PRICE> $1.50 </PRICE> </ITEM> </ORDERS> </CUSTOMER> <CUSTOMER> <NAME> <LAST_NAME> Weber </LAST_NAME> <FIRST_NAME> Bill </FIRST_NAME> <MIDDLE_NAME> XML </MIDDLE_NAME> </NAME> <DATE> October 25, 2001 </DATE> <ORDERS> <ITEM> <PRODUCT> Asparagus </PRODUCT> <NUMBER> 12 </NUMBER> <PRICE> $2.95 </PRICE> </ITEM> <ITEM> <PRODUCT id="5231" TYPE="3133"> Lettuce </PRODUCT> <NUMBER> 6 </NUMBER> <PRICE> $11.50 </PRICE> </ITEM> </ORDERS> </CUSTOMER> </DOCUMENT>
You can find the code for this example, XMLWriter.java, in Listing 11.5.
Listing 11.5 XMLWriter.java
import java.awt.*; import java.io.*; import java.awt.event.*; import org.w3c.dom.*; import org.apache.xerces.parsers.DOMParser; import org.apache.xerces.*; public class XMLWriter { static String displayStrings[] = new String[1000]; static int numberDisplayLines = 0; static Document document; static Node c; public static void displayDocument(String uri) { try { DOMParser parser = new DOMParser(); parser.parse(uri); document = parser.getDocument(); display(document, ""); } catch (Exception e) { e.printStackTrace(System.err); } } public static void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { case Node.DOCUMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?xml version=\"1.0\" encoding=\""+ "UTF-8" + "\"?>"; numberDisplayLines++; display(((Document)node).getDocumentElement(), ""); break; } case Node.ELEMENT_NODE: { if(node.getNodeName().equals("NAME")) { Element middleNameElement = document.createElement("MIDDLE_NAME"); Text textNode = document.createTextNode("XML"); middleNameElement.appendChild(textNode); node.appendChild(middleNameElement); } displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0; Attr attributes[] = new Attr[length]; for (int loopIndex = 0; loopIndex < length; loopIndex++) { attributes[loopIndex] = (Attr)node.getAttributes().item(loopIndex); } for (int loopIndex = 0; loopIndex < attributes.length; loopIndex++) { Attr attribute = attributes[loopIndex]; displayStrings[numberDisplayLines] += " "; displayStrings[numberDisplayLines] += attribute.getNodeName(); displayStrings[numberDisplayLines] += "=\""; displayStrings[numberDisplayLines] += attribute.getNodeValue(); displayStrings[numberDisplayLines] += "\""; } displayStrings[numberDisplayLines]+=">"; numberDisplayLines++; NodeList childNodes = node.getChildNodes(); if (childNodes != null) { length = childNodes.getLength(); indent += " "; for (int loopIndex = 0; loopIndex < length; loopIndex++ ) { display(childNodes.item(loopIndex), indent); } } break; } case Node.CDATA_SECTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<![CDATA["; displayStrings[numberDisplayLines] += node.getNodeValue(); displayStrings[numberDisplayLines] += ""; numberDisplayLines++; break; } case Node.TEXT_NODE: { displayStrings[numberDisplayLines] = indent; String newText = node.getNodeValue().trim(); if(newText.indexOf("\n") < 0 && newText.length() > 0) { displayStrings[numberDisplayLines] += newText; numberDisplayLines++; } break; } case Node.PROCESSING_INSTRUCTION_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?"; displayStrings[numberDisplayLines] += node.getNodeName(); String text = node.getNodeValue(); if (text != null && text.length() > 0) { displayStrings[numberDisplayLines] += text; } displayStrings[numberDisplayLines] += "?>"; numberDisplayLines++; break; } } if (type == Node.ELEMENT_NODE) { displayStrings[numberDisplayLines] = indent.substring(0, indent.length() - 4); displayStrings[numberDisplayLines] += "</"; displayStrings[numberDisplayLines] += node.getNodeName(); displayStrings[numberDisplayLines] += ">"; numberDisplayLines++; indent += " "; } } public static void main(String args[]) { displayDocument(args[0]); try { FileWriter filewriter = new FileWriter("customer2.xml"); for(int loopIndex = 0; loopIndex < numberDisplayLines; loopIndex++){ filewriter.write(displayStrings[loopIndex].toCharArray()); filewriter.write('\n'); } filewriter.close(); } catch (Exception e) { e.printStackTrace(System.err); } } } As you see, there's a lot of power in XML for Java. In fact, there's another way to do all this besides using the DOM. It's called SAX, and I'll take a look at it in the next chapter.
| CONTENTS |
EAN: 2147483647
Pages: 23