| RSS is an acronym for Rich Site Summary (or, some will tell you, Really Simple Syndication). It is an XML-based technology for syndicating the content of news and blog Web sites. A program that is aware of RSS is called an aggregator. If you see a little orange XML icon in a Web page, it means that that content is available in an RSS feed. In this episode, we'll write an RSS aggregator. It will pull together many of the technologies we have discussed, including GUI apps, and introduce some advanced topics we haven't discussed, such as networking, Collections, and caching. Before we talk about what we'll write, let's figure out a bit more about RSS. RSS is an XML format that is largely concerned with defining titles, news items, content, images, descriptions, and other structural information that news articles conform to. There are many different versions of RSS. The first was .90, which was quickly obsolete. It was followed by version .91, wonderfully simple and straightforward to use, which makes it very popular for basic data. Version .92 allows for more metadata than previous versions. The common element between these versions of RSS is that they are each controlled by a single vendor (Netscape in the case of .90, and UserLand for the others). Version 1.0, however, is controlled by the RSS development working group . The current version is 2.0, and offers support for extensibility modules, a stable core , and active development. Note that this version is upwards compatible ”that is, any valid 91 source is also a valid 2.0 feed. The point in considering these different versions is that they are quite different indeed, and you are likely to encounter the many different versions on your travels . The application we write will allow you to create an XML file that defines the URLs of the RSS feeds you are interested in. Here is what version .91 looks like:
<?xml version="1.0" encoding="ISO-8859-1" ?> <rss version="0.91"> <channel> <title>WriteTheWeb</title> <link>http://writetheweb.com</link> <description>News for web users that write back</description> <language>en-us</language> <copyright>Copyright 2000, WriteTheWeb team. </copyright> <managingEditor>editor@writetheweb.com</managingEditor> <webMaster>webmaster@writetheweb.com</webMaster> <image> <title>WriteTheWeb</title> <url>http://writetheweb.com/images/mynetscape88.gif</url> <link>http://writetheweb.com</link> <width>88</width> <height>31</height> <description>News for web users that write back</description> </image> <item> <title>Giving the world a pluggable Gnutella</title> <link>http://writetheweb.com/read.php?item=24</link> <description>WorldOS is a framework on which to build programs that work like Freenet.</description> </item> </channel> </rss>
Here is a version of RSS 2.0:
<?xml version="1.0" ?> <! RSS generated by UserLand Frontier v9.0 on 11/30/2003; 7:13:00 PM Eastern > <rss version="2.0"> <channel> <title>Scripting News</title> <link>http://www.scripting.com/</link> <description>All scripting, all the time, forever.</ description> <language>en-us</language> <copyright>Copyright 1997-2003 Dave Winer</copyright> <pubDate>Sun, 30 Nov 2003 05:00:00 GMT</pubDate> <lastBuildDate>Mon, 01 Dec 2003 00:13:00 GMT</lastBuildDate> <docs>http://blogs.law.harvard.edu/tech/rss</docs> <generator>UserLand Frontier v9.0</generator> <managingEditor>dwiner@cyber.law.harvard.edu</ managingEditor> <webMaster>dwiner@cyber.law.harvard.edu</webMaster> <item> <description><img src="http://monster2.scripting.com/z/ images/archiveScriptingCom/2003/11/30/xmasTree.gif" width="44" height="66" border="0" align="right" hspace="15" vspace="5" alt="A picture named xmasTree.gif">Thanks to Vitamin C, <a href="http://www.herbs.org/greenpapers/ echinacea.html">echinacea</a> and lots of rest, my first cold of the winter appears to be over.</description> <pubDate>Mon, 01 Dec 2003 00:05:11 GMT</pubDate> <guid>http://archive.scripting.com/2003/11/ 30#When:7:05:11PM</guid> <category>/Boston/Weather</category> </item> </channel> </rss>
This version is obviously more verbose, but you see that the basic elements ”channel, item, image ”are intact. What is added is extra metadata, such as publication date, last build date, and so on. In our application, let's create an XML document that indicates the URLs of the RSS news feeds we want to view. Then, our Java app will display this list of links by reading in this XML document, and fetch the RSS data when we click on the link. However, because it is native XML, it is not very readable in this format, and wasn't meant to be viewed this way. So, we use a basic XSL stylesheet that accounts for many of the common RSS tags in order to transform the source into HTML. Our completed app will look like Figure 35.7 when we launch it.Click the URL on the left side. The app will open a network connection and retrieve the data at the other end, transform the data using the XSL stylesheet, and save the resulting HTML to a cache. Every subsequent time in this session that you click on that URL, the app retrieves the content from the cache. Figure 35.7. The RSS Aggregator app displays channels to choose from for news reading. 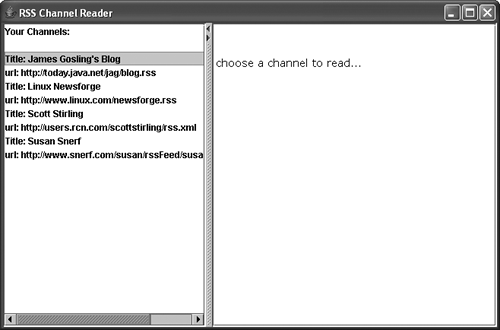
If the document contains a link, you can click on the link and the app will act as a browser, retrieve that content, and display it (see Figure 35.8). Note that to save space, the app does not check the version of the RSS document and do anything special based on that info , nor is the stylesheet anything more than rudimentary. For those reasons, most RSS feeds you throw at it should display, but they will likely display with varying degrees of beauty. Figure 35.8. Browsing to a complete entry in James Gosling's blog. 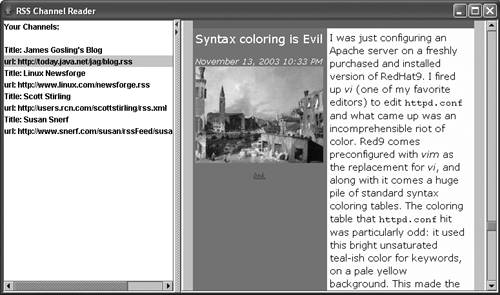
If you click on a title, your browser will clear. As mentioned earlier, clicking on the same title a second time in the same session retrieves data from the cache. The program's output to the standard out illustrates this:
F:\eclipse\workspace\garage\src\apps\rss\source\channels.xml File F:\eclipse\workspace\garage\src\apps\rss\source\cache\blog.rss not in cache F:\eclipse\workspace\garage\src\apps\rss\source\cache\blog.rss Getting file F:\eclipse\workspace\garage\src\apps\rss\source\cache\blog.rss from in cache
Let's look at the files that make up the application in order of appearance. First, NewsReader.java contains the main method. It starts the application by creating a new ReaderFrame and displaying it. NewsReader.java
package net.javagarage.apps.rss; /** * Starts the application by displaying the ReaderFrame. * @author eben hewitt * @see ReaderFrame */ public class NewsReader { public static void main(String[] args) { start(); } public static void start() { ReaderFrame frame = new ReaderFrame("RSS Channel Reader"); frame.pack(); frame.setVisible(true); } }
It's pretty straightforward. Because the main job of NewsReader.java is to create a ReaderFrame, let's take a look at his job. ReaderFrame.java
package net.javagarage.apps.rss; import java.awt.Dimension; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.MalformedURLException; import java.net.URL; import java.util.Map; import java.util.StringTokenizer; import java.util.Vector; import javax.swing.JEditorPane; import javax.swing.JFrame; import javax.swing.JLabel; import javax.swing.JList; import javax.swing.JScrollPane; import javax.swing.JSplitPane; import javax.swing.ListSelectionModel; import javax.swing.event.HyperlinkEvent; import javax.swing.event.HyperlinkListener; import javax.swing.event.ListSelectionEvent; import javax.swing.event.ListSelectionListener; /** * <p> * The frame that holds the content of the app. * It encapsulates the necessary JFrame code and * gathers the content. * Note in particular the getRSSData() method, which * demonstrates a pretty good use of caching. The * data is retrieved only when the user * requests it, and it is fresh the first time, but * subsequent reads of the same file in the same * session are read from the cache, * which stores the transformed result. * </p> * <p> * Created: Sep 12, 2003 4:38:09 PM * <p> * * @author HewittE * @since 1.2 * @version 1.0 * @see */ public class ReaderFrame extends JFrame implements ListSelectionListener, HyperlinkListener { private Vector imageNames; private JLabel channelLabel = new JLabel(); private JEditorPane contentPane; private JList list; private JSplitPane splitPane; private String root = RSSKeys.RESOURCE_ROOT; /** * Constructor. See inline comments * @param title The app name that appears in the * window's upper left corner. */ public ReaderFrame(String title) { super(title); initFrame(); //make the channel list list = new JList(getChannelList()); //allow display of only one item at a time list.setSelectionMode(ListSelectionModel. SINGLE_SELECTION); //select the first item in the list //when the app starts list.setSelectedIndex(2); list.addListSelectionListener(this); //to hold list of available channels JScrollPane listScrollPane = new JScrollPane(list); try { //create the right-hand side to show the transformed HTML contentPane = new JEditorPane("file:///" + RSSKeys.RESOURCE_ROOT + "start.html"); } catch (IOException ioe) { System.out.println(ioe.getMessage()); } //to hold the contents of selected channel contentPane.setEditable(false); contentPane.addHyperlinkListener(this); JScrollPane channelScrollPane = new JScrollPane(contentPane); //make a split pane with two scroll panes splitPane = new JSplitPane(JSplitPane.HORIZONTAL_SPLIT, listScrollPane, channelScrollPane); //allows the divider to be toggled on or off //with one click splitPane.setOneTouchExpandable(true); /*set minimum sizes for the two components in the split pane. */ Dimension minimumSize = new Dimension(300, 300); splitPane.setMinimumSize(minimumSize); //set preferred size for the split pane. splitPane.setPreferredSize(new Dimension(650, 400)); //set the divider at the end of the channel list pane splitPane.setDividerLocation(250); //put the content into the frame getContentPane().add(this.getSplitPane()); } /** * do typical things to set up the window * */ public void initFrame(){ setDefaultLookAndFeelDecorated(true); //shut down the app when the window is closed setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); //put window somewhere setLocation(300,300); } /** * This method is separate from the parseList in * order to help keep the implementation-specific * details to a minimum in how we populate the list. * That is, we need a Vector of Strings. * @return Vector The list of channels as * user-friendly text. */ public Vector getChannelList() { String channelList = XMLReader.transform(RSSKeys.LIST_XML, RSSKeys.LIST_XSL); return parseList(channelList); } /** * @param s * @return Vector The list items as parsed from the * channels.xml document */ protected static Vector parseList(String s) { //default size of list will be 6 Vector channels = new Vector(6); channels.add("Your Channels: "); StringTokenizer tokenizer = new StringTokenizer(s, "\n"); while (tokenizer.hasMoreTokens()) { String channelName = tokenizer.nextToken(); channels.addElement(channelName); } return channels; } /** * Gets the split pane that holds the two * JScroll panes * @return JSplitPane The main frame */ public JSplitPane getSplitPane() { return splitPane; } /** * We are implementing the ListSelectionListener, * which means that we promise to do something when * the user clicks an item in the list. * <br>What we do is either display a clever message * if the user has clicked a channel name instead of * a URL. In the lucky event that the user clicks * that channel's URL instead, we pass that string * into the getRSSData method in order to get the * viewable page back. */ public void valueChanged(ListSelectionEvent evt) { if (evt.getValueIsAdjusting()) return; //setup cache to hold transformed files Map cache = Cache.getInstance().getCache(); JList theList = (JList)evt.getSource(); String content = "No channel selected"; String rssSite = ""; if (theList.isSelectionEmpty()) { channelLabel.setText("Selection empty"); } else { rssSite = (String)theList.getSelectedValue(); if (rssSite.startsWith("url:")) { rssSite = rssSite.substring(4); contentPane.setText(getRSSData(rssSite)); } else { contentPane.setText("<code>"); } } channelLabel.revalidate(); } /** * The main workhorse of the app. Gets the url * passed in and gets its content from * the Internet the first time. * After that data has been read * once (per session) subsequent views are read * from the cache. * * @param rssSite The internet address of the XML * RSS feed that you want to read * @return The RSS transformed into HTML, which is * viewable in the JEditorPane * @see Cache */ public String getRSSData(String rssSite) { String data; String result = ""; try { URL url = new URL(rssSite); String xsl = RSSKeys.RSS_XSL; //Note that the cache is a singleton Map cache = Cache.getInstance().getCache(); BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream())); //get only the file name, without any of the path String fileName = url.getFile(); fileName = fileName.substring(fileName.lastIndexOf("/") + 1); String savedXML = RSSKeys.CACHE + fileName; if (cache.get(savedXML) == null) { System.out.println("File " + savedXML + " not in cache"); PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(savedXML, false))); //get data from URL while((data = in.readLine())!= null) { out.write(data); } out.close(); in.close(); //transform the file into HTML using XSL result = XMLReader.transform(savedXML, xsl); //cache the data cache.put(savedXML, result); } else { System.out.println("Getting file " + savedXML + " from in cache"); result = (String) cache.get(savedXML); } } catch (MalformedURLException mfe){ System.out.println(mfe.getMessage()); } catch (IOException ioe){ System.out.println(ioe.getMessage()); } return result; } /** * Receives a hyperlink event when user clicks on * a link that might be in one of the blog pages * and sets the page to that URL. */ public void hyperlinkUpdate(HyperlinkEvent e) { URL url=e.getURL(); if ((e.getEventType() == HyperlinkEvent.EventType.ACTIVATED) && (url.toString().startsWith("http"))) { try { contentPane.setPage(url); } catch (Exception ex) { System.out.println(ex.getMessage()); } } } }
As you can see, ReaderFrame does the main work of the application. It relies on a number of other documents. The first is channels.xml, and it is our own custom XML file that defines the names and locations of the channels that we want to view. Obviously, you can change these values to ones that suit you better. channels.xml
<?xml version="1.0"?> <channel-list> <channel> <title>James Gosling's Blog</title> <url>http://today.java.net/jag/blog.rss</url> </channel> <channel> <title>Linux Newsforge</title> <url>http://www.linux.com/newsforge.rss</url> </channel> <channel> <title>Scott Stirling</title> <url>http://users.rcn.com/scottstirling/rss.xml</url> </channel> <channel> <title>Susan Snerf</title> <url>http://www.snerf.com/susan/rssFeed/ susansnerfrss.xml</url> </channel> </channel-list>
This stylesheet is used to transform the contents of the channel list. channels.xsl
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/ Transform" version="1.0"> <xsl:output method="html" indent="yes"/> <xsl:strip-space elements="*"/> <xsl:template match="channel-list/channel/title"> Title: <xsl:apply-templates/> <xsl:value-of select="title"/> </xsl:template> <xsl:template match="channel-list/channel/url"> url: <xsl:apply-templates/><xsl:value-of select="url"/> </xsl:template> </xsl:stylesheet>
But how do we get the opening, default page? The JEditorPane reads in the start.html page, which looks like this. start.html
<html> <body> <br> <br> <font face="Verdana">choose a channel to read...</font> </body> </html>
The file RSSKeys.java contains nothing other than String constants used by the application. This is an easy way here to use declarative style programming, where we don't store data that the app relies on (but which is specific to the environment) inside the program. This way, it is easy to change these values. Note that you probably want to do this business in a Properties file. RSSKeys.java
package net.javagarage.apps.rss; /** * @author eben hewitt * Holds constants that different classes need. * Note the naming convention of all uppercase and * underscores in between words for constants. */ public class RSSKeys { public static final String RESOURCE_ROOT = "F:\eclipse\workspace\garage\src\apps\rss\ source\"; public static final String CACHE = RESOURCE_ROOT + "cache\"; public static final String LIST_XML = RESOURCE_ROOT + "channels.xml"; public static final String LIST_XSL = RESOURCE_ROOT + "channels.xsl"; public static final String RSS_XSL = RESOURCE_ROOT + "rssStyle.xsl"; }
Remember that on Windows, we need to escape the backslash character that is used as the file path separator. The next important file is the XMLReader.java class. Its job is to read in the specified document as an input stream and transform it using the stylesheet. The XML document URL comes from the event generated in the GUI list (which itself was generated from the XML channels file), and the XSL stylesheet location is in the RSSKeys class. XMLReader.java
package net.javagarage.apps.rss; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; import java.net.MalformedURLException; import java.net.URL; import javax.xml.transform.Templates; import javax.xml.transform.Transformer; import javax.xml.transform.stream.StreamSource; import javax.xml.transform.stream.StreamResult; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import java.io.StringWriter; /** * <p> * Reads XML documents and transforms them using XSLT. * </p> * @author eben hewitt * */ public class XMLReader { public static InputStream getDocumentAsInputStream(URL url) throws IOException { InputStream in = url.openStream(); return in; } public static InputStream getDocumentAsInputStream(String url) throws MalformedURLException, IOException { URL u = new URL(url); return getDocumentAsInputStream(u); } public static String transform(String xml, String xsl) { System.out.println(xml); TransformerFactory tfactory = TransformerFactory.newInstance(); try { // compile the stylesheet Templates templates = tfactory.newTemplates(new StreamSource(new FileInputStream(xsl))); StringWriter sos = new StringWriter(); StreamResult out = new StreamResult(sos); Transformer transformer = templates.newTransformer(); transformer.transform(new StreamSource(xml), out); sos.close(); String result = sos.toString(); return result; } catch (IOException ex) { System.out.println(ex.getMessage()); } catch (TransformerException ex) { System.out.println(ex.getMessage()); } return null; } }
Here is the XSL stylesheet used to transform the content read in from a channel into pretty HTML. rssStyle.xsl
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/ Transform" version="1.0"> <xsl:output method="html" indent="yes"/> <xsl:strip-space elements="*"/> <xsl:template match="rss"> <table border="1"> <xsl:apply-templates/> </table> </xsl:template> <xsl:template match="rss/channel"> <tr> <td> <a> <xsl:attribute name="href"> <xsl:value-of select="link"/> </xsl:attribute> <b> <xsl:value-of select="title"/> </b> </a> </td> </tr> <xsl:apply-templates/> </xsl:template> <xsl:template match="rss/channel/link"> </xsl:template> <xsl:template match="rss/channel/title"> </xsl:template> <xsl:template match="rss/channel/description"> </xsl:template> <xsl:template match="rss/channel/language"> </xsl:template> <xsl:template match="rss/channel/copyright"> </xsl:template> <xsl:template match="rss/channel/managingEditor"> </xsl:template> <xsl:template match="rss/channel/webMaster"> </xsl:template> <xsl:template match="rss/channel/image"> </xsl:template> <xsl:template match="rss/channel/item"> <tr> <td> <a> <xsl:attribute name="href"> <xsl:value-of select="link"/> </xsl:attribute> <b> <xsl:value-of select="title"/> </b> </a> </td> <td> <xsl:value-of select="description"/> </td> </tr> </xsl:template> </xsl:stylesheet>
The Cache class here holds the generated content from previous visits to URLs. This is a fairly common way to implement a cache, and has the added benefit of demonstrating the Singleton design pattern. Cache.java
package net.javagarage.apps.rss; import java.util.HashMap; import java.util.Map; /** * @author eben hewitt * Singleton. Which means there can only be one * instance of this class per JVM. * * Holds a HashMap collection, which * allows easy retrieval of object values based on a * key name. So we can pass in the URL string of a * file name along with the content of the * file, and get the file out later. The obvious * benefit is speed, also, singleton is a pretty * importantpattern and one that is used frequently * in a manner similar to this. */ public class Cache { private Map cache = new HashMap(); private static Cache instance = new Cache(); private Cache() {} protected Map getCache() { return cache; } protected static Cache getInstance() { return instance; } }
|