RMAN and RAC
|
| < Day Day Up > |
|
RMAN is an excellent partner for any RAC environment, regardless of the RAC configuration. If you use raw partitions, RMAN is an excellent choice for the backup, as there are no tricky offsets for the dd command, and no chance of error. RMAN accesses the datafiles on the raw partitions via the Oracle memory buffer, so every block is read correctly and written correctly. If you use the Oracle Cluster File System (OCFS), RMAN is just as adept at backing up the datafiles.
RMAN certainly simplifies the backup and recovery strategies in any environment, even RAC. That being said, it is worth noting some unique backup and recovery challenges of the cluster database.
RMAN Configuration for the Cluster
There are configuration decisions that must be made prior to implementing an RMAN backup strategy for the RAC database. These decisions are predicated on how the backup will proceed, and then how the recovery will proceed.
RMAN makes an Oracle Net Service connection to a node in the database. This connection must be a dedicated connection that is not configured for failover or load balancing across the cluster. In other words, RMAN does not connect to the cluster-it connects to one node in the cluster. All RMAN server processes related to job building, controlfile access, and controlfile updates will reside at the node of connection. However, when you allocate channels for a backup job to occur, you can allocate channels at each node in the cluster by specifying a connect string in the channel allocation command.
allocate channel x1 type sbt connect sys/password@node1; allocate channel x2 type sbt connect sys/password@node2;
And so on. In this way, you can distribute the workload of a backup operation across the nodes of the cluster. The decision to put a single node in charge of backup operations, or to share the work across all (or some) nodes, is an architectural decision you must make based on how you use the nodes in your cluster. It might make sense in some environments to restrict backup overhead to a less-used node in the cluster; likewise, if you have a well-tuned load-balancing technique for all nodes, distributing the backup workload evenly might make the most sense. We discuss the consequences further, as it pertains to datafile and archivelog backups, later in this chapter.
The Snapshot Controlfile in RAC Environments
You will need to move the snapshot controlfile to a shared location, if you plan on running backups from more than one node. If you do not move the snapshot to a shared file system like OCFS, then you must make sure that the local destination is identical on all nodes. To see the snapshot controlfile location, you can use the show command:
rman> show snapshot controlfile name;
To change the value, use the configure command.
rman> configure snapshot controlfile name to '/u02/oradata/grid10/snap_grid10.scf';
Datafile Backup
Datafiles can be backed up from any node in the cluster, as they are shared between instances anyway. So, you can run a datafile backup from any node, or from all nodes, and not run into any problems.
If you are backing up to tape, you must configure your third-party SBT interface at each node that will have channels allocated for backup. If you only back up from a single node, then only that node will have to be configured with the media management layer. But if you allocate channels across all nodes, the media management layer must be configured at each node.
If you are backing up to disk without using a flashback recovery area, you would most likely want to configure a shared disk location on which to write your backups, so that if a node is lost, the backups taken at any node will be available to any other node. You could do this through NFS mounts, if you do not use OCFS.
Archivelog Backup
Archivelog backup strategies are where it gets a little sticky. This is because every node generates its own thread of archivelogs, which typically pile up on the local disks of each node. Because RMAN connects to only one node, but reads a shared controlfile that lists all archivelogs, RMAN will fail when it tries to back up archivelogs that exist on unreachable disks of other nodes.
RMAN-6089: archived log <name> not found or out of sync with catalog
Chapter 4 provided an overview of configuring archivelogs for the RAC cluster. Depending on which solution you chose, the backup of those archivelogs will differ.
Archivelogs Going to Shared OCFS Volume This is, by far, the simplest and most elegant solution for archivelogs in a RAC/Linux environment. If you archive logs from all nodes to a shared volume running Oracle Clustered File System, you can connect to any node in your cluster and be able to back up archivelogs that are produced by every node. If you use this methodology, the RMAN backup command is simple, and you can allocate a channel at each node to perform archivelog backups (for load sharing only), or you can use a single node.
backup archivelog all delete input;
The delete input command means that after RMAN backs up the archivelogs, it will delete those files that it just backed up. See more in the 'Archivelog Housekeeping with RMAN' section below for archivelog maintenance.
Archivelogs Available via NFS Mounts If you have set up a configuration that archives logs from each node to every other node, you still should be able to back up the archivelogs from any node. Using this methodology, you can run your backup with channels allocated all at a single node, or you can spread the load out across all nodes for load balancing.
If you use NFS to archive logs from every node to a single repository node, the repository node must serve as the node to which RMAN connects for backups. In such an environment, you would need to allocate all the channels for archivelog backup at the same repository node for the channel processes to have access to all the archivelogs required for backup.
Archivelogs to Local Disks Only If you choose to stay in the stone age of clustering, and continue to produce archivelogs for each thread only at the local node level, you will be required to allocate backup channels at each node in order to perform an archivelog backup. This is not that big of a deal, really, except that there are significant consequences during recovery. We talk about that in the recovery section coming up.
Archivelog Housekeeping with RMAN The archivelog backup command will check v$archived_log for all archivelogs with a status of A (for available), and then back them up. If the archivelog record has a status of D (deleted) or X (expired), then RMAN will not attempt to back up that archivelog. There is a widely held misperception that RMAN determines which archivelogs to back up by checking the log_archive_dest for available files. This is not the case. RMAN uses views in the controlfile to determine the status and availability, and these views can only be updated by RMAN. So if you clean out archivelogs at the OS level (instead of using RMAN), the archivelog backup will fail as it tries to back up nonexistent files, and will give the same RMAN-20242 error mentioned above when trying to back up archivelogs inaccessible on other nodes.
It is highly recommended that you use RMAN to clean up after your archivelogs even if you don't use RMAN to back them up. Not only does RMAN mark the status of the archivelogs in the controlfile (something you can only do with RMAN), but RMAN will also never delete an archivelog while it is being written by the ARCn process. It knows more about the archivelogs than any other utility.
If you use RMAN to back up archivelogs, we highly recommend using the delete input command at some level to automate archivelog cleanout. That said, you may want to back up archivelogs, but not delete them immediately-in the case of recovery, obviously, it's best to have them on disk, not tape. What you can do is automate a process that backs up archivelogs older than a certain number of days, and then deletes them:
backup archivelog until sysdate-7 delete input;
This will back up archivelogs older than seven days, then delete them. If you want to back up archivelogs up to the current point, but delete ones older than seven days, you can do that also, but it takes two separate commands:
backup archivelog all; delete archivelog completed before sysdate -7;
The only problem with this approach is that if you run it every day, you will get approximately seven copies of every archivelog backed up to tape. This is because you back up all the archivelogs every day, but only delete any of them after seven days. So you can specify how many times to back up archivelogs, after which they will be skipped. Then you issue your delete command:
backup archivelog not backed up 2 times; delete archivelog completed before sysdate -7;
You have now achieved archivelog maintenance nirvana: you back up every archivelog to tape twice, you keep the last few days' worth on disk, and you delete permanently from all backup locations archivelogs that are older than seven days.
From the RAC perspective, archivelog housekeeping follows all guidelines outlined above. In addition, remember that you may have issues of accessibility if you generate archivelogs at different nodes-make sure that you follow the same channel allocation rules you follow for backup when performing maintenance commands.
Thinking Forward to Recovery
The single-node connection that limits RMAN's connection to the RAC database determines how recovery proceeds. While the restore of the database files can occur from any node in the cluster, recovery is a different beast altogether. RMAN connects to a single node in the cluster, issues the recover command, and then goes looking for archivelogs to perform recovery. This session needs archivelogs from every thread in the cluster, meaning that it is looking locally at the node for archivelogs from every node. Figure 8-8 shows what the DBA at Horatio's Woodscrew Company did wrong in Chapter 1, and why his recovery caused so many headaches: he had each archivelog thread generated only at the local node.
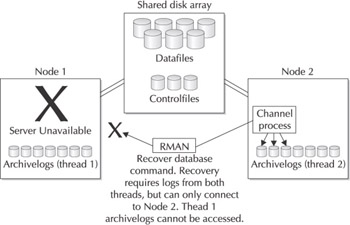
Figure 8-8: The doomed archivelog configuration
There are multiple ways to deal with this situation. We recommend, again, that you run your RAC cluster on an Oracle Cluster File System (OCFS) configuration. With OCFS in use on your shared disk volumes, you can configure all the archivelog destinations for each node to a shared location that is visible to all nodes. If you use a flashback recovery area, put the FRA on the shared OCFS disk pronto: life will be very, very good to you (FRA on CFS is discussed next).
If you are not using CFS, and instead are using uncooked volumes for your shared disk location, you no doubt have decided against putting your archivelogs on the raw partitions because of the administrative impossibility of it all. Instead, all of your archivelogs are being created locally at each node; or you have implemented an NFS multiple archive destination solution to stream a copy of all archivelogs to each node-or to a single recovery node.
The secret to successful recovery when you have archivelogs on cooked, local file systems is the ability to successfully NFS mount the log archive destination of all nodes by the single node that is performing recovery. With node failure a real issue in most environments, here are your rules to live by:
-
You need to push your archivelogs from each node to at least one other node. Otherwise, you've given yourself a single point of failure.
-
Ensure that every log_archive_dest that you have configured for each node is uniquely named, so that you can NFS mount it from any other node.
-
Use RMAN to back up your archivelogs. RMAN can always write archivelogs to whatever location you specify, and when it does, these archivelogs are usable by the recovery session RMAN implements. So you can worry a little less about your complicated archiving strategy.
Flashback Recovery Area for RAC
It is extremely advantageous to use the flashback recovery area, but even more so in a clustered environment. The FRA can ease the headaches associated with multithread archivelog generation, as well as provide simplicity during stressful recovery situations. With a shared FRA (using OCFS), you can set your log_archive_dest of each node to a shared location that is accessible by all other nodes. You can also employ a backup strategy where backups are spread across each node, and the backups still go to a single location, or you can use a single-node backup strategy. With the FRA in place, you can have the backups accessible to all other nodes if a node failure occurs, regardless of your backup strategy. The benefits are simplicity in design and availability as the goal.
Tape Backups and RAC Nodes
Whether you use an FRA or not, it is worth noting that if you plan on backing up to tape, you should configure your vendor's media management interface at each node in the cluster. Even if you back up from a single node, if that one node fails, you may need to perform a restore from a different node.
|
| < Day Day Up > |
|
EAN: N/A
Pages: 134