The application server tier
|
| < Day Day Up > |
|
This section discusses clustering and maintenance scenarios for the application server tier. With the possibility of the need to keep session state, the application server tier offers new challenges compared to the Web tier. In discussing the application server tier, the terms stateless and stateful refer to whether the application server tier is used to store some or all user conversation state for interaction between transactions.
In designing the application server tier, consider keeping the application server tier stateless. The advantages of stateless over stateful are:
-
Better horizontal scalability
-
Higher availability in maintenance and failover scenarios
-
Overall ease of system management
Clustering the application server tier
This section describes several clustering scenarios. The techniques common to all scenarios are covered before the specific scenarios and techniques.
Techniques common to all scenarios
Like the Web server tier, configure the application server tier with at least two physical machines, or nodes. Each node runs at least one application server instance with the same installed application. With the minimal requirement of two nodes, each node must be capable of handling the site's peak load in the event of a failure of a node.
Pay special attention to the application server process. For Web sites with dynamic content, most of the processing required to respond to a Web request typically occurs in the application server. Consequently, this process has the greatest probability of a failure. Within the application server process, the execution of a transaction is handled mostly by the application code as opposed to application server code. Compared to the code in the operating system and the application server, the code in the application is typically the least tested and most prone to error, increasing the risk of failure. To mitigate the risk of failure, deploy two identical application server processes on each node. Deploying two redundant application server processes per node ensures the availability of the greatest capacity of the hardware in the event a process fails.
There are other benefits to having at least two server processes. Multiple processes ensure the highest availability during application upgrades. When the application server nodes are 4-way or greater, having multiple JVMs may provide higher throughput per node. This depends heavily on the nature of the application and the operating system.
Clustering using the Web server plug-in
This section discusses clustering using the functions available in the WebSphere Application Server, Version 5 Web server plug-in. Figure 3-3 depicts the typical deployment topology for a clustering scenario using the Web server plug-in. The plug-in provides weighted load balancing using a round robin or random request dispatching policy. The plug-in provides failover functionality through the detection of a failure in the application server process. The load balancing and failover functions for the application server tier are controlled through a plug-in XML file called plug-in-cfg.xml and located on the Web server nodes.
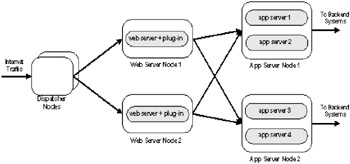
Figure 3-3: WebSphere plug-in as the load balancer for tier 2
Several elements and attributes of the plug-in file control failover and load balancing. Figure 3-4 shows an excerpt of the plug-in-cfg.xml file to refer to during this discussion.
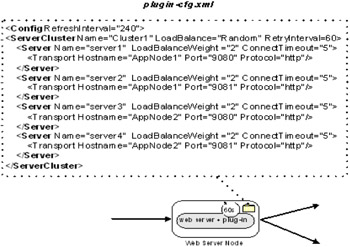
Figure 3-4: Plug-in-cfg.xml load balancing attributes
The ServerCluster element groups the redundant application processes as defined by the cluster and the cluster members in the system administration client. Each process, or cluster member, is represented by a Server element in the ServerCluster element. The attributes of the ServerCluster element that control load balancing and failover are LoadBalance and RetryInterval:
LoadBalance: Specifies the load balancing algorithm: can be either round-robin or random. The default algorithm is round-robin and works for most load balancing scenarios.
RetryInterval: Specifies the length of time that elapses from the time that a server process is marked down to the time that the plug-in retries a connection to that process. The default is 60 seconds.
The attributes of the server element that control load balancing and failover are ConnectTimeout and LoadBalanceWeight:
ConnectTimeout: Allows the plug-in to perform nonblocking connections with the application server by specifying a value in seconds, after which if there is no response to a connection request, the application server process is marked down. Nonblocking connections are beneficial when the plug-in is unable to contact the destination to determine if the port is available. A value between 5 and 10 should be reasonable for this attribute.
By default no ConnectTimeout value is specified, and in this case the plug-in performs a blocking connect during which time the plug-in waits until an operating system time-out. After the operating system time-out, which can be several minutes, the application server is then marked down. A value of 0 also causes the plug-in to perform a blocking connect.
LoadBalanceWeight: The weight associated with this server when the plug-in does weighted round robin load balancing. The value is set when adding a member, or duplicate application server instance, to a cluster using an administration client. The default value in the administration Web client is 2.
As the plug-in performs load balancing it selects a server and decrements the selected server's weight. When a server's weight reaches zero, no more requests are routed to that server until all servers in the cluster have a weight of zero. After all servers reach zero, the weights for all servers in the cluster are reset and the process repeats.
LoadBalanceWeight can be used to accommodate a mismatch in hardware capacity in the application server tier.
The elements and attributes of the plug-in XML file are set from an administration client, with some exceptions. When the plug-in file generation process is invoked, the file is placed in the WASROOT\config\cells directory by default. When the Web server is on a node that is physically separate from the application server, the file needs to be transferred from the deployment manager node to the Web node. See the section Sample scripts for an excerpt from a sample script for moving and modifying the file.
After the plug-in file is updated in place, the changes can take effect without restarting the Web server as the plug-in "refreshes" itself by rereading the plug-in XML file every sixty seconds by default. The refresh interval can be changed by manually modifying the RefreshInterval of the Config element.
The Web server plug-in can be used as a load balancer in these scenarios:
For both stateless and stateful application server tiers. For a stateless application server tier, a standalone load balancer between the Web and application tiers may provide easier system management. See Clustering using an external load balancer. Some load balancers also support stateful application server tiers using the active cookie affinity feature.
When the number of Web servers is four or less. Using scripts to update the plug-in file can become prone to human error when many Web servers are involved. One way to avoid this issue is to share the same file among the Web servers though a shared disk.
For dynamic content caching through the plug-in's support for edge side fragment caching.
When it is desired to use the IBM HTTP Server as the Web server for static content caching.
Clustering using an external load balancer
There are two alternatives to using the Web server plug-in for clustering. Both alternatives use the Edge components that ship with WebSphere Application Server Network Deployment, Version 5.
The first option uses the Dispatcher Edge component, as depicted in Figure 3-5. Essentially Dispatcher virtualizes the application server tier in the same way it can be used to virtualize the Web site as a single server or point of presence. The external load balancer distributes the load across at least two ports on each physical application server. This option can also work with load balancers such as F5's BigIP and Cisco's Content Service Switch (CSS) devices.
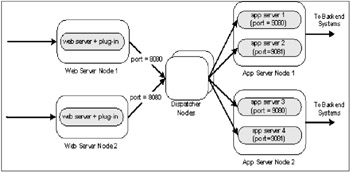
Figure 3-5: External load balancer for application server load balancing
Here are configuration options to consider for this scenario:
-
Configure Dispatcher to use the network address port translation (NAPT) capability due to multiple processes listening on unique ports for each node. For more information, refer to the Load Balancer Administration Guide at www.ibm.com/software/webservers/appserv/doc/v50/ec/infocenter/index.html.
-
For high-volume Web sites, consider gigabit Ethernet cards to prevent network bottlenecks at the dispatcher component.
-
Test to determine maximum capacity of not only the network interfaces but also the CPUs of the dispatcher nodes.
-
Set the ClusterAddress element of the plugin-cfg.xml file to the IP address of the cluster address of the load balancer. The ClusterAddress has the same attributes as the server element. The ClusterAddress differs in that you can only define one of them within a ServerCluster. This prevents the plug-in from performing load balancing.
The advantages of using an external load balancer for clustering are:
-
Modifying the configuration of the dispatcher machine can mark down individual instances of the application server. There is less chance of plug-ins being out of synchronization.
-
Scripts are not needed. Instead, use the administration GUI or simple commands to mark down the application servers.
-
More sophisticated load balancing algorithms are available than with the Web server plug-in.
-
In combination with stateless applications, an external load balancer provides the most scalable and manageable option of all the scenarios.
-
The external load balancer's monitoring facilities can be used to easily check the state (marked up or marked down) of an application server, as opposed to "looking" inside plug-in-cfg.xml files.
-
Fine grain load balancing using custom advisors is an option.
The disadvantage of an external load balancer is the difficulty of supporting stateful application server tiers. There are external load balancers from F5 and Cisco that support session affinity using a technique known as active cookie affinity. With active cookie affinity, the load balancer sets a cookie in the request before sending the request to a server. The cookie contains the name of the server that the load balancer selects. Subsequent requests that have this cookie indicate where the load balancer should send the request. Because inspecting cookies increases the load on the load balancer, this type of configuration should be thoroughly tested to determine the performance limits of the load balancer.
Clustering using the Dispatcher and CBR components
This section covers the second alternative to using the Web server plug-in for clustering. It uses three Edge components: Dispatcher, Content Based Routing (CBR), and Caching Proxy (Figure 3-6) and supports both stateful and stateless architectures.
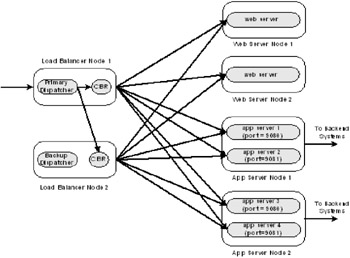
Figure 3-6: Clustering scenario using Dispatcher and Content Based Routing
CBR and the required Caching Proxy component (not shown) serve as the Web server tier in this architecture. CBR uses the plugin-cfg.xml configuration file in the same format as required by the Web server plug-in. With this capability, this configuration functions well for both stateful and stateless middle tiers. CBR provides several commands for managing the plug-in XML configuration file.
The primary advantage of this scenario over the Web server plug-in is ease of administration. For a stateless application, however, a kernel based load balancer may provide better performance.
Here are configuration options to consider for this scenario:
-
Configure Caching Proxy the same on all of the load-balancing servers. To improve the overall accessibility to the Web pages on the back-end servers, set up Caching Proxy to do memory caching.
-
Define the cluster address and ports to be the same in CBR and Dispatcher.
-
Configure CBR the same across all load-balancing servers.
-
Configure one load balancer as the primary high availability machine for one dispatcher component and the other as the standby.
Super scalable clustering scenarios
This section reviews some high level approaches for scaling a Web site by using additional load balancers with the scenarios covered in the previous sections. The overriding strategy presented here is to segment Web site traffic by using special purpose load balancers in multi-tiered configurations. The special purpose load balancer at each tier can be the same product but configured differently to suit the function required.
Figure 3-7 is an aggregation of various scenarios. The selected configuration is for discussing different techniques and it's not recommended that they be used together. The discussion follows the numbers shown in Figure 3-7. Each number represents a point in the logical network where load balancing can be used.
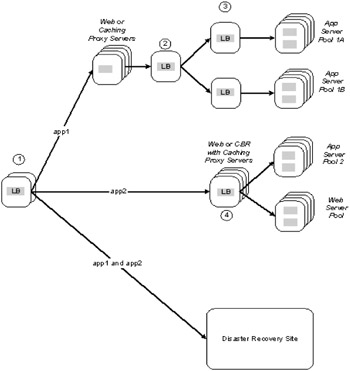
Figure 3-7: Multi-tier load balancing for scalability and availability
-
Several types of load balancing can be performed for multisite or content-based load balancing. For multisite load balancing, the load can be split based on client TCP/IP domain, or round robin for a stateless application. For content-based load balancing, the load can be logically split by function (URL). This means that http://hostname.mycompany.com/app1 goes to a different logical pool of servers than http://hostname.mycompany.com/app2. Dispatcher and Site Selector, working together with the ISP DNS, can provide this type of load balancing. Products from Cisco, F5, and Resonate also provide this function.
-
Load balancing provides a way to split the load for the same application, for example, app1, into two separate server pools. Typically app1 is an extremely high-volume application. Splitting the traffic may be necessary when load balancers at level 3 cannot handle the required throughput due to either network or CPU capacity. Another valid use is for major migrations of hardware, operating system, WebSphere, or application. The load balancing function at this level can be provided by a simple DNS round robin or by configuring Dispatcher in media access control (MAC) forwarding mode.
-
The load balancers provide the function described in the section Clustering using an external load balancer. Using multiple instances of this load balancer in combination with the load balancing at level 2 provides horizontal scalability and migration flexibility.
-
The load balancers are as described in the section Clustering using the Dispatcher and CBR components. The configuration using the WebSphere Application Server HTTP Server plug-in can also be substituted at this level.
Maintenance and failover scenarios
This section covers maintenance scenarios for achieving continuous availability. Sample scenarios highlight the WebSphere Application Server HTTP Server plug-in scenario and capability, but the same can be accomplished for the other scenarios and load balancers. The following scenarios are covered:
-
Adding a new application server process
-
Removing an application server in a stateful environment
-
Application upgrade and roll-back
-
Application server, network, and hardware failure
Sample scripts are provided in the section Sample scripts.
Adding a new application server process
The discussion applies to adding a new application server process, but can be extended to a node because the procedure doesn't care whether it is on an existing node or a new node.
To add an application server:
-
Add a Server element within the ServerCluster element of the plug-in XML file, either by regenerating the plug-in from an administration client, or by manually updating the XML file.
-
Redeploy the new plug-in XML file on the Web server nodes. The Web server plug-in refreshes its configuration from the file. When the configuration is refreshed the Web server starts distributing work to the new application server process.
This process can be automated using a script. See the sample script provided in the section Sample scripts.
Like most load balancers, Dispatcher and CBR have a feature to dynamically add a new application server instance to a cluster without restarting the load balancer.
Removing an application server in a stateful environment
One way to remove an application server process is to stop the application process using an administrative client or script. This causes the plug-in to fail to make a new connection to the process and, therefore, the plug-in marks the server down. Transactions in progress complete before the server stops. Simply stopping the process causes the plug-in to keep checking the server, which can increase response time.
A better approach to stopping an application server is to drain it:
-
Mark the application server instance down by setting the LoadBalanceWeight to 0 for the Web server plugin-cfg.xml file. The Web server plug-in stops load balancing to this server but continues to send users with existing sessions to the server.
-
Monitor the number of active sessions using IBM Tivoli® Performance Viewer, included with WebSphere, until all active sessions have ended.
-
Stop the application server.
A sample script is provided in the section Sample scripts.
The same can be accomplished with Dispatcher by using the command dscontrol manager quiesce.
This procedure can be useful when there is a need to perform hardware maintenance, for example replacing or upgrading CPU/memory. This procedure should be followed for each application process running on the node.
Application upgrade and rollback
In the experience of HVWS, application upgrade and rollback is the most frequent maintenance scenario. A generic scenario that can be customized as the environment and requirements vary is discussed. Note that if there is user session state either in the back end (tier 3) or in the browser, and the application server tier is stateless, care must be used when implementing this procedure. In this case the application must provide backward compatibility between releases as multiple requests from the same user could potentially fall across two releases of the application during the switch over. The alternative it to have a small window, say about one hour, for application upgrades when all users are forced off the system.
The process of deploying and restarting processes puts a load on the hardware. Therefore, to reduce risk of affecting response time, the procedure should be performed during off peak hours.
One advantage of this procedure is that it can be performed while maintaining most of the system capacity. To keep full capacity of the system, the recommended deployment architecture for the application server should resemble Figure 3-8.
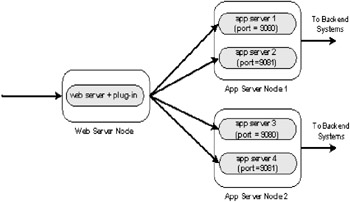
Figure 3-8: Detail configuration to support application upgrade and rollback
The configuration details are as follows:
-
The application is deployed on a cluster running on at least two application server nodes
-
There must be at least two cluster members defined on each application server node
-
The memory capacity of the application server nodes must be capable of supporting two concurrently running instances of the application and its server
The manual steps for rolling out the new application are as follows, but many can be automated based on the scripts provided in the section Sample scripts:
-
Mark the even numbered servers down
-
Stop the even numbered cluster members
-
Deploy the new application to the cluster
-
Deploy static content if necessary on the Web server tier (separate process for this)
-
Disable the old application on the cluster
-
Start the even numbered cluster members
-
Test the application by going through an optional staging Web server
-
Mark the odd numbered servers down and the even numbered servers up
-
Drain the users from odd numbered application servers (see sample script)
-
Restart the odd numbered application servers after they've been drained
-
Mark the odd numbered application servers up
If a roll back is necessary:
-
Enable the older version of the application
-
Disable the new version of the application
-
Mark the even numbered application servers down
-
Restart the even numbered application servers
-
Mark the even numbered application servers up and the odd numbered application servers down
-
Restart the odd numbered application servers
-
Mark the odd numbered application servers up
Application server, network, or hardware failure
If the plug-in fails to make a connection to an application server process, it marks the application server as unavailable and redirects the request to another application server in the cluster. The plug-in retries the unavailable server after the RetryInterval expires. The plug-in can fail to connect to the server due to a network, hardware, or process failure. For the CBR Edge component, the WLMServlet advisor should be used to provide server up or down status. A similar feature exists in most external HTTP load balancers.
|
| < Day Day Up > |
|
EAN: N/A
Pages: 117