Solution Overview
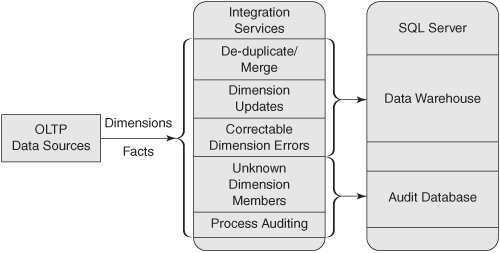
| Our solution uses patterns that can be repeated for many commonly occurring data cleansing requirements. We will merge two partially overlapping lists using fuzzy matching, detect facts that refer to missing dimension members and re-route them appropriately, create placeholders for delayed dimension members, and implement an ETL audit process. The entire solution is implemented in the ETL phase, using SQL Server Integration Services (SSIS, or Integration Services). Business RequirementsThe customer lists from the two stores must be merged, and duplicates should be eliminated. When duplicates are encountered, the most recent customer information should be retained. All sales data must be accounted for. Valid records must be placed into the data warehouse, and records with any faults must be redirected for corrective action. Where possible, fact records should be included in the data warehouse even if they can't be completely assigned to standard categories. Those incomplete fact records must be assigned to well-known special categories such as "unknown" or "missing." High-Level ArchitectureOur goal is to load only clean data from the source systems into our data warehouse. The ETL process will move valid data directly into the data warehouse without using an intermediate staging database. A new management and auditing database will be used to hold data that needs remedial action and data that tracks and traces the flow of data into the data warehouse. Resolving issues with the rejected data will typically require a solution tailored to your specific subject area to present the rows to a user for correction and subsequent resubmission to the ETL process. We leave building that application to you as an exercise because it is not directly related to SQL Server 2005. Before we can load any operational data, we need to clean up the existing customer data by merging the lists from the two companies. This one-time process removes duplicate customers from the merged list, while retaining the most recent customer data. To accommodate the free-form entry of names and addresses, we will use fuzzy matching techniques available in Integration Services to achieve good duplicate detection in spite of small differences in formatting or spelling between some of the common fields of the same customer. In production, we will use Integration Services to perform the normal ETL processes necessary to deliver the data from the source to the data warehouse. During this processing, errors such as missing dimension members will be automatically detected by the Integration Services transforms. Most transforms have at least two output paths: one for success, and one for the failing rows that we will use to redirected problem fact records for alternate processing. We'll use additional transforms to count the records moved along each path and record the counts in an audit table. As shown in Figure 7-1, source data will be routed using Integration Services data flows either to the data warehouse, to a process for automatic correction, or to a queue for manual correction. Figure 7-1. High-level architecture Business BenefitsUsers will be able to rely on the data they obtain from the data warehouse. Reports will be available sooner and will be more accurate because errors will be detected before they find their way into reports, and systemic processing errors in the data sources can be more readily identified and corrected, further reducing the effort necessary to produce reports. |
EAN: 2147483647
Pages: 132