The Document Object Models: A History
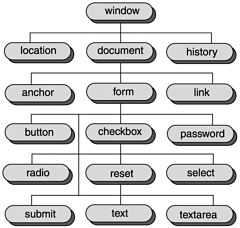
| The primary power of JavaScript is that it's a straightforward language that enables you to script the objects available to you in browsers, and much of this book is an exploration of those objects. All browsers have had different object models, and as you know, that presents a programming challenge in JavaScript. You can see a basic overview of the browser objects available to you in JavaScript in Figure 4.1; you can count on these objects being available in all scriptable browsers. Figure 4.1. The common DOM model. Beyond the basics you see in Figure 4.1, however, browsers diverge. You can see an overview of the various DOMs in various browsers in Table 4.1. I'll take a more in-depth look at each of these models next . Table 4.1. The DOM by Browser Version
The DOM 0The original DOM, which you see more or less entirely in Figure 4.1, was supported by Netscape Navigator 2.0. This was the first DOM and provided the early support to JavaScript of the browser objects. In fact, the DOM 0 introduced the browser objects that are familiar to us today: the window , document , navigator , and other objects. Using this DOM, you started to get access to the HTML elements in a web page. However, only the interactive elements of the web pagecontrols such as text fields, buttons , check boxes, links, and so onbecame accessible. The rest of the page was still static. DOM 0 was so successful that Internet Explorer 3.0 also implemented it virtually unchangeda short, peaceful interlude before the browser wars really started. Tip Two versions of Internet Explorer 3.0 appeared that were slightly different, which we're calling versions 3a and 3b, as discussed in Chapter 1, "Essential JavaScript." So if you're scripting for version 3.0, you should think about using object detection, coming up in this chapter, to be sure of the browser's capabilities. DOM 0+ImagesNot long after Internet Explorer 3.0 appeared, Netscape Navigator 3.0 was released. Actually, not that much had changed from a scripting perspective in Netscape Navigator 3.0; more properties, methods , and events had been added to some browser objects. However, one change was to have far-reaching consequences for JavaScript: The Image object appeared. The Image object itself was originally no great shakesit just supported properties for the various attributes of <IMG> elements, and those properties were all read-onlywith one exception:You could change the SRC attribute of the image at runtime. That meant you could swap the image displayed under script control, and that simple way of making web pages come alive has done a lot for JavaScript's reputation. When the mouse rolled over an image, that image could suddenly change; when the mouse left the image, it could be restored, and the result was that web pages looked a lot more active. This wasn't something you could do with a roundtrip to the serverthis had to be done in the browser itself, which meant using scripts. Unfortunately, Internet Explorer 3.0 didn't support this property, and the cross-browser issues we face today got started then. Programmers had to start adding code to check which browser they were working in to avoid errors, and they didn't like it. NS4 ExtensionsIn many ways, Netscape still had the upper hand in innovation in those days, and when Netscape Navigator 4.0 was released, that was truer than ever. This browser gave you more control over creating and sizing new browser windows (something that users viewing pop-up ads may regret even to this day). It also gave programmers new power in two particular areas: event handling and layers . Although event handling had existed before, Netscape Navigator 4.0 introduced more power and complexity by letting objects capture events. Keyboard and mouse events were added. In the Netscape Navigator, events started at the top of the object hierarchy and propagated downward to the actual cause of the eventfor example, if a button was clicked, the event would move down through the window , document , and so on objects to eventually reach the button. You could now use the window or document (or layer , coming up next) captureEvents method to capture those events and so centralize event handling instead of having to handle such events in the objects that created them. To stop capturing events, you used the releaseEvents method. Netscape Navigator 4.0 also introduced layers , a Netscape innovation that, although still supported, is no longer in widespread use. Layers let you "layer" your web page content, enabling you to move objects in different layers at runtime. Layers were supported with the <LAYER> element, and the document object got a new arraynow called a collection the document.layers array, which held all the layers in the document. Layers had various properties and methods that let you move them. Each layer had its own document object, and you could access elements in a layer in any of one of these three ways: document.layers[ n ].document. elementName document. layersName .document. elementName document.layers[ layersName ].document. elementName . Layers introduced a major incompatibility between the Netscape Navigator and Internet Explorerthe Internet Explorer still does not support layers, and in fact, most of what you could do with layers is now commonly done with style sheets. At the time, however, layers were quite an innovation, and eagerly received by the JavaScript community. We'll see more on layers in Chapter 16, "Dynamic HTML: Changing Web Pages On-the-Fly ." (Note that Netscape Navigator 6 no longer supports layers; their function has largely been taken over by style properties). IE4 ExtensionsNext came Internet Explorer 4.0, a major release for JavaScript programmers. The biggest change here was that all HTML elements could now be scripted, and all HTML elements now supported properties and methods available to JavaScript. This gave JavaScript programmers the most control over their web pages yet. To access the elements in a web page without having to specify all the intervening objects (for example, document.forms[0].textField1 ), Microsoft introduced the all collection, which is a collection of all contained HTML elements. For example, if an element had the ID or name (as set with its ID or NAME attribute) textField1 , you could then access that element as docu ment.all.textField1 . All you needed to know was an element's ID or name, and you had direct access to it. (See "Accessing HTML Elements" later in this chapter for the various ways to access elements using the all collection.) The all collection was one way to make your page entirely scriptable; another was to give all elements their own properties (such as tagName , parentElement , offsetLeft , and offsetTop ) and methods (such as scrollIntoView , setAttribute , and getAttribute ). We'll see which elements and methods are supported by which HTML element in detail in the next two chapters. Dynamic HTML also got a boost here, because Internet Explorer 4.0 introduced the innerText , outerText , innerHTML , outerHTML , insertAdjacentHTML , and insertAdjacentText properties and methods we'll see in Chapter 16; these enable you to change the content of individual HTML elements on-the-fly. Cascading Style Sheets also got their start here with the style property. Now you could access individual style properties like this: document.all. ID .style. styleProperty , as discussed in Chapter 21, "Cascading Style Sheets and CGI Programming." The Internet Explorer 4.0 also introduced a new event capture model: event bubbling . The Netscape Navigator event capture model had events moving downward from the topmost level, but the Internet Explorer has events moving upward, or "bubbling," from the object that caused the event up to the window object. And whereas Netscape event objects are passed to you in event handlers, Internet Explorer event objects are part of the window object. As we'll see in Chapter 6, "Using Core HTML Methods and Events," these conflicting event models are the cause of not a few headaches . (Note that these event models conflict when you start to capture eventsthey're still compatible at the basic level of adding a click event handler to a button using the ONCLICK event attribute.) In addition, you could now bind scripts to specific elements using the new FOR and EVENT attributes of the <SCRIPT> element; we've already seen these attributes at work in Chapter 1. Internet Explorer 4.0 also contained new features for Windows only, such as filters and transitions, which enable you to support impressive visual effects, as discussed in Chapter 16. All in all, Internet Explorer 4.0 was a huge new release for scripting programmers. However, there was more to come. IE5 ExtensionsMicrosoft introduced Internet Explorer 5 and then 5.5; from a scripting point of view, the big news was that these two browsers started to support the W3C DOM, although the support was only partialsee the next section to continue the W3C DOM story. The other big news in Internet Explorer 5 and 5.5 was Internet Explorer behaviors and HTML applications , which we'll meet in Chapter 17, "Dynamic HTML: Drag and Drop, Data Binding, and Behaviors." A behavior is a customized script you can save as an external file that can be applied to any HTML element and that has access to some powerful techniques, such as blurring or highlighting elements. HTML applications are XML-based applications that you can download and initialize automatically. TIP XML is Extensible Markup Language , and it's very much like HTML (which is Hypertext Markup Language ) except that you can define your own elements. You can see the XML specification at www.w3.org/TR/REC-xml. The idea with behaviors and HTML applications was that Microsoft wanted to start separating data from code, and to some extent this has been successful. However, the adoption of behaviors has been hampered by the fact that they're not easy to script, and they're supported only in the Internet Explorer. In fact, both browser corporations had for some time been realizing that the browser wars weren't doing much good for either browser, and they had already turned to W3C to standardize the DOM. Although the W3C DOM started to be implemented in Internet Explorer 5.0, it wasn't until version 6.0 of both browsers that we really made progress in this regard. Version 6 ExtensionsThe current crop of browsers is the version 6 generation. The big story here is that finally, the two browsers are working toward some level of shared support using the W3C DOM. Both the Netscape Navigator and Internet Explorer support the W3C DOM level 1as well as their own proprietary object models. So what is the W3C DOM? It's the object model meant to bring the browsers togetherand, of course, much of it is totally different from what we've already seen. For that reason, I'll take a look at it in some detail now. The W3C DOMThe current version of the W3C DOM is level 2, although the DOM level 3 is in the working draft stage. Here are the various DOM documents online, and a brief history of each:
There is also an unofficial W3C DOM level 0, which is the same as DOM 0, the original object model for browsers. This means that the basic object hierarchy you see in Figure 4.1 is supported in W3C DOMcompatible browsers. It's important to realize that the W3C DOM does not attempt to codify all that's in the browser object models nowfar from it. In fact, the first level W3C DOM didn't even have an event model. Layers are not part of the W3C DOM, and literally thousands of Internet Explorer objects, properties, methods, and events are left out. Also not supported: the all collection. Instead of using the all collection to address elements, you use a new method, getElementById . The Dynamic HTML properties innerHTML , outerHTML , innerText , and outerText are missing as well. Some properties that had been part of the document object ( alinkColor , bgColor , linkColor , and vlinkColor ) are part of the body object (which you access as document.body ). In fact, the W3C DOM is literally a document object modelit concerns itself only with the document object and the objects that are part of the document, such as the body object (although that may change in level 3). The window , navigator , and other such objects are not a significant part of the W3C DOM yet. In addition, the W3C DOM adheres to HTML 4.01 (www.w3.org/TR/html401), which introduces some new HTML-authoring practices if you want to use W3C DOM capabilities. The biggest issue here is that, like XML, each HTML element must have both an opening and a closing tag. Earlier, you didn't have to use closing tags with many elements (such as <P> , <IMG> , <LI> , and so on), but to adhere to the HTML 4.01 specification, you should include a closing tag for each element. Also, HTML attribute values are all supposed to be enclosed in quotation marks now (like this: <IMG SRC="image1.jpg"> ). In addition, several popular elements, such as <CENTER> , have been omitted from the HTML 4.01 specification. (In the case of <CENTER> , you can often use the style attributes of various elements instead, or use a <DIV> element and specify center justification in the <DIV> element's style propertiesmore on styles in Chapter 21.) Also, HTML 4.01, and the W3C DOM, emphasizes the ID attribute over the NAME attribute. (You can give an element both an ID and a name at the same time, because much server-side code still relies on names , not ID2s.) Therefore, to identify your HTML elements, you use the ID attribute in the W3C DOM, not the NAME attribute. Instead of accessing such elements with the all collection, in the W3C DOM, you use the getElementById method. If you have a paragraph, created with a <P> element named paragraph1 (that is, <P NAME="paragraph1"...> ), for example, you could reference it as document.all.paragraph1 using the all collection. However, now you use document.getElementById(paragraph1) , where you've given the paragraph the ID paragraph1 (that is, <P ID="paragraph1"...> ). The older way of accessing elements in a form, such as document.forms[0]. name or document. form1 . name , that we've already seen (and will see again in "Accessing HTML Elements" in this chapter) also still works. TIP Note that the getElementById method ends with a lower case d many people type in getElementByID and can't understand why that doesn't work. In fact, the whole way you think about an HTML document is different in the W3C DOM, and that bears some examination. W3C DOM NodesThe W3C DOM makes the elements available in both XML and HTML documents more accessible from scripts, but doing so introduces some more terminology for us. To define the structure of a web page, W3C introduces the concept of a node . For example, an HTML element is a node, the text content of an HTML element is a node, an element's attributes are all nodes, and so on. There are 12 node types defined for XML and HTML, but only 7 apply to HTML documents. You'll find them in Table 4.2. (All of these node types are supported in version 6.0 of the two browsers with which we're working.) Table 4.2. W3C DOM HTML Node Types
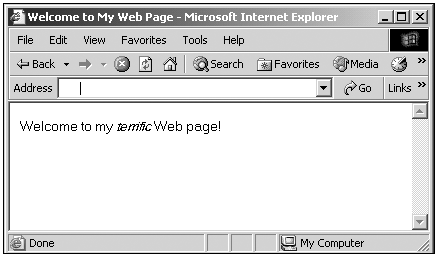
Tip To see all 12 XML and HTML node types, see Table 5.34. Here's an exampletake this short web page: <HTML> <HEAD> <TITLE> Welcome to My Web Page </TITLE> </HEAD> <BODY ID="body1"> <P ID="paragraph1"> Welcome to my <I> terrific </I> Web page! </P> </BODY> </HTML> You can see this web page in Figure 4.2. Figure 4.2. A short web page. Rather than a haphazard collection of elements, the W3C DOM sees this page as a hierarchy of element, attribute, and text nodes. In particular, starting from the document node, first comes the <HTML> element node, then the <HEAD> element node, the <TITLE> element node, which itself encloses a text node that contains the text "Welcome to My Web Page" , and so on. Here's the page's structure in node terms: document __<HTML> __<HEAD> __<TITLE> __"Welcome to My Web Page" __<BODY ID="body1"> __<P ID="paragraph1"> __"Welcome to my" __<I> __"terrific" __"Web page!" In fact, the situation is even a little more complex than this, because in the W3C DOM, even the whitespace (spaces and/or tabs) used to indent this HTML document is counted as a text node. That means that all whitespace between element tags (not between an element tag and any text content of the element, because that whitespace is merged with the text content of the element) is technically considered a text node. Here's what this document looks like in node form if you include the whitespace text nodes: document ___<HTML> __*whitespace text node* __<HEAD> __*whitespace text node* __<TITLE> __"Welcome to My Web Page" __*whitespace text node* __*whitespace text node* __<BODY ID="body1"> __*whitespace text node* __<P ID="paragraph1"> __"Welcome to my" __<I> __"terrific" __"Web page!" __*whitespace text node* To make matters more confusing, the Internet Explorer currently ignores these whitespace nodes, whereas the Netscape Navigator treats them as bona-fide text nodes. We'll see more on this issue in the section "Accessing HTML Elements with the W3C DOM," later in this chapter. W3C DOM Node Properties, Methods, and EventsTo work with nodes, the W3C DOM includes new properties, methods, and event-handling techniques. You can see some of the properties shared by all nodes in W3C DOM level 2 in Table 4.3, and shared methods in Table 4.4. (There are other properties and methods for specific nodes, as we'll see in the coming chapters.) Table 4.3. Common W3C DOM Level 2 Node Object Properties
Table 4.4. Common W3C DOM Level 2 Node Object Methods
You can use the nextSibling , lastChild , firstChild , parentNode , and so on properties to navigate through an entire document, treated as a node tree . We'll see how to do this in "Accessing HTML Elements with the W3C DOM" in this chapter. Note that all this is added to the other ways that browsers enable you to access HTML elementsas of yet, no old way of accessing elements has been removed from the browsers in favor of doing things the W3C DOM way. The W3C DOM also introduces a new way of handling events that we'll see in Chapter 6: using event listeners . Event listeners were introduced in Java earlier, and the W3C has followed that lead; a listener is an object that you can use to "listen" for particular types of events. For example, a click listener will listen for and handle click events. To make a listener listen for an event, you use the addEventListener method of a node that can handle events. Because you specifically tailor how the event is handled and what nodes to add listeners to, you can configure your own event-handling model, whether you want to follow the traditional Netscape top-down or the Internet Explorer bubble-up model, or create your own custom model. More on handling events this way in Chapter 6. By standardizing how you access elements in a web page, as well as the names of properties and method, the W3C DOM is intended to bring some sanity to the browser wars. However, it's an evolving standard, and currently, it covers only a relatively small part of the whole picture, focusing on the document objectand just a part of that object at that. That provides us with an overview of what's going on in the W3C DOM; the primary innovation so far has been the introduction of the node model and event listeners. We'll see more on the W3C DOM throughout the book, as we cover the various HTML elements that support the W3C DOM properties and methods, as well as the standard properties and methods. Now I'll turn back to the big picture, as we take a look at the various browser objects available to us in the browsers we're working withthe navigator , window , document , and other objects. I'll take a look at all of these objects in overview, because we'll be covering them all in depth in the upcoming chapters. |