The Unified Modeling Language (UML)
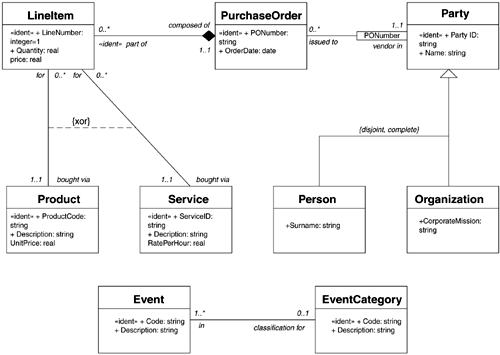
The Unified Modeling Language (UML) The Unified Modeling Language (UML) is not billed as a "data-modeling" but as an "object-modeling" technique. Instead of entity types, it models "object classes". Close examination of its models, however, shows these to look suspiciously like entity/relationship models. Indeed, Ivar Jacobson even calls these classes in a business-oriented model entity type objects [Jacobson, 1992, p. 132]. Because of a confluence of ideas, techniques, personalities, and politics, UML promises to become a standard notation for representing the structure of data in the object-oriented community. It was developed when the "three amigos" of the object-oriented world, James Rumbaugh, Grady Booch, and Ivar Jacobson, among others, agreed to adopt as standard a variation on a notation originally developed by David Embley and his colleagues [Embley et al., 1992]. The UML was published by the Object Management Group in 1997 [OMG, 1998]. Messrs. Rumbaugh, Jacobson, and Booch have written significant texts on UML: a reference manual [Rumbaugh, Jacobson, & Booch, 1999], a user guide [Booch, Rumbaugh, & Jacobson, 1999], and a guide to their methodology [Jacobson, Booch, & Rumbaugh, 1999], although many other books on the subject are also available. As a system of notation for representing the structure of data, when used for analysis, the UML static diagram is functionally the exact equivalent of any other data-modeling, entity-type/relationship modeling, or object-modeling technique. Its classes of entity-type objects are really entity types, and its associations are relationships. It has specialized symbols for some things that are already represented by the main symbols in other notations, and it lacks some symbols used in e/r diagrams. It does, however, have a more extensive ability to describe interrelationship constraints. Yes, the UML does add the ability to describe the behavior of each object class/entity type, but the data-structure part of the technique is fundamentally no different from any other data-modeling technique in what it can represent. It also adds notation details most useful when it is applied to object-oriented design. In addition, the UML includes other kinds of diagrams besides static object diagrams. These include use cases, activity diagrams, and others. They do not concern us here, however. Figure B.8 shows the UML version of our example. Figure B.8. A UML Model. Entity Types (Object Classes) and AttributesAs stated above, in object models, entity types are called classes. A class in the UML static model is a square-cornered rectangle with three divisions. The top part contains the class name . The middle section contains a list of attributes. The bottom, if included, contains descriptions of behavior. Since the UML is used mostly for design, these behavior descriptions are usually in the form of pseudo-code, C++, or simply program names , or simply references to programs. An attribute can be referred to by one or more of the following elements:
There are no spaces between the words in names. The class is called PurchaseOrder instead of Purchase Order. The UML introduces the concept of stereotype , which is an additional annotation that can be used to enhance the standard UML notation. If you don't like something about UML, you can change it! A stereotype is identified by being surrounded by guillimets (), and can be used to extend entity type, attribute, and association definitions. In Figure B.8, the stereotype ident extends the model to denote unique identifiers. (See "Unique Identifiers" on page 375, below.) Relationships (Associations)A relationship is called an "association" in the object-oriented world. Rather than using graphic symbols, all the information on a UML association is conveyed by characters . Cardinality/OptionalityBoth cardinality and optionality are conveyed by characters in the form: <lower limit> .. <upper limit> where the <lower limit> denotes the optionality (nearly always 0 or 1, although conceivably it could be something else), and the <upper limit> denotes the cardinality. The <upper limit> may be an asterisk (*) for the generic "more than one", or it may be an explicit number, a set of numbers , or a range. For example, "0..*" means "may be one or more" (zero, one, or more), and "1..1" means "must be exactly one". Since they are most common, "0..*" may be abbreviated "*", and "1..1" may be abbreviated "1". In Figure B.8, for example, the fact that each Party may be a vendor in one or more purchase orders is shown by the string "0..*" next to Purchase Order. The "0" makes it optional ("may be"), and the * means that it can be any number. Similarly, the fact that each Purchase Order must be to one and only one Party is shown by the string "1..1" next to Party. The first 1 means that the relationship is mandatory ("must be"), and the second means that the purchase order may be to no more than one Party. NamesThere are two primary ways to name associations. A simple verb phrase may name the association in its entirety. A triangle next to the name tells which way to read it. Alternatively, "roles" can be defined at each end to describe the part played by the class in the association. The concept of role is very close to the relationship names used in the Barker notation, so that convention could be applied here, as was done in Figure B.8. "Part of/ composed of"Extra symbols represent the particular association where each object in one class is composed of one or more objects in the other class. (Each object in the second class must be part of one and only one object in the first class.) The association acquires a diamond symbol next to the parent ("composed of") class. If the association is mandatory and the referential integrity rule is "cascade delete"that is, deletion of the parent deletes all the childrenthis is called "composition" and the diamond is solid. This is shown for the PurchaseOrder/LineItem association in Figure B.8. If the association is optional to the parent (and therefore has the referential integrity rule "nullify delete")that is, a parent can be deleted without affecting the childrenthen the diamond is open and is called "aggregation". The notation does not address the "restricted" rule, in which deletion of a parent is not permitted if children exist. Nor does it address referential integrity rules for any other kind of association. Unique IdentifiersUnique identifiers are rarely referred to in the object-oriented world. When the behavior of objects in a class requires locating a particular occurrence of another class, however, the attribute used for locating that occurrence is shown in a box next to the entity type needing it. For example, in Figure B.8, "PO number" is required from the point of view of Party to locate a particular Purchase Order. This reflects the programming that will be required to navigate from Party to Purchase Order when the classes are implemented, but it is not meaningful in an analysis model. Alternatively, stereotypes can be used to designate attributes and relationships that constitute unique identifiers, in a structure very similar to that of the Barker notation. These are shown as ident in Figure B.8. Sub-typesThe UML shows sub-types as separate entity-type boxes, each removed from its super-type and connected to it by an "isa" relationship. (Each occurrence of a sub-type "is a[n]" occurrence of the super-type.) Note in Figure B.8 that the sub-type structure is labeled { disjoint , complete}. This is equivalent to the rule in other notations that each occurrence of the super-type must be a member of one of the sub-types ( complete ), and an occurrence may not be a member of more than one sub-type ( disjoint ). In UML, this constraint is not required. The sub-type structure could be { overlapping, incomplete } or any other permutations of the two. Constraints between RelationshipsConstraints between relationships are shown as dashed lines between pairs of associations. Such a line is called a constraint . If it is annotated {xor} or simply {or}, it is an exclusive or . In Figure B.8, a constraint says that each occurrence of LineItem must be (or may be) either for an occurrence of Product or for an occurrence of Service, but not both . If it were {ior}, however, it would be an inclusive or . (Each occurrence of the base entity type must be (or may be) related to either an occurrence of one entity type, or to an occurrence of the other, or both .) Indeed, the dashed line can represent any relationship desired between two associations. CommentsUML has a number of advantages over its predecessors:
These are valuable concepts. The first three could easily be added to other notations, with good effect. The fourth cannot, but it is rare that such a construct is needed, so its omission in other notations is not a serious practical problem. Such specific upper limits tend to be derived from business rules that might change, so it is not a good idea to include them in a conceptual data model. In the fifth case, the requirement that sub-types be complete and disjoint turns out to be a very useful discipline that produces much more rigorous models than if the restriction were relaxed . The final case describes a point which is controversial even in the object-oriented world. In your author's experience, nearly all examples that appear to require multiple-inheritance or multiple-type hierarchies can be solved by attacking the model from a different direction. All of these may be valuable, however, if the model is being used to support design. Other aspects of UML, however, are problematic if the models are to be presented to the public for requirements analysis. First of all, in UML, cardinality and optionality are represented by numbers instead of graphic symbols. Yes, this has the advantage of permitting any kind of cardinality, such as 1, 46, 7, but requirements for such a statement are rare. It has the disadvantage , however, of making it an intellectual exercise to decode the symbolsinstead of a visual processing one. You no longer "see" the relationship. You must "understand" it. The left side of the brain is used instead of the right. With information engineering or with Mr. Barker's notation, the entire process of decoding how many participants there are in a relationship is a visual oneand this makes the models much easier to read for those untutored in the notation. The shorthand of using an asterisk for "may be one or more" and a one for "must be one and only one" in one sense simplifies the UML model, since these are the most common cardinalities and optionalities. On the other hand, it destroys the systematic semantic structure in which you automatically know both the upper and lower limits. Second, the UML has added unnecessary symbols for specific kinds of relationships. The concepts of composition and aggregation are handled in entity-type/relationship diagrams by simply labeling a relationship part of and composed of . Having special symbols for two of the many possible kinds of relationships unnecessarily complicates the model. More significantly, these additional symbols are incomplete. They represent the cascade delete and nullify delete rules for "composed of/part of" relationships, but what about the restricted delete rule? (You may not delete the parent at all if children exist.) And what about showing these rules for other relationships? Adding "C", "R", or "N" to an e/r diagram uniformly describes whether deletion of the parent is permitted and whether it calls for deletion of the childrenregardless of the relationship. In addition, Entity-Type Life Histories more completely describe how entity-type occurrences may be created and under what circumstances they can be deleted (see Chapter 7, pages 262282). The justification for these symbols turns out to be that there are physical design implications for the aggregation and composition concepts. In an object-oriented implementation, it is possible for one object to be physically inside another object. Showing the diamonds on a UML design model provides information to the programmers. This is, however, both distracting and unnecessary in the conceptual model used for requirements analysis. As stated previously, while it does permit showing multiple-inheritance and multiple-type hierarchies, the multi-box approach to sub-types takes up a lot of room on the drawing, limiting the number of other entity types that can be placed on it. Moreover, it does not clearly convey the fact that an occurrence of a sub-type is an occurrence of a super-type. There are two other shortcomings of the UML, but these can be addressed, either through the use of stereotypes or by imposing discipline on the way the UML is used. In the first case, the UML could be significantly improved by increased discipline in the use of relationship names. Most commonly a relationship name in the UML is a single verb that describes it in one direction. Were this the only option, it would be unacceptable. It is, however, possible to add "roles" to each end of the relationship. This provides the ability to portray how an entity type is viewed from the perspective of another entity type. Given this structure, it would be valuable if these role names were constrained to follow the Barker naming convention. Second, the UML deals only partially with unique identifiers. The philosophy behind object orientation is that it isn't necessary explicitly to show unique identifiers. But then it turns out that, from the point of view of a parent entity type, it is often necessary to identify occurrences of a child entity type. So "qualified associations" allow this to be expressed . But you are allowed to identify an occurrence only to a parent entity type. You are not allowed to identify it to the world at large. This means that, instead of a simple symbol attached to a relationship or attribute to indicate a unique identifier universally , you have to add a whole new box whose meaning is constrained and confusing at best. [3]
Note that this can be addressed using stereotypes as described above. In Figure B.8, "ident" was added to several attributes and a relationship to show their participation in unique identifiers. This doesn't mean that the UML shouldn't be used for the physical design model. To the contrary, the additional expressiveness described here makes it eminently suitable for that purpose. (And designers are not the least bit bothered by the aesthetic objections raised above.) But the UML is fundamentally thata design tool. |

| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 129