Chapter 7. XML on the Web
| CONTENTS |
|
XML began as an effort to bring the full power and structure of SGML to the Web in a form that was simple enough for nonexperts to use. Like most great inventions, XML turned out to have uses far beyond what its creators originally envisioned. Indeed, there's a lot more XML off the Web than on it. Nonetheless, XML is still a very attractive language in which to write and serve web pages. Since XML documents must be well-formed and parsers must reject malformed documents, XML pages are less likely to have annoying cross-browser incompatibilities. Since XML documents are highly structured, they're much easier for robots to parse. Since XML tag and attribute names reflect the nature of the content they hold, search-engine spiders can more easily determine the true meaning of a page.
XML on the Web comes in three flavors. The first is XHTML, an XMLized variant of HTML 4.0 that tightens up HTML to match XML's syntax. For instance, XHTML requires that all start-tags correspond to a matching end-tag and that all attribute values be quoted. XHTML also adds a few bits of syntax to HTML, such as the XML declaration and empty-element tags that end with />. Most of XHTML can be displayed quite well in legacy browsers, with a few notable exceptions.
The second flavor of XML on the Web is direct display of XML documents that use arbitrary vocabularies in web browsers. Generally, the formatting of the document is supplied either by a CSS stylesheet or by an XSLT stylesheet that transforms the document into HTML (perhaps XHTML). This flavor requires an XML-aware browser and is only beginning to be supported by the installed base of web clients.
A third option is to mix raw XML vocabularies such as MathML and SVG with XHTML using Modular XHTML. Modular XHTML lets you embed RDF cataloging information, MathML equations, SVG pictures, and more inside your XHTML documents. Namespaces sort out which elements belong to which applications.
7.1 XHTML
XHTML is an official W3C recommendation. It defines an XML-compatible version of HTML, or rather it redefines HTML as an XML application instead of as an SGML application. Just looking at an XHTML document, you might not even realize that there's anything different about it. It still uses the same <p>, <li>, <table>, <h1>, and other tags with which you're familiar. Elements and attributes have the same, familiar names they have in HTML. The syntax is still basically the same.
The difference is not so much what's allowed but what's not allowed. <p> is a legal XHTML tag, but <P> is not. <table border="0" width="515"> is legal XHTML; <table border=0 width=515> is not. A paragraph prefixed with a <p> and suffixed with a </p> is legal XHTML, but a paragraph that omits the closing </p> tag is not. Most existing HTML documents require substantial editing before they become well-formed and valid XHTML documents. However, once they are valid XHTML documents, they are automatically valid XML documents that can be manipulated with the same editors, parsers, and other tools you use to work with any XML document.
7.1.1 Moving from HTML to XHTML
Most of the changes required to turn an existing HTML document into an XHTML document involve making the document well-formed. For instance, given a legacy HTML document, you'll probably have to make at least some of these changes to turn it into XHTML:
-
Add missing end-tags like </p> and </li>.
-
Rewrite elements so that they nest rather than overlap. For example, change <p><em>an emphasized paragraph</p></em> to <p><em>an emphasized paragraph</em></p>.
-
Put double or single quotes around your attribute values. For example, change <p align=center> to <p align="center">.
-
Add values (which are the same as the name) to all minimized Boolean attributes. For example, change <input type="checkbox" checked> to <input type="checkbox" checked="checked">.
-
Replace any occurrences of & or < in character data or attribute values with & and <. For instance, change A&P to A&P and <a href="http://www.google.com/search?client=googlet&q=Java%20XML"> to <a href="http://www.google.com/search?client=googlet&q=Java%20XML">.
-
Make sure the document has a single root html element.
-
Change empty elements like <hr> to <hr/> or <hr></hr>.
-
Add hyphens to comments so that <! this is a comment> becomes <!-- this is a comment -->.
-
Encode the document in UTF-8 or UTF-16, or add an XML declaration that specifies in which character set it is encoded.
However, XHTML doesn't merely require well-formedness; it requires validity. In order to create a valid XHTML document, you'll need to make these changes as well:
-
Add a DOCTYPE declaration to the document pointing to one of the three XHTML DTDs.
-
Make all element and attribute names lowercase.
-
Make any other changes you have to make to your markup so that the document validates against the DTD: for example, eliminating nonstandard elements like marquee, adding required attributes like the alt attribute of img, or moving child elements out from inside elements where they're not allowed such as a blockquote inside a p.
In addition, the XHTML specification imposes several requirements that, strictly speaking, are not required for either well-formedness or validity. However, they do make parsing XHTML documents a little easier. These are:
-
The root element of the document must be html.
-
There must be a DOCTYPE declaration that uses a PUBLIC ID to identify one of the three XHTML DTDs.
-
The root element of the document must have an xmlns attribute identifying the default namespace as http://www.w3.org/1999/xhtml.
Finally, if you wish, you may but do not have to add an XML declaration or an xml-stylesheet processing instruction to the prolog of your document.
Example 7-1 shows an HTML document from the O'Reilly web site that exhibits many of the validity problems you'll find on the Web today. In fact, this is a much neater page than most. Nonetheless, not all attribute values are quoted. The noshade attribute of the HR element doesn't even have a value. There's no document type declaration. Tags are a mix of upper- and lowercase, mostly uppercase. The DD elements are missing end-tags, and there's some character data inside the second definition that's not part of a DT or a DD.
Example 7-1. A typical HTML document
<HTML><HEAD> <TITLE>O'Reilly Shipping Information</TITLE> </HEAD> <BODY BGCOLOR="#ffffff" VLINK="#0000CC" LINK="#990000" TEXT="#000000"> <table border=0 width=515> <tr> <td> <IMG SRC="/www/graphics_new/generic_ora_header_wide.gif" BORDER=0> <H2>U.S. Shipping Information </H2> <HR size="1" align=left noshade> <DL> <DT> <B>UPS Ground Service (Continental US only -- 5-7 business days):</B></DT> <DD> <PRE> $ 5.95 - $ 49.99 ......................... $ 4.50 $ 50.00 - $ 99.99 ......................... $ 6.50 $100.00 - $149.99 ......................... $ 8.50 $150.00 - $199.99 ......................... $10.50 $200.00 - $249.99 ......................... $12.50 $250.00 - $299.99 ......................... $14.50 </PRE> <DT> <B>Federal Express:</B></DT> (Shipping within 24 hours of receipt of order by O'Reilly) <DD> <PRE> <EM>1 or 2 books</EM>: Economy 2-day ............................. $ 8.75 Overnight Standard (Afternoon Delivery) ... $12.75 Overnight Priority (Morning Delivery) ..... $16.50 </PRE> </DL> <b>Alaska and Hawaii:</b> add $10 to Federal Express rates. <P> <A HREF="int-ship.html"><b>International Shipping Information</b></A> <P> <CENTER> <HR SIZE="1" NOSHADE> <FONT SIZE="1" FACE="Verdana, Arial, Helvetica"> <A HREF="http://www.oreilly.com/"> <B>O'Reilly Home</B></A> <B> | </B> <A HREF="http://www.oreilly.com/sales/bookstores"> <B>O'Reilly Bookstores</B></A> <B> | </B> <A HREF="http://www.oreilly.com/order_new/"> <B>How to Order</B></A> <B> | </B> <A HREF="http://www.oreilly.com/oreilly/contact.html"> <B>O'Reilly Contacts<BR></B></A> <A HREF="http://www.oreilly.com/international/"> <B>International</B></A> <B> | </B> <A HREF="http://www.oreilly.com/oreilly/about.html"> <B>About O'Reilly</B></A> <B> | </B> <A HREF="http://www.oreilly.com/affiliates.html"> <B>Affiliated Companies</B></A><p> <EM>© 2000, O'Reilly & Associates, Inc.</EM> </FONT> </CENTER> </td> </tr> </table> </BODY> </HTML>
Example 7-2 shows this document after it's been converted to XHTML. All the previously noted problems and a few more besides have been fixed. A number of deprecated presentational attributes, such as the size and noshade attributes of hr, had to be replaced with CSS styles. We've also added the necessary document type and namespace declarations. This document can now be read by both HTML and XML browsers and parsers.
Example 7-2. A valid XHTML document
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta name="generator" content="HTML Tidy, see www.w3.org" /> <style type="text/css"> body {backgroundColor: #FFFFFF; color: #000000} a:visited {color: #0000CC} a:link {color: #990000} </style> <title>O'Reilly Shipping Information</title> </head> <body> <table border="0" width="515"> <tr> <td><img src="/www/graphics_new/generic_ora_header_wide.gif" style="border-width: 0" alt="O'Reilly"/> <h2>U.S. Shipping Information</h2> <hr style="height: 1; text-align: left"/> <dl> <dt><b>UPS Ground Service (Continental US only -- 5-7 business days):</b></dt> <dd> <pre> $ 5.95 - $ 49.99 ......................... $ 4.50 $ 50.00 - $ 99.99 ......................... $ 6.50 $100.00 - $149.99 ......................... $ 8.50 $150.00 - $199.99 ......................... $10.50 $200.00 - $249.99 ......................... $12.50 $250.00 - $299.99 ......................... $14.50 </pre> </dd> <dt><b>Federal Express:</b></dt> <dd>(Shipping within 24 hours of receipt of order by O'Reilly)</dd> <dd> <pre> <em>1 or 2 books</em>: Economy 2-day ............................. $ 8.75 Overnight Standard (Afternoon Delivery) ... $12.75 Overnight Priority (Morning Delivery) ..... $16.50 </pre> </dd> </dl> <b>Alaska and Hawaii:</b> add $10 to Federal Express rates. <p><a href="int-ship.html"><b>International Shipping Information</b></a></p> <div style="font-size: xx-small; font-face: Verdana, Arial, Helvetica; text-align: center"> <hr style="height: 1"/> <a href="http://www.oreilly.com/"><b>O'Reilly Home</b></a> <b>|</b> <a href="http://www.oreilly.com/sales/bookstores"><b>O'Reilly Bookstores</b></a> <b>|</b> <a href="http://www.oreilly.com/order_new/"><b>How to Order</b></a> <b>|</b> <a href="http://www.oreilly.com/oreilly/contact.html"><b> O'Reilly Contacts<br /> </b></a> <a href="http://www.oreilly.com/international/"><b> International</b></a> <b>|</b> <a href="http://www.oreilly.com/oreilly/about.html"><b>About O'Reilly</b></a> <b>|</b> <a href="http://www.oreilly.com/affiliates.html"><b>Affiliated Companies</b></a></div> <p style="font-size: xx-small; font-family: Verdana, Arial, Helvetica"><em>© 2000, O'Reilly & Associates, Inc.</em></p> </td> </tr> </table> </body> </html>
|

7.1.2 Three DTDs for XHTML
XHTML comes in three flavors, depending on which DTD you choose:
- Strict
-
This is the W3C's recommended form of XHTML. This includes all the basic elements and attributes such as p and class. However, it does not include deprecated elements and attributes such as applet and center. It also forbids the use of presentational attributes such as the body element's bgcolor, vlink, link, and text. These capabilities are provided by CSS instead. Strict XHTML is identified with this DOCTYPE declaration:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd" >
Example 7-2 used this DTD.
- Transitional
-
This is a looser form of XHTML for when you can't easily do without deprecated elements and attributes such as applet and bgcolor. It is identified with this DOCTYPE declaration:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd" >
- Frameset
-
This is the same as the transitional DTD except that it also allows frame-related elements such as frameset and iframe. It is identified with this DOCTYPE declaration:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "DTD/xhtml1-frameset.dtd" >
All three DTDs use the same http://www.w3.org/1999/xhtml namespace. You should choose the strict DTD unless you've got a specific reason to use another one.
7.1.3 Browser Support for XHTML
Many current web browsers, especially Internet Explorer 5.0 and earlier and Netscape 4.79 and earlier, deal inconsistently with XHTML. Certainly they don't require it, accepting as they do such a wide variety of malformed, invalid, and out-and-out mistaken HTML. However, beyond that they do have some problems when they encounter certain common XHTML constructs.
7.1.3.1 The XML declaration and processing instructions
Some browsers display processing instructions and the XML declaration inline. These should be omitted if possible.
Few, if any, browsers recognize or respect the encoding declaration in the XML declaration. Furthermore, many browsers won't automatically recognize UTF-8 or UCS-2 Unicode text. If you use a non-ASCII character set, you should also include a meta element in the header identifying the character set. For example:
<meta http-equiv="Content-type" content='text/html; charset=UTF-8'></meta>
7.1.3.2 Empty elements
Browsers deal inconsistently with both forms of empty element syntax. That is, some browsers understand <hr/> but not <hr></hr> (typically rendering it as two horizontal lines rather than one), while others recognize <hr></hr> but not <hr/> (typically omitting the horizontal line completely). The most consistent rendering seems to be achieved by using an empty-element tag with an optional attribute such as class or id, for example, <hr class="empty" />. There's no real reason for the class attribute here, except that its presence keeps browsers from choking on the />. Any other attribute the DTD allows would serve equally well.
On the other hand, if a particular instance of an element happens to be empty, but not all instances of the element have to be empty for instance, a p that doesn't contain any text you should use two tags like <p></p> rather than one empty-element tag <p/>.
7.1.3.3 Entity references
Embedded scripts often contain reserved characters like & or < so the document that contains them is not well-formed. However, most JavaScript and VBScript interpreters won't recognize & or < in place of the operators they represent. If the script can't be rewritten without these operators (for instance, by changing a less-than comparison to a greater-than-or-equal-to comparison with the arguments flipped), then you should move to external scripts instead of embedded ones.
Furthermore, most non-XML-aware browsers don't recognize the ' predefined entity reference. You should avoid this if possible and just use the literal ' character instead. The only place this might be a problem is inside attribute values that are enclosed in single quotes because they contain double quotes. However, most browsers do recognize the " entity reference for the " character so you can enclose the attribute value in double quotes and escape the double quotes that are part of the attribute value as ".
7.1.3.4 Other unsupported features
There are a few other subtle differences between how browsers handle XHTML and how XHTML expects to be handled. For instance, XHTML allows character references and CDATA sections although almost no current browsers understand these constructs. However, you're unlikely to encounter these when converting from HTML to XHTML, and you can generally do without them if you're writing XHTML from scratch.
Mozilla, Opera 5.0 and later, Internet Explorer 5.5 and later, and Netscape 6.0 and later can parse and display valid XHTML without any difficulties and without requiring page authors to jump through these hoops. However, since many users have not upgraded their browsers to the level XHTML requires, user-friendly web designers will be jumping through these hoops for some years to come.
7.2 Direct Display of XML in Browsers
Ultimately, one hopes that browsers will be able to display not just XHTML documents but any XML document as well. Since it's too much to ask that browsers provide semantics for all XML applications both current and yet-to-be-invented, stylesheets will be attached to each document to provide instructions about how each element will be rendered.
The current major stylesheet languages are:
-
Cascading Style Sheets Level 1 (CSS1)
-
Cascading Style Sheets Level 2 (CSS2)
-
XSL Transformations 1.0
Eventually, there will be still more versions of these, including at least CSS3 and XSLT 2.0. However, let's begin by looking at how and how well existing style languages are supported by existing browsers.
7.2.1 The xml-stylesheet Processing Instruction
The stylesheet associated with a document is indicated by an xml-stylesheet processing instruction in the document's prolog, which comes after the XML declaration but before the root element start-tag. This processing instruction uses pseudoattributes to describe the stylesheet (that is, they look like attributes but are not attributes because xml-stylesheet is a processing instruction and not an element).
7.2.1.1 The required href and type pseudoattributes
There are two required pseudoattributes for xml-stylesheet processing instructions. The value of the href pseudoattribute gives the URL, possibly relative, where the stylesheet can be found. The type pseudoattribute value specifies the MIME media type of the stylesheet, text/css for cascading stylesheets, application/xml for XSLT stylesheets. In Example 7-3, the xml-stylesheet processing instruction tells browsers to apply the CSS stylesheet person.css to this document before showing it to the reader.
Example 7-3. A very simple yet complete XML document
<?xml version="1.0"?> <?xml-stylesheet href="person.css" type="text/css"?> <person> Alan Turing </person>
|
In addition to these two required pseudoattributes, there are four optional pseudoattributes:
-
media
-
charset
-
alternate
-
title
7.2.1.2 The media pseudoattribute
The media pseudoattribute contains a short string identifying for which medium this stylesheet should be used, for example, paper, onscreen display, television, and so forth. It can specify either a single medium or a comma-separated list of mediums. The recognized values include:
- screen
-
Computer monitors
- tty
-
Teletypes, terminals, xterms, and other monospaced, text-only devices
- tv
-
Televisions, WebTVs, video game consoles, and the like
- projection
-
Slides, transparencies, and direct-from-laptop presentations that will be shown to an audience on a large screen
- handheld
-
PDAs, cell phones, GameBoys, and the like
-
Paper
- braille
-
Tactile feedback devices for the sight-impaired
- aural
-
Screen readers and speech synthesizers
- all
-
All of the previously mentioned plus any that haven't been invented yet
For example, this xml-stylesheet processing instruction says that the CSS stylesheet at the URL http://www.cafeconleche.org/style/titus.css should be used for television, projection, and print:
<?xml-stylesheet href="http://www.cafeconleche.org/style/titus.css" type="text/css" media="tv, projection, print"?>
7.2.1.3 The charset pseudoattribute
The charset pseudoattribute specifies in which character set the stylesheet is written, using the same values as the encoding declaration uses. For example, to say that the CSS stylesheet koran.css is written in the ISO-8859-6 character set, you'd use this processing instruction:
<?xml-stylesheet href="koran.css" type="text/css" charset="ISO-8859-6"?>
7.2.1.4 The alternate and title pseudoattributes
The alternate pseudoattribute specifies whether this is the primary stylesheet for its media type or an alternate one for special cases. The default value is no, which indicates that it is the primary stylesheet. If alternate has the value yes, then the browser may (but does not have to) present the user a choice from among the alternate stylesheets. If it does offer a choice, then it uses the value of the title pseudoattribute to tell the user how the stylesheets differ. For example, these three xml-stylesheet processing instructions offer the user a choice between large, small, and medium text:
<?xml-stylesheet href="big.css" type="text/css" alternate="yes" title="Large fonts"?> <?xml-stylesheet href="small.css" type="text/css" alternate="yes" title="Small fonts"?> <?xml-stylesheet href="medium.css" type="text/css" title="Normal fonts"?>
Browsers that aren't able to ask the user to choose a stylesheet will simply pick the first nonalternate sheet that most closely matches its media-type (screen for a typical web browser).
7.2.2 Internet Explorer
Microsoft Internet Explorer 4.0 (IE4) includes an XML parser that can be accessed from VBScript or JavaScript. This is used internally to support channels and the Active Desktop. Your own JavaScript and VBScript programs can use this parser to read XML data and insert it into the web page. However, anything more straightforward, like simply displaying a page of XML from a specified URL, is beyond IE4's capabilities. Furthermore, IE4 doesn't understand any stylesheet language when applied to XML.
Internet Explorer 5 (IE5) and 5.5 (IE 5.5) do understand XML, though their parser is more than a little buggy; it rejects a number of documents it shouldn't reject, most embarrassingly the XML 1.0 specification itself. Internet Explorer 6 (IE6) has improved XML support somewhat, but is still not completely conformant.
IE5 and later can directly display XML files, with or without an associated stylesheet. If no stylesheet is provided, then IE5 uses a default, built-in XSLT stylesheet that displays the tree structure of the XML document along with a little DHTML to allow the user to collapse and expand nodes in the tree. Figure 7-1 shows IE5 displaying Example 6-1 from the last chapter.
Figure 7-1. A document that uses IE5's built-in stylesheet
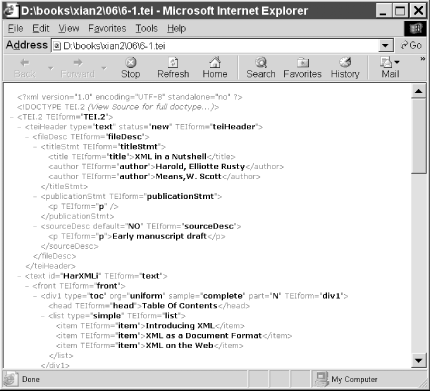
IE5 also supports parts of CSS Level 1 and a little of CSS Level 2. However, the support is spotty and inconsistent. Even some aspects of CSS that work for HTML documents fail when applied to XML documents. IE 5.5 and IE6 slightly improve coverage of CSS, but don't support all CSS properties and selectors. In fact, many CSS features that work in IE6 for HTML still don't work when applied to XML documents.
IE5 and IE 5.5 support their own custom version of XSLT, based on a very early working draft of the XSLT specification. They do not support XSLT 1.0. You can tell the difference by looking at the namespace of the stylesheet. A stylesheet written for IE5 uses the http://www.w3.org/TR/WD-xsl namespace, whereas a stylesheet designed for standard-compliant XSLT processors uses the http://www.w3.org/1999/XSL/Transform namespace. Despite superficial similarities, these two languages are not compatible. A stylesheet written for IE5 will not work with any other XSLT processor, and a stylesheet written using standard XSLT 1.0 will not work in IE5. IE6 supports both real XSLT and Microsoft's nonstandard dialect.
7.2.3 Netscape and Mozilla
Netscape 4.x and earlier do not provide any significant support for displaying XML in the browser. Netscape 4.0.6 and later do use XML internally for some features such as "What's Related." However, the parser used isn't accessible to the page author, even through JavaScript.
Mozilla and Netscape 6.0 do fully support display of XML in the browser. CSS Level 2 is completely supported. Mozilla can read an XML web page, download the associated CSS stylesheet, apply it to the document, and display the result to the end user, all completely automatically and more or less exactly as XML on the Web was always meant to work.
Netscape 6.2 also supports XSLT 1.0, but at the time of this writing the support is fairly buggy, and really hard to get working. You have to serve the files from a web server (not the local disk) and the web server must supply the exactly right MIME media types for the XML document and its stylesheet. Even then the transform fails about half the time. Mozilla 1.0 does have the best XSLT support of any current browser, so it seems likely that future versions of Netscape 6 (which is based on earlier betas of Mozilla) will do a better job. Mozilla also partially supports MathML; and there's a third party effort underway to support SVG graphics. However, this probably won't be ready for Mozilla 1.0.
7.2.4 Alternative Approaches
Authoring your web pages in XML does not necessarily require serving them in XML. Fourth-generation and earlier browsers that don't support XML in any significant way will be with us for years to come. Servicing users with these browsers requires standard, ordinary HTML that works in any browser back to Mosaic 1.0.
One popular option is to write the pages in XML, but serve them in HTML. When the server receives a request for an XML document, it automatically converts the document to HTML and sends the converted document instead. More sophisticated servers can cache the converted documents. They can also recognize browsers that support XML and send them the raw XML instead.
The preferred way to perform the conversion is with an XSLT stylesheet and a Java servlet. Indeed, most XSLT engines such as Xalan-J and SAXON include servlets that do exactly this. However, other schemes are possible, for instance, using PHP or CGI instead of a servlet. The key is to make sure that browsers only receive what they know how to read and display. We'll talk more about XSLT in the next chapter.
7.3 Authoring Compound Documents with Modular XHTML
XHTML 1.1 divides the three XHTML DTDs into individual modules. Parameter entities connect the modules by including or leaving out particular modules. Modules include:
- Structure Module, %xhtml-struct.module;
-
The absolute bare minimum of elements needed for an HTML document: html, head, title, and body
- Text Module, %xhtml-text.module;
-
The basic elements that contain text and other inline elements: abbr, acronym, address, blockquote, br, cite, code, dfn, div, em, h1, h2, h3, h4, h5, h6, kbd, p, pre, q, samp, span, strong, and var
- Hypertext Module, %xhtml-hypertext.module;
-
Elements used for linking, that is, the a element
- List Module, %xhtml-list.module;
-
Elements used for the three kinds of lists: dl, dt, dd, ul, ol, and li
- Applet Module, %xhtml-applet.module;
-
Elements needed for Java applets: applet and param
- Presentation Module, %xhtml-pres.module;
-
Presentation oriented markup, that is, the b, big, hr, i, small, sub, sup, and tt elements
- Edit Module, %xhtml-edit.module;
-
Elements for revision tracking: del and ins
- Bi-directional Text Module, %xhtml-bdo.module;
-
An indication of directionality when text in left-to-right languages, like English and French, is mixed with text in right-to-left languages, like Hebrew and Arabic
- Basic Forms Module, %xhtml-basic-form.module;
-
Forms as defined in HTML 3.2 using the form, input, select, option, and textarea elements
- Forms Module, %xhtml-form.module;
-
Forms as defined in HTML 4.0 using the form, input, select, option, textarea, button, fieldset, label, legend, and optgroup elements
- Basic Tables Module, %xhtml-basic-table.module;
-
Minimal table support including only the table, caption, th, tr, and td elements
- Tables Module, %xhtml-table.module;
-
More complete table support including not only the table, caption, th, tr, and td elements, but also the col, colgroup, tbody, thead, and tfoot elements
- Image Module, %xhtml-image.module;
-
The img element
- Client-side Image Map Module, %xhtml-csismap.module;
-
The map and area elements, as well as extra attributes for several other elements needed to support client-side image maps
- Server-side Image Map Module, %xhtml-ssismap.module;
-
Doesn't provide any new elements, but adds the ismap attribute to the img element
- Object Module, %xhtml-object.module;
-
The object element used to embed executable content like Java applets and ActiveX controls in web pages
- Param Module, %xhtml-param.module;
-
Used to pass parameters from web pages to their embedded executable content like Java applets and ActiveX controls
- Frames Module, %xhtml-frames.module;
-
The elements needed to implement frames including frame, frameset, and noframes
- Iframe Module %xhtml-iframe.mod;
-
The iframe element used for inline frames
- Intrinsic Events, %xhtml-events.module;
-
Attributes to support scripting like onsubmit and onfocus that are attached to elements declared in other modules
- Metainformation Module, %xhtml-meta.module;
-
The meta element used in headers
- Scripting Module, %xhtml-script.module;
-
Elements that support JavaScript and VBScript: script and noscript
- Stylesheet Module, %xhtml-style.module;
-
The style element used to define Cascading Style Sheets
- Link Module, %xhtml-link.module;
-
The link element that specifies relationships to various external documents such as translations, glossaries, and previous and next pages
- Base Module, %xhtml-base.module;
-
The base element that specifies a URL against which relative URLs are resolved
- Target Module, %xhtml-target.module;
-
The target attribute used to specify the destination frame or window of a link
- Style Attribute Module, %xhtml-inlstyle.module;
-
The style attribute used to attach CSS styles to individual elements in the document
- Name Identification Module, %xhtml-nameident.module;
-
The name attribute that is a deprecated earlier version of the id attribute
- Legacy Module, %xhtml-legacy.module;
-
Deprecated elements and attributes including the basefont, center, font, s, strike, and u elements
- Ruby Module, %xhtml11-ruby.module;
-
The ruby, rbc, rtc, rb, rt, and rp elements used in East Asian text to place small amounts of text next to the body text, generally indicating pronunciation
7.3.1 Mixing XHTML into Your Applications
The advantage to dividing HTML into all these different modules is that you can pick and choose the pieces you want. If your documents use tables, you include the table module. If your documents don't use tables, then you can leave it out. You get only the functionality you actually need.
For example, let's suppose you're designing a DTD for a catalog. Each item in the catalog is a catalog_entry element. Each catalog_entry contains a name, a price, an item_number, a color, a size, and various other common elements you're likely to find in catalogs. Furthermore, each catalog_entry contains a description of the item. The description contains formatted narrative text. In other words, it looks something like this:
<catalog_entry> <name>Aluminum Duck Drainer</name> <price>34.99</price> <item_number>54X8</item_number> <color>silver</color> <size>XL</size> <description> <p> This sturdy <strong>silver</strong> colored sink stopper dignifies the <em>finest kitchens</em>. It makes a great gift for </p> <ul> <li>Christmas</li> <li>Birthdays</li> <li>Mother's Day</li> </ul> <p>and all other occasions!</p> </description> </catalog_entry>
It's easy enough to write this markup. The tricky part is validating it. Rather than reinventing a complete DTD to describe all the formatting that's needed in straightforward narrative descriptions, you can reuse XHTML. The XHTML 1.1 DTD makes heavy use of parameter entity references to define content specifications and attribute lists for the different elements. Three entity references are of particular note:
- %Inline.mix;
-
A choice containing all the elements that don't generally require a line break such as em, a, and q. That is, it resolves to:
br | span | em | strong | dfn | code | samp | kbd | var | cite | abbr | acronym | q | tt | i | b | big | small | sub | sup | bdo | a | img | map | applet | ruby | input | select | textarea | label | button | ins | del | script | noscript
- %Block.mix;
-
A choice containing all the elements that generally require a line break like p, blockquote, and ul. That is, it resolves to:
h1 | h2 | h3| h4 | h5 | h6| ul| ol| dl| p | div | pre| blockquote | address | hr | table | form | fieldset | ins | del | script | noscript
- %Flow.mix;
-
A choice containing both of the previous; that is, it resolves to:
h1 | h2 | h3 | h4 | h5 | h6 | ul | ol | dl | p | div | pre | blockquote | address | hr | table | form | fieldset | br | span | em | strong | dfn | code | samp | kbd | var | cite | abbr | acronym | q | tt | i | b | big | small | sub | sup | bdo | a | img | map | applet | ruby | input | select | textarea | label | button | ins | del | script | noscript
You can declare that the description element contains essentially any legal XHTML fragment, like this:
<!ENTITY % xhtml PUBLIC "-//W3C//DTD XHTML 1.1//EN" "xhtml11.dtd"> %xhtml; <!ELEMENT description (#PCDATA | %Flow.mix;)*>
If you wanted to require description to contain only block elements at the top level, you'd instead declare it like this:
<!ENTITY % xhtml PUBLIC "-//W3C//DTD XHTML 1.1//EN" "xhtml11.dtd"> %xhtml; <!ELEMENT description ((%Block.mix;)*)>
The first two lines import the XHTML driver DTD from a relative URL. You can get this DTD and the other local files it depends on from the zip archive at http://www.w3.org/TR/xhtml11/xhtml11.zip. The second line uses an entity reference defined in that DTD to set the content specification for the description element.
|
Unfortunately, this goes a little too far. It includes not only the pieces of HTML you want, such as p, em, and ul, but also a lot of elements you don't want in a printed catalog, such as a, applet, map, and a lot more. However, you can omit these. The main XHTML DTD imports each module inside an INCLUDE/IGNORE block, such as this one for the hypertext module:
<!-- Hypertext Module (required) ................................. --> <!ENTITY % xhtml-hypertext.module "INCLUDE" > <![%xhtml-hypertext.module;[ <!ENTITY % xhtml-hypertext.mod PUBLIC "-//W3C//ELEMENTS XHTML Hypertext 1.0//EN" "http://www.w3.org/TR/xhtml-modularization/DTD/xhtml-hypertext-1.mod" > %xhtml-hypertext.mod;]]>
If the %xhtml-hypertext.module; parameter entity reference has previously been defined as IGNORE instead of INCLUDE, that declaration takes precedence; all the elements and attributes defined in the hypertext module (specifically, the a element) are left out of the resulting DTD.
Let's say you just want the Structure, Basic Text, and List modules. Then you use a driver DTD that redefines the parameter entity references for the other modules as IGNORE. Example 7-4 demonstrates.
Example 7-4. A catalog DTD that uses basic XHTML but omits a lot of elements
<!ELEMENT catalog (catalog_entry*)> <!ELEMENT catalog_entry (name, price, item_number, color, size, description)> <!ELEMENT name (#PCDATA)> <!ELEMENT size (#PCDATA)> <!ELEMENT price (#PCDATA)> <!ELEMENT item_number (#PCDATA)> <!ELEMENT color (#PCDATA)> <!-- throw away the modules we don't need --> <!ENTITY % xhtml-hypertext.module "IGNORE" > <!ENTITY % xhtml-ruby.module "IGNORE" > <!ENTITY % xhtml-edit.module "IGNORE" > <!ENTITY % xhtml-pres.module "IGNORE" > <!ENTITY % xhtml-applet.module "IGNORE" > <!ENTITY % xhtml-param.module "IGNORE" > <!ENTITY % xhtml-bidi.module "IGNORE" > <!ENTITY % xhtml-form.module "IGNORE" > <!ENTITY % xhtml-table.module "IGNORE" > <!ENTITY % xhtml-image.module "IGNORE" > <!ENTITY % xhtml-csismap.module "IGNORE" > <!ENTITY % xhtml-ssismap.module "IGNORE" > <!ENTITY % xhtml-meta.module "IGNORE" > <!ENTITY % xhtml-script.module "IGNORE" > <!ENTITY % xhtml-style.module "IGNORE" > <!ENTITY % xhtml-link.module "IGNORE" > <!ENTITY % xhtml-base.module "IGNORE" > <!-- import the XHTML DTD, at least those parts we aren't ignoring. You will probably need to change the system ID to point to whatever directory you've stored the DTD in. --> <!ENTITY % xhtml11.mod PUBLIC "-//W3C//DTD XHTML 1.1//EN" "xhtml11/DTD/xhtml11.dtd"> %xhtml11.mod; <!ELEMENT description ( %Block.mix; )+>
7.3.2 Mixing Your Applications into XHTML
An even more important feature of Modular XHTML is the option to add new elements that HTML doesn't support. For instance, to include SVG pictures in your documents, you just have to import the SVG DTD and redefine the Misc.extra parameter entity to allow the SVG root element svg. (This only lets you validate XHTML document that contain SVG markup. It doesn't magically give the browser the ability to render these pictures.) You accomplish this by redefining any of three parameter entity references:
- %Inline.extra;
-
Place the root elements of your application here if you want them to be added to the content specifications of inline elements such as span, em, code, and textarea.
- %Block.extra;
-
Place the root elements of your application here if you want them to be added to the content specifications of block elements such as div, h1, p, and pre.
- %Misc.extra;
-
Place the root elements of your application here if you want them to be added to the content specifications of both block and inline elements.
The definition of each of these parameter entities should be a list of the elements you want to add to the content specification separated by vertical bars and beginning with a vertical bar. For instance, to include MathML equations as both inline and block elements, you'd import the MathML DTD and redefine the Misc.extra parameter entity to include the MathML root element math like this:
<!ENTITY % Misc.extra "| math">
If you wanted to allow block-level MathML equations and SVG pictures, you'd import their respective DTDs and redefine the Block.extra parameter entity like this:
<!ENTITY % Block.extra "| math | svg">
Order is important here. The MathML DTD and the Block.extra declaration both have to be parsed before the XHTML DTD is parsed. Example 7-5 demonstrates with a DTD that mixes MathML 1.0 and XHTML, throwing in a namespace declaration for good measure.
Example 7-5. A DTD that mixes MathML into XHTML and MathML
<!ENTITY % mathml SYSTEM "mathml/mathml.dtd"> %mathml; <!ATTLIST math xmlns CDATA #FIXED "http://www.w3.org/1998/Math/MathML"> <!ENTITY % Misc.extra "| math"> <!ENTITY % xhtml PUBLIC "-//W3C//DTD XHTML 1.1//EN" "xhtml11/DTD/xhtml11.dtd"> %xhtml;
You can also mix new elements like math into individual elements like p without changing all the other block elements. The content specification for each XHTML element is defined by a parameter entity named Element.content, for example, %p.content;, %em.content;, %td.content; and so forth. The standard definition of p.content looks like this:
<!ENTITY % p.content "( #PCDATA | %Inline.mix; )*" >
To allow the math element to be a child of p elements, but not of every other block element, you would redefine p.content like this:
<!ENTITY % p.content "( #PCDATA | %Inline.mix; | math )*" >
The XHTML 1.1 DTD is quite sophisticated. There are a lot more tricks you can play by mixing and matching different parts of the DTD, mostly by defining and redefining different parameter entity references. The easiest way to learn about these is by reading the raw DTDs. In many cases, the comments in the DTD are more descriptive and accurate than the prose specification.
7.3.3 Mixing Your Own XHTML
The XHTML 1.1 DTD does not include all of the modules that are available. For instance, frames and the legacy presentational elements are deliberately omitted and cannot easily be turned on. This is the W3C's not-so-subtle way of telling you that you shouldn't be using these elements in the first place. If you do want to use them, you'll need to create your own complete DTD using the individual modules you require.
To do this, first you must define the namespace URI and prefixed names for your elements and attributes. The W3C provides a template you can adapt for this purpose at http://www.w3.org/TR/xhtml-modularization/DTD/templates/template-qname-1.mod. Example 7-6 demonstrates with a DTD fragment that defines the names for the today and quoteoftheday elements that one of the authors uses on his web sites. The module is based on the W3C-provided template.
Example 7-6. A DTD module to define the today and quoteoftheday elements' names and namespaces
<!-- ........................................................... --> <!-- CafeML Qualified Names Module ............................. --> <!-- file: cafe-qname-1.mod This is an extension of XHTML, a reformulation of HTML as a modular XML application. This DTD module is identified by the PUBLIC and SYSTEM identifiers: PUBLIC "-//Elliotte Rusty Harold//ELEMENTS CafeML Qualified Names 1.0//EN" "cafe-qname-1.mod" Revisions: (none) ........................................................... --> <!-- NOTES: Using the CafeML Qualified Names Extension This is a module for a markup language 'CafeML', which currently declares two extension elements, quoteoftheday and today. The parameter entity naming convention uses uppercase for the entity name and lowercase for namespace prefixes, hence this example uses 'CAFEML' and 'cafeml' respectively. Please note the three case variants: 'CafeML' the human-readable markup language name 'CAFEML' used as a parameter entity name prefix 'cafeml' used as the default namespace prefix The %NS.prefixed; conditional section keyword must be declared as "INCLUDE" in order to allow prefixing be used. --> <!-- :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: --> <!-- CafeML Qualified Names This module is contained in two parts, labeled Section 'A' and 'B': Section A declares parameter entities to support namespace- qualified names, namespace declarations, and name prefixing for CafeML. Section B declares parameter entities used to provide namespace-qualified names for all CafeML element types. The recommended step-by-step program for creating conforming modules is enumerated below, and spans both the CafeML Qualified Names Template and CafeML Extension Template modules. --> <!-- Section A: CafeML XML Namespace Framework :::::::::::::::::::: --> <!-- 1. Declare a %CAFEML.prefixed; conditional section keyword, used to activate namespace prefixing. The default value should inherit '%NS.prefixed;' from the DTD driver, so that unless overridden, the default behavior follows the overall DTD prefixing scheme. --> <!ENTITY % NS.prefixed "IGNORE" > <!ENTITY % CAFEML.prefixed "%NS.prefixed;" > <!-- 2. Declare a parameter entity (e.g., %CAFEML.xmlns;) containing the URI reference used to identify the Module namespace: --> <!ENTITY % CAFEML.xmlns "http://www.cafeconleche.org/xmlns/cafeml" > <!-- 3. Declare parameter entities (eg., %CAFEML.prefix;) containing the default namespace prefix string(s) to use when prefixing is enabled. This may be overridden in the DTD driver or the internal subset of a document instance. If no default prefix is desired, this may be declared as an empty string. NOTE: As specified in [XMLNAMES], the namespace prefix serves as a proxy for the URI reference, and is not in itself significant. --> <!ENTITY % CAFEML.prefix "cafeml" > <!-- 4. Declare parameter entities (eg., %CAFEML.pfx;) containing the colonized prefix(es) (eg., '%CAFEML.prefix;:') used when prefixing is active, an empty string when it is not. --> <![%CAFEML.prefixed;[ <!ENTITY % CAFEML.pfx "%CAFEML.prefix;:" > ]]> <!ENTITY % CAFEML.pfx "" > <!-- 5. The parameter entity %CAFEML.xmlns.extra.attrib; may be redeclared to contain any non-CafeML namespace declaration attributes for namespaces embedded in CafeML. When prefixing is active it contains the prefixed xmlns attribute and any namespace declarations embedded in CafeML, otherwise an empty string. --> <![%CAFEML.prefixed;[ <!ENTITY % CAFEML.xmlns.extra.attrib "xmlns:%CAFEML.prefix; %URI.datatype; #FIXED '%CAFEML.xmlns;'" > ]]> <!ENTITY % CAFEML.xmlns.extra.attrib "" > <!ENTITY % XHTML.xmlns.extra.attrib "%CAFEML.xmlns.extra.attrib;" > <!-- Section B: CafeML Qualified Names ::::::::::::::::::::::::::::: --> <!-- This section declares parameter entities used to provide namespace-qualified names for all CafeML element types. --> <!-- module: cafe-1.mod --> <!ENTITY % CAFEML.quoteoftheday.qname "%CAFEML.pfx;quoteoftheday" > <!ENTITY % CAFEML.today.qname "%CAFEML.pfx;today" > <!-- end of cafe-qname-1.mod -->
Next you have to define the elements and attributes with these names in a module of your own creation. The W3C provides a template, which you can adapt for this purpose, at http://www.w3.org/TR/xhtml-modularization/DTD/templates/template-1.mod. This template uses the same techniques and follows the same patterns as XHTML's built-in modules, for example, parameter entity references that resolve to INCLUDE or IGNORE.
Example 7-7 demonstrates with a DTD fragment that defines the today and quoteoftheday elements. The today element can contain any block-level content through the Block.mix parameter entity and has a required date attribute. The quoteoftheday element always contains exactly one blockquote element followed by exactly one p element with no attributes.
Example 7-7. A DTD module to define the today and quoteoftheday elements
<!-- ............................................................ --> <!-- CAFEML Extension Template Module ........................... --> <!-- file: CafeML-1.mod This is an extension of XHTML, a reformulation of HTML as a modular XML application. This DTD module is identified by the PUBLIC and SYSTEM identifiers: PUBLIC "Elliotte Rusty Harold//ELEMENTS CafeML Qualified Names 1.0//EN" SYSTEM "CafeML-1.mod" Revisions: (none) ........................................................... --> <!-- Extension Template This sample template module declares two extension elements, today and quoteoftheday. The parameter entity naming convention uses uppercase for the entity name and lowercase for namespace prefixes. Hence this example uses 'CAFEML' and 'cafe' respectively. This module declares parameter entities used to provide namespace-qualified names for all CAFEML element types, as well as an extensible framework for attribute-based namespace declarations on all element types. The %NS.prefixed; conditional section keyword must be declared as "INCLUDE" in order to allow prefixing to be used. By default, foreign (i.e., non-XHTML) namespace modules should inherit %NS.prefixed; from XHTML, but this can be overridden when prefixing of only the non-XHTML markup is desired. XHTML's default value for the 'namespace prefix' is an empty string. The Prefix value can be redeclared either in a DTD driver or in a document's internal subset as appropriate. NOTE: As specified in [XMLNAMES], the namespace prefix serves as a proxy for the URI reference, and is not in itself significant. --> <!-- ................................................................ --> <!-- 1. Declare the xmlns attributes used by CAFEML dependent on whether CAFEML's prefixing is active. This should be used on all CAFEML element types as part of CAFEML's common attributes. If the entire DTD is namespace-prefixed, CAFEML should inherit %NS.decl.attrib;. Otherwise it should declare %NS.decl.attrib; plus a default xmlns attribute on its own element types. --> <![%CAFEML.prefixed;[ <!ENTITY % CAFEML.xmlns.attrib "%NS.decl.attrib;" > ]]> <!ENTITY % CAFEML.xmlns.attrib "xmlns %URI.datatype; #FIXED '%CAFEML.xmlns;'" > <!-- now include the module's various markup declarations ........ --> <!ENTITY % CAFEML.Common.attrib "%CAFEML.xmlns.attrib; id ID #IMPLIED" > <!-- 2. In the attribute list for each element, declare the XML Namespace declarations that are legal in the document instance by including the %NamespaceDecl.attrib; parameter entity in the ATTLIST of each element type. --> <!ENTITY % CAFEML.today.qname "today" > <!ELEMENT %CAFEML.today.qname; ( %Flow.mix; )* > <!ATTLIST %CAFEML.today.qname; %CAFEML.Common.attrib; date CDATA #REQUIRED > <!ENTITY % CAFEML.quoteoftheday.qname "quoteoftheday" > <!ELEMENT %CAFEML.quoteoftheday.qname; ( %blockquote.qname;, %p.qname; ) > <!ATTLIST %CAFEML.quoteoftheday.qname; %CAFEML.Common.attrib; > <!-- 3. If the module adds attributes to elements defined in modules that do not share the namespace of this module, declare those attributes so that they use the %CAFEML.pfx; prefix. For example: <!ENTITY % CAFEML.img.myattr.qname "%CAFEML.pfx;myattr" > <!ATTLIST %img.qname; %CAFEML.img.myattr.qname; CDATA #IMPLIED > This would add a myattr attribute to the img element of the Image Module, but the attribute's name will be the qualified name, including prefix, when prefixes are selected for a document instance. We do not need to do this for this module. --> <!-- end of CafeML-1.mod -->
Next you need to write a document model module that defines the parameter entities used for content specifications in the various modules not only the CafeML modules, but the XHTML modules as well. (This is how your elements become part of the various XHTML elements.) The W3C does not provide a template for this purpose. However, it's normally easy to adapt the document model module from either XHTML 1.1 or XHTML Basic to include your new elements. Example 7-8 is a document model module based on the XHTML 1.1 document model module.
Example 7-8. A document model module for CafeML
<!-- ............................................................ --> <!-- CafeML Model Module ....................................... --> <!-- file: CafeML-model-1.mod PUBLIC "-//Elliotte Rusty Harold//ELEMENTS XHTML CafeML Model 1.0//EN" SYSTEM "CafeML-model-1.mod" xmlns:cafeml="http://www.cafeconleche.org/xmlns/cafeml" ............................................................ --> <!-- Define the content model for Misc.extra --> <!ENTITY % Misc.extra "| %CAFEML.today.qname; | %CAFEML.quoteoftheday.qname; "> <!-- .................... Inline Elements ..................... --> <!ENTITY % HeadOpts.mix "( %meta.qname; )*" > <!ENTITY % I18n.class "" > <!ENTITY % InlStruct.class "%br.qname; | %span.qname;" > <!ENTITY % InlPhras.class "| %em.qname; | %strong.qname; | %dfn.qname; | %code.qname; | %samp.qname; | %kbd.qname; | %var.qname; | %cite.qname; | %abbr.qname; | %acronym.qname; | %q.qname;" > <!ENTITY % InlPres.class "" > <!ENTITY % Anchor.class "| %a.qname;" > <!ENTITY % InlSpecial.class "| %img.qname; " > <!ENTITY % Inline.extra "" > <!-- %Inline.class; includes all inline elements, used as a component in mixes --> <!ENTITY % Inline.class "%InlStruct.class; %InlPhras.class; %InlPres.class; %Anchor.class; %InlSpecial.class;" > <!-- %InlNoAnchor.class; includes all non-anchor inlines, used as a component in mixes --> <!ENTITY % InlNoAnchor.class "%InlStruct.class; %InlPhras.class; %InlPres.class; %InlSpecial.class;" > <!-- %InlNoAnchor.mix; includes all non-anchor inlines --> <!ENTITY % InlNoAnchor.mix "%InlNoAnchor.class; %Misc.class;" > <!-- %Inline.mix; includes all inline elements, including %Misc.class; --> <!ENTITY % Inline.mix "%Inline.class; %Misc.class;" > <!-- ..................... Block Elements ...................... --> <!ENTITY % Heading.class "%h1.qname; | %h2.qname; | %h3.qname; | %h4.qname; | %h5.qname; | %h6.qname;" > <!ENTITY % List.class "%ul.qname; | %ol.qname; | %dl.qname;" > <!ENTITY % BlkStruct.class "%p.qname; | %div.qname;" > <!ENTITY % BlkPhras.class "| %pre.qname; | %blockquote.qname; | %address.qname;" > <!ENTITY % BlkPres.class "| %hr.qname;" > <!ENTITY % Block.extra "" > <!ENTITY % Table.class "| %table.qname;" > <!ENTITY % BlkSpecial.class "%Table.class;" > <!-- %Block.class; includes all block elements, used as an component in mixes --> <!ENTITY % Block.class "%BlkStruct.class; %BlkPhras.class; %BlkPres.class; %BlkSpecial.class; %Block.extra;" > <!-- %Block.mix; includes all block elements plus %Misc.class; --> <!ENTITY % Block.mix "%Heading.class; | %List.class; | %Block.class; %Misc.class;" > <!-- ................ All Content Elements .................. --> <!-- %Flow.mix; includes all text content, block and inline --> <!ENTITY % Flow.mix "%Heading.class; | %List.class; | %Block.class; | %Inline.class; %Misc.class;" > <!-- special content model for pre element --> <!ENTITY % pre.content "( #PCDATA | %Inline.class; )*" > <!-- end of CafeML-model-1.mod -->
Finally, replace the standard XHTML DTD, which only imports the normal XHTML modules, with a new one that imports the standard modules you want, as well as any new modules you've defined. Again, the W3C offers a template for this purpose, which you can download from http://www.w3.org/TR/xhtml-modularization/DTD/templates/template.dtd. This template is a minimal DTD that makes the necessary imports and declares the necessary parameter entity references upon which all the other modules depend. Example 7-9 is a DTD based on this template. It merges in the element module defined in Example 7-7, as well as the standard XHTML tables, images, meta, and block presentation modules.
Example 7-9. An XHTML DTD that mixes in the Cafe DTD
<!-- ................................................................. --> <!-- XHTML + CafeML DTD ............................................. --> <!-- file: CafeML.dtd --> <!-- CafeML DTD --> <!-- Please use this formal public identifier to identify it: "-//Elliotte Rusty Harold//DTD XHTML CafeDTD//EN" --> <!ENTITY % XHTML.version "-//W3C//DTD XHTML CafeDTD//EN" > <!-- Bring in any qualified name modules outside of XHTML --> <!ENTITY % CAFEML-qname.mod SYSTEM "cafe-qname-1.mod"> %CAFEML-qname.mod; <!-- Define any extra prefixed namespaces that this DTD relies upon --> <!ENTITY NS.prefixed.extras.attrib "" > <!-- Define the Content Model file for the framework to use --> <!ENTITY % xhtml-model.mod SYSTEM "CafeML-model-1.mod" > <!-- reserved for future use with document profiles --> <!ENTITY % XHTML.profile "" > <!-- Bi-directional text support This feature-test entity is used to declare elements and attributes used for internationalization support. Set it to INCLUDE or IGNORE as appropriate for your markup language. --> <!ENTITY % XHTML.bidi "IGNORE" > <!-- ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: --> <!-- Pre-Framework Redeclaration placeholder .................... --> <!-- This serves as a location to insert markup declarations into the DTD prior to the framework declarations. --> <!ENTITY % xhtml-prefw-redecl.module "IGNORE" > <![%xhtml-prefw-redecl.module;[ %xhtml-prefw-redecl.mod; <!-- end of xhtml-prefw-redecl.module -->]]> <!-- The events module should be included here if you need it. In this skeleton it is IGNOREd. --> <!ENTITY % xhtml-events.module "IGNORE" > <!-- Modular Framework Module ................................... --> <!ENTITY % xhtml-framework.module "INCLUDE" > <![%xhtml-framework.module;[ <!ENTITY % xhtml-framework.mod PUBLIC "-//W3C//ENTITIES XHTML 1.1 Modular Framework 1.0//EN" "xhtml-framework-1.mod" > %xhtml-framework.mod;]]> <!-- Post-Framework Redeclaration placeholder ................... --> <!-- This serves as a location to insert markup declarations into the DTD following the framework declarations. --> <!ENTITY % xhtml-postfw-redecl.module "IGNORE" > <![%xhtml-postfw-redecl.module;[ %xhtml-postfw-redecl.mod; <!-- end of xhtml-postfw-redecl.module -->]]> <!-- Text Module (required) ............................... --> <!ENTITY % xhtml-text.module "INCLUDE" > <![%xhtml-text.module;[ <!ENTITY % xhtml-text.mod PUBLIC "-//W3C//ELEMENTS XHTML 1.1 Text 1.0//EN" "xhtml-text-1.mod" > %xhtml-text.mod;]]> <!-- Hypertext Module (required) ................................. --> <!ENTITY % xhtml-hypertext.module "INCLUDE" > <![%xhtml-hypertext.module;[ <!ENTITY % xhtml-hypertext.mod PUBLIC "-//W3C//ELEMENTS XHTML 1.1 Hypertext 1.0//EN" "xhtml-hypertext-1.mod" > %xhtml-hypertext.mod;]]> <!-- Lists Module (required) .................................... --> <!ENTITY % xhtml-list.module "INCLUDE" > <![%xhtml-list.module;[ <!ENTITY % xhtml-list.mod PUBLIC "-//W3C//ELEMENTS XHTML 1.1 Lists 1.0//EN" "xhtml-list-1.mod" > %xhtml-list.mod;]]> <!-- Your modules can be included here. Use the basic form defined above, and be sure to include the public FPI definition in your catalog file for each module that you define. You may also include W3C-defined modules at this point. --> <!-- CafeML Module (custom module) ....................... --> <!ENTITY % cafeml.module "INCLUDE" > <![%cafeml.module;[ <!ENTITY % cafeml.mod PUBLIC "-//Cafe con Leche//XHTML Extensions today 1.0//EN" "CafeML-1.mod" > %cafeml.mod;]]> <!-- Tables Module (optional) ....................... --> <!ENTITY % xhtml-table.module "INCLUDE" > <![%xhtml-table.module;[ <!ENTITY % xhtml-table.mod PUBLIC "-//W3C//ELEMENTS XHTML Tables 1.0//EN" "xhtml-table-1.mod" > %xhtml-table.mod;]]> <!-- Meta Module (optional) ....................... --> <!ENTITY % xhtml-meta.module "INCLUDE" > <![%xhtml-meta.module;[ <!ENTITY % xhtml-meta.mod PUBLIC "-//W3C//ELEMENTS XHTML Meta 1.0//EN" "xhtml-meta-1.mod" > %xhtml-meta.mod;]]> <!-- Image Module (optional) ....................... --> <!ENTITY % xhtml-image.module "INCLUDE" > <![%xhtml-image.module;[ <!ENTITY % xhtml-image.mod PUBLIC "-//W3C//ELEMENTS XHTML Images 1.0//EN" "xhtml-image-1.mod" > %xhtml-image.mod;]]> <!-- Block Presentation Module (optional) ....................... --> <!ENTITY % xhtml-blkpres.module "INCLUDE" > <![%xhtml-blkpres.module;[ <!ENTITY % xhtml-blkpres.mod PUBLIC "-//W3C//ELEMENTS XHTML Block Presentation 1.0//EN" "xhtml-blkpres-1.mod" > %xhtml-blkpres.mod;]]> <!-- Document Structure Module (required) ....................... --> <!ENTITY % xhtml-struct.module "INCLUDE" > <![%xhtml-struct.module;[ <!ENTITY % xhtml-struct.mod PUBLIC "-//W3C//ELEMENTS XHTML 1.1 Document Structure 1.0//EN" "xhtml-struct-1.mod" > %xhtml-struct.mod;]]> <!-- end of CAFEML DTD .............................................. --> <!-- ................................................................. -->
7.4 Prospects for Improved Web-Search Methods
Part of the hype of XML has been that web search engines will finally understand what a document means by looking at its markup. For instance, you can search for the movie Sneakers and just get back hits about the movie without having to sort through "Internet Wide Area `Tiger Teamers' mailing list," "Children's Side Zip Sneakers Recalled by Reebok," "Infant's `Little Air Jordan' Sneakers Recalled by NIKE," "Sneakers.com - Athletic shoes from Nike, Reebok, Adidas, Fila, New," and the 32,395 other results that Google pulled up on this search that had nothing to do with the movie.[1]
In practice, this is still vapor, mostly because few web pages are available on the frontend in XML, even though more and more backends are XML. The search-engine robots only see the frontend HTML. As this slowly changes, and as the search engines get smarter, we should see more and more useful results. Meanwhile, it's possible to add some XML hints to your HTML pages that knowledgeable search engines can take advantage of using the Resource Description Framework (RDF), the Dublin Core, and the robots processing instruction.
7.4.1 RDF
The Resource Description Framework (RDF, http://www.w3.org/RDF/) can be understood as an XML encoding for a particularly simple data model. An RDF document describes resources. Each resource has zero or more properties. Each property has a name and a value. The value may itself be another resource.
The root element of an RDF document is an RDF element. Each resource the RDF element describes is represented as a Description element whose about attribute contains a URI or other identifier pointing to the resource described. Each child element of the Description element represents a property of the resource. The contents of that child element are the value of that property. All RDF elements like RDF and Description are placed in the http://www.w3.org/1999/02/22-rdf-syntax-ns# namespace. Property values generally come from other namespaces.
For example, suppose we want to say that the book XML in a Nutshell has the authors W. Scott Means and Elliotte Rusty Harold. In other words, we want to say that the resource identified by the URI urn:isbn:0596002920 has one author property with the value "W. Scott Means" and another author property with the value "Elliotte Rusty Harold." Example 7-10 does this.
Example 7-10. A simple RDF document saying that W. Scott Means and Elliotte Rusty Harold are the authors of XML in a Nutshell
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> <rdf:Description about="urn:isbn:0596002920"> <author>Elliotte Rusty Harold</author> <author>W. Scott Means</author> </rdf:Description> </rdf:RDF>
In this simple example the values of the author properties are merely text. However, they could be XML as well. Indeed, they could be other RDF elements.
There's more to RDF, including containers, schemas, and nested properties. However, this will be sufficient description for web metadata.
7.4.2 Dublin Core
The Dublin Core, http://purl.org/dc/, is a standard set of ten information items with specified semantics that reflect the sort of data you'd be likely to find in a card catalog or annotated bibliography. These are:
- Title
-
Fairly self-explanatory; this is the name by which the resource is known. For instance, the title of this book is "XML in a Nutshell."
- Creator
-
The person or organization who created the resource, e.g., a painter, author, illustrator, composer, and so on. For instance, the creators of this book are W. Scott Means and Elliotte Rusty Harold.
- Subject
-
A list of keywords, very likely from some other vocabulary such as the Dewey Decimal System or Yahoo categories, identifying the topics of the resource. For instance, using the Library of Congress Subject Headings vocabulary, the subject of this book is "XML (Document markup language)."
- Description
-
Typically, a brief amount of text describing the content of the resource in prose, but it may also include a picture, a table of contents, or any other description of the resource. For instance, a description of this book might be "A brief tutorial on and quick reference to XML and related technologies and specifications."
- Publisher
-
The name of the person, company, or organization who makes the resource available. For instance, the publisher of this book is "O'Reilly & Associates."
- Contributor
-
A person or organization who made some contribution to the resource but is not the primary creator of the resource. For example, the editors of this book, Laurie Petrycki, Simon St.Laurent, and Jeni Tennison, might be identified as contributors, as would Susan Hart, the artist who drew the picture on the cover.
- Date
-
The date when the book was created or published, normally given in the form YYYY-MM-DD. For instance, this book's date might be 2002-05-23.
- Type
-
The abstract kind of resource such as image, text, sound, or software. For instance, a description of this book would have the type text.
- Format
-
For hard objects like books, the physical dimensions of the resource. For instance, the paper version of XML in a Nutshell has the dimensions 6" x 9". For digital objects like web pages, this is possibly the MIME media type. For instance, an online version of this book would have the Format text/html.
- Identifier
-
A formal identifier for the resource, such as an ISBN number, a URI, or a Social Security number. This book's identifier is "0596002920."
- Source
-
The resource from which the present resource was derived. For instance, the French translation of this book might reference the original English edition as its source.
- Language
-
The language in which this resource is written, typically an ISO-639 language code, optionally suffixed with a hyphen and an ISO-3166 country code. For instance, the language for this book is en-US. The language for the French translation of this book might be fr-FR.
- Relation
-
A reference to a resource that is in some way related to the current one, generally using a formal identifier, such as a URI or an ISBN number. For instance, this might refer to the web page for this book.
- Coverage
-
The location, time, or jurisdiction the resource covers. For instance, the coverage of this book might be the U.S., Canada, Australia, the U.K., and Ireland. The coverage of the French translation of this book might be France, Canada, Haiti, Belgium, and Switzerland. Generally these will be listed in some formal syntax such as country codes.
- Rights
-
Information about copyright, patent, trademark and other restrictions on the content of the resource. For instance, a rights statement about this book may say "Copyright 2002 O'Reilly & Associates."
Dublin Core can be encoded in a variety of forms including HTML META tags and RDF. Here we concentrate on its encoding in RDF. Typically, each resource is described with an rdf:Description element. This element contains child elements for as many of the Dublin Core information items as are known about the resource. The name of each of these elements matches the name of one of the 14 Dublin Core properties. These are placed in the http://purl.org/dc/elements/1.1/ namespace. Example 7-11 shows an RDF-encoded Dublin Core description of this book.
Example 7-11. An RDF-encoded Dublin Core description for XML in a Nutshell
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description about="urn:isbn:0596002920"> <dc:Title>XML in a Nutshell</dc:Title> <dc:Creator>W. Scott Means</dc:Creator> <dc:Creator>Elliotte Rusty Harold</dc:Creator> <dc:Subject>XML (Document markup language)</dc:Subject>. <dc:Description> A brief tutorial on and quick reference to XML and related technologies and specifications </dc:Description> <dc:Publisher>O'Reilly & Associates</dc:Publisher> <dc:Contributor>Laurie Petrycki</dc:Contributor> <dc:Contributor>Simon St. Laurent</dc:Contributor> <dc:Contributor>Jeni Tennison</dc:Contributor> <dc:Contributor>Susan Hart</dc:Contributor> <dc:Date>2002-04-23</dc:Date> <dc:Type>text</dc:Type> <dc:Format>6" x 9"</dc:Format> <dc:Identifier>0596002920</dc:Identifier> <dc:Language>en-US</dc:Language> <dc:Relation>http://www.oreilly.com/catalog/xmlnut/</dc:Relation> <dc:Coverage>US UK ZA CA AU NZ</dc:Coverage> <dc:Rights>Copyright 2002 O'Reilly & Associates</dc:Rights> </rdf:Description> </rdf:RDF>
There is as yet no standard for how an RDF document should be associated with the XML document it describes. One possibility is for the rdf:RDF element to be embedded in the document it describes, for instance, as a child of the BookInfo element of the DocBook source for this book. Another possibility is that servers provide this meta information through an extra-document channel. For instance, a standard protocol could be defined that would allow search engines to request this information for any page on the site. A convention could be adopted so that for any URL xyz on a given web site, the URL xyz/meta.rdf would contain the RDF-encoded Dublin Core metadata for that URL.
7.4.3 Robots
In HTML the robots META tag tells search engines and other robots whether they're allowed to index a page. Walter Underwood has proposed the following processing instruction as an equivalent for XML documents:
<?robots index="yes" follow="no"?>
Robots will look for this in the prolog of any XML document they encounter. The syntax of this particular processing instruction is two pseudoattributes, one named index and one named follow, whose values are either yes or no. If the index attribute has the value yes, then this page will be indexed by a search-engine robot. If index has the value no, then it won't be. Similarly, if follow has the value yes, then links from this document will be followed. If follow has the value no, then they won't be.
[1] In fairness to Google, four of the first ten hits it returned were about the movie.
| CONTENTS |
EAN: 2147483647
Pages: 28