Criteria in Designing IP Networks The topics in this section are important both for understanding IP addressing and routing and for use within the context of the Cisco certification. The need for the hierarchical design proposed by Cisco is discussed, explaining the function of each layer and how access lists are used in conjunction with this design to protect the network from excessive and redundant traffic. This section deals with the hierarchical design that Cisco uses. The design integrates well with VLSM design because summarization helps to ensure a stable and well-managed network. This section also includes a review of access lists and their use, because they are integral to IP network design. You will examine alternatives to access lists and identify other key points to remember when designing an IP network. The Cisco Hierarchical Design It is crucial to build a network that can grow or scale with the needs of the user . This avoids a network that reels from crisis to crisis. Cisco provides a hierarchical design that simplifies network management and also allows the network to grow. This growth may be physical growth or capacity growth. To achieve a stable and responsive networkand to keep local traffic local, preventing network congestionCisco suggests a network design structure that allows for growth. The key to the design is making it hierarchical, with a division of functionality between the layers of the hierarchy. Traffic that begins on a lower layer of the hierarchy is only allowed to be forwarded through to the upper levels if it meets clearly defined criteria. A filtering operation restricts unnecessary traffic from traversing the entire network. Thus, the network is more adaptable, scalable, and reliable. Clear guidelines and rules govern how to design networks according to these principles. The following section explains how the hierarchical network design proposed by Cisco reduces congestion. If the network is designed hierarchically, with each layer acting as a filter for the layer beneath it, the network can grow effectively. In this way, local traffic is kept local (within the same layer), and only data and information about global resources needs to travel outside the immediate domain or layer. Understanding that the layers are filtering functions begs the question of how many layers are required in your network. The answer is that it depends on the type of applications and network architecture, in addition to other criteria. The Cisco design methodology is based on simplicity and filtering. Cisco suggests that the largest networks currently require no more than three layers of filtering. Because a hierarchical layer in the network topology is a control point for traffic flow, a hierarchical layer is the same as a routing layer. Thus, a layer of hierarchy is created with the placement of a router or a Layer 3 switching device. The number of hierarchical layers that you need to implement in your network reflects the amount of traffic control required. To determine how many layers are required, you must identify the function that each layer will have within your network. The Functions of Each Layer Each hierarchical layer in the network design is responsible for preventing unnecessary traffic from being forwarded to the higher layers, only to be discarded by unrelated or uninterested hosts . The goal is to allow only relevant traffic to traverse the network and thereby reduce the load on the network. If this goal is met, the network can scale more effectively. The three layers of a hierarchy are as follows : -
The access layer -
The distribution layer -
The core layer The next sections describe each layer in more detail. The Access Layer In accordance with its name , the access layer is where the end devices connect to the networkwhere they gain access to the company network. The Layer 3 devices (such as routers) that guard the entry and exit to this layer are responsible for ensuring that all local server traffic does not leak out to the wider network. Quality of service (QoS) classification is performed here, along with other technologies that define the traffic that is to traverse the network. Service Advertisement Protocol (SAP) filters for NetWare and AppleTalk's GetZoneLists are also implemented here, in reference to the design consideration of client/server connectivity. The Distribution Layer The distribution layer provides connectivity between several parts of the access layer. The distribution layer is responsible for determining access across the campus backbone by filtering out unnecessary resource updates and by selectively granting specific access to users and departments. Access lists are used not just as traffic filters, but as the first level of rudimentary security. Access to the Internet is implemented here, requiring a more sophisticated security or firewall system. The Core Layer The responsibility of the core layer is to connect the entire enterprise by interconnecting distribution layer devices. At the pinnacle of the network, reliability is of the utmost importance. A break in the network at this level would result in the inability for large sections of the organization to communicate. To ensure continuous connectivity, the core layer should be designed to be highly redundant, and as much as possible, all latency should be removed. Because latency is created when decisions are required, decisions relating to complex routing issues, such as filters, should not be implemented at this layer. They should be implemented at the access or distribution layers, leaving the core layer with the simple duty of relaying the data as fast as possible to all areas of the network. In some implementations , QoS is implemented at this layer to ensure a higher priority to certain packets, preventing them from being lost during high congestion periods. General Design Rules for Each Layer A clear understanding of the traffic patterns within the organizationwho is connecting to whom and whenhelps to ensure the appropriate placement of client and servers, and eases the implementation of filtering at each layer. Without hierarchy, networks have less capacity to scale because the traffic must traverse every path to find its destination, and manageability becomes an issue. It is important for each layer to communicate only with the layer above or below it. Any connectivity or meshing within a layer impedes the hierarchical design. Organizations often design their networks with duplicate paths. This is to build network resilience so that the routing algorithm can immediately use an alternative path if the primary link fails. If this is the design strategy of your company, care should be taken to ensure that the hierarchical topology is still honored. Figure 3-1 shows an illustration of the appropriate design and traffic flow. Figure 3-1. Redundant Connections Between Layers 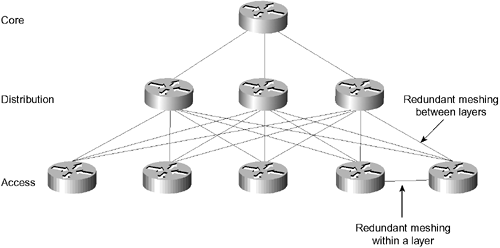 You need to have an understanding of the current network, the placement of the servers, and traffic flow patterns before attempting to design an improved network with the proper hierarchy. One of the strengths of the Cisco hierarchical design is that it allows you to identify easily where to place the access lists. A quick review of access lists and how they can be used is provided in the next section. IP Access Lists Cisco router features enable you to control traffic, primarily through access lists. They are crucial to the sophisticated programming of a Cisco router and allow for great subtlety in the control of traffic. Given that the router operates at Layer 3, the control that is offered is extensive . The router can also act at higher layers of the OSI model. This proves useful when identifying particular traffic and protocol types for prioritization across slower WAN links. You can use access lists to either restrict or police traffic entering or leaving a specified interface. They are also used to implement "what if" logic on a Cisco router. This gives you the only real mechanism of programming the Cisco router. The access lists used for IP in this way enable you to apply subtlety to the router's configuration. This section reviews how to configure access lists and discusses their use in an IP network. The books CCNA Self-Study: Interconnecting Cisco Network Devices (ICND) and the CCNA ICND Exam Certification Guide (CCNA Self-Study, exam #640-811) , both from Cisco Press, deal with these subjects in more depth. Because access lists can be used so subtly in system programming, they are used in many ways. IP access lists are used mainly to manage traffic. The next sections discuss the role of access lists in security and controlling terminal access. Security Using Access Lists Cisco recommends using alternative methods rather than access lists for security. Although access lists are complex to conceive and write, they are easy to spoof and break through. As of IOS software version 11.3, Cisco implemented full security features. Use these features instead of access lists. The Cisco Secure Integrated Software (IOS Firewall Feature Set) is also now available. Some simple security tasks are well suited to access lists, however. Although access lists do not constitute complex security, they will deter the idle user from exploring the company network. The best way to use access lists for security is as the first hurdle in the system, to alleviate processing on the main firewall. Whether the processing on the firewall device is better designed for dealing with the whole security burden , or whether this task should be balanced between devices, should be the topic of a capacity-planning project. Controlling Terminal Access Access lists applied to router interfaces filter traffic traversing the router; they are not normally used to filter traffic generated by the router itself. To control Telnet traffic in which the router is the end station, an access list can be placed on the vty. Five terminal sessions are available: vty 0 through vty 4. Because anticipating which session will be assigned to which terminal is difficult, control is generally placed uniformly on all virtual terminals. Although this is the default configuration, some platforms have different limitations on the number of vty interfaces that can be created. Traffic Control Through Routing Updates Traffic on the network must be managed. Traffic management is most easily accomplished at Layer 3 of the OSI model. You must be careful, however, because limiting traffic also limits connectivity. Therefore, careful design and documentation is required. Routing updates convey information about the available networks. In most routing protocols, these updates are sent out periodically to ensure that every router's perception of the network is accurate and current. Distribute Lists Access lists that are applied to routing protocols restrict the information sent out in the update and are called distribute lists . Distribute lists work by omitting the routing information about certain networks based on the criteria in the access list. The result is that remote routers that are unaware of these networks are not capable of delivering traffic to them. Networks hidden in this way are typically research-and-development sites, test labs, secure areas, or just private networks. This is also a way to reduce overhead traffic in the network. These distribute lists are also used to prevent routing loops in networks that have redistribution between multiple routing protocols. When connecting two separate routing domains, the connection point of the domains, or the entry point to the Internet, is an area through which only limited information needs to be sent. Otherwise , routing tables become unmanageably large and consume large amounts of bandwidth. Other Solutions to Traffic Control Many administrators tune the update timers between routers, trading currency of information for optimization of bandwidth. All routers running the same routing protocol expect to hear these updates with the same frequency that they send out their own. If any of the parameters defining how the routing protocol works are changed, these alterations should be applied consistently throughout the network; otherwise, routers will time out and the routing tables will become unsynchronized. CAUTION Tuning network timers of any type is an extremely advanced task and should be done only under very special circumstances and with the aid of the Cisco TAC team.
Across WAN networks, it might be advantageous to turn off routing updates completely and to define manually or statically the best path to be taken by the router. Note also that sophisticated routing protocols such as EIGRP or OSPF send out only incremental updates. Be aware, however, that these are correspondingly more complex to design and implement, although ironically, the configuration is very simple. Another method of reducing routing updates is to implement snapshot routing , which is available on Cisco routers and designed for use across on-demand WAN links. This allows the routing tables to be frozen and updated either at periodic intervals or when the on-demand link is brought up. For more information on this topic, refer to the Cisco web page. To optimize the traffic flow throughout a network, you must carefully design and configure the IP network. In a client/server environment, control of the network overhead is even more important. The following section discusses some concerns and strategies. Prioritization Access lists are not used just to determine which packets will be forwarded to a destination. On a slow network connection where bandwidth is at a premium, access lists are used to determine the order in which traffic is scheduled to leave the interface. Unfortunately, some of the packets might time out. Therefore, it is important to carefully plan the prioritization based on your understanding of the network. You need to ensure that the most sensitive traffic (that is, traffic most likely to time out) is handled first. Many types of prioritization are available. Referred to as queuing techniques , they are implemented at the interface level and are applied to the interface queue. The weighted fair queuing (WFQ) technique is turned on by default on interfaces slower than 2 Mbps, and can be tuned with the fair-queue x y z interface configuration command. The WFQ method is available in the later versions of the IOS. It is turned on automaticallyin some instances, by the Cisco IOSreplacing the first-in, first-out (FIFO) queuing mechanism as the default. The queuing process analyzes the traffic patterns on the link, based on the size of the packets and the nature of the traffic, to distinguish interactive traffic from file transfers. The queue then transmits traffic based on its conclusions. Queuing techniques that are manually configured with access lists are as follows: -
Priority queuing This is a method of dividing the outgoing interface buffer into four virtual queues. Importance or priority ranks these queues, and traffic will be sent out of the interface accordingly . This method ensures that sensitive traffic on a slow or congested link is processed first. -
Custom queuing The interface buffer is divided into many subqueues. Each queue has a threshold stating the number of bytes or the number of packets that might be sent before the next queue must be serviced. In this way, it is possible to determine the percentage of bandwidth that each type of traffic is given. -
Class-based weighted fair queuing (CBWFQ) This queuing method extends the standard WFQ functionality to provide support for user-defined traffic classes. For CBWFQ, you define traffic classes based on match criteria, including protocols, access control lists (ACLs)known as simply access lists in Cisco parlanceand input interfaces. Packets satisfying the match criteria for a class constitute the traffic for that class. A queue is reserved for each class, and traffic belonging to a class is directed to that class's queue. -
Low-latency queuing (LLQ) This feature brings strict priority queuing to CBWFQ. Configured by the priority command, strict priority queuing gives delay-sensitive data, such as voice, preferential treatment over other traffic. With this feature, delay-sensitive data is sent first. In the absence of data in the priority queue, other types of traffic can be sent. Reducing Network Traffic: Alternatives to Access Lists Because of the resources required to process access lists, they are not always the most suitable solution. The null interface is a good example of when a technology can be used imaginatively to produce a low-resource solution. The null interface is a virtual or logical interface that exists only in the operating system of the router. Traffic can be sent to it, but it disappears because the interface has no physical layer. A virtual interface does not physically exist. Administrators have been extremely creative and have used the interface as an alternative to access lists. Access lists require CPU processing to determine which packets to forward. The null interface just forwards the traffic to nowhere. By default, the router responds to traffic sent to the null interface by sending an Internet Control Message Protocol (ICMP) Unreachable message to the source IP address of the datagram. However, you can configure the router simply and silently drop the datagrams. With this configuration, no error messages are sent to the transmitting node. This has several benefits, one of which is additional security. To disable the sending of ICMP Unreachable messages in response to packets sent to the null interface, in interface configuration mode, type the following: Router(config-if)# no ip unreachables The following sections provide examples of how a null interface can be used within the Internet, as well as in an intranet environment. Internet Example If the router receives traffic to be forwarded to network 10.0.0.0, it will be dropped through null0 into a "black hole." Because this is a private network address to be used solely within an organization, never to stray onto the Internet, this is a command that may well be configured on routers within the Internet. Figure 3-2 shows how you might implement a null interface in an organization. The example shows how it can be used to filter the private network from entering the Internet. Figure 3-2. Using the Null Interface on the Internet 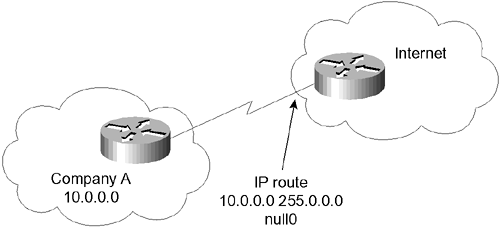 Intranet Example Configuring the static route to null0 on an internal company router would prevent connectivity to the defined network because all traffic to that destination would be forwarded to the null0 interface and dropped. This is illustrated in Figure 3-3. Figure 3-3. Using the Null Interface Within an Organization 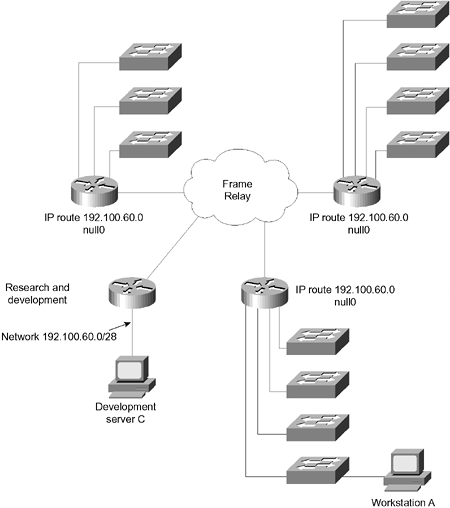 In Figure 3-3, Workstation A would not be capable of connecting to Server C, the development server used by the Research and Development department. The result is that the Research and Development department would be capable of seeing the rest of the organization. Indeed, the rest of the world can see the Research and Development department in a routing table. Any attempt to direct traffic to the network will be unsuccessful , however. The first router that sees the traffic will statically route it to the null interface, which metaphorically is a black hole. NOTE Because the static route is entered into the routing table, it is important to remember that all the rules of static routing apply. By default, if the router hears of the destination route via another source, it is ignored in favor of the static route that has a lower administrative distance (more credible source).
Certain guidelines or key points should be used in the design of an IP network. The following section identifies these guidelines. Keys Points to Remember When Designing an IP Network When addressing an IP network, you should consider whether it is for an existing network or a network that is to be created from scratch, because the approaches will differ . Because the concerns are different, the following list considers general points that apply to both kinds of network. This is followed by a discussion of points to think about when readdressing an existing network. You should consider the following list of items when preparing the IP addressing plan for your network, whether it is a new or existing network: -
Identifying how many hosts and subnets will be required in the future requires communication with other departments, in terms of the growth of personnel and the budget for network growth. Without the standard-issue crystal ball, a wider view must be taken at a high level to answer these questions. The answers need to come from a range of sources, including the senior management and executive team of the organization. -
The design of the IP network must take into consideration the network equipment and its vendors . Interoperability may well be an issue, particularly with some of the features offered by each product. -
For route aggregation (summarization) to occur, the address assignments must have topological significance. -
When using VLSM, the routing protocol must send the extended prefix (subnet mask) with the routing update. -
When using VLSM, the routing protocol must do a routing table lookup based on the longest match. -
Make certain that enough bits have been allowed at each level of the hierarchical design to address all devices at that layer. Also be sure that growth of the network at each level has been anticipated. What address space is to be used (Class A, B, C, private, registered), and will it scale with the organization? NOTE Cisco offers many enhancements in its IOS Software. Most of these enhancements are interoperable. If they are not, Cisco provides solutions for connecting to industry standards (which, of course, are fully supported by Cisco). Check Cisco.com to review the latest features and any connectivity issues.
In many cases, not enough consideration is given to IP address design with regard to the routing process, leaving the decision to be based on the longest address match. Careful consideration of IP addresses is essential to the design of a VLSM network. Consider a network, as described in Chapter 2 in the section "Assigning IP VLSM Subnets for WAN Connections," that uses the Class B Internet address 140.100.0.0. The routing table has the following among its entries: -
140.100.0.0/16 -
140.100.1.0/20 -
140.100.1.192/26 A packet comes into the router destined for the end host 140.100.1.209. The router will forward to the network 140.100.1.192 because the bit pattern matches the longest bit mask provided. The other routes are also valid, however, so the router has made a policy decision that it will always take the most specific mask, sometimes referred to as the longest match . This decision is based on the design assumption that has been made by the router that the longest match is directly connected to the router or that the network is reached from the identified interface. If the end host 140.100.1.209 actually resides on network 140.100.1.208/29, this network must be accessible through the interface that has learned of the subnet 140.100.1.192/26. Summarization will have been configured, because 140.100.1.192 is an aggregate of various networks, including the network 140.100.1.208/29. If the network 140.100.1.208/29 resides out of the interface that has learned about 140.100.1.0/20, no traffic will ever reach the subnet 140.100.1.208/29, because it will always forward based on the longest match in the routing table. The only solution is to turn off summarization and to list every subnet with the corresponding mask. If summarization is turned off, the subnet 140.100.1.208/29 will not be summarized into the network 140.100.1.0/20. It will consequently be the longest match in the routing table, and traffic will be sent to the destination network 140.100.1.208/29. Figure 3-4 shows an example of route summarization. Figure 3-4. Route Summarization and VLSM 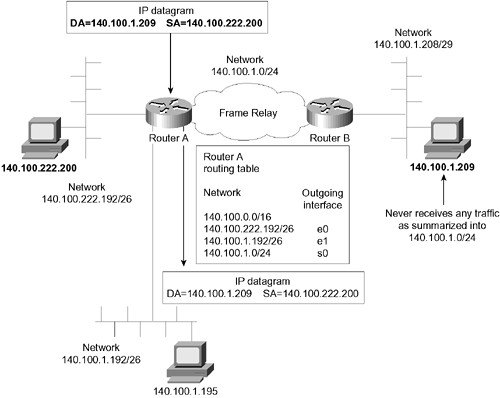 Designing IP Addresses for an Existing Network Up to this point, the discussion has dealt with organizations that are designing an IP network for the first time. In reality, this is rarely the case, unless a decision has been made to readdress the entire network. Often the network has been up and running for some years . If this is the case, the usual task is to use some of the newer technologies available to reduce and manage network traffic so that the network can grow without pain. The simplest solution is to implement a classless routing protocol that sends the subnet mask in the updates and thus allows VLSM and summarization. OSPF, EIGRP, and IS-IS are examples of classless routing protocols. For a detailed comparison of the various routing protocols, refer to Chapter 1, "IP Routing Principles," in the section "Types of Routing Protocols." However appropriate the routing protocol that you have chosen , it might not be possible to use the summarization feature. As explained earlier, this capability is determined in part by how well the addressing scheme mirrors and is supported by the physical topology. You can use the following guidelines to determine whether summarization can be configured within a particular network: -
The network addressing scheme should reflect the physical topology of the network. -
The physical and logical topology of the network should be hierarchical in design. -
Given the network addressing scheme, the addresses to be summarized need to share the same high-order bits. -
If the subnet addresses are clearly set on a single binary border, this suggests a prefix mask of /21 or 255.255.248.0. Because the subnets are multiples of 8, they might be summarized by a higher subnet value that is divisible by 8, such as 140.100.64.0. The following subnets provide an example: -
- 140.100.64.0 -
- 140.100.72.0 -
- 140.100.80.0 -
- 140.100.88.0 -
- 140.100.96.0 -
- 140.100.104.0 -
- 140.100.112.0 -
- 140.100.120.0 -
The nature of the traffic flow within the network should reflect the hierarchical logical and physical design. -
The routing protocol used must support VLSM. Using this list to identify whether summarization is possible, you might find that you do not have the answers to some of the questions that arise or that another solution to readdressing must be found. For example, any design of a network requires very careful analysis of the current network and a clear understanding of the organization's plans. Unfortunately, it is not always possible to determine the nature or flow of data through a network. Intranets and internal web pages have made the nature of the traffic within an organization far more unpredictable. The increased tendency for organizations to need flexibility or mobility in addressing can make the IP design very challenging. The design would need to include Dynamic Host Configuration Protocol ( DHCP ) and Domain Name System ( DNS ) servers to maximize the flexibility of the network. DHCP allows end hosts to be assigned an IP address upon application. As an example, consider an airline that assumes that not everyone will turn up for the flight, so it can oversell the seats on the plane. In a similar fashion, the DHCP server has a block of addresses, but it does not expect every machine on the network to turn on at the same time. Thus, 100 users are provided 60 IP addresses. The DNS server provides a name-to-address translation, which is extremely useful when the DNS server works in conjunction with the DHCP server. It is also important to understand fully the nature of the traffic in the network, particularly if it is a client/server environment, in which the design must allow for servers to communicate with each other and with their clients . Using the existing addressing of the organization might not be possible. If this is the case, the decision must be made to readdress the network. You might need to make this decision for two reasons: either the network cannot scale because of the limitations of the classful address that has been acquired from the IANA, or the original design does not allow for the current environment or growth. If the addressing scheme is inadequate in size, you have several options. The first action for the administrator to take is to apply to the IANA for another address; the second is to use private addressing. The next section describes private addresses on the Internet. Private Addresses on the Internet Private addressing is one of the solutions (along with VLSM, IPv6 with an address field of 128 bits, and CIDR addressing and prefix routing) that the Internet community began to implement when it became apparent that there was a severe limitation to the number of IP addresses available on the Internet. Private addressing is defined by RFC 1597 and revised in RFC 1918. It was designed as an addressing method for organizations that have no intention of ever connecting to the Internet. If Internet connectivity is not required, there is no requirement for a globally unique address from the Internet. The individual organization could address its network without any reference to the Internet, using one of the address ranges provided. The advantage of the Internet is that none of the routers within the Internet recognize any of the addresses designated as private addresses. If an organization that deployed private addressing as outlined in RFC 1918 (in error) connected to the Internet, all its traffic would be dropped. The routers of Internet service providers (ISPs) are configured to filter all network routing updates from networks using private addressing. In the past, organizations "invented" addresses, which were, in fact, valid addresses that had already been allocated to another organization. There are many amusing and horrifying stories of organizations connecting to the Internet and creating duplicate addresses within the Internet. A small company inadvertently masquerading as a large state university can cause much consternation. Table 3-2 outlines the IP address ranges reserved for private addressing, as specified in RFC 1918. Table 3-2. Private Address Ranges | Address Range | Prefix Mask | Number of Classful Addresses Provided | | 10.0.0.0 to 10.255.255.255 | /8 | 1 Class A | | 172.16.0.0 to 172.31.255.255 | /12 | 16 Class Bs | | 192.168.0.0 to 192.168.255.255 | /16 | 256 Class Cs | The use of private addressing has now become widespread among companies connecting to the Internet. It has become the means by which an organization avoids applying to the IANA for an address. As such, it has dramatically slowed, if not prevented, the exhaustion of IP addresses. Because private addresses have no global significance, an organization cannot just connect to the Internet. It must first go through a gateway that can form a translation to a valid, globally significant address. This is called a Network Address Translation ( NAT ) or NAT gateway. Configuring private addressing is no more complicated than using a globally significant address that has been obtained from the IANA and is "owned" by the organization. In many ways, configuring private addressing is easier, because there are no longer any restrictions on the subnet allocation, particularly if you choose the Class A address 10.0.0.0. The reasons for addressing your organization's network using private addressing include the following: -
There is a shortage of addressing within the organization. -
You require security. Because the network must go through a translation gateway, it will not be visible to the outside world. -
You have an ISP change. If the network is connecting to the Internet through an ISP, the addresses allocated are just on loan or are leased to your organization. If the organization decides to change its ISP, the entire network will have to be readdressed. If the addresses provided define just the external connectivity and not the internal subnets, however, readdressing is limited and highly simplified. The use of private addressing has been implemented by many organizations and has had a dramatic impact on the design of IP networks and the shortage of globally significant IP addresses. You should bear some things in mind when designing an IP network address plan using private addressing, including the following: -
If connections to the Internet are to be made, hosts wanting to communicate externally will need some form of address translation performed. -
Because private addresses have no global meaning, routing information about private networks will not be propagated on interenterprise links, and packets with private source or destination addresses should be forwarded across such links with extreme care. Routers in networks not using private address space, especially those of ISPs, are expected to be configured to reject (filter out) routing information about private networks. -
In the future, you might be connecting, merging, or in some way incorporating with another company that has also used the same private addressing range. -
Security and IP encryption do not always allow NAT. If private addressing is deployed in your network and you are connecting to the Internet, you will be using some form of NAT. The following section explains this technology. Connecting to the Outside World with NAT When connecting to the outside world, some filtering and address translation might be necessary. Unless an address has been obtained from the Internet or from an ISP, you must perform address translation. The RFC that defines NAT is RFC 1631, "The IP Network Address Translator." NAT is the method of translating an address on one network into a different address for another network. It is used when a packet is traversing from one network to another and when the source address on the transmitting network is not legal or valid on the destination network, such as when the source corresponds to a private address. The NAT software process must be run on a Layer 3 device or router (which is logical, because NAT deals with the translation of Layer 3 addresses). NAT is often implemented on a device that operates at higher layers of the OSI model because of their strategic placement in the organization. NAT is often used on a firewall system, for example, which is a security device that guards the entrance into the organization from the outside world. The position of the firewall makes it an excellent choice for NAT, because most translations are required for traffic exiting an organization that has used private addressing as defined in RFC 1918. NAT had a controversial childhood, particularly when it was used for translating addresses that did not use RFC 1918 guidelines for private addressing; sometimes an organization used an address that had just been created imaginatively by a network administrator. This practice occurred when there was no glimmer of a possibility that the organization would ever connect to the Internet. This certainty that a company would never connect to the Internet is unrealistic , even for small companies, in an era when even individual homes have Internet connectivity. Therefore, NAT is useful in the following circumstances: -
To connect organizations that used address space issued to other organizations to the Internet -
To connect organizations that use private address space defined in RFC 1918 and want to connect to the Internet -
To connect two organizations that have used the same private address, in line with RFC 1918 -
When the organization wants to hide its addresses and is using NAT as part of firewall capabilities or is using additional security features TIP NAT is designed for use between an organization and the outside world. Although it might be used to solve addressing problems within an organization, you should see this as a temporary fix. In such situations, NAT is a transitory solution to keep the network functional while you are designing and readdressing it appropriately.
Figure 3-5 illustrates an organization connecting to the outside world using NAT. Figure 3-5. Connecting to the Outside World Using NAT 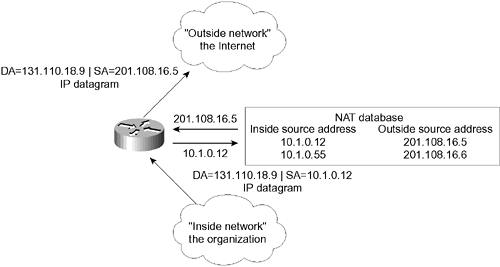 Cisco supports the use of NAT on the majority of its platforms, as well as on its Cisco Secure PIX firewall. Various levels of support are offered, depending on the platform and the IOS release that your company has purchased. Cisco now bundles NAT support into the standard product offering. It started to be widely offered from IOS version 11.2 with the purchase of the "plus" software, and full NAT functionality became available in the Base IOS form with version 12.0. NAT itself is currently at version 3.0. The following sections describe the main features and functions of NAT that Cisco offers. NOTE If you are considering implementing NAT, contact Cisco via its web page. You should always contact the vendor of a product before purchase to appreciate fully the latest offerings and pricing. Because this industry is so dynamic, it is wise to verify the latest data.
The Main Features of NAT The main features of NAT, as supported by Cisco, include the following: -
Static addressing This one-to-one translation is manually configured. -
Dynamic source address translation Here, a pool of addresses is defined. These addresses are used as the product of the translation. They must be a contiguous block of addresses. -
Port address translation (PAT) Different local addresses (within the organization) are translated into one address that is globally significant for use on the Internet. The additional identifier of a TCP or UDP port unravels the multiple addresses that have been mapped to single addresses. The uniqueness of the different local addresses is ensured by the use of the port number mapped to the single address. -
Destination address rotary translation This is used for traffic entering the organization from the outside. The destination address is matched against an access list, and the destination address is replaced by an address from the rotary pool. This is used only for TCP traffic, unless other translations are in effect. The Main Functions of NAT The basic operation of NAT is very straightforward, although the terminology is rather confusing. The list of address definitions in Table 3-3 clarifies the different terms. To translate one network address into another, the process must differentiate between the functionality of the addresses being translated. Table 3-3 lists the categories of functions. Table 3-3. Categories of Functions | Address | Definition | | Inside Global | The addresses that connect your organization indirectly to the Internet. Typically, these are the addresses provided by the ISP. These addresses are propagated outside the organization. They are globally unique and are the addresses used by the outside world to connect to inside the organization. Simply explained, they are the addresses that define how the inside addresses are seen globally by the outside. | | Inside Local | The addresses that allow every end device in the organization to communicate. Although these addresses are unique within the organization, they are probably not globally unique. They may well be private addresses that conform to RFC 1918. They are the inside addresses as seen locally within the organization. | | Outside Global | These are the Internet addresses (all the addresses outside the domain of the organization). They are the outside addresses as they appear to the global Internet. | | Outside Local | These addresses are external to the organization. This is the destination address used by a host inside the organization connecting to the outside world. This will be the destination address of the packet propagated by the internal host. This is how the outside world is seen locally from inside the organization. | As shown in Figure 3-6, a router within the organization sees the inside addresses and the address of the router connecting them to the outside world, namely the Outside Local address. The router that connects to the outside world has an Inside Global address (how it is seen by the rest of the world) and an address to connect to the ISP, the Outside Global address. The diagram shows what each router sees based on its position in the NAT world. Figure 3-6. Using the NAT Terms 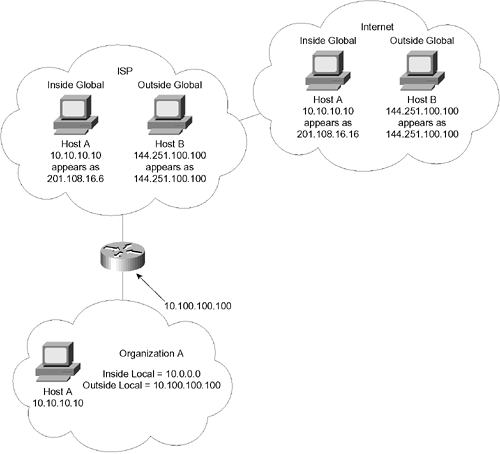 Figure 3-6 illustrates the terms defined in Table 3-3. Understanding IPv6 You have learned about IP addressing, but the discussion so far has been about IPv4, how to address a network, and how to overcome some of its limitations. IPv6 is the solution to many of the limitations in addressing that are seen in IPv4. Although there are IPv6 implementations, IPv6 is yet to be seen as a widespread solution, mainly because of the overwhelming task of readdressing networks and upgrading applications. Both NAT and private addressing are creative solutions to the inherent capacity problem that IPv4 has encountered . As the demand for IP addresses increases , these solutions, however creative, cease to be effective. IPv6 quadruples the address space, providing 128 bits instead of the 32 bits currently available with IPv4. In real terms, that increases the number of addresses from just more than four million to a nearly infinite number of addresses. The address size is quadrupled, allowing approximately 1030 addresses per person on the planet. With IPv6, the ability to dispense with solutions such as NAT, private addresses, and temporarily assigned addresses through DHCP means that end-to-end connectivity is available. With this direct connectivity come some technical enhancements. Both security and QoS might be implemented more efficiently when there is end-to-end connectivity, with no intermediary translations. IPv6 offers the following benefits and features: -
Larger address space -
Unicast and multicast addressing -
Address aggregation -
Autoconfiguration -
Renumbering -
A simple and efficient header -
Security -
Mobility -
Options for transitioning from IPv4 to IPv6 -
Routing protocols The following sections describe each of these features in detail. IPv6 Address Format The IPv6 address is very different from the IPv4 address. Not only is it four times the length, increasing the length from 32 to 128 bits, but it is also represented in hexadecimal as opposed to decimal notation. Colons separate the 16-bit hexadecimal number fields, which are portions of the 128-bit address, from the 128 bits. An example of an IPv6 address follows: 4021:0000:240E:0000:0000:0AC0:3428:121C To avoid confusion, error, and unnecessary complication, the following rules have been determined. These rules simplify the address where possible, making it more manageable: -
The hexadecimal numbers are not case sensitive, preventing operator error in entering addresses. -
Leading 0s in any 16-bit field can be dropped and represented by colons. -
A pair of colons (::) indicates the successive 16-bit fields of 0s have been dropped. The process easily identifies the number of 0s dropped by adding 0s until the address is once again 128 bits long. -
Only one pair of colons is allowed in any address, because the process would not be able to identify how many 0s should be replaced in each location. NOTE The rules for the addressing of IPv6, including guidelines for simplification, are given in the RFC 2373, "IP Version 6 Addressing Structure."
Keeping these rules in mind, the following address: 4021:0000:240E:0000:0000:0AC0:3428:121C can be written in the following form: 4021:0:240E::0AC0:3428:121C Although there cannot be two instances of a double colon , those fields with only 0s can be shown as 0. In this example, the second field shows the 0s reduced to one representational zero. If the address is that of a network with no host ID shown, the address can end in a double colon, for example: 4021:0:240E:: IPv6 addressing comes in many forms, and it is able to solve many of the limitations of IPv4 not simply through additional bits but through greater flexibility and complexity. IPv6 Unicast Addresses The IPv6 unicast addresses are divided up according to functionality. Although a unicast address is tied to a specific node with a unique address to identify it, the scope of the search for that end system is clearly defined in IPv6. This minimizes the resources required, making the transport of packets across the network faster and more efficient all around. IPv6 unicasts come in the following flavors: -
Link local This is a specific address, known as a local link unicast address, where the end system is on the same physical link. This would include discovery protocols, routing protocols, and other control protocols. These addresses are autoconfigured and use the prefix FE80::/10. -
Site local This is a system that is within the same site but might be on a different network. It requires no connection to the global network of the Internet, because there is no guarantee that the addressing is globally unique. -
Aggregate global unicast This is an Internet address that is globally unique. -
Unspecified and loopback This address is simply a placeholder, often used when downloading software or requesting an address. The loopback address is used to test the interface in basic troubleshooting. The address is: 0000.0000.0000.0000.0000.0000.0000.0000.0000.0000.0000.0001 or 0.0.0.0.0.0.0.0.0.0.1 or ::1 IPv6 Multicast Addresses A multicast address is an address that identifies a group of interfaces, typically on different end systems. The packet is delivered to all the systems identified in the multicast address. Using multicast addresses is much more efficient than using broadcasts, which require every end system to stop what it is doing, taking both time and resources. Because a multicast address is an address to a group of systems, if the receiving system is not part of the multicast group, it discards the packet at Level 2. However, broadcasts are processed through the OSI stack before the system can determine that the broadcast is not relevant to them. Layer 2 devices (bridges and switches) propagate broadcasts because broadcast addresses are not stored in its forwarding CAM table. Unlike a router, whose default is to drop packets with unknown addresses, a switch will propagate a frame with an unknown destination address out of every interface. Theoretically, this is also true of multicast addresses, though some devices have intelligence built into the software to restrict multicast propagation. The LAN technologies can propagate these broadcasts around and around if there is a problem, thus causing a broadcast storm that can seriously affect response time and, in extreme cases, network connectivity. IPv6 does not use broadcasts at all, relying solely on the use of multicast addresses. Though IPv4 uses multicasts as defined in RFC 2365, "Administratively Scoped IP Multicast," it uses them in a different manner. The IPv6 multicast has a much larger address range. All IPv6 multicast addresses start with the first 8 bits of the address set to 1. Thus all multicast addresses start with the hexadecimal notation FF (1111 1111). The multicast range is as follows: FF00::/8 FFFF::/8 The second octet, following the first octet of FF, identifies both the scope and the lifetime of the multicast address. In this way, IPv6 has millions of group multicast addresses to use in current and emerging technologies. Address Aggregation Summarization, wherever possible, is crucial within the Internet. The current offering of IPv4 and the routing tables makes summarization critical. The routing tables are more manageable with the implementation of CIDR. Although the addressing scheme in IPv6 allows for an almost infinite amount of addresses to be allocated, the address structure must employ a hierarchical structure so as not to overrun itself. As in IPv4, the leftmost bits of the address are used to summarize networks that appear lower in the bit structure. Thus, the IPv4 address 140.108.128.0/17 could include the subnets 140.108.128.0/24 through to 140.108.255.0/24. This would mean that the routing tables could route to all the subnets, but that instead of having 128 subnets listed in the routing tables, there is a single entry. To locate a minor subnet, the normal rules of routing are followed and the packet is sent to the router advertising 140.108.128.0/17. This router, armed with the more detailed routing table, forwards the packet on until it reaches the destination. In IPv6, the address structure allows for greater granularity in the external address format used within the Internet. The address is very long, and each part serves a function. The first 48 bits of the address are a header used by the IANA for external routing within the Internet to create the Aggregate Global Unicast. The first 3 bits (or the 3 leftmost bits) are fixed as 001 to indicate a global address. The Site Level Aggregator (SLA) is the address used for routing within the autonomous system and identifies the destination network. It can be used without the 48-bit prefix assigned by the IANA. If this 48-bit prefix is not granted or used, the addressing scheme is similar to IPv4 private addressing, and the autonomous system must not attach to the Internet. The interface address is often autoconfigured by using the MAC address of the interface. The IPv6 address that is unique to the Internet is called the Aggregate Global Unicast. The various components described are summarized to the bit allocation below, showing the following address structure: | A fixed prefix of 001 | 3 bits | | IANA allocated prefix | 45 bits | | Site Level Aggregator (SLA) | 16 bits | | Interface | 64 bits | Autoconfiguration The local or directly connected router sends out the prefix of the local link and the router's default route. This is sent to all the nodes on the wire, allowing them to autoconfigure their own IPv6 addresses. The local router provides the 48-bit global prefix and the SLA or subnet information to each end system. The end system simply adds its own Layer 2 address, which is unique because it is the burned-in address (MAC address) taken from the interface card. This MAC address, when appended to the 48-bit global address and the 16-bit subnet address, makes up the unique 128-bit IPv6 end system address. The ability to simply plug in a device without any configuration or DHCP server allows new devices to be added to the Internet, such as cell phones, wireless devices, and even the home toaster. The Internet has become "plug-and-play." Renumbering The ability to connect remote devices automatically alleviates many other tasks that were previously administrative nightmares, requiring months of project planning. In IPv4, the mere thought of readdressing the network made experienced , competent network managers turn pale and shake. IPv6 autoconfiguration allows the router to provide the required information to all the hosts on its network. This means they can renumber or reconfigure their address with ease. This is a requirement if and when you change service providers, because the service provider issues the addressing scheme for its customers. With IPv6, it is reassuring to know that such a radical change can be transparent to the end user. Simple and Efficient Header The IPv6 header has been simplified to speed up processing and, thus, the performance and efficiency of the router. This has been achieved in the following ways: The reduction in processing is because of the fewer fields to process. Memory is used more efficiently with the fields aligned to 64 bits. This allows the lookups to be very fast, because the 64-bit fields take advantage of the 64-bit processors in use today. The only drawback is the use of the 128-bit address, which is larger than the current atomic word size. The removal of the checksum reduces the processing time further. A calculation has been moved up the stack to the transport layer, where both the connection and connectionless transport are required to issue checksums. Remember that the improved efficiency is realized at each router in the path to the destination host, which greatly increases the overall efficiency. Figure 3-7 compares the IPv4 header with the IPv6 header. Figure 3-7. The IPv4 and IPv6 Headers Compared 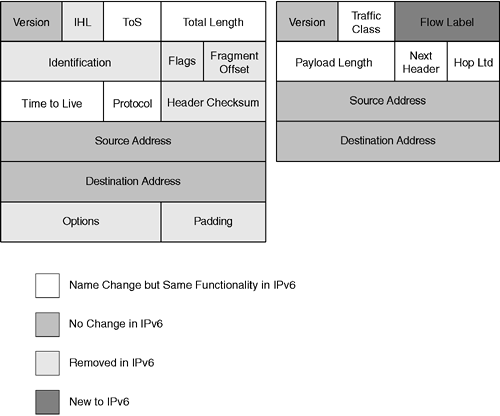 IPv6 Extension Header Instead of including the Options field within the header as IPv4 does, IPv6 attaches the Options field to the end of the header, indicating with the Next Header field whether there is something additional to process. This speeds up the processing and also allows for protocol evolution, because many extension fields can be chained together. Security With direct end-to-end connectivity achieved with a larger address space, security is a more realistic option with IPv6. Because the need for firewalls and NAT processes between the end hosts is decreased, a wider and more direct approach can be given to security by placing the encryption within the host systems. Although IPSec is available with IPv4, it is mandatory in IPv6. The use of extension headers allows for a protocol dedicated to end-to-end security. Mobility IPv6 was designed with mobility built into the protocol using Mobile IP, which is an Internet Engineering Task Force (IETF) standard. Mobile IP allows end systems to move location without the connection being lost, which is essential for wireless products, such as IP phones and GPS systems in cars . The IPv6 routing header allows the end system to change its IP address by using a home address as the source of the packets. The home address is stable, allowing the roving address to maintain mobility. Although IPv4 offers Mobile IP, it does so by tunneling back to the home network and then forwarding the data to the final destination. This is called triangle routing , and though it works, it is more cumbersome than the solution that is provided by IPv6. IPv4 to IPv6 Transitions The key to the success of IPv6 lies not only in its functionality and efficiency as a routed protocol, but also in the ability to transition existing networks to the new protocol. This requires many things to happen, including the following: The main theory is that you should start by deploying IPv6 at the outer edges of the network and move into the core of the network in a slow, methodical, and controlled manner. This means that one of three options must occur: The IPv6 traffic needs to be carried through the IPv4 network so that IPv6 can communicate with other devices in a remote domain; both IPv4 and IPv6 need to run through the network, allowing both protocols to live in peaceful coexistence; or one protocol needs to be translated into the other. The following methods describe how a transition from IPv4 to IPv6 could occur: -
IOS dual stack Both IPv4 and IPv6 run on all systems. This approach allows new IPv6 applications to be introduced on the end systems. The application on the end system requests either an IPv4 address or an IPv6 address from the DNS server. This determines which application uses which IP protocol. -
Configured tunnels These tunnels are for more permanent solutions and provide a secure and stable method of communication across an IPv4 backbone. Both end points of the tunnel need to be manually configured and to be running both IPv4 and IPv6. -
6to4 tunneling This allows IPv6 to be run over an automatically configured tunnel. It requires that the routers connecting the IPv6 remote sites through the IPv4 cloud need to be running dual stacks. The edge routers responsible for running the tunnel will use the prefix 2002::/16 and append the IPv4 interface address to create an address. The interface is the IPv4 address converted to hexadecimal and added to the routing prefix 2002::/16. IPv6 Routing Protocols The IP routing protocols that support IPv6 are RIPng, OSPF, IS-IS, and BGP-4, as of Cisco IOS Software Release 12.2T and later. RIPng is an interior routing protocol and is supported by Cisco IOS. Its functionality is that of RIPV2. It is a distance vector routing protocol, which means that it uses split horizon with poison reverse and has a maximum hop count. You will learn more about distance vector protocols in Chapter 4, "IP Distance Vector Routing Principles." To accommodate the needs of IPv6, RIPng incorporates the following features: BGP-4+ is an exterior routing protocol. It is used to connect autonomous systems across the Internet or within organizations. |